1 LVS action
LVS is an open source software, which can realize transport layer and four layer load balancing.
LVS is the abbreviation of Linux Virtual Server, which means Linux Virtual Server.
Currently:
- Three IP load balancing technologies: VS/NAT, VS/TUN and VS/DR
- Eight scheduling algorithms: rr, wrr, lc, wlc, lblc, lblcr, dh, sh
2. Difference between LVS and Nginx
LVS
LVS has strong load capacity. Because its working mode logic is very simple, it only distributes requests, and works in layer 4 of the network, there is no traffic, so its efficiency does not need to worry too much.
LVS can basically support all applications. Because it works in layer 4, LVS can load balance almost all applications, including Web, database, etc.
Note: LVS cannot completely identify node failures. For example, under WLC rules, if a node in the cluster is not configured with a VIP, the whole cluster will not be used. There are other problems that need further testing.
Nginx
Nginx works at layer 7 of the network, so it can implement diversion strategies for HTTP applications, such as domain name, structure, etc. In contrast, LVS does not have such a function, so nginx can be used in far more occasions than LVS. Moreover, nginx has little dependence on the network. In theory, as long as Ping works, web pages can be connected normally. LVS depends on network environment. Only when DR mode is used and servers are shunted in the same network segment can the effect be guaranteed.
Nginx can detect the internal failure of the server by processing the status code and timeout returned by the web page, and will resend the request that returns the error to another node. At present, LVS and LDirectd also support monitoring the internal situation of the server, but they cannot resend requests.
For example, if the user is uploading a file and the node processing the uploaded information just fails, nginx will resend the upload request to another server, and the LVS will be directly disconnected in this case. Nginx can also support HTTP and Email (Email function is rarely used). LVS supports more applications in this e-commerce than nginx.
Nginx can also bear high load and operate stably. Because the processing flow is limited by machine I/O and other configurations, the load capacity is relatively poor.
The installation, configuration and testing of nginx are relatively simple because there are corresponding error logs to prompt. The installation, configuration and testing of LVS takes a long time, because LVS has a great influence on the network. In many cases, the configuration may not be successful because of network problems, and it is relatively difficult to solve problems. Nginx itself has no ready-made hot standby scheme, so it is risky to run on a single machine. It is recommended to use it with KeepAlived. In addition, nginx can be used as a node machine of LVS to make full use of the functions and performance of nginx. Of course, in this case, Squid and other software with distribution function can also be used directly.
Specific application and specific analysis. If it is a relatively small website (the daily PV is less than 1 million), Nginx can deal with it. If there are many machines, DNS polling can be used. There are many machines used after LVS. When building large websites or providing important services and there are many machines, LVS can be considered more.
Note: Alibaba cloud does not support virtual VIP technology by default
3. Keepalived effect
LVS can achieve load balancing, but it cannot perform health check. For example, if an rs fails, LVS will still forward the request to the failed rs server, which will lead to the invalidity of the request.
Keepalive software can perform health check, and can realize the high availability of LVS at the same time to solve the problem of single point of failure of LVS. In fact, keepalive is born for LVS.
4. Working principle of kept
keepalived is a software similar to Layer2, 4 and 7 switching mechanism. It is a service software to ensure high availability of clusters in Linux cluster management. Its function is to prevent single point of failure.
How keepalived works:
keepalived is a service software based on VRRP protocol to ensure high availability of clusters. Its main function is to realize fault isolation of real machines and failure switching between load balancers to prevent single point of failure. Before understanding the principle of kept, first understand the VRRP protocol.
VRRP protocol: Virtual Route
Redundancy Protocol virtual routing Redundancy Protocol. It is a fault-tolerant protocol to ensure that when the next hop route of the host fails, another router will work instead of the failed router, so as to maintain the continuity and reliability of network communication. Before introducing VRRP, let's introduce some terms related to VRRP:
- Virtual Router: it is composed of one Master router and multiple Backup routers. The host uses the virtual router as the default gateway.
- VRID: the identification of the virtual router. A group of routers with the same VRID constitute a virtual router.
- Master router: the router that undertakes the task of message forwarding in the virtual router.
- Backup router: a router that can replace the Master router when the Master router fails.
- Virtual IP address: the IP address of the virtual router. A virtual router can have one or more IP addresses.
- IP address owner: a router whose interface IP address is the same as the virtual IP address is called an IP address owner.
