catalogue
HA high availability deployment
Hbase installation and deployment
Unzip the installation package
Test whether Sqoop can successfully connect to the database
kafka installation and deployment
Unzip the installation package
Unzip the installation package
Configure environment variables
Configure flume and kafka connections
spark installation and deployment
preface
Prepare for the 2021 "Hubei craftsman Cup" skill competition - big data technology application competition. Attach the data link. Please correct any mistakes. Relevant articles are written in the blog, you can refer to.

data
Link: https://pan.baidu.com/s/162xqYRVSJMy_cKVlWT4wjQ
Extraction code: yikm
HA high availability deployment
Please move HA high availability architecture , refer to the article to complete HA high availability deployment.
Hive installation deployment
Please move Construction of data warehouse game analysis , refer to the article to complete Hive installation and deployment.
Hbase installation and deployment
Please move HBASE installation , refer to the article to complete the Hbase installation and deployment.
Note: hbase-site.xml file
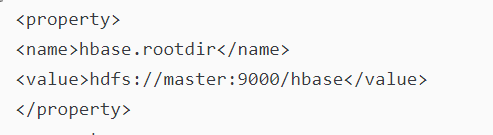 :
:
master:9000 should be changed to mycluster

sqoop installation deployment
Unzip the installation package
mkdir /usr/sqoop tar -zxvf /usr/package/sqoop-1.4.7.bin.tar.gz -C /usr/sqoop/
Modify profile
environment variable
vim /etc/profile
add to:
#sqoop export SQOOP_HOME=/usr/sqoop/sqoop-1.4.7.bin export PATH=$PATH:$SQOOP_HOME/bin
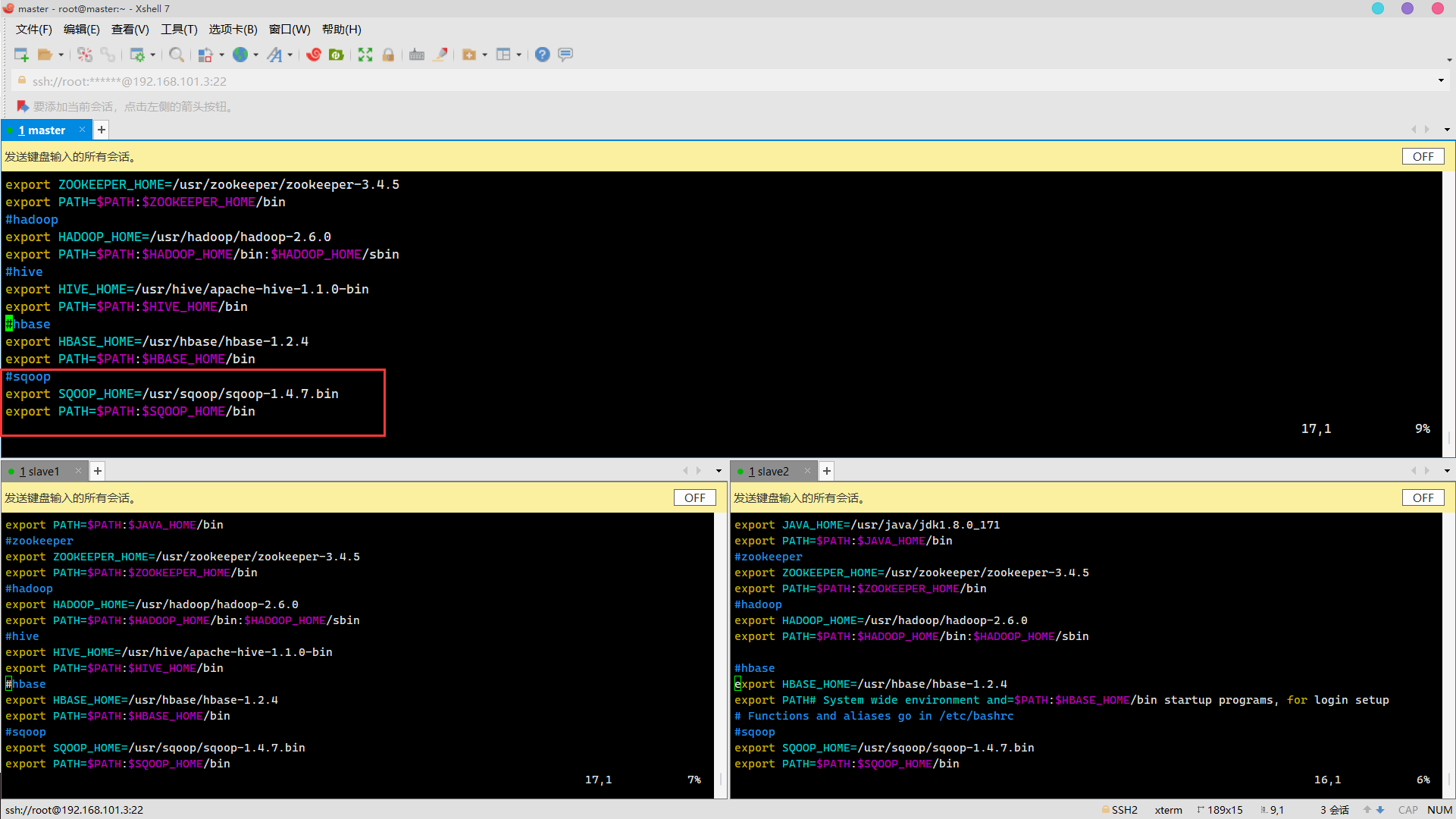
Effective environment variable
source /etc/profile
see
sqoop version
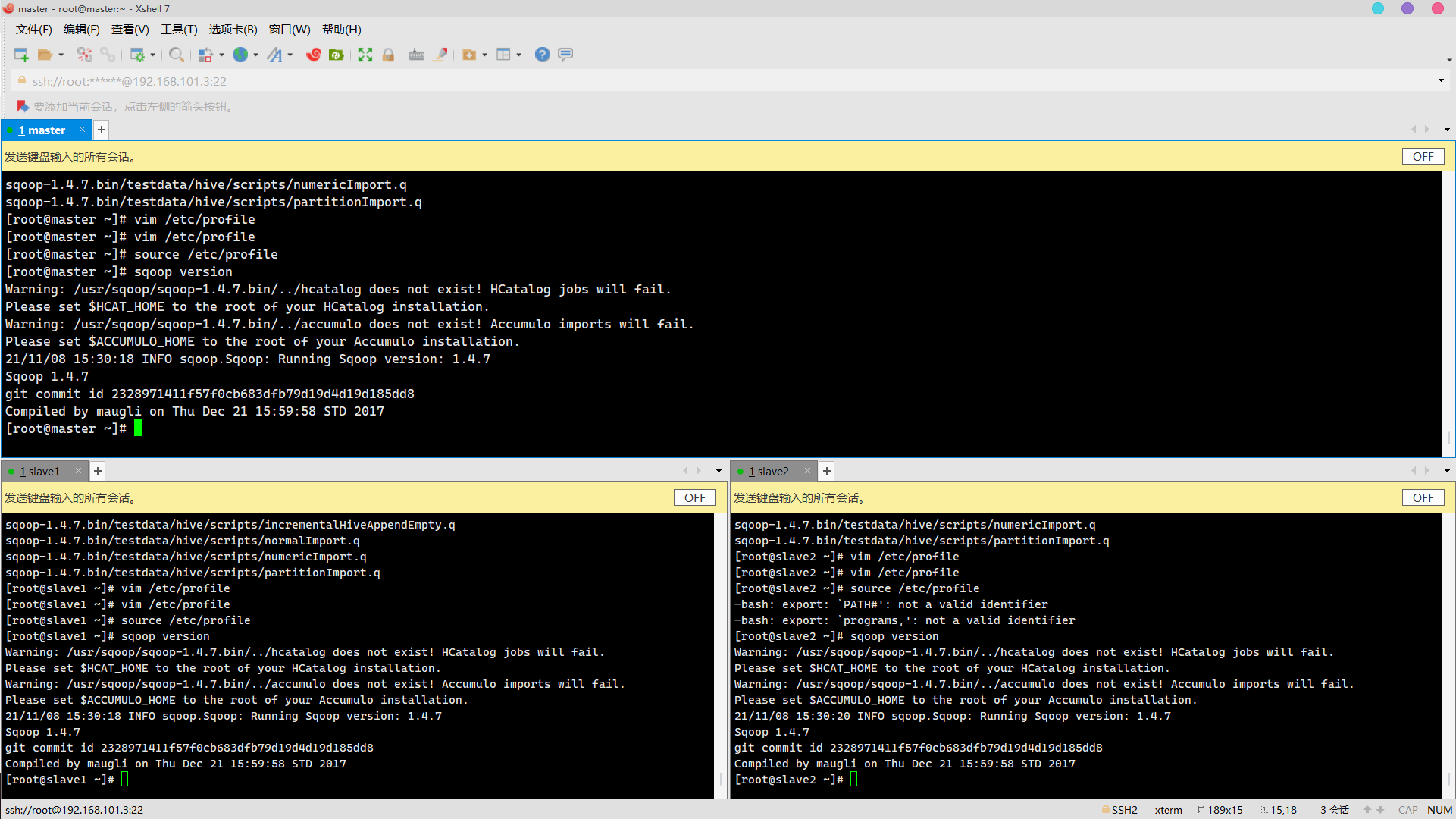
sqoop-env.sh
cd /usr/sqoop/sqoop-1.4.7.bin/conf/ mv sqoop-env-template.sh sqoop-env.sh echo "export HADOOP_COMMON_HOME=/usr/hadoop/hadoop-2.6.0 export HADOOP_MAPRED_HOME=/usr/hadoop/hadoop-2.6.0 export HIVE_HOME=/usr/hive/apache-hive-1.1.0-bin export ZOOKEEPER_HOME=/usr/zookeeper/zookeeper-3.4.5 export ZOOCFGDIR=/usr/zookeeper/zookeeper-3.4.5" >> sqoop-env.sh cat sqoop-env.sh
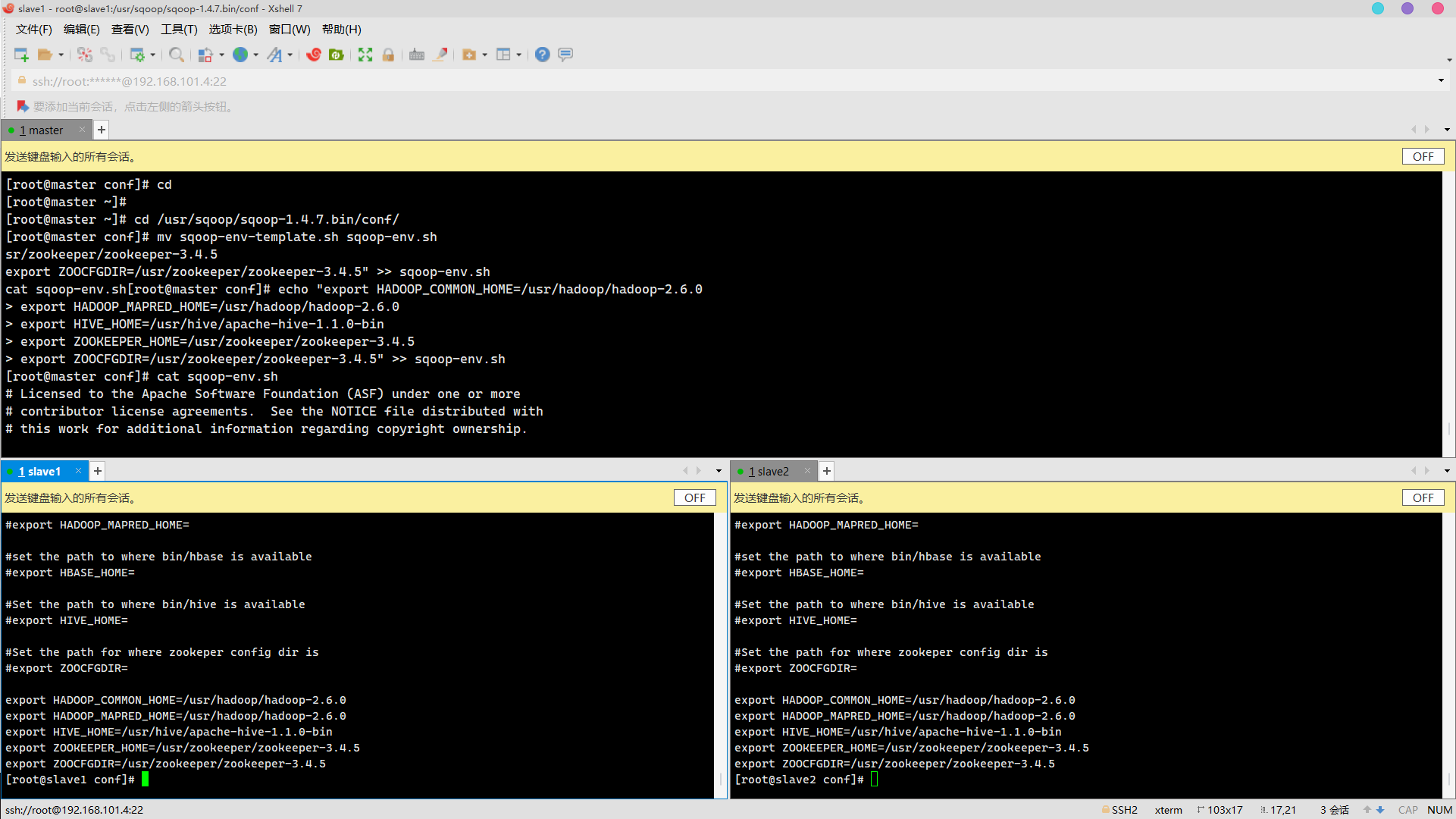
Copy JDBC Driver
cp /usr/package/mysql-connector-java-5.1.47-bin.jar /usr/sqoop/sqoop-1.4.7.bin/lib/
