✏️ Editor's note
Every summer, Milvus community will work with the Software Institute of the Chinese Academy of Sciences to prepare rich engineering projects for college students in the "open source summer" activity, and arrange tutors to answer questions and solve doubts. Zhang Yumin performed well in the "open source summer" activity. He believed that he would be happy every inch and tried to surpass himself in the process of contributing to open source.
His project provides precision control for vector query operation of Milvus database, allows developers to customize the return precision, reduces memory consumption and improves the readability of the return results.
Want to learn more about high-quality open source projects and project experience sharing? Please stamp: What open source projects are worth participating in?
Project introduction
Project Name: supports specifying the distance precision returned during search
Student profile: Zhang Yumin, master of electronic information software engineering, University of Chinese Academy of Sciences
Project Supervisor: Zilliz software engineer Zhang Cai
Comments from the tutor: Zhang Yumin optimized the query function of the Milvus database so that it can query with the specified accuracy during the search, making the search process more flexible. Users can query with different accuracy according to their own needs, which brings convenience to users.
Supports specifying the distance precision returned when searching
Mission profile
In the vector query, the search request returns the id and distance fields, where the distance field type is a floating point number. The distance calculated by the Milvus database is a 32-bit floating-point number, but the Python SDK returns and displays it as a 64 bit floating-point number, resulting in some invalid precision. The contribution of this project is to support the distance precision returned during specified search, solve the problem that some precision is invalid when displayed on the Python side, and reduce some memory overhead.
Project objectives
- Solve the problem of mismatch between calculation results and display accuracy
- Supports the return of specified distance precision during search
- Supplement relevant documents
Project steps
- Preliminary research, understand the overall framework of Milvus
- Clarify the calling relationship between modules
- Design solutions and validation results
Project overview
What is? Milvus database
Milvus is an open source vector database that enables AI applications and vector similarity search. In terms of system design, The front end of the Milvus database has a Python SDK (Client) that is convenient for users to use; At the back end of the Milvus database, the whole system is divided into four levels: Access Layer, Coordinator Server, Worker Node and storage service:
(1) Access Layer: the facade of the system, which contains a group of peer-to-peer Proxy nodes. The Access Layer is a unified endpoint exposed to users, which is responsible for forwarding requests and collecting execution results.
(2) Coordinator Service: the brain of the system, which is responsible for assigning tasks to execution nodes. There are four types of coordinator roles: root coordinator, data coordinator, query coordinator and index coordinator.
(3) Worker Node: the limbs of the system. The execution node is only responsible for passively executing the read-write requests initiated by the coordination service. At present, there are three types of execution nodes: data node, query node and index node.
(4) Storage service: the skeleton of the system, which is the basis for the realization of all other functions. Milvus The database relies on three types of storage: metadata storage, message storage (log broker) and object storage. From the perspective of language, it can be regarded as three language layers: SDK layer composed of Python, middle layer composed of Go and core computing layer composed of C + +.
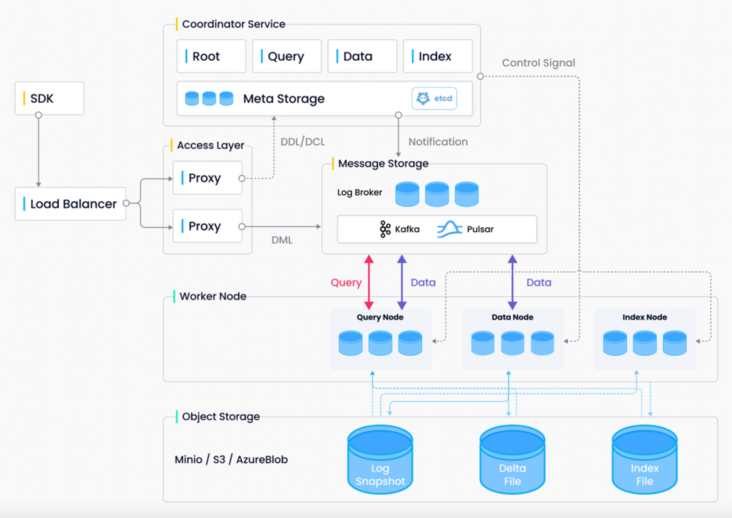
Architecture diagram of Milvus database
What happens when a vector queries Search?
