1, Serial connection
Prepare two USB to TTLS and several DuPont cables, cross connect the RX and TX pins of the two USB to TTLS, and connect the two USB interfaces to a laptop (simulate the serial port transmission between the two computers).
2, Transfer file
Using the serial port debugging assistant that can transfer files (I use SSCOM V5.13.1 here), open two windows, and each window opens a serial port (two serial ports generated by USB TO TTL connection). You can see the serial ports COM4 and COM5 here
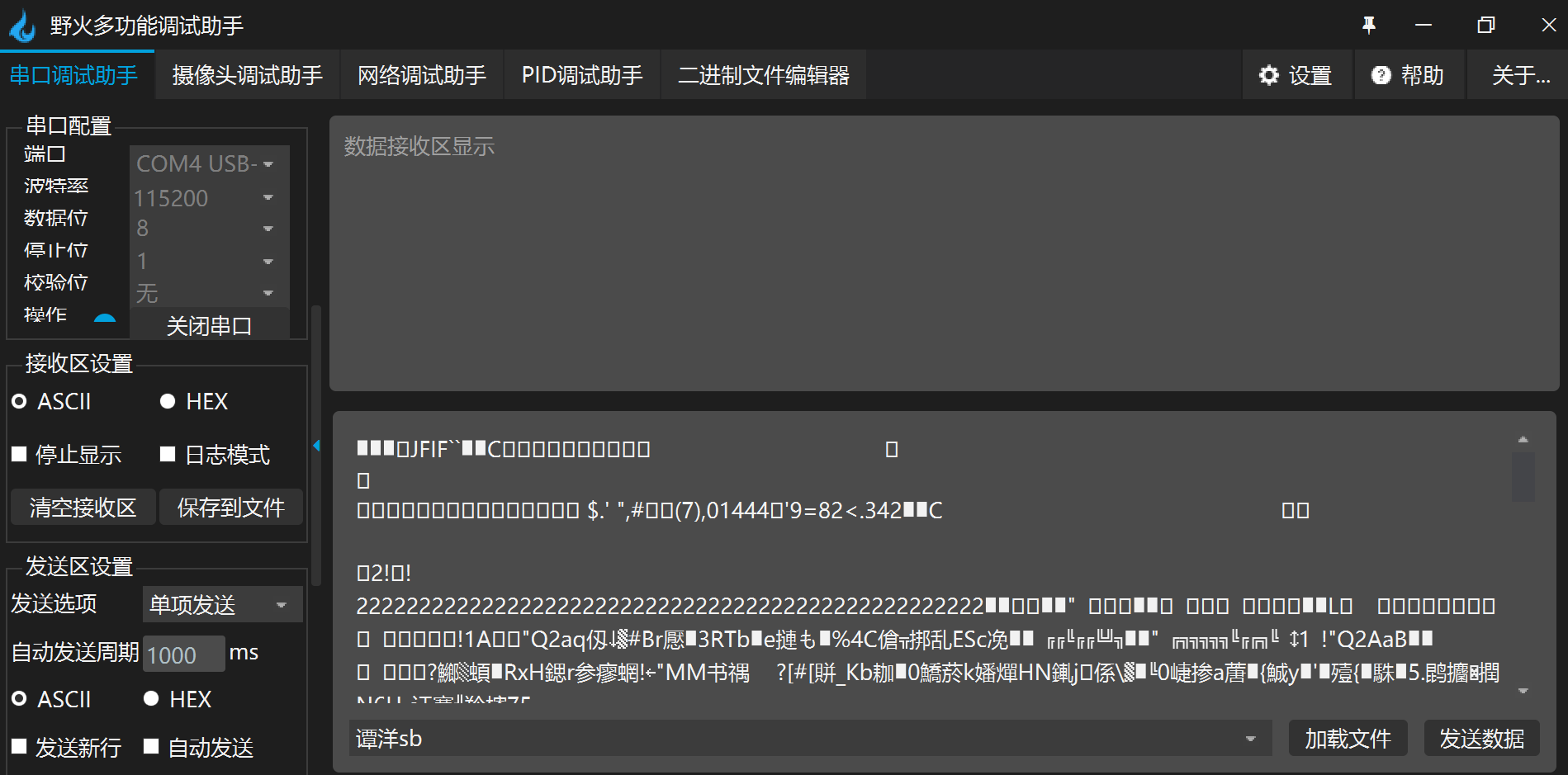
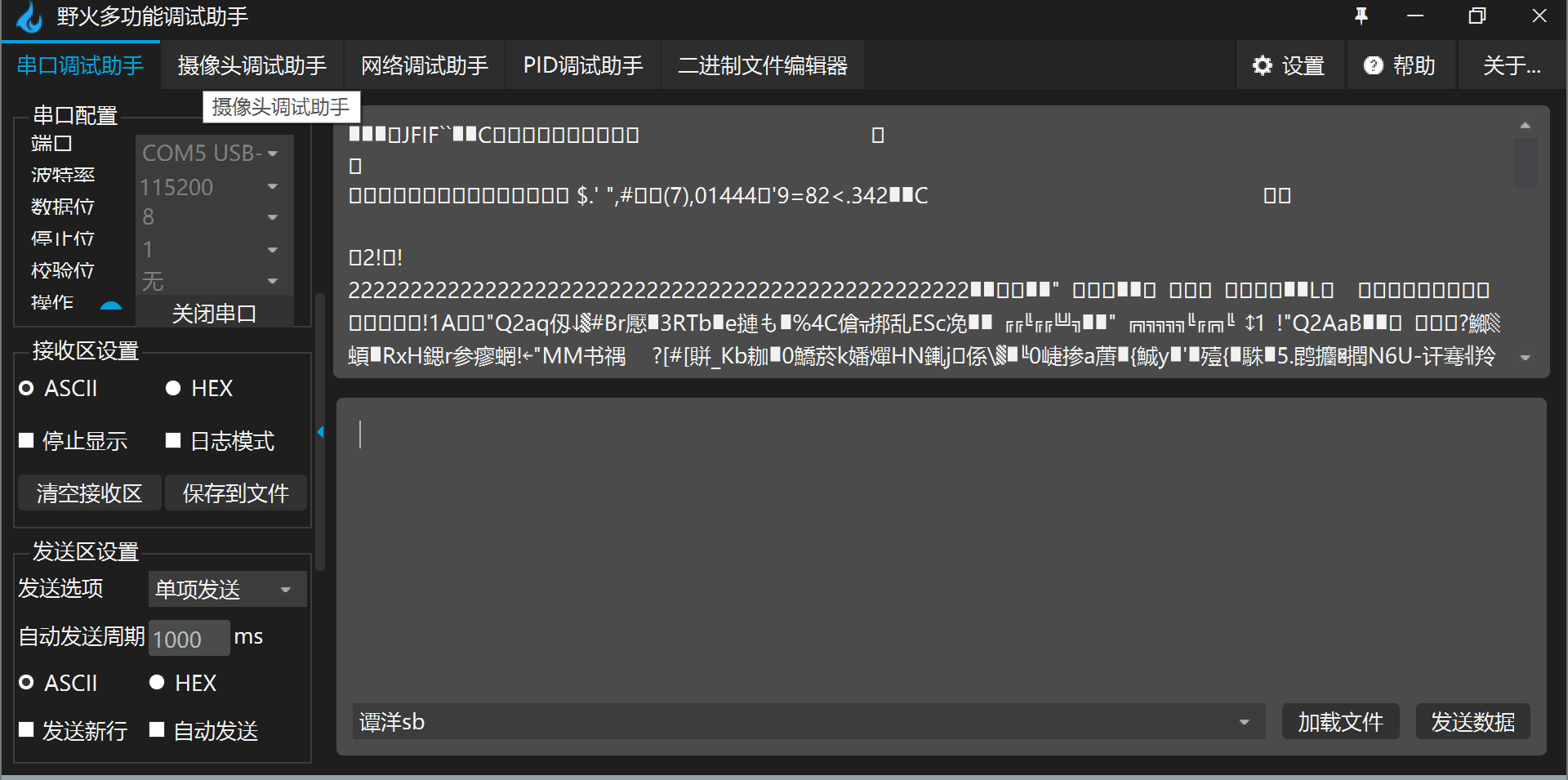
The baud rate selected here is 115200, data bit 8, stop bit 1 and no check bit.