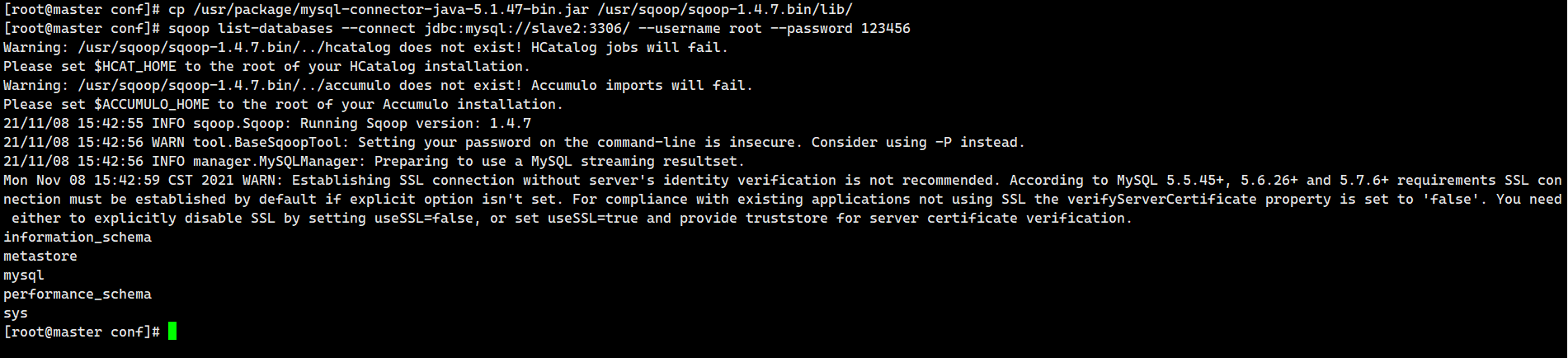
Test whether Sqoop can successfully connect to the database
My cluster uses slave2 as the storage database.
sqoop list-databases --connect jdbc:mysql://slave2:3306/ --username root --password 123456
kafka installation and deployment
Unzip the installation package
mkdir /usr/kafka tar -zxvf /usr/package/kafka_2.11-1.0.0.tgz -C /usr/kafka/
environment variable
vim /etc/profile
add to:
#kafka export KAFKA_HOME=/usr/kafka/kafka_2.11-1.0.0 export PATH=$PATH:$KAFKA_HOME/bin
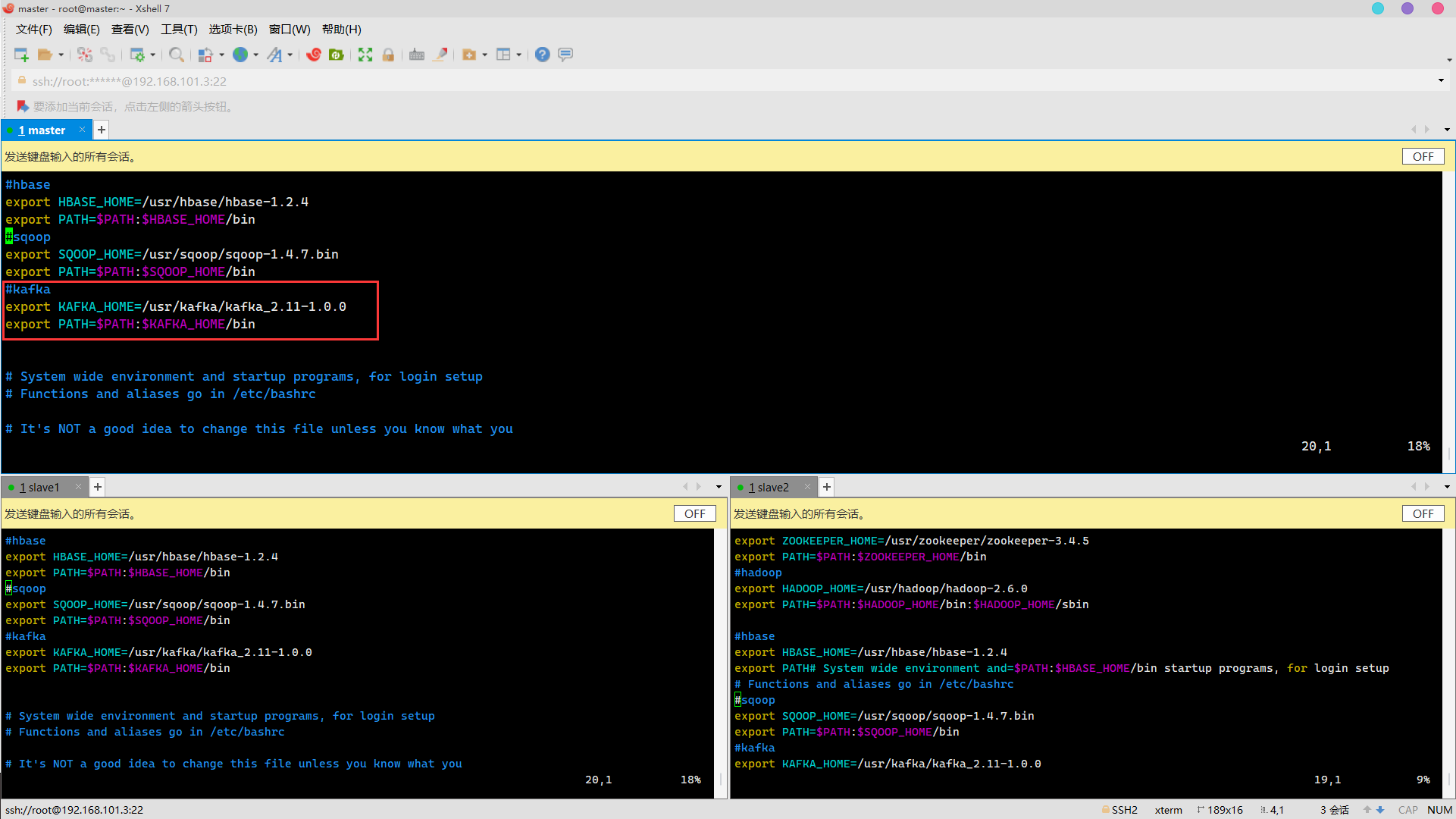
Effective environment variable
source /etc/profile
configuration file
Create logs folder
cd /usr/kafka/kafka_2.11-1.0.0/ mkdir logs
zookeeper.properties
Modify dataDir to be consistent with zoo.cfg in zookeeper
cd /usr/kafka/kafka_2.11-1.0.0/config vim zookeeper.properties
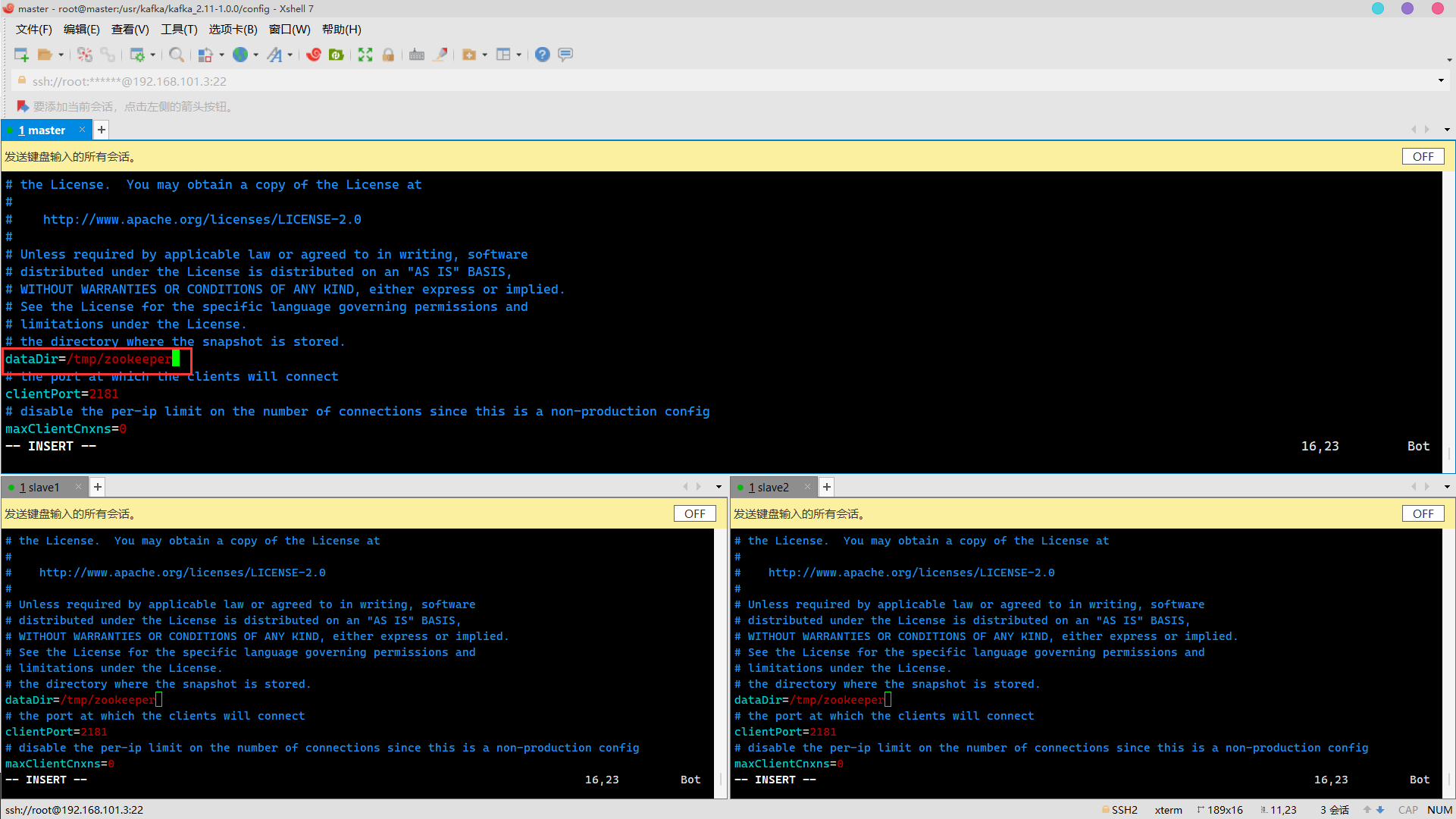
Change to
dataDir=/usr/zookeeper/zookeeper-3.4.5/zkdata
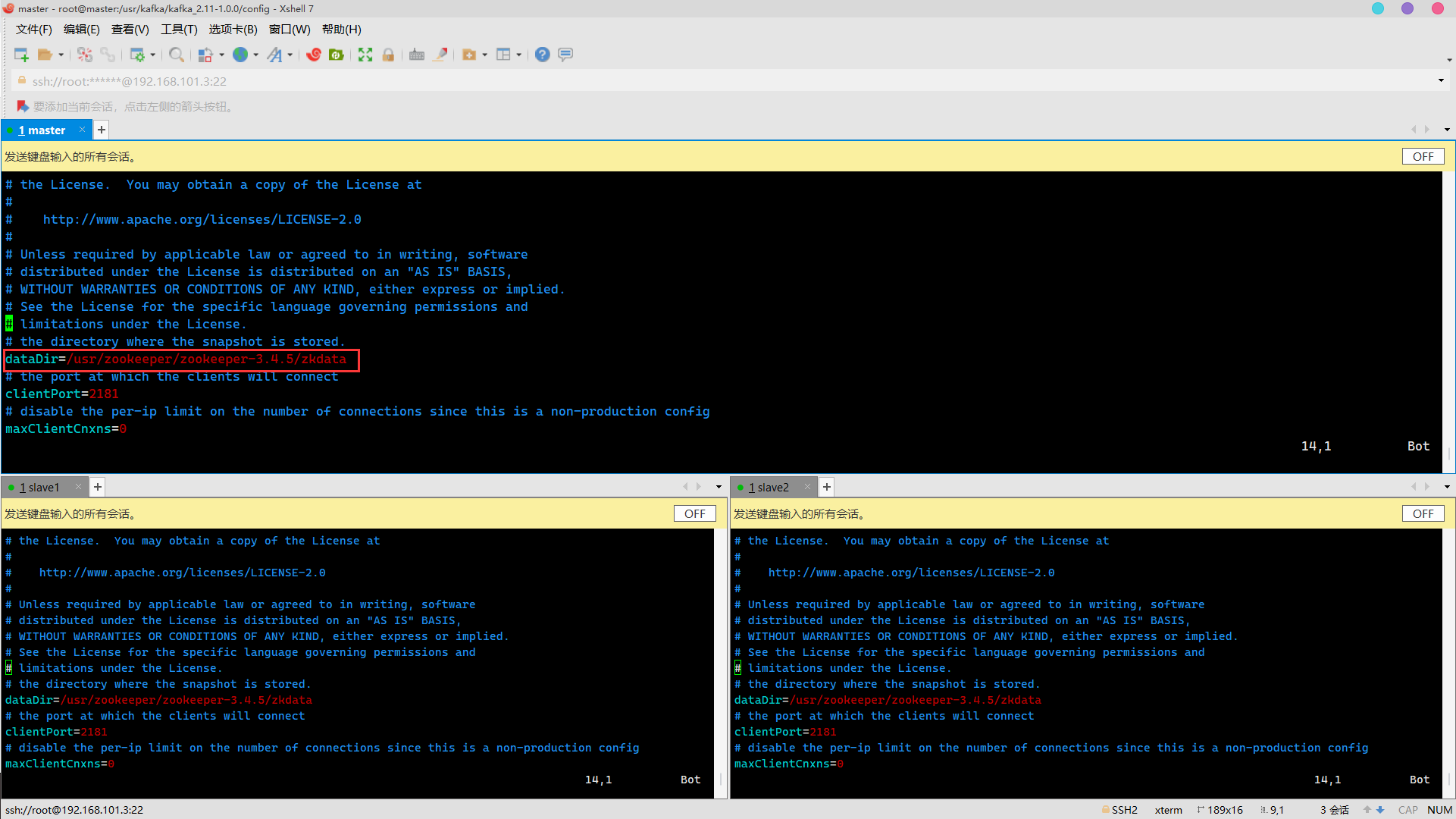
server.properties
vim server.properties
broker.id modification
0 on master, 1 on slave1 and 2 on slave2