- Virtual MAC address: a virtual router has a virtual MAC address. The format of the virtual MAC address is 00-00-5E-00-01-{VRID}. Usually, the virtual router responds to ARP requests using the virtual MAC address. Only when the virtual router is specially configured, it responds to the real MAC address of the interface.
- Priority: VRRP determines the status of each router in the virtual router according to the priority.
- Non preemptive mode: if the Backup router works in non preemptive mode, as long as the Master router does not fail, the Backup router will not become the Master router even if it is configured with a higher priority.
- Preemption mode: if the Backup router works in preemption mode, it will compare its priority with the priority in the notification message after receiving the VRRP message. If your priority is higher than that of the current Master router, you will take the initiative to seize the Master router; Otherwise, the Backup state will be maintained.
Virtual routing diagram:
VRRP divides a group of routers in the LAN together to form a VRRP backup group. It is functionally equivalent to the function of a router and is identified by virtual router number (VRID). Virtual router has its own virtual IP address and virtual MAC address. Its external realization form is exactly the same as the actual physical routing. The host in the LAN sets the IP address of the virtual router as the default gateway to communicate with the external network through the virtual router.
The virtual router works on the actual physical router. It consists of multiple actual routers, including a Master router and multiple Backup routers. When the Master router works normally, the host in the LAN communicates with the outside world through the Master. When the Master router fails, a device in the Backup router will become a new Master router to take over the task of forwarding messages. (high availability of router)
Work engineering of VRRP:
(1) The router in the virtual router elects the Master according to the priority. The Master router notifies its virtual MAC address to the connected device or host by sending free ARP message, so as to undertake the message forwarding task;
(2) The master router sends VRRP message periodically to announce its configuration information (priority, etc.) and working status;
(3) If the Master router fails, the Backup router in the virtual router will re elect a new Master according to the priority;
(4) During the virtual router state switching, the Master router switches from one device to another. The new Master router simply sends an ARP message carrying the MAC address and virtual IP address information of the virtual router, so that the ARP related information in the host or device connected to it can be updated. The host in the network cannot perceive that the Master router has switched to another device.
(5) When the priority of the Backup router is higher than that of the Master router, the working mode (preemptive mode and non preemptive mode) of the Backup router determines whether to re elect the Master.
The value range of VRRP priority is 0 to 255 (the higher the value, the higher the priority)
5 LVS + kept + nginx architecture diagram
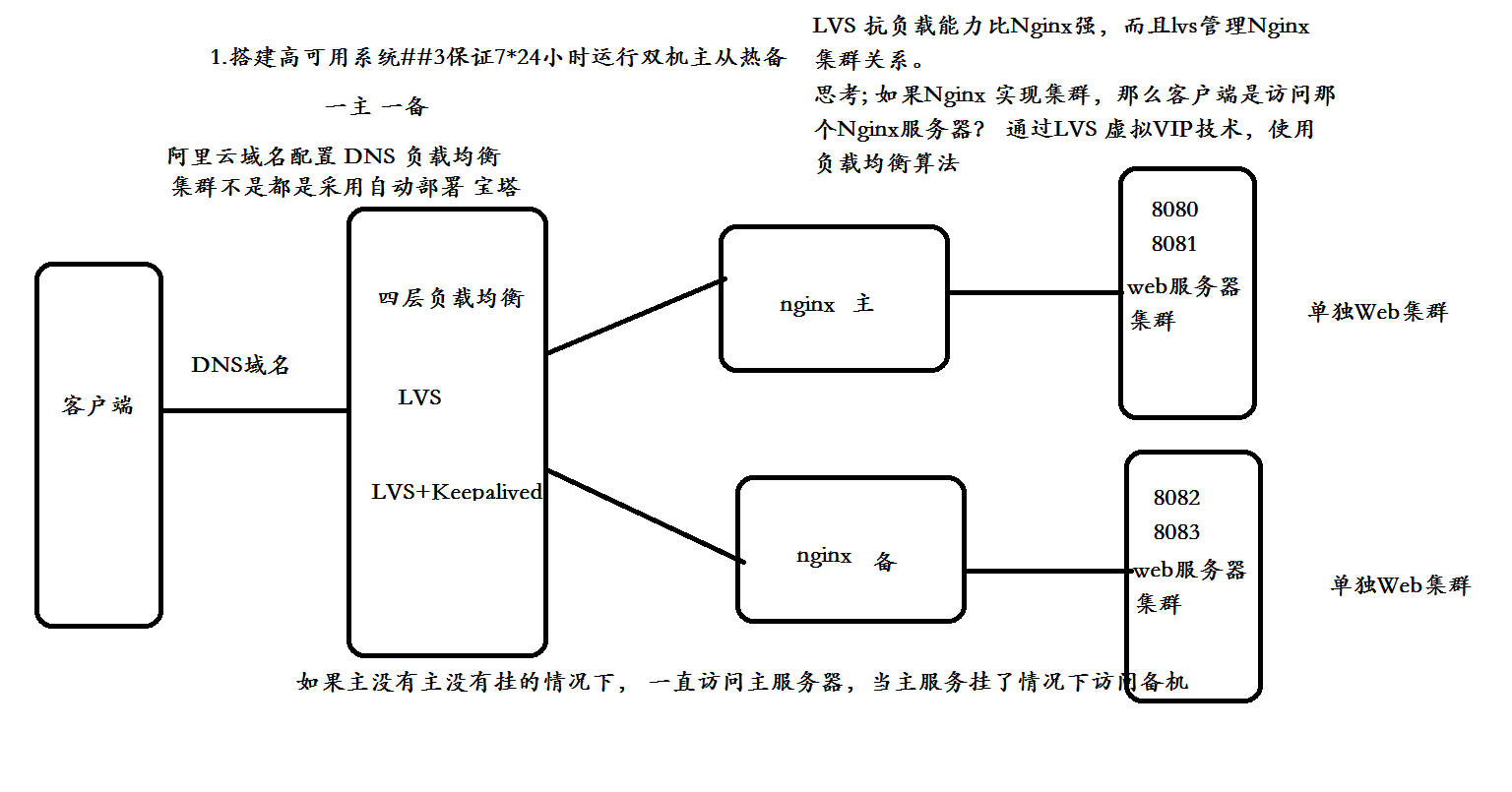
6 environment service configuration
- Nginx main server: 192.168.153.11
- Nginx standby server: 192.168.153.12
- Lvs virtual VIP: 192.168.153.13
7 environment construction
cd /usr/local
1. Download keepalived
wget http://www.keepalived.org/software/keepalived-1.2.18.tar.gz
2. Decompression and installation:
tar -zxvf keepalived-1.2.18.tar.gz -C /usr/local/
3. Download the plug-in openssl
yum install -y openssl openssl-devel
4. Start compiling keepalived
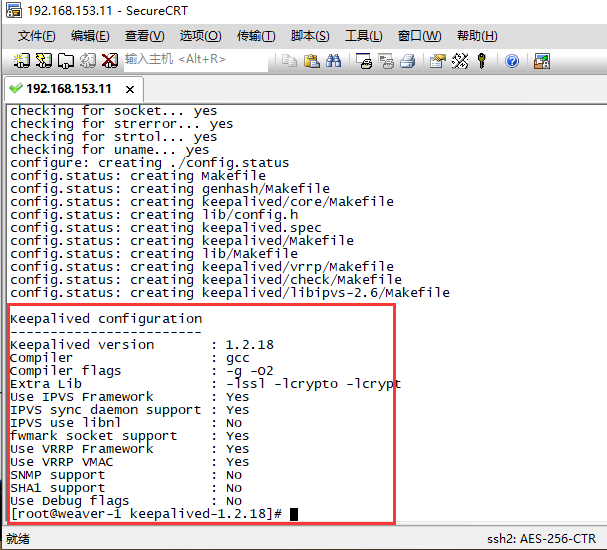
cd keepalived-1.2.18/ && ./configure --prefix=/usr/local/keepalived
Compiled successfully interface:
If eepalived executes. / configure --prefix=/usr/local/keepalived, an error is reported:
configure: error: Popt libraries is required
Reason for this error:
Development pack for popt not installed
resolvent:
yum install popt-devel
Install the development package of popt. Re. / configure.
