preface
Use requests+xpath to crawl Douban film reviews. Don't talk too much nonsense.
Let's start happily~
development tool
**Python version: * * 3.6.4
Related modules:
requests module;
jieba module;
pandas module
numpy module
Pyecarts module;
And some Python built-in modules.
Environment construction
Install Python and add it to the environment variable. pip can install the relevant modules required.
preparation in advance
1. Get page content
# Crawl page url\ douban_url = 'https://movie.douban.com/subject/26647117/comments?status=P'\ # Requests send requests\ get_response = requests.get(douban_url)\ # Convert the returned response code into text (entire web page)\ get_data = get_response.text
2. Analyze the page content and get the content we want
- Open the page we want to crawl in the browser
- Press F12 to enter the developer tool and check where the data we want is
- Here we only need reviewers + comments
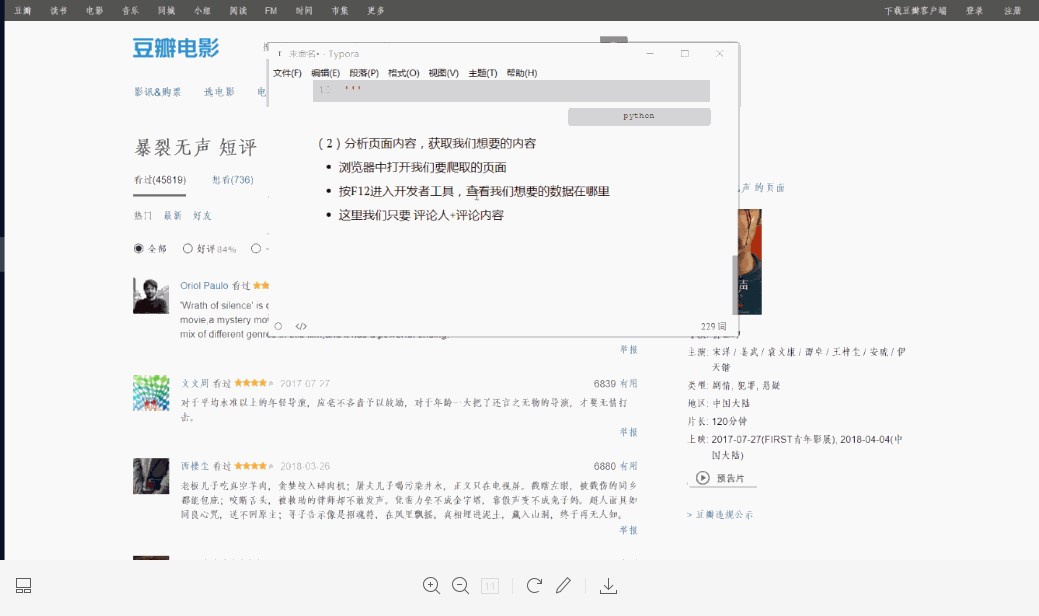
- Analyze the xpath values we get
'/html/body/div[3]/div[1]/div/div[1]/div[4]/**div[1]** /div[2]/h3/span[2]/a' '/html/body/div[3]/div[1]/div/div[1]/div[4]/**div[2]** /div[2]/h3/span[2]/a' '/html/body/div[3]/div[1]/div/div[1]/div[4]/**div[3]** /div[2]/h3/span[2]/a'
- Through observation, we find that these xpaths are only slightly different. The format of the bold part above has been changed. Therefore, we need to crawl all commenters. Just change the xpath to:
'/html/body/div[3]/div[1]/div/div[1]/div[4]/**div**/div[2]/h3/span[2]/a'
That is, do not use the following sequence number. When we query, we will automatically capture similar xpath.