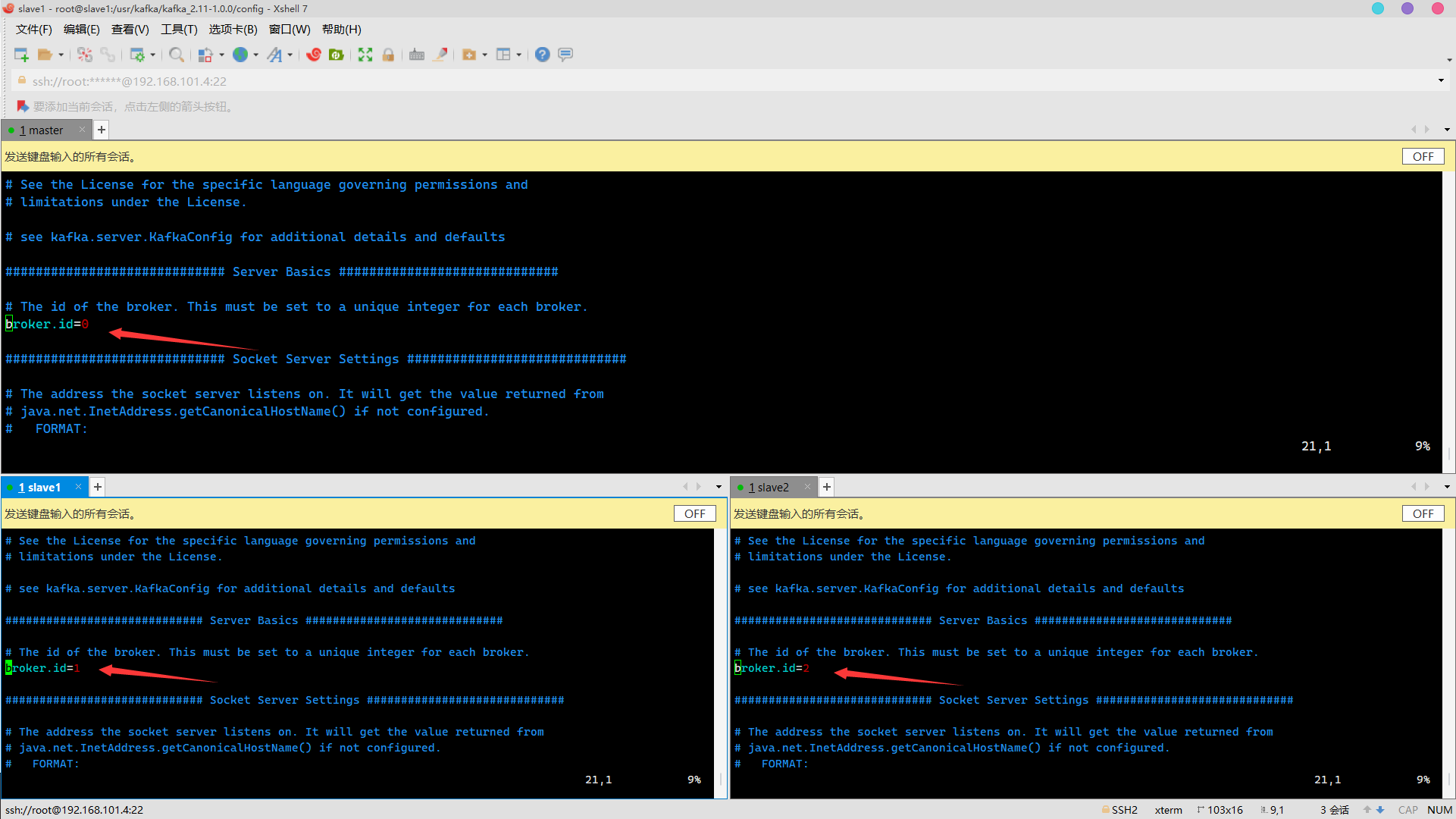
Note: the broker.id cannot be repeated
log.dirs modification
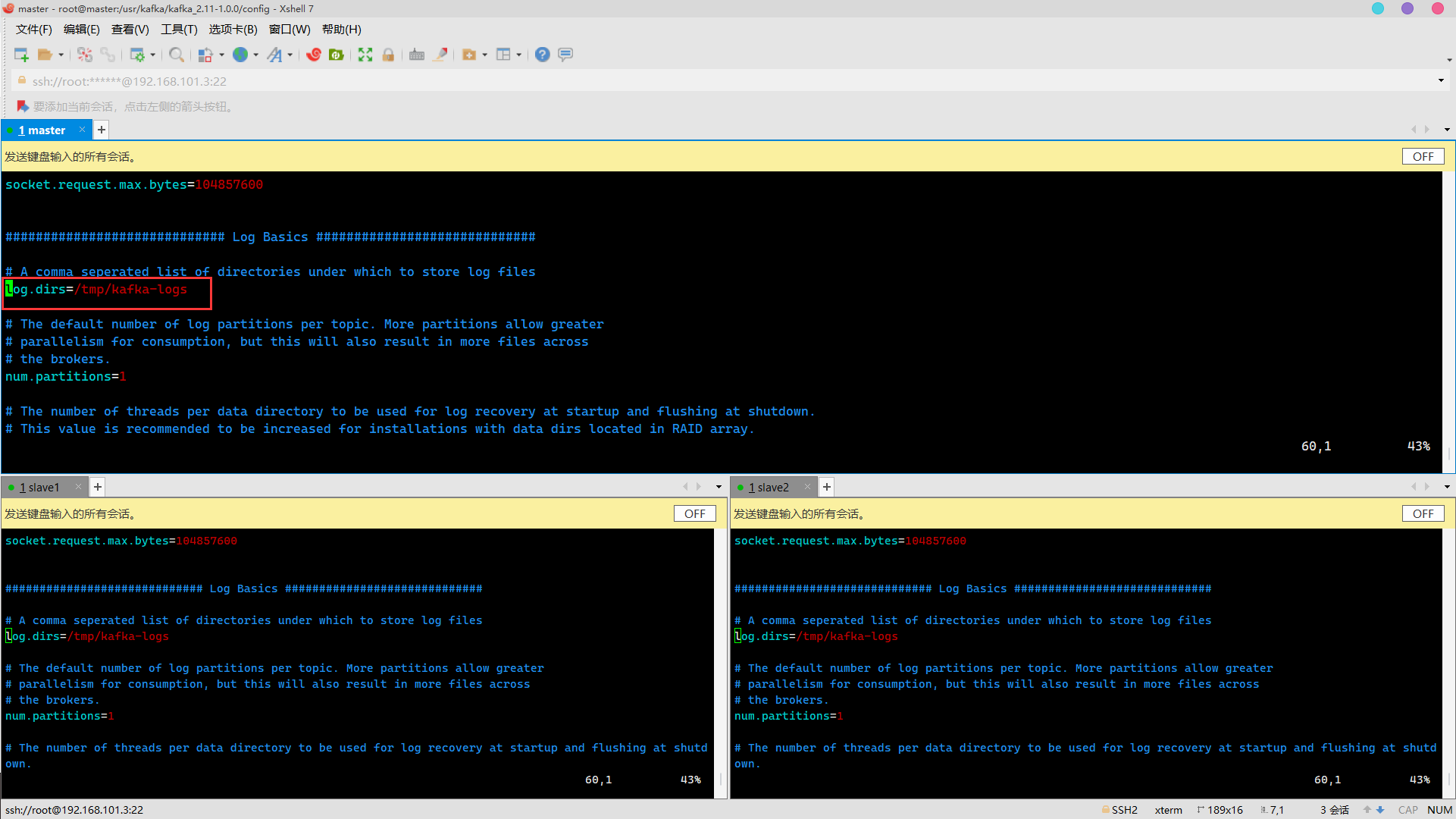
Change to
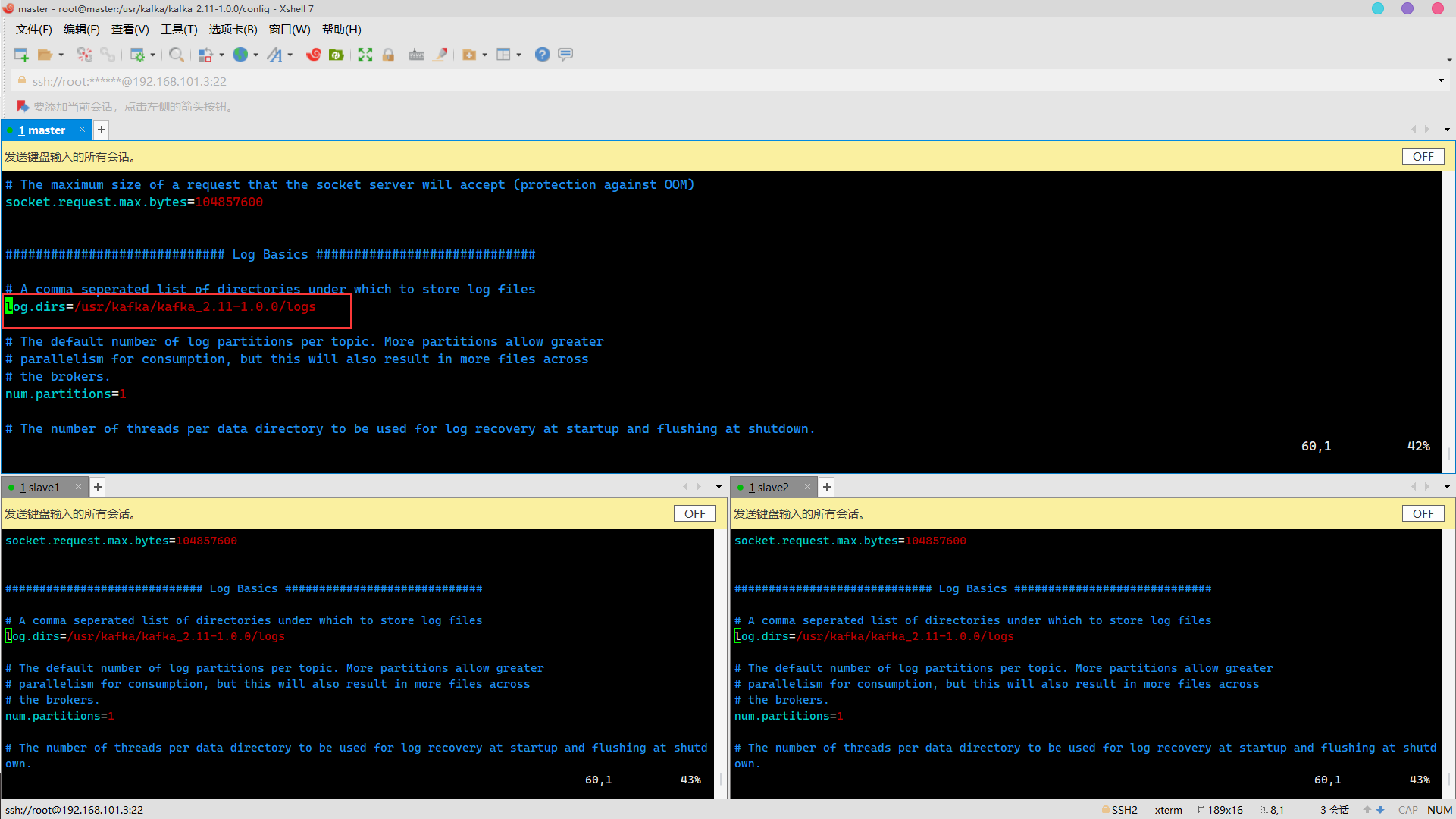
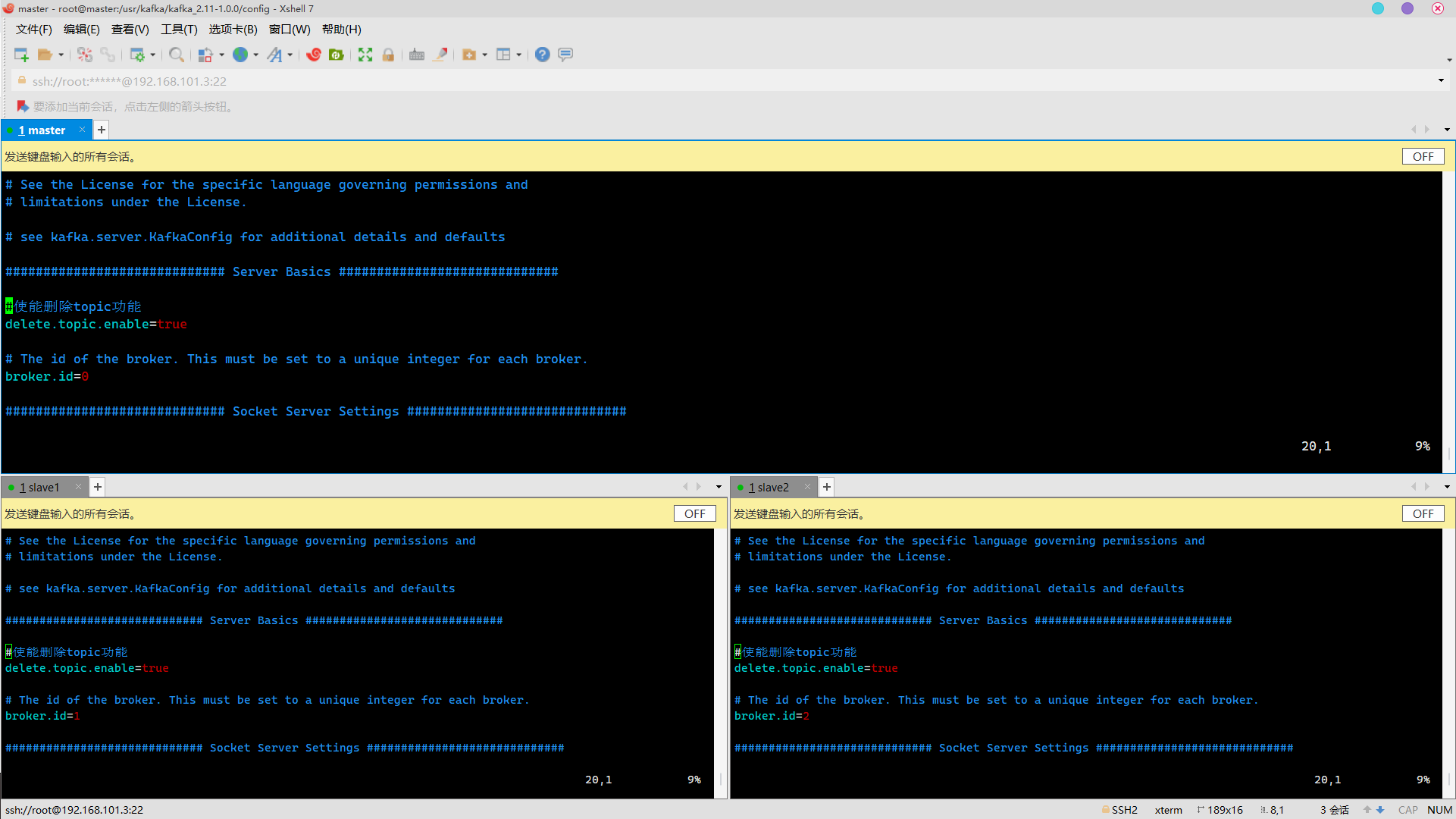
Enable to delete topic function
increase
#Enable to delete topic function delete.topic.enable=true
Configure Zookeeper cluster address
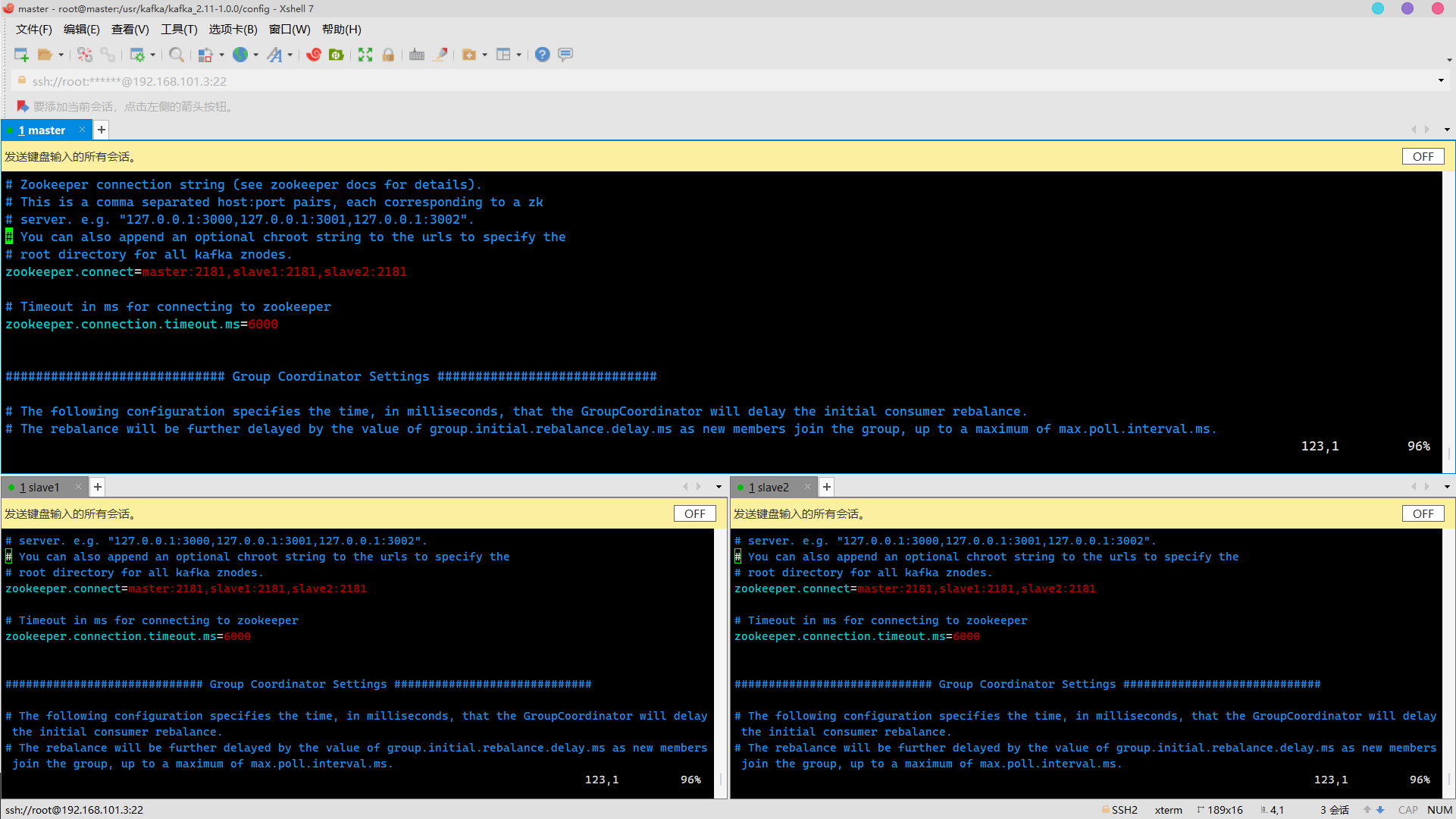
Change to
zookeeper.connect=master:2181,slave1:2181,slave2:2181
Start cluster
Start zookeeper
/usr/zookeeper/zookeeper-3.4.5/bin/zkServer.sh start
Start kafka
cd /usr/kafka/kafka_2.11-1.0.0/ bin/kafka-server-start.sh config/server.properties & jps
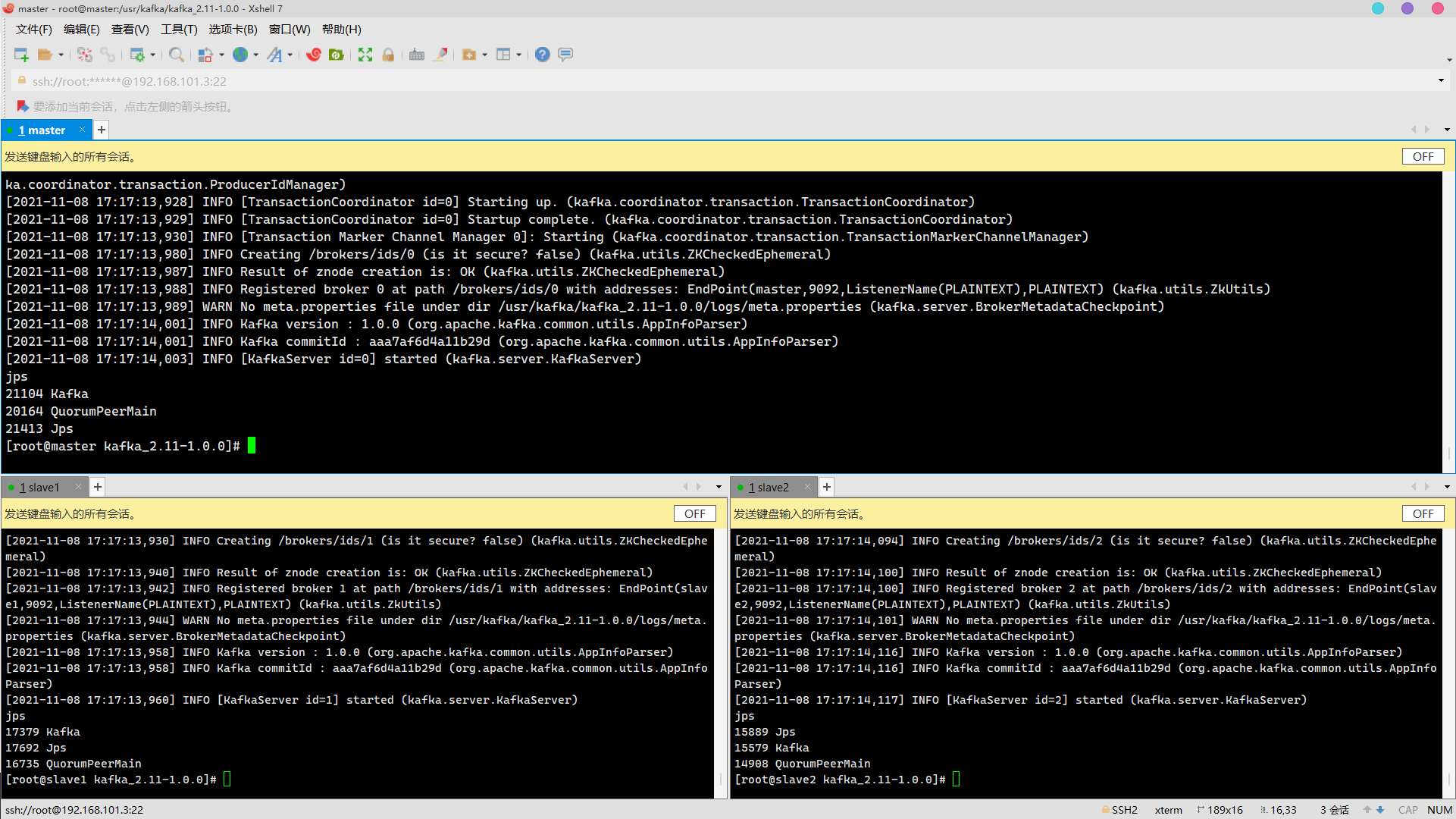
verification
Only under master
View all topic s in the current server
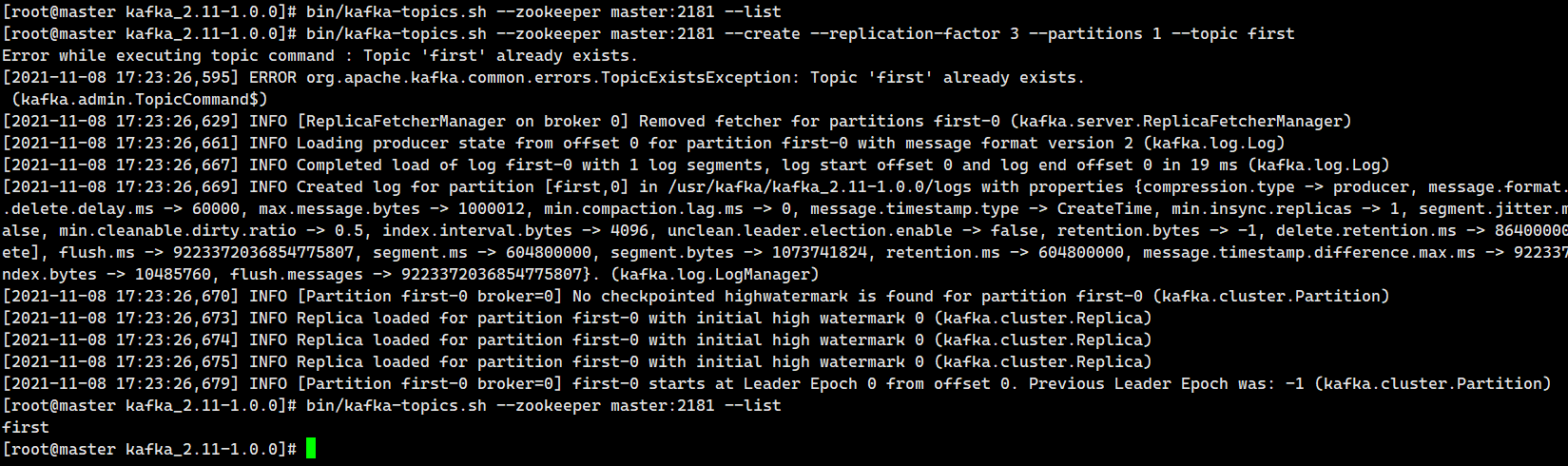
bin/kafka-topics.sh --zookeeper master:2181 --list
Create topic
bin/kafka-topics.sh --zookeeper master:2181 --create --replication-factor 3 --partitions 1 --topic first
Option Description:
--Topic defines the topic name
--Replication factor defines the number of copies