5. make it
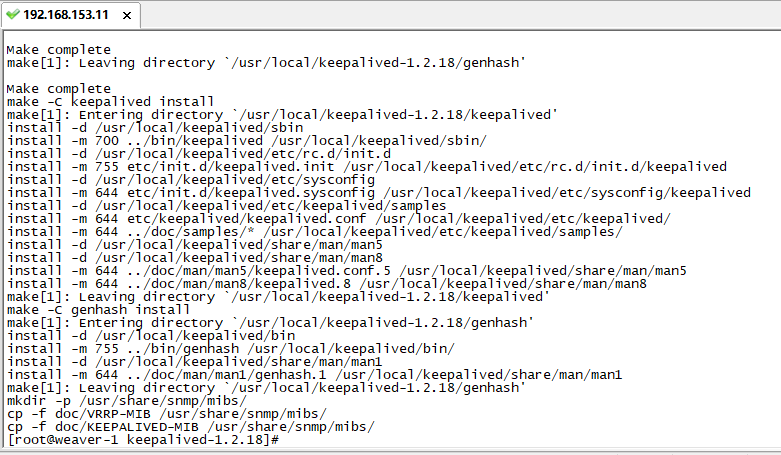
make && make install
Successful interface:
8 keepalived is installed as a Linux system service
Install keepalived as a Linux system service because the default installation path of keepalived is not used (default path: / usr/local). After the installation is completed, some modifications need to be made:
First create a folder and copy the keepalived configuration file:
mkdir /etc/keepalived
cp /usr/local/keepalived/etc/keepalived/keepalived.conf /etc/keepalived/
Then copy the keepalived script file:
cp /usr/local/keepalived/etc/rc.d/init.d/keepalived /etc/init.d/
cp /usr/local/keepalived/etc/sysconfig/keepalived /etc/sysconfig/
ln -s /usr/local/sbin/keepalived /usr/sbin/
ln -s /usr/local/keepalived/sbin/keepalived /sbin/
report errors:

You can set startup:
chkconfig keepalived on
8.1 keepalived common commands
Start keepalived
service keepalived start
Startup error:
Starting keepalived (via systemctl): Job for keepalived.service failed. See 'systemctl status keepalived.service' and 'journalctl -xn' for details.
terms of settlement:
cd /usr/sbin/
rm -f keepalived
cp /usr/local/keepalived/sbin/keepalived /usr/sbin/
Restart keepalived
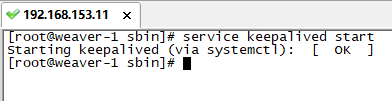
service keepalived start
Successful startup:
Stop keepalived
service keepalived stop
8.2 using keepalived virtual VIP
cd /etc/keepalived/
rm -rf keepalived.conf
vi keepalived.conf
! Configuration File for keepalived
vrrp_script chk_nginx {
script "/etc/keepalived/nginx_check.sh" #Run the script. The content of the script is shown below, which is to automatically start the service after an nginx outage
interval 2 #Detection interval
weight -20 #If the condition holds, the weight is - 20
}
# Define virtual routes, VI_1 is the identifier of the virtual route and defines its own name
vrrp_instance VI_1 {
state MASTER # To decide the master and slave
interface ens33 # Bind the network interface of virtual IP and fill it in according to your own machine
virtual_router_id 121 # The ID number of the virtual route. The settings of the two nodes must be the same
mcast_src_ip 192.168.153.11 # Fill in local ip
priority 100 # The node priority is mainly higher than that of the slave node
nopreempt # The high priority setting nopreempt solves the problem of preemption again after exception recovery
advert_int 1 # The multicast information sending interval must be the same between the two nodes. The default is 1s
authentication {
auth_type PASS
auth_pass 1111
}
# Track_ Add script block to instance configuration block
track_script {
chk_nginx # Services that perform Nginx monitoring
}
### Virtual IP address configuration specification
virtual_ipaddress {
192.168.153.13 # Virtual ip, that is, the ip that solves how the ip that writes the dead program can be switched, is also scalable and widely used. Multiple can be configured.
