
This article is for those who have deeply understood the mathematical principles and operation process of RNN, LSTM and GRU. If they do not understand its basic idea and process, it may not be very simple to understand.
1, Let's start with an example
This is an example on the official website. Taking LSTM as an example this time, in fact, the operation process of GRU, LSTM and RNN is very similar.
Later, I will explain the above operation process in detail. Let's take a look at the definition of LSTM, which is a class
2, Definition of LSTM class
The above parameters are a little too many. I won't translate them one by one. In fact, they are very easy to understand. Each of them is relatively clear.
3, In depth understanding of required parameters
1. The three parameters of the constructors of RNN, GRU and LSTM must be understood -- step 1: construct the loop layer object
When creating a circular layer, the first step is to construct a circular layer, as follows:
lstm = nn.LSTM(10, 20, 2)
The parameter list of the constructor is as follows:
(1)input_size: refers to the characteristic dimension of each word. For example, if I have a sentence in which each word is represented by a 10-dimensional vector, then input_size is 10;
(2)hidden_size: refers to the number of hidden nodes of each LSTM internal unit in the loop layer. This is self-defined and can be set arbitrarily;
(3)num_layers: the number of layers of the circular layer. The default is one layer. This depends on your own situation.
For example:
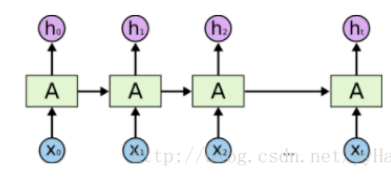
There is only one circular layer on the left and two circular layers on the right.
2. Construct the forward propagation process through the object constructed in the first step - step 2: call the loop layer object, pass in parameters, and get the return value
The general operations are as follows:
output, (hn, cn) = lstm(input, (h0, c0))
Take LSTM as an example,
(1) Input parameters
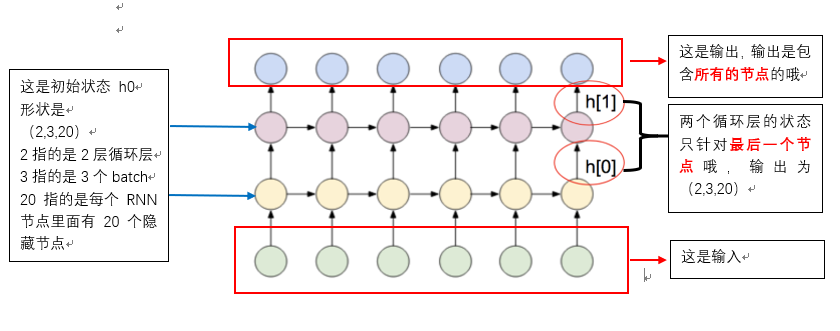
Input: must be in this format (seq,batch,feature). The first seq refers to the length of the sequence, which is determined according to my own data. For example, the maximum length of my sentence is 20 words, so here is 20. The above example assumes that the sentence length is 5; The second is batch, which is easy to understand. It is to use several samples at a time, such as three groups of samples; The third feature refers to the vector dimension of each word. It should be noted that this must be consistent with the first parameter input of the constructor_ The size remains the same. In the above example, it is 10
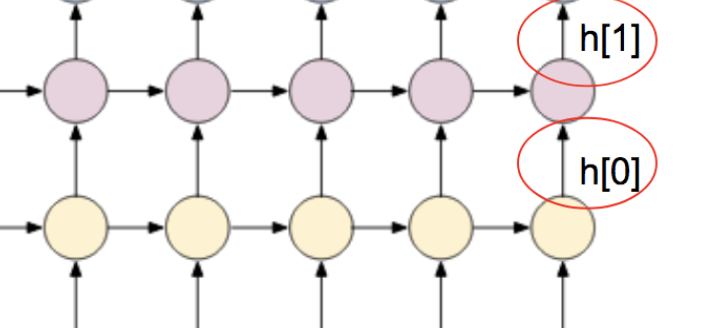
(h0,c0): refers to the initial state of each cycle layer. It can be initialized to 0 without specifying. Here, because LSTM has two states to be transferred, there are two. For example, if ordinary RNN and GRU have only one state to be transferred, only one h state needs to be transferred, as shown below:
It should be noted here that the dimension of the passed in status parameter is still in terms of LSTM:
The data dimensions of h0 and c0 are (num_layers * num_directions, batch, hidden_size). What does this mean?
First num_layer refers to the base circulating layer. It is easy to understand that several layers should have several initial states;
Second num_directions refers to whether the loop layer is bidirectional (specified by the bidirectional parameter in the constructor). If it is not bidirectional, the value is 1; if it is bidirectional, the value is 2;
The third batch refers to the batch of each data, which can be consistent with the previous batch;
Last hidden_size refers to the number of hidden nodes in each node of the loop layer. This requires a good understanding of the whole operation process of the loop neural network!
(2) Output results
In fact, the output results match the input results, as follows:
In terms of lstm:
The output dimension of output: (seq_len, batch, num_directions * hidden_size). In the above example, it should be (5,3,20). We verified that it is true. It should be noted that the first dimension is SEQ_ Len, that is, the output at each time point is the output result, which is different from the hidden layer;
The output dimensions of hn and cn are (num_layers * num_directions, batch, hidden_size) and (2,3,20) in the above example, which have also been verified. We find that this is consistent with the sequence length seq_len doesn't matter. Why? The output state only refers to the output state of the last loop layer node.
As shown in the figure below:
The following example is drawn with an ordinary RNN, so there is only one state h and no state c.
3. Several important attributes are understood
Whether it is RNN, GRU or lstm, the internal learnable parameters are actually several weight matrices, including offset matrices. How do you view these learned parameters? It is realized through these matrices
(1)weight_ih_l[k]: This represents the weight matrix input between hidden layers, where K represents the cycle layer,
If K=0, it represents the matrix from the lowest input layer to the first cycle layer, and the dimension is (hidden_size, input_size). If k > 0, it represents the weight matrix from the first cycle layer to the second cycle layer, the second cycle layer to the third cycle layer, and so on. The shape is (hidden_size, num_directions * hidden_size).
(2)weight_hh_l[k]: refers to the weight matrix between the circulating layers. Here, K refers to the circulating layer, and the values are 0,1,2,3,4. Shape is (hidden_size, hidden_size)
Note: the number of layers of the circulating layer starts from 0, 0 represents the first circulating layer, 1 represents the second circulating layer, and so on.
(3)bias_ih_l[k]: the offset item of the kth cycle layer, which represents the offset input to the cycle layer, and the dimension is (hidden_size)
(4)bias_hh_l[k]: the offset item of the kth cycle layer represents the offset from the cycle layer to the interior of the cycle layer, and the dimension is (hidden_size).
As like as two peas, we found the result is exactly the same as the one described.
Reference article:
https://blog.csdn.net/lwgkzl/article/details/88717678
https://blog.csdn.net/rogerfang/article/details/84500754
https://blog.csdn.net/qq_27825451/article/details/99691258