--Partitions defines the number of partitions
Shutdown cluster
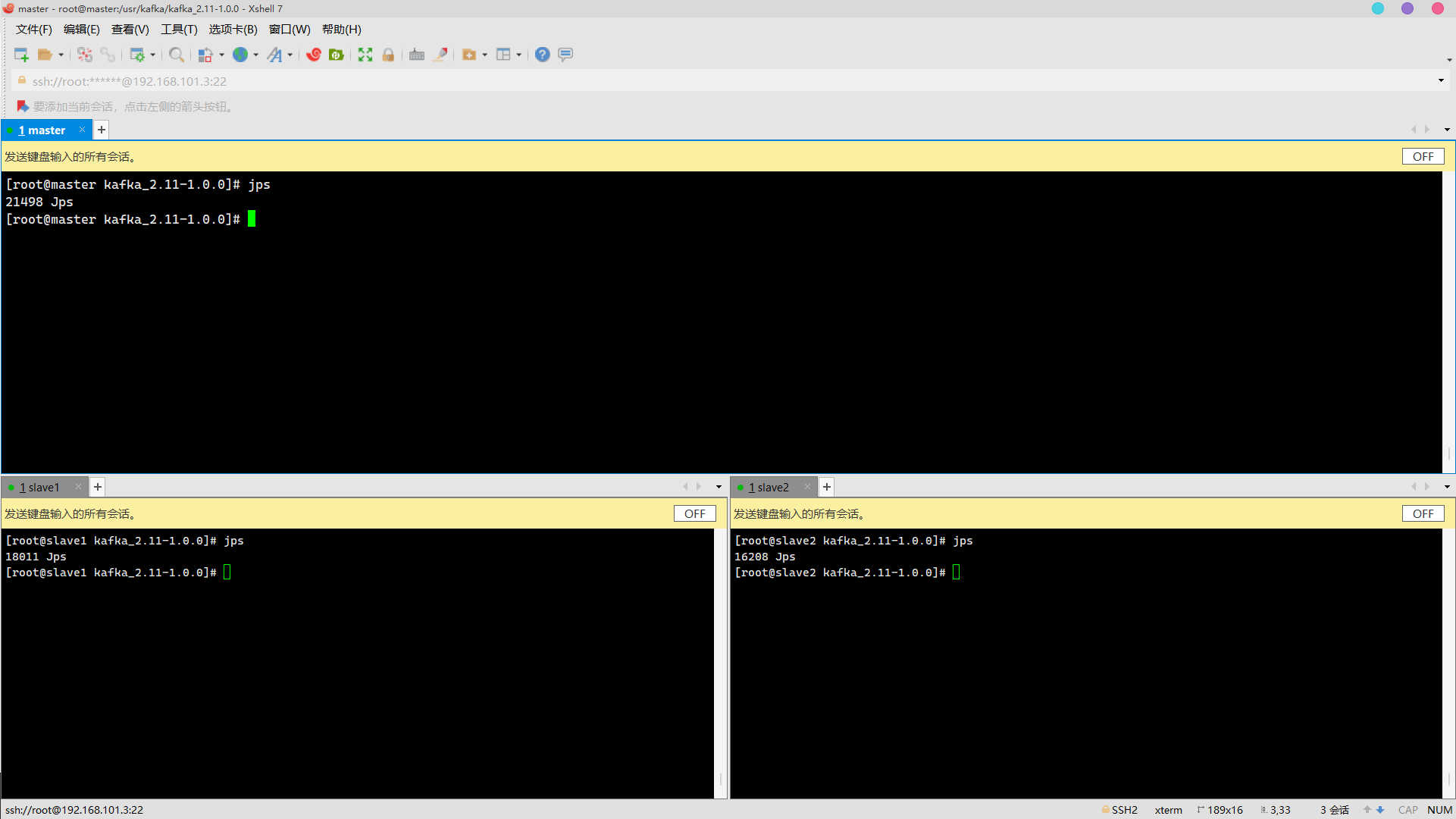
bin/kafka-server-stop.sh stop //Wait for the message to pop up and stop before entering jps /usr/zookeeper/zookeeper-3.4.5/bin/zkServer.sh stop jps
flume installation deployment
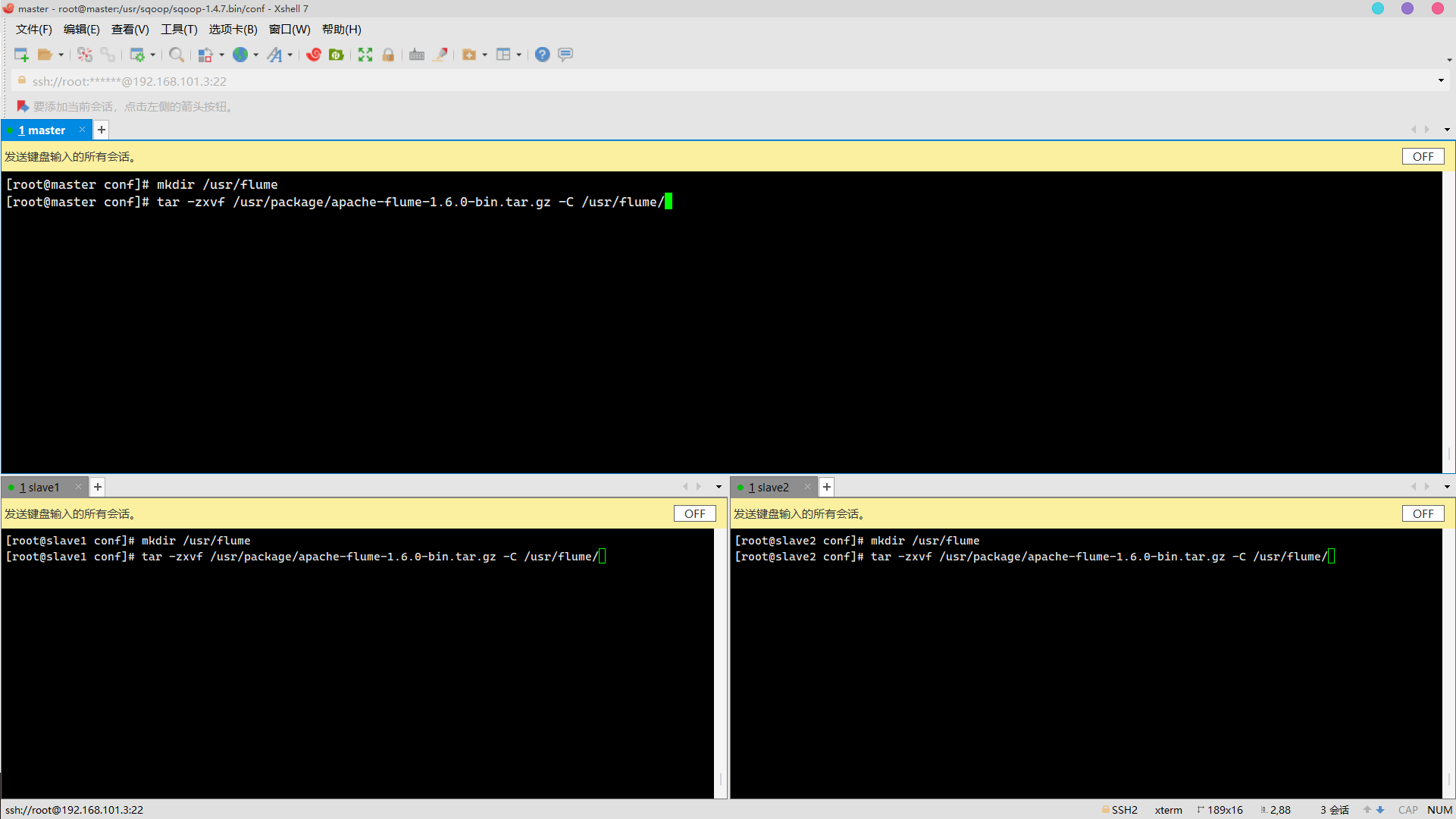
Unzip the installation package
mkdir /usr/flume tar -zxvf /usr/package/apache-flume-1.6.0-bin.tar.gz -C /usr/flume/
Configure environment variables
vim /etc/profile
add to:
#flume export FLUME_HOME=/usr/flume/apache-flume-1.6.0-bin export FLUME_CONF_DIR=$FLUME_HOME/conf export PATH=$PATH:$FLUME_HOME/bin
Effective environment variable
source /etc/profile
flume-env.sh
cd /usr/flume/apache-flume-1.6.0-bin/conf/ mv flume-env.sh.template flume-env.sh echo "export JAVA_HOME=/usr/java/jdk1.8.0_171" >> flume-env.sh cat flume-env.sh
see
flume-ng version
report errors
Error: Could not find or load main class org.apache.flume.tools.GetJavaProperty
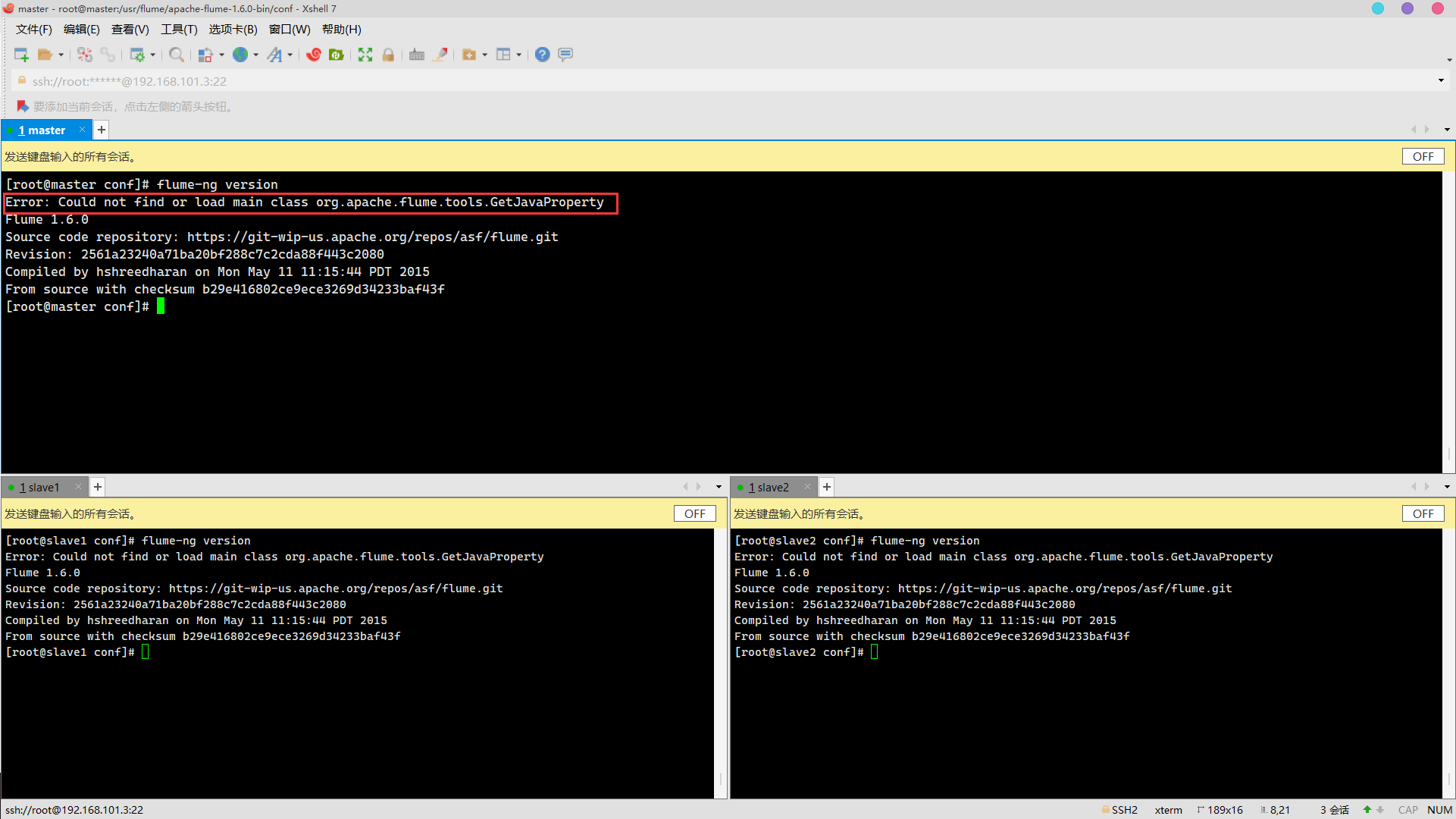
Solution
Flume ng script problem
terms of settlement