Click load file, select the picture prepared in advance, and click send data, as shown in the figure above.
Through experiments, it is found that in a certain range, when the baud rate increases, the transmission time will be reduced for files of the same size. When it exceeds this range, the impact of baud rate on transmission time will be reduced.
Learning Chinese character dot matrix for Ubuntu+OpenCV
3, Principle of Chinese character lattice font
1. Chinese character coding
(1) Location code: it is stipulated in the national standard GD2312-80 that all national standard Chinese characters and symbols are allocated in a square matrix with 94 rows and 94 columns. Each row of the square matrix is called an "area", numbered from 01 to 94, and each column is called a "bit", numbered from 01 to 94, The area code and tag number of each Chinese character and symbol in the square array are combined to form four Arabic numerals, which are their "location code". The first two digits of the location code are its area code and the last two digits are its bit code. A Chinese character or symbol can be uniquely determined by location code. Conversely, any Chinese character or symbol also corresponds to a unique location code. The location code of the Chinese character "mother" is 3624, indicating that it is 24 digits in area 36 of the square matrix. If the location code of the question mark "?" is 0331, it is 3l digits in area 03.
(2) Internal code: the internal code of Chinese characters refers to the code representing a Chinese character in the computer. The internal code is slightly different from the location code. As mentioned above, the area code and bit code of Chinese location code are between 1 ~ 94. If the location code is directly used as the internal code, it will be confused with the basic ASCII code. In order to avoid the conflict between the internal code and the basic ASCII code, it is necessary to avoid the control code (00H~1FH) in the basic ASCII code and distinguish it from the characters in the basic ASCII code. In order to achieve these two points, 20H can be added to the area code and bit code respectively, and 80h can be added on this basis (here "H" means that the first two digits are hexadecimal numbers). After these processes, it takes two bytes to represent a Chinese character with internal code, which are called high byte and low byte respectively. The internal code of these two bytes is represented according to the following rules:
High byte = area code + 20h + 80h (or area code + A0H)
Low byte = bit code + 20h + 80h (or bit code + AOH)
Since the hexadecimal numbers in the value range of area code and bit code of Chinese characters are 01h ~ 5eh (i.e. 01 ~ 94 in decimal system), the value range of high-order byte and low-order byte of Chinese characters is A1H ~ FEH (i.e. 161 ~ 254 in decimal system). For example, the location code of the Chinese character "ah" is 1601, and the area code and bit code are expressed in hexadecimal respectively, that is, 1001H. The high byte of its internal code is B0H, the low byte is A1H, and the internal code is B0A1H.
2 dot matrix font structure
(1) Lattice font storage
In the dot matrix font of Chinese characters, each bit of each byte represents a point of a Chinese character. Each Chinese character is composed of a rectangular dot matrix. 0 represents no and 1 represents a point. Draw 0 and 1 in different colors to form a Chinese character. There are three commonly used dot matrix font types: 1212, 1414 and 16 * 16. The font can be divided into horizontal matrix and vertical matrix according to the different points represented by bytes. At present, most font libraries are stored in horizontal matrix (the most used should be the early UCDOS font library). The vertical matrix is generally because some LCD adopts the vertical scanning display method. In order to improve the display speed, the font matrix is made into vertical matrix, Save matrix conversion when displaying. What we describe next refers to the horizontal matrix font.