}
}
Turn off the firewall:
systemctl stop firewalld
Installing Nginx
cd /usr/local/
wget http://nginx.org/download/nginx-1.9.10.tar.gz
tar -zxvf nginx-1.9.10.tar.gz
cd nginx-1.9.10
./configure
make && make install
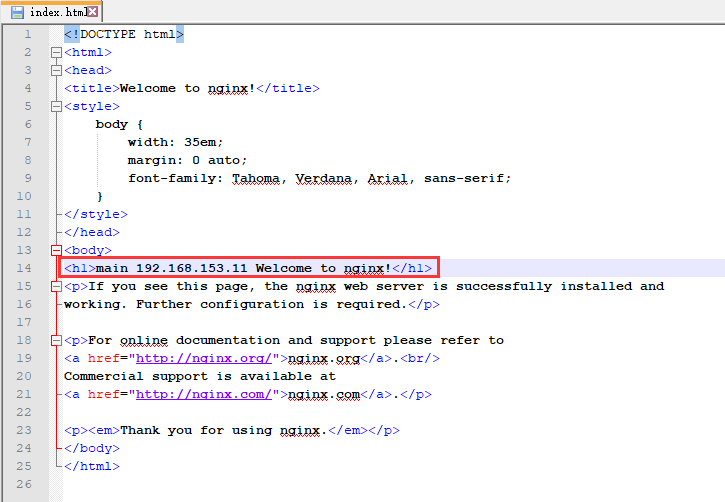
Modify html page:
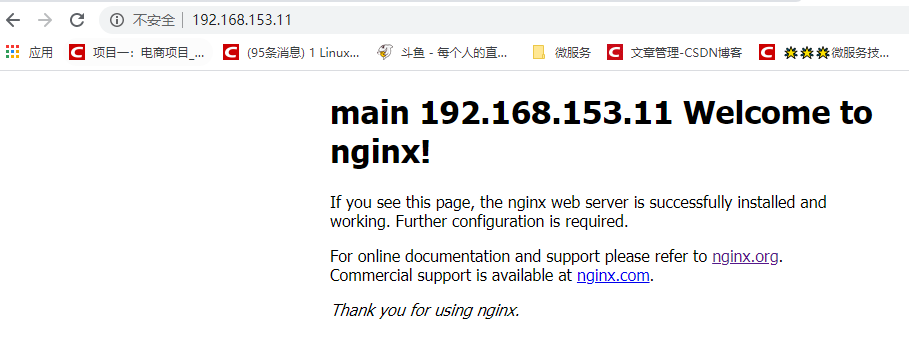
Start Nginx:
/usr/local/nginx/sbin/nginx
keepalived
service keepalived start
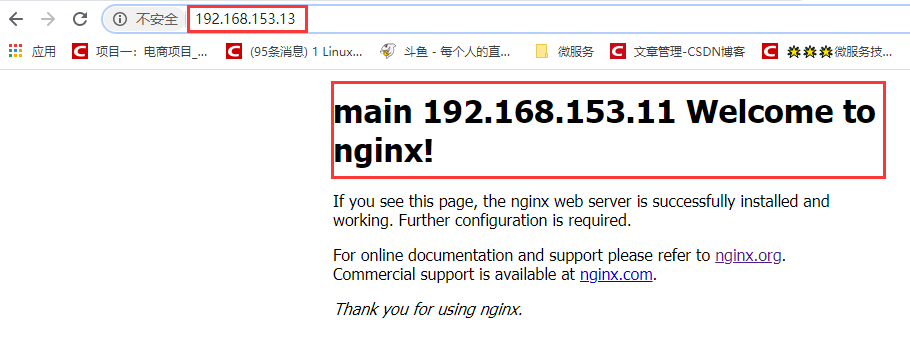
Using the virtual server address, discovery can also access: http://192.168.153.13/
6.3 nginx + keepalived simple dual master-slave hot standby
6.3.1 overview of dual master-slave hot standby
The two machines can be hot standby for each other, and each is responsible for its own service at ordinary times. During the online update, after closing the tomcat of one server, nginx automatically switches the traffic to the backup machine of another service, so as to realize painless update, maintain the continuity of the service and improve the reliability of the service, so as to ensure the 7 * 24-hour operation of the server.
6.3.2 Nginx Upstream realizes simple dual master-slave hot standby
Set up the active and standby Tomcat servers
upstream testproxy {
server 127.0.0.1:8080;
server 127.0.0.1:8081 backup;
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://testproxy;
index index.html index.htm;
}
### Timeout time between nginx and upstream server (real access server) timeout time of back-end server connection_ Timeout for initiating handshake waiting for response
proxy_connect_timeout 1s;
### Timeout time of nginx sending to upstream server (real access server)
proxy_send_timeout 1s;
### nginx accepts the timeout time of upstream server (real access server)
proxy_read_timeout 1s;
}
As long as a backup parameter is added after the server ip that you want to become a backup server, this server will become a backup server.