cd /usr/flume/apache-flume-1.6.0-bin/bin/ vim flume-ng //Add the following in line 124 2>/dev/null | grep hbase
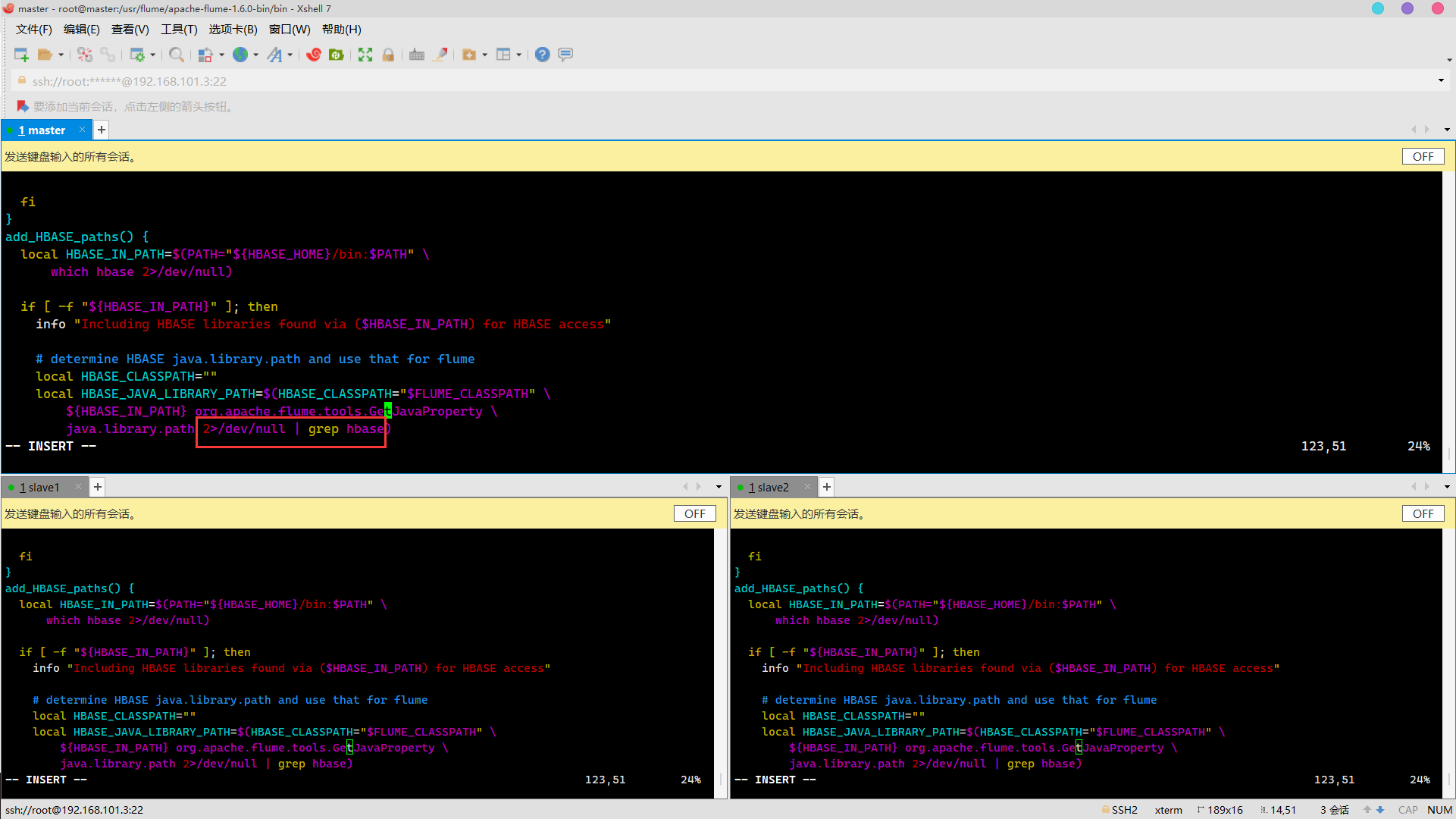
Successfully solved
Configure flume and kafka connections
cd /usr/flume/apache-flume-1.6.0-bin/conf/ echo "#Configure the source, channel and sink of flume agent a1.sources = r1 a1.channels = c1 a1.sinks = k1 #Configure source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /tmp/logs/kafka.log #Configure channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 #Configure sink a1.sinks.k1.channel = c1 a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink #Configure Kafka's Topic a1.sinks.k1.kafka.topic = mytest #Configure the broker address and port number of kafka a1.sinks.k1.brokerList = matser:9092,slave1:9092,slave2:9092 #Configure the number of batch submissions a1.sinks.k1.kafka.flumeBatchSize = 20 a1.sinks.k1.kafka.producer.acks = 1 a1.sinks.k1.kafka.producer.linger.ms = 1 a1.sinks.k1.kafka.producer.compression.type = snappy #Bind source and sink to channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1" >> kafka.properties
Stepping pit