(2) 16 × 16 dot matrix font
For the 1616 matrix, the number of bits required is 1616 = 256 bits, and each byte is 8 bits. Therefore, each Chinese character needs to be represented by 256 / 8 = 32 bytes. That is, every two bytes represent 16 points in a line, and a total of 16 lines are required. When displaying Chinese characters, you only need to read 32 bytes at one time and print every two bytes as a line to form a Chinese character. The lattice structure is shown in the figure below:
[the external chain image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-ny3w4idt-1636108573997) (C: \ users \ 28205 \ appdata \ roaming \ typora user images \ image-20211104185708908. PNG)]
(3) 14 × 14 and 12 × 12 dot matrix font
For 14 × 14 and 12 × 12. Theoretically, the dot matrices they need are (14) respectively × 14/8)=25, (12 × 12 / 8) = 18 bytes. However, if it is stored in this way, when taking and displaying the dot matrix, because each line of them is not an integer of 8, it will involve the calculation and processing of the dot matrix, increase the complexity of the program and reduce the efficiency of the program. In order to solve this problem, some dot matrix font libraries will × 14 and 12 × 12 font press 16 × 14 and 16 × 12, that is, each line is still stored in two bytes, but 14 × 14 font, the last two bits of every two bytes are not used, 12 × 12 bytes, the last four bits of every two bytes are not used. This will have different processing methods according to different word libraries, so pay attention to this problem when using word libraries, especially 14 × 14's font.
3. Chinese character dot matrix acquisition
(1) Using location code to obtain Chinese characters
The Chinese character dot matrix font is stored according to the sequence of location codes. Therefore, we can obtain the dot matrix of a font according to location. Its calculation formula is as follows:
Lattice start position = ((area code - 1) × 94 + (bit code – 1)) × Number of Chinese character dot matrix bytes
After obtaining the starting position of the dot matrix, we can read and take out the dot matrix of a Chinese character from this position.
(2) Acquiring Chinese characters by using Chinese character internal code
The relationship between location code and internal code of Chinese characters is as follows:
High byte of internal code = area code + 20h + 80h (or area code + A0H)
Low byte of internal code = bit code + 20h + 80h (or bit code + AOH)
Conversely, we can also obtain the location code according to the internal code:
Area code = high byte of internal code - A0H
Bit code = low byte of internal code - AOH
By combining this formula with the formula for obtaining the Chinese character dot matrix, the position of the Chinese character dot matrix can be obtained.
4, Chinese character display
1. Project