When it is not used at ordinary times, nginx will not forward any requests to it. Nginx will enable this node only when all other nodes cannot be connected.
Once a node is available to restore service, the node is no longer used and enters the backup state.
6.3.3 - 6.3.5: build active and standby Nginx servers
6.3.3 Nginx + keepalived simple dual master-slave hot standby
A VIP is installed for each virtual service, and the master-slave relationship is configured. When the master hangs up, the standby machine is directly run.
- Kept virtual VIP address: 192.168.153.13
- Server A: 192.168.153.11
- B server: 192.168.153.12
Direct cloning 192.168.153.11 was 192.168.153.12
6.3.4 modifying the main keepalived information
Modify the keepalived file of the primary Nginx server:
vi /etc/keepalived/keepalived.conf
- State is MASTER
- mcast_src_ip: 192.168.153.11
! Configuration File for keepalived
vrrp_script chk_nginx {
script "/etc/keepalived/nginx_check.sh" #Run the script. The content of the script is shown below, which is to automatically start the service after an nginx outage
interval 2 #Detection interval
weight -20 #If the condition holds, the weight is - 20
}
# Define virtual routes, VI_1 is the identifier of the virtual route and defines its own name
vrrp_instance VI_1 {
state MASTER # To decide the master and slave
interface ens33 # Bind the network interface of virtual IP and fill it in according to your own machine
virtual_router_id 121 # The ID number of the virtual route. The settings of the two nodes must be the same
mcast_src_ip 192.168.153.11 #Fill in local ip
priority 100 # The node priority is mainly higher than that of the slave node
nopreempt # The high priority setting nopreempt solves the problem of preemption again after exception recovery
advert_int 1 # The multicast information sending interval must be the same between the two nodes. The default is 1s
authentication {
auth_type PASS
auth_pass 1111
}
# Track_ Add script block to instance configuration block
track_script {
chk_nginx # Services that perform Nginx monitoring
}
virtual_ipaddress {
192.168.153.13 # Virtual ip, that is, the ip that solves how the ip that writes the dead program can be switched, is also scalable and widely used. Multiple can be configured.
}
}
6.3.5 modify the keepalived information
Modify the keepalived file of the primary Nginx server
/etc/keepalived/keepalived.conf
- State is BACKUP
- mcast_src_ip: 192.168.153.12
! Configuration File for keepalived
vrrp_script chk_nginx {
script "/etc/keepalived/nginx_check.sh" #Run the script. The content of the script is shown below, which is to automatically start the service after an nginx outage
interval 2 # Detection interval
weight -20 # If the condition holds, the weight is - 20
}
# Define virtual routes, VI_1 is the identifier of the virtual route and defines its own name
vrrp_instance VI_1 {
state BACKUP # To decide the master and slave
interface ens33 # Bind the network interface of virtual IP and fill it in according to your own machine
virtual_router_id 121 # The ID number of the virtual route. The settings of the two nodes must be the same
mcast_src_ip 192.168.153.12 # Fill in local ip
priority 100 # The node priority is mainly higher than that of the slave node
nopreempt # The high priority setting nopreempt solves the problem of preemption again after exception recovery
advert_int 1 # The multicast information sending interval must be the same between the two nodes. The default is 1s
authentication {
auth_type PASS
auth_pass 1111
}
# Track_ Add script block to instance configuration block
track_script {
chk_nginx # Services that perform Nginx monitoring
}
virtual_ipaddress {
192.168.153.13 # Virtual ip, that is, the ip that solves how the ip that writes the dead program can be switched, is also scalable and widely used. Multiple can be configured.
}
}
summary
Keepalived is based on LVS to detect heartbeat and monitor the server to achieve failover. If the server goes down, it will try to automatically retry the script. If repeated retries still fail, an email will be sent to the operation and maintenance personnel.
What should I do when a server in a production environment goes down?
- Failover
- Heartbeat detection
- load balancing
- Automatic restart
6.4 nginx + keepalived for high availability
Write nginx_check.sh script:
vi /etc/keepalived/nginx_check.sh
#!/bin/bash
A=`ps -C nginx –no-header |wc -l`
if [ $A -eq 0 ];then
/usr/local/nginx/sbin/nginx
sleep 2
if [ `ps -C nginx --no-header |wc -l` -eq 0 ];then
killall keepalived
fi
fi
Note: the script must be authorized
chmod 777 nginx_check.sh