report errors
(conf-file-poller-0) [ERROR - org.apache.flume.node.AbstractConfigurationProvider.loadSinks(AbstractConfigurationProvider.java:427)] Sink k1 has been removed due to an error during configuration org.apache.flume.conf.ConfigurationException: brokerList must contain at least one Kafka broker at org.apache.flume.sink.kafka.KafkaSinkUtil.addDocumentedKafkaProps(KafkaSinkUtil.java:55) at org.apache.flume.sink.kafka.KafkaSinkUtil.getKafkaProperties(KafkaSinkUtil.java:37) at org.apache.flume.sink.kafka.KafkaSink.configure(KafkaSink.java:211) at org.apache.flume.conf.Configurables.configure(Configurables.java:41)
resolvent
Configuration in kafka.properties file
A1.sins.k1.kafka.bootstrap.servers (written in version 1.7 +)
A1.sins.k1.brokerlist (version 1.6)
Create directory
mkdir -p /tmp/logs touch /tmp/logs/kafka.log
Create script
cd vim kafkaoutput.sh //Add the following #!/bin/bash for((i=0;i<=1000;i++)) do echo "kafka_test-"+$i >> /tmp/logs/kafka.log done
 Script empowerment
Script empowerment
chmod 777 kafkaoutput.sh
Create topic in kafka node
Premise zookpeer, kafka start