(1) Open ubuntu and create a new folder to store codes, pictures, 24 dot matrix. hz files and ASCII. zf files
Chinese dot matrix font library and display tools
Extraction code: 2000
(2) Paste the picture, 24 dot matrix. hz file, ASCII code. zf file and logo.txt into this path
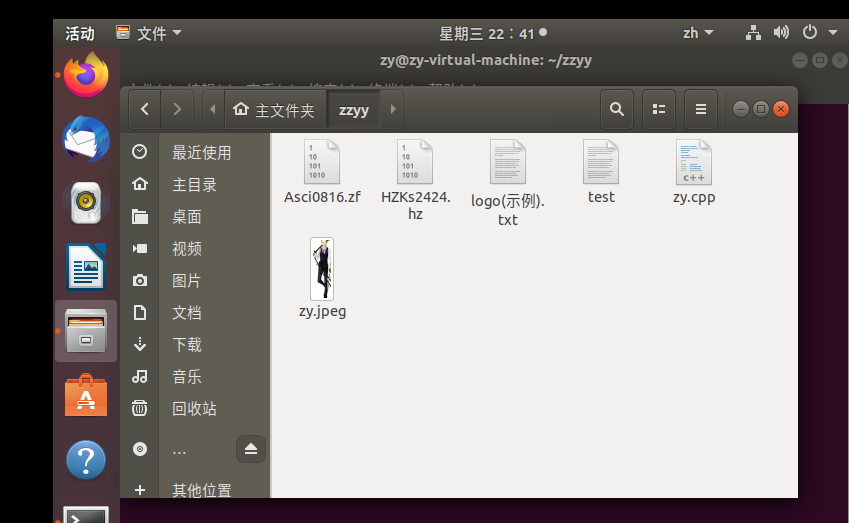
(3) Create a zy.cpp file under zzyy
#include<iostream>
#include<opencv/cv.h>
#include"opencv2/opencv.hpp"
#include<opencv/cxcore.h>
#include<opencv/highgui.h>
#include<math.h>
using namespace cv;
using namespace std;
void paint_chinese(Mat& image,int x_offset,int y_offset,unsigned long offset);
void paint_ascii(Mat& image,int x_offset,int y_offset,unsigned long offset);
void put_text_to_image(int x_offset,int y_offset,String image_path,char* logo_path);
int main(){
String image_path="zy.jpeg";//Picture path
char* logo_path=(char*)"logo.txt";//Student ID name path
put_text_to_image(20,300,image_path,logo_path);
return 0;
}
void paint_ascii(Mat& image,int x_offset,int y_offset,unsigned long offset){
//Coordinates of the starting point of the drawing
Point p;
p.x = x_offset;
p.y = y_offset;
//Storing ascii word film
char buff[16];
//Open ascii font file
FILE *ASCII;
if ((ASCII = fopen("Asci0816.zf", "rb")) == NULL){
printf("Can't open ascii.zf,Please check the path!");
//getch();
exit(0);
}
fseek(ASCII, offset, SEEK_SET);
fread(buff, 16, 1, ASCII);
int i, j;
Point p1 = p;
for (i = 0; i<16; i++) //Sixteen char s
{
p.x = x_offset;
for (j = 0; j < 8; j++) //One char and eight bit s
{
p1 = p;
if (buff[i] & (0x80 >> j)) /*Test whether the current bit is 1*/
{
/*
Because the original ascii word film was 8 * 16, it was not large enough,
So the original pixel is replaced by four pixels,
After replacement, there are 16 * 32 pixels
ps: I think it's unnecessary to write code like this, but I only think of this method for the time being
*/
circle(image, p1, 0, Scalar(0, 0, 255), -1);
p1.x++;
circle(image, p1, 0, Scalar(0, 0, 255), -1);
p1.y++;
circle(image, p1, 0, Scalar(0, 0, 255), -1);
p1.x--;
circle(image, p1, 0, Scalar(0, 0, 255), -1);
}
p.x+=2; //One pixel becomes four, so x and y should both be + 2
}
p.y+=2;
}
}
void paint_chinese(Mat& image,int x_offset,int y_offset,unsigned long offset){//Draw Chinese characters on the picture
Point p;
p.x=x_offset;
p.y=y_offset;
FILE *HZK;
char buff[72];//72 bytes for storing Chinese characters
if((HZK=fopen("HZKs2424.hz","rb"))==NULL){
printf("Can't open HZKf2424.hz,Please check the path!");
exit(0);//sign out
}
fseek(HZK, offset, SEEK_SET);/*Move the file pointer to the offset position*/
fread(buff, 72, 1, HZK);/*Read 72 bytes from the offset position, and each Chinese character occupies 72 bytes*/
bool mat[24][24];//Define a new matrix to store the transposed text film
int i,j,k;
for (i = 0; i<24; i++) /*24x24 Dot matrix Chinese characters, a total of 24 lines*/