On the Python SDK side, when a user initiates a Search API call, the call will be encapsulated as a gRPC request and sent to the Milvus backend. At the same time, the SDK starts to wait. On the back end, the Proxy node first accepts the request sent from the Python SDK, then processes the received request, and finally encapsulates it into a message and sends it to the consumption queue via the Producer. After the message is sent to the consumption queue, the Coordinator will coordinate it and send the information to the appropriate query node for consumption. When the query node receives the message, it will further process the message, and finally pass the information to the computing layer composed of C + +. In the calculation layer, different calculation functions will be called to calculate the distance between vectors according to different situations. When the calculation is completed, the results will be passed up in turn until they reach the SDK end.
Solution design
Through the previous brief introduction, we have a general concept of the process of vector query. At the same time, we can clearly realize that in order to complete the query target, we need to modify the SDK layer composed of Python, the middle layer composed of Go and the computing layer composed of C + +. The modification scheme is as follows:
1. Modification steps in Python layer:
Add a round for the vector query Search request_ Decimal parameter to determine the returned precision information. At the same time, some validity checks and exception handling need to be performed on the parameters to build gRPC requests:
round_decimal = param_copy("round_decimal", 3)
if not isinstance(round_decimal, (int, str))
raise ParamError("round_decimal must be int or str")
try:
round_decimal = int(round_decimal)
except Exception:
raise ParamError("round_decimal is not illegal")
if round_decimal < 0 or round_decimal > 6:
raise ParamError("round_decimal must be greater than zero and less than seven")
if not instance(params, dict):
raise ParamError("Search params must be a dict")
search_params = {"anns_field": anns_field, "topk": limit, "metric_type": metric_type, "params": params, "round_decimal": round_decimal}
2. Modification steps in Go layer:
Add the constant RoundDecimalKey in the task.go file to keep the style uniform and facilitate subsequent retrieval:
const ( InsertTaskName = "InsertTask" CreateCollectionTaskName = "CreateCollectionTask" DropCollectionTaskName = "DropCollectionTask" SearchTaskName = "SearchTask" RetrieveTaskName = "RetrieveTask" QueryTaskName = "QueryTask" AnnsFieldKey = "anns_field" TopKKey = "topk" MetricTypeKey = "metric_type" SearchParamsKey = "params" RoundDecimalKey = "round_decimal" HasCollectionTaskName = "HasCollectionTask" DescribeCollectionTaskName = "DescribeCollectionTask"
Next, modify the PreExecute function to get round_ Value of decimal, build queryInfo variable, and add exception handling:
searchParams, err := funcutil.GetAttrByKeyFromRepeatedKV(SearchParamsKey, st.query.SearchParams)
if err != nil {
return errors.New(SearchParamsKey + " not found in search_params")
}
roundDecimalStr, err := funcutil.GetAttrByKeyFromRepeatedKV(RoundDecimalKey, st.query.SearchParams)
if err != nil {
return errors.New(RoundDecimalKey + "not found in search_params")
}
roundDeciaml, err := strconv.Atoi(roundDecimalStr)
if err != nil {
return errors.New(RoundDecimalKey + " " + roundDecimalStr + " is not invalid")
}
queryInfo := &planpb.QueryInfo{
Topk: int64(topK),
MetricType: metricType,
SearchParams: searchParams,
RoundDecimal: int64(roundDeciaml),
}At the same time, modify the proto file of query and add round to QueryInfo_ Decimal variable:
message QueryInfo {
int64 topk = 1;
string metric_type = 3;
string search_params = 4;
int64 round_decimal = 5;
}3. Modification steps in C + + layer:
Add a new variable round in the SearchInfo structure\_ decimal\_ , So as to accept the round from the Go layer_ Decimal value:
struct SearchInfo {
int64_t topk_;
int64_t round_decimal_;
FieldOffset field_offset_;
MetricType metric_type_;
nlohmann::json search_params_;
};In the ParseVecNode and PlanNodeFromProto functions, the SearchInfo structure needs to accept the round in the Go layer_ Decimal value:
std::unique_ptr<VectorPlanNode>
Parser::ParseVecNode(const Json& out_body) {
Assert(out_body.is_object());
Assert(out_body.size() == 1);
auto iter = out_body.begin();
auto field_name = FieldName(iter.key());
auto& vec_info = iter.value();
Assert(vec_info.is_object());
auto topk = vec_info["topk"];
AssertInfo(topk > 0, "topk must greater than 0");
AssertInfo(topk < 16384, "topk is too large");
auto field_offset = schema.get_offset(field_name);
auto vec_node = [&]() -> std::unique_ptr<VectorPlanNode> {
auto& field_meta = schema.operator[](field_name);
auto data_type = field_meta.get_data_type();
if (data_type == DataType::VECTOR_FLOAT) {
return std::make_unique<FloatVectorANNS>();
} else {
return std::make_unique<BinaryVectorANNS>();
}
}();
vec_node->search_info_.topk_ = topk;
vec_node->search_info_.metric_type_ = GetMetricType(vec_info.at("metric_type"));
vec_node->search_info_.search_params_ = vec_info.at("params");
vec_node->search_info_.field_offset_ = field_offset;
vec_node->search_info_.round_decimal_ = vec_info.at("round_decimal");
vec_node->placeholder_tag_ = vec_info.at("query");
auto tag = vec_node->placeholder_tag_;
AssertInfo(!tag2field_.count(tag), "duplicated placeholder tag");
tag2field_.emplace(tag, field_offset);
return vec_node;
}std::unique_ptr<VectorPlanNode>
ProtoParser::PlanNodeFromProto(const planpb::PlanNode& plan_node_proto) {
// TODO: add more buffs
Assert(plan_node_proto.has_vector_anns());
auto& anns_proto = plan_node_proto.vector_anns();
auto expr_opt = [&]() -> std::optional<ExprPtr> {
if (!anns_proto.has_predicates()) {
return std::nullopt;
} else {
return ParseExpr(anns_proto.predicates());
}
}();
auto& query_info_proto = anns_proto.query_info();
SearchInfo search_info;
auto field_id = FieldId(anns_proto.field_id());
auto field_offset = schema.get_offset(field_id);
search_info.field_offset_ = field_offset;
search_info.metric_type_ = GetMetricType(query_info_proto.metric_type());
search_info.topk_ = query_info_proto.topk();
search_info.round_decimal_ = query_info_proto.round_decimal();
search_info.search_params_ = json::parse(query_info_proto.search_params());
auto plan_node = [&]() -> std::unique_ptr<VectorPlanNode> {
if (anns_proto.is_binary()) {
return std::make_unique<BinaryVectorANNS>();
} else {
return std::make_unique<FloatVectorANNS>();
}
}();
plan_node->placeholder_tag_ = anns_proto.placeholder_tag();
plan_node->predicate_ = std::move(expr_opt);
plan_node->search_info_ = std::move(search_info);
return plan_node;
}Add a new member variable round in the SubSearchResult class_ Decimal, and modify the SubSearchResult variable declaration at each place at the same time:
class SubSearchResult {
public:
SubSearchResult(int64_t num_queries, int64_t topk, MetricType metric_type)
: metric_type_(metric_type),
num_queries_(num_queries),
topk_(topk),
labels_(num_queries * topk, -1),
values_(num_queries * topk, init_value(metric_type)) {
}Add a new member function in the SubSearchResult class to control the rounding accuracy of each result:
void
SubSearchResult::round_values() {
if (round_decimal_ == -1)
return;
const float multiplier = pow(10.0, round_decimal_);
for (auto it = this->values_.begin(); it != this->values_.end(); it++) {
*it = round(*it * multiplier) / multiplier;
}
}Add a new variable round for the SearchDataset structure_ Decimal, and modify the SearchDataset variable declaration at each place at the same time:
struct SearchDataset {
MetricType metric_type;
int64_t num_queries;
int64_t topk;
int64_t round_decimal;
int64_t dim;
const void* query_data;
};Modification C++ Each distance calculation function in the layer (FloatSearch, BinarySearchBruteForceFast, etc.) makes it accept round_decomal value:
Status
FloatSearch(const segcore::SegmentGrowingImpl& segment,
const query::SearchInfo& info,
const float* query_data,
int64_t num_queries,
int64_t ins_barrier,
const BitsetView& bitset,
SearchResult& results) {
auto& schema = segment.get_schema();
auto& indexing_record = segment.get_indexing_record();
auto& record = segment.get_insert_record();
// step 1: binary search to find the barrier of the snapshot
// auto del_barrier = get_barrier(deleted_record_, timestamp);
#if 0
auto bitmap_holder = get_deleted_bitmap(del_barrier, timestamp, ins_barrier);
Assert(bitmap_holder);
auto bitmap = bitmap_holder->bitmap_ptr;
#endif
// step 2.1: get meta
// step 2.2: get which vector field to search
auto vecfield_offset = info.field_offset_;
auto& field = schema[vecfield_offset];
AssertInfo(field.get_data_type() == DataType::VECTOR_FLOAT, "[FloatSearch]Field data type isn't VECTOR_FLOAT");
auto dim = field.get_dim();
auto topk = info.topk_;
auto total_count = topk * num_queries;
auto metric_type = info.metric_type_;
auto round_decimal = info.round_decimal_;
// step 3: small indexing search
// std::vector<int64_t> final_uids(total_count, -1);
// std::vector<float> final_dis(total_count, std::numeric_limits<float>::max());
SubSearchResult final_qr(num_queries, topk, metric_type, round_decimal);
dataset::SearchDataset search_dataset{metric_type, num_queries, topk, round_decimal, dim, query_data};
auto vec_ptr = record.get_field_data<FloatVector>(vecfield_offset);
int current_chunk_id = 0;SubSearchResult
BinarySearchBruteForceFast(MetricType metric_type,
int64_t dim,
const uint8_t* binary_chunk,
int64_t size_per_chunk,
int64_t topk,
int64_t num_queries,
int64_t round_decimal,
const uint8_t* query_data,
const faiss::BitsetView& bitset) {
SubSearchResult sub_result(num_queries, topk, metric_type, round_decimal);
float* result_distances = sub_result.get_values();
idx_t* result_labels = sub_result.get_labels();
int64_t code_size = dim / 8;
const idx_t block_size = size_per_chunk;
raw_search(metric_type, binary_chunk, size_per_chunk, code_size, num_queries, query_data, topk, result_distances,
result_labels, bitset);
sub_result.round_values();
return sub_result;
}Result confirmation
1. Recompile the Milvus database:
2. Start environment container:

3. Start the Milvus database:

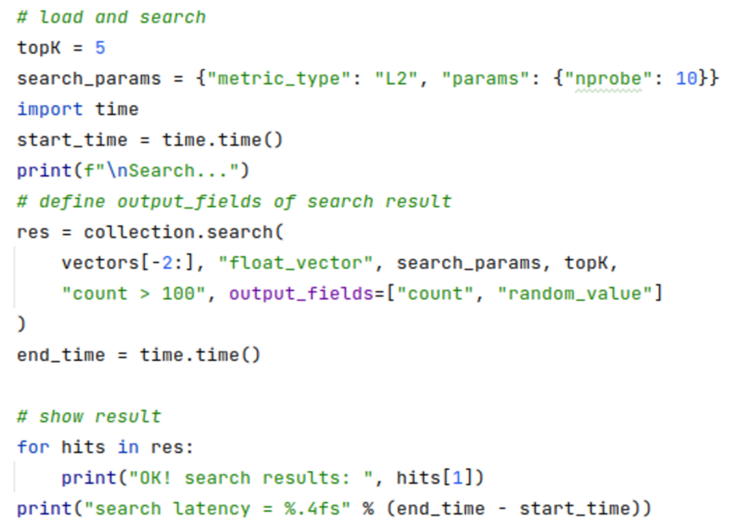
4. Build vector query request:
5. Confirm the result. 3 decimal places are reserved by default, and 0 is rounded off:

Summary and feelings
Participating in this summer open source activity is a very valuable experience for me. In this activity, I tried to read the open source project code for the first time, I tried to contact multi language projects for the first time, and I came into contact with Make, gRPc, pytest and so on. In the stage of writing and testing code, I also encountered many unexpected problems, such as "strange" dependency, compilation failure caused by Conda environment, failure of test, etc. Facing these problems, I gradually learned to patiently and carefully check the error log, actively think, check the code and test, narrow the error range step by step, locate the error code and try various solutions.
Through this activity, I have learned many experiences and lessons. At the same time, I am also very grateful to mentor Zhang Cai for patiently helping me answer questions, solve doubts and guide the direction in the process of my development! At the same time, I hope you can pay more attention to the Milvus community and I believe you will gain something!
Finally, welcome to communicate with me( 📮 deepmin@mail.deepexplore.top ), My main research direction is natural language processing. I usually like to read science fiction, animation and toss server personal websites, and stroll around Stack Overflow and GitHub every day. I believe there is joy in every inch, and I hope to make progress with you.