- Through the same analysis, we can get that the xpath of the comment content is:
'/html/body/div[3]/div[1]/div/div[1]/div[4]/**div**/div[2]/p'
# (following the above code) parse the page and output the obtained content\
a = etree.HTML(get_data)\
commentator = s.xpath('/html/body/div[3]/div[1]/div/div[1]/div[4]/div/div[2]/h3/span[2]/a/text()')\
comment_content = a.xpath('/html/body/div[3]/div[1]/div/div[1]/div[4]/div/div[2]/p/text()')\
# Analyze the obtained content and remove the redundant content\
for i in range(0,len(files)):\
print(commentator[i]+'Say:')\
files[i].strip(r'\n')\
files[i].strip(' ')\
print(comment_content[i])
Operation results
Oriol Paulo Say: 'Wrath of silence' is quite different from the crime movies I've seen. It's a mix of genres. It's a crime movie,a mystery movie,an action movie,it's also a social realistic movie. Xin Yu Kun plays very well the mix of different genres in this film,and it has a powerful ending. Wen Wenzhou said: young directors above the average level should be encouraged without stinginess. Only those directors who are too old to have anything should be ruthlessly attacked. Xiluochen said: the boss's son ate vacuum mutton and greedily ground it into the meat shredder; The butcher's son drinks polluted well water, and justice is only on the TV screen. If you poke your left eye blind, your fellow countrymen who are stabbed can cover it up; Biting his tongue, the rescued lawyer dared not speak. You can't build a pyramid by brute force, you can't turn into a rabbit mother by falsehood. Superman mask is like a curse of conscience, which cannot be sent back to its original owner; The notice of looking for a son is like a soul calling sign, fluttering in the wind. The truth is buried in the earth, hidden in the cave, and finally no one knows it. #85 said: Xin Yukun's second work is not the heart maze 2.0 operated by a show. If you want to say who the style is like, it's all like and not like: Kubrick's single point perspective staring at the cave, the neurotic killer shaped like the Cohen brothers, the corridor Fight like the old boy... What's different is that he doesn't just want to tell you who the killer is, but his choice, And like a scalpel, it cuts open the social crux of upper-level gaffe, middle-level immorality, bottom-level aphasia and human disqualification Eat the small cake and say: the ending is great. I like the soundtrack very much. If only the subtitles could be removed. When Jiang Wu picked up the ashtray, he guessed the end. Just think carefully and fear, why is the well water getting saltier and saltier? Why are so many people edema? The village head knows, otherwise he won't drink mineral water. However, the stem didn't explain too much in the end The big meat pot said: the upper level is hypocritical and cruel, the middle level is indifferent and selfish, and the lower level is aphasia and powerlessness. The little prince of martial arts said: the power of Motorola was still much lower than that of Nokia. Liu Xiaoyang said: only 80%The film has been wonderful. That's how Chinese genre films should be made. Good multi-line narrative control, deep hole mapping of human nature, explosive growth of economy, burst and uncontrollable social problems, men's Silent Resentment and pain, just like the people at the bottom who can't speak. At the end of darkness, the child was not found, and the truth was not revealed. This is the social truth. Sometimes the wicked do evil only to become a true alliance with those with the same interests. Europa said: the kind of film that goes down and falls into darkness castigates the main social contradictions and is not responsible for providing the pleasure of solving puzzles, so it will be very heavy and blocked after watching. If the heart maze is still a spontaneous creation in the manual era, it is obviously considered in the industrial era (CASS action special effects). The three compete, the lawyer is too weak, Song Yang's combat power is too strong, and Jiang Wu is modeled. The advantages and disadvantages are obvious. Bavarian Dionysus said: the ending is so fucking awesome. After watching it, take a breath in the cinema. Insinuation is also very awesome. In the motorcycle license in 1984, a loser at the bottom was set as a mute (without the right to speak), and there was collusion between lawyers (representing the middle class and the law) and coal bosses (representing the powerful and evil forces). Therefore, even if Zhang Baomin has the force value of Mian Zhenghe in the Yellow Sea, he can only become a victim of this cruel society. Ling Rui said: when you look at the abyss, the abyss is looking at you. frozenmoon Said: Chang Wannian is a carnivore, Xu Wenjie drinks soup, and Zhang Baomin himself is "meat". Originally, they played their role in a position in the food chain, but accidentally broke everything. After getting out of control, everyone found that they were just "meat". Chang took off his wig and suit and had to submit to violence and luck. Xu had to face cruelty to get out of the protection of money and words. Zhang's price may be even greater. The dull sound of human nature. Shameless bastard said: what moves me most in the film is not the obvious and even obvious metaphors, but the "Aphasia" of the whole film. We belong to the "aphasia generation". In the corresponding film, we are not only the "physiological aphasia" of Zhang Baomin, the mute on the surface, but also the "active aphasia" selected by elite lawyers at the end of the film. The film's accurate display of "Aphasia" not only sensitively captures the pain points of the times, but also extremely painful.
3. Turn the page, and store the reviewer and comment content in csv file
- Page 1
Unlike the previous analysis of xpath, we just need to find out the differences and laws of URLs between each page.
# The start property indicates the start position\ turn_page1 = 'https://movie.douban.com/subject/26647117/comments?status=P'\ turn_page2 = 'https://movie.douban.com/subject/26647117/comments?start=20&limit=20&sort=new_score&status=P'\ turn_page3 = 'https://movie.douban.com/subject/26647117/comments?start=40&limit=20&sort=new_score&status=P'\ turn_page4 = 'https://movie.douban.com/subject/26647117/comments?start=60&limit=20&sort=new_score&status=P'
It is observed that, except for the first one, only the value of start is different for each url, and it is increased by 20 each time. The start attribute has been mentioned above. Through observation, it is not difficult to find that there are only 20 comments on each page, which is controlled by the limit attribute (Xiaobian has tried, and manual changes are useless. It is estimated that it is the anti climbing of Douban, but it does not affect us), What I want to explain here is that the reason why the start value is incremented by 20 is controlled by the limit.