{
for (j = 0; j<3; j++) /*There are 3 bytes in the horizontal direction, and the value of each byte is determined by cycle*/
for (k = 0; k<8; k++) /*Each byte has 8 bits, and the loop judges whether each byte is 1*/
if (buff[i * 3 + j] & (0x80 >> k)) /*Test whether the current bit is 1*/
{
mat[j * 8 + k][i] = true; /*1 is stored in a new word film*/
}
else {
mat[j * 8 + k][i] = false;
}
}
for (i = 0; i < 24; i++)
{
p.x = x_offset;
for (j = 0; j < 24; j++)
{
if (mat[i][j])
circle(image, p, 1, Scalar(255, 0, 0), -1); //Write (replace) pixels
p.x++; //Shift right one pixel
}
p.y++; //Move down one pixel
}
}
void put_text_to_image(int x_offset,int y_offset,String image_path,char* logo_path){//Put Chinese characters on the picture
//x and y are the starting coordinates of the first word on the picture
//Get pictures through picture path
Mat image=imread(image_path);
int length=18;//Length of characters to print
unsigned char qh,wh;//Define area code and tag number
unsigned long offset;//Offset
unsigned char hexcode[30];//Hexadecimal used to store Notepad reading. Remember to use unsigned
FILE* file_logo;
if ((file_logo = fopen(logo_path, "rb")) == NULL){
printf("Can't open txtfile,Please check the path!");
//getch();
exit(0);
}
fseek(file_logo, 0, SEEK_SET);
fread(hexcode, length, 1, file_logo);
int x =x_offset,y = y_offset;//x. Y: the starting coordinate of the text drawn on the picture
for(int m=0;m<length;){
if(hexcode[m]==0x23){
break;//It ends when the # number is read
}
else if(hexcode[m]>0xaf){
qh=hexcode[m]-0xaf;//The font used starts with Chinese characters, not Chinese symbols
wh=hexcode[m+1] - 0xa0;//Calculation bit code
offset=(94*(qh-1)+(wh-1))*72L;
paint_chinese(image,x,y,offset);
/*
Calculate the offset in the Chinese character library
Each Chinese character is represented by a 24 * 24 dot matrix
A line has three bytes, a total of 24 lines, so 72 bytes are required
Such as Zhao Zi
The location code is 5352
Hex bit 3534
The internal code is d5d4
d5-af=38(Decimal), because it starts with Chinese characters, ah, so it subtracts af instead of a0. 38 + 15 equals 53, which corresponds to the area code
d4-a0=52
*/
m=m+2;//The internal code of a Chinese character occupies two bytes,
x+=24;//A Chinese character has 24 * 24 pixels. Because it is placed horizontally, it moves 24 pixels to the right
}
else{//When the read character is ASCII
wh=hexcode[m];
offset=wh*16l;//Calculate the offset of English characters
paint_ascii(image,x,y,offset);
m++;//English characters only occupy one byte in the file, so just move back one bit
x+=16;
}
}
cv::imshow("image", image);
cv::waitKey();
}
Compile run
g++ test.cpp -o test `pkg-config --cflags --libs opencv`
./test
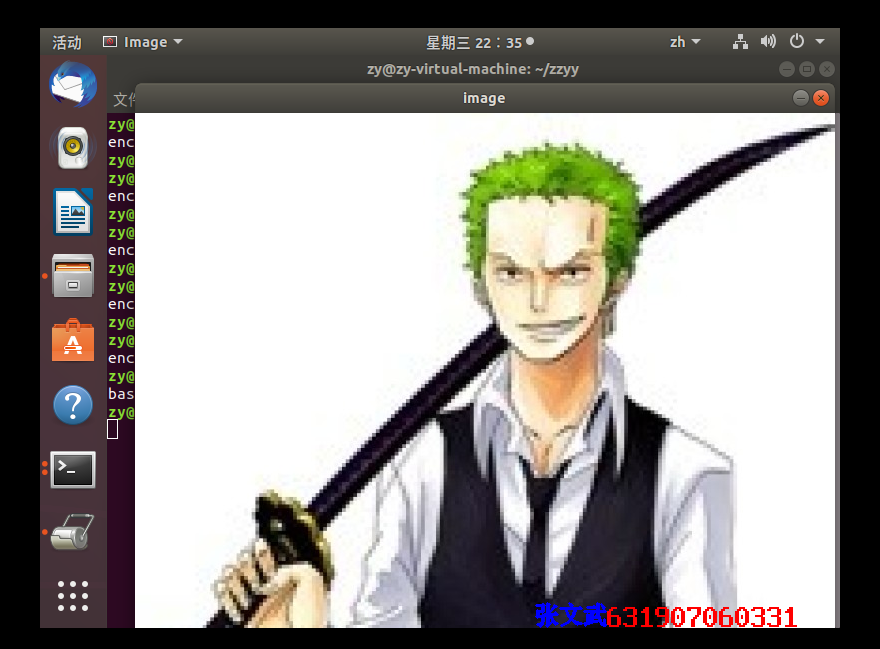
result:
5, References
https://blog.csdn.net/qq_55691662/article/details/121213716