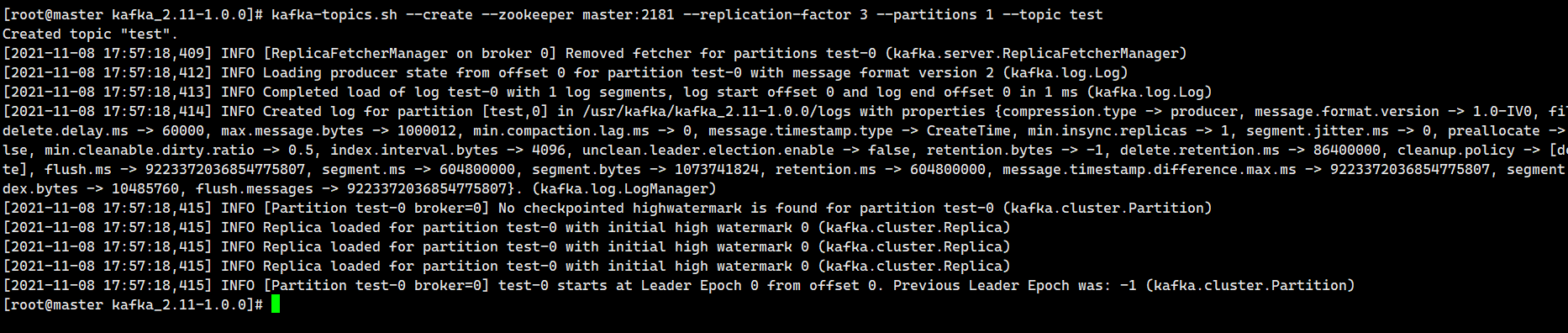
Create topic
On master only
kafka-topics.sh --create --zookeeper master:2181 --replication-factor 3 --partitions 1 --topic mytest
 Open the console
Open the console
kafka-console-consumer.sh --bootstrap-server master:9092,slave1:9092,slave2:9092 --from-beginning --topic mytest
Start test
flume-ng agent --conf /usr/flume/apache-flume-1.6.0-bin/conf/ --conf-file /usr/flume/apache-flume-1.6.0-bin/conf/kafka.properties -name a1 -Dflume.root.logger=INFO,console
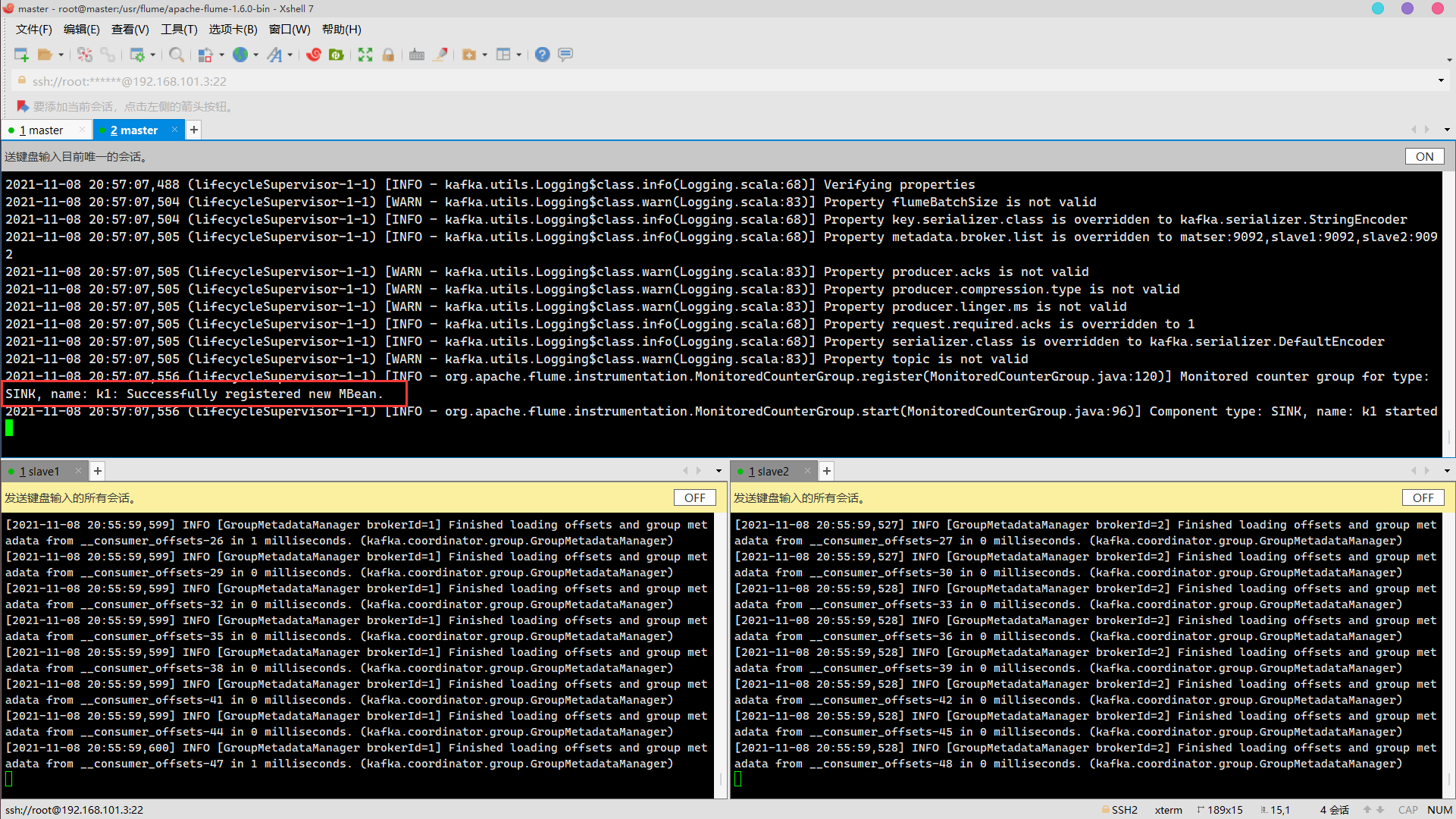
success!
Execute script
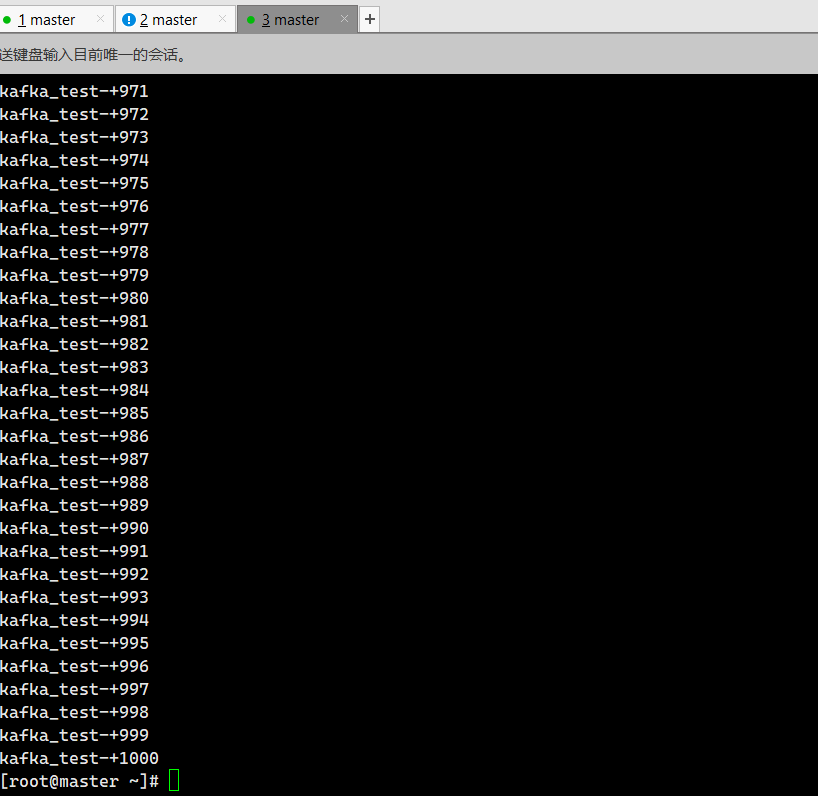
sh kafkaoutput.sh
View in kafka
cat /tmp/logs/kafka.log
spark installation and deployment
Please move spark installation Refer to completing spark installation and deployment.
At the end of the full text, one day, so many components were deployed on the cluster for the first time, and there were mutual docking configurations. They kept reporting and troubleshooting errors. Finally, it was completed!
Eye pain!!!
The next period of time to prepare for the game! Come on!