- Page 2
# Total number of comments obtained\
comment_counts = a.xpath('/html/body/div[3]/div[1]/div/div[1]/div[1]/ul/li[1]/span/text()')\
comment_counts = int(comment_counts[0].strip("Yes()"))\
# Calculate the total number of pages (20 comments per page)\
page_counts = int(comment_counts/20)\
# Request access and store the crawled data in csv file\
for i in range(0,page_counts):\
turn_page_url = 'https://movie.douban.com/subject/26647117/comments?start={}&limit=20&sort=new_score&status=P'.format(i*20)\
get_respones_data(turn_page_url)
Before completing the above, we must modify the previously written code to make the code look good. We can package the previously written code into a function get_respones_data(), pass in an access url parameter to get the returned HTML.
code implementation
import requests\
from lxml import etree\
import pandas as pd\
def get_respones_data(douban_url = 'https://movie.douban.com/subject/26647117/comments?status=P'):\
# Requests send requests\
get_response = requests.get(douban_url)\
# Convert the returned response code into text (entire web page)\
get_data = get_response.text\
# Parse page\
a = etree.HTML(get_data)\
return a\
first_a = get_respones_data()\
# Turn pages\
comment_counts = first_a.xpath('/html/body/div[3]/div[1]/div/div[1]/div[1]/ul/li[1]/span/text()')\
comment_counts = int(comment_counts[0].strip("Yes()"))\
page_counts = int(comment_counts / 20)\
#Xiaobian has been tested. If you don't log in, you can only visit 10 pages at most, that is, 200 comments\
#The next edition will teach you how to deal with anti climbing\
for i in range(0, page_counts+1):\
turn_page_url = 'https://movie.douban.com/subject/26647117/comments?start={}&limit=20&sort=new_score&status=P'.format(\
i * 20)\
print(turn_page_url)\
a = get_respones_data(turn_page_url)\
# Get reviewers and comments\
commentator = a.xpath('/html/body/div[3]/div[1]/div/div[1]/div[4]/div/div[2]/h3/span[2]/a/text()')\
comment_content = a.xpath('/html/body/div[3]/div[1]/div/div[1]/div[4]/div/div[2]/p/text()')\
# Parse the content and store it in csv file\
content = [' ' for i in range(0, len(commentator))]\
for i in range(0, len(commentator)):\
comment_content[i].strip(r'\n')\
comment_content[i].strip(' ')\
content_s = [commentator[i],comment_content[i]]\
content[i] = content_s\
name = ['Commentator','Comment content']\
file_test = pd.DataFrame(columns=name, data=content)\
if i == 0:\
file_test.to_csv(r'H:\PyCoding\FlaskCoding\Test_all\test0609\app\comment_content.cvs',encoding='utf-8',index=False)\
else:\
file_test.to_csv(r'H:\PyCoding\FlaskCoding\Test_all\test0609\app\comment_content.cvs',mode='a+',encoding='utf-8',index=False)
Data visualization
Install the new module
pip install jieba\ pip install re\ pip install csv\ pip install pyecharts\ pip install numpy
1 analyze data
1 with codecs.open(r'H:\PyCoding\FlaskCoding\Test_all\test0609\app\comment_content.cvs', 'r', 'utf-8') as csvfile:\
2 content = ''\
3 reader = csv.reader(csvfile)\
4 i =0\
5 for file1 in reader:\
6 if i == 0 or i ==1:\
7 pass\
8 else:\
9 content =content + file1[1]\
10 i = i +1\
11 # Remove extra characters from all comments\
12 content = re.sub('[,,. . \r\n]', '', content)
2 analysis data
# Cut words, break the whole comment into words one by one\
segment = jieba.lcut(content)\
words_df = pd.DataFrame({'segment': segment})\
# quoting=3 means that all contents in stopwords.txt are not referenced\
stopwords = pd.read_csv(r"H:\PyCoding\FlaskCoding\Test_all\test0609\app\stopwords.txt", index_col=False, quoting=3, sep="\t", names=['stopword'], encoding='utf-8')\
words_df = words_df[~words_df.segment.isin(stopwords.stopword)]\
# Calculate the number of repetitions of each word\
words_stat = words_df.groupby(by=['segment'])['segment'].agg({"count": numpy.size})\
words_stat = words_stat.reset_index().sort_values(by=["count"], ascending=False)
3 data visualization
1 test = words_stat.head(1000).values\
# Get all words\
2 words = [test[i][0] for i in range(0,len(test))]\
# Gets the number of occurrences of the word\
3 counts = [test[i][1] for i in range(0,len(test))]\
4wordcloud = WordCloud(width=1300, height=620)\
# Generate word cloud\
5 wordcloud.add("Burst silent", words, counts, word_size_range=[20, 100])\
6 wordcloud.render()
Effect display
