Experimental task 1
Task 1-1:
(1)task1_1.asm source code
assume ds:data, cs:code, ss:stack data segment db 16 dup(0) data ends stack segment db 16 dup(0) stack ends code segment start: mov ax, data mov ds, ax mov ax, stack mov ss, ax mov sp, 16 mov ah, 4ch int 21h code ends end start
(2)task1_1. Screenshot after debugging to the end of line17 and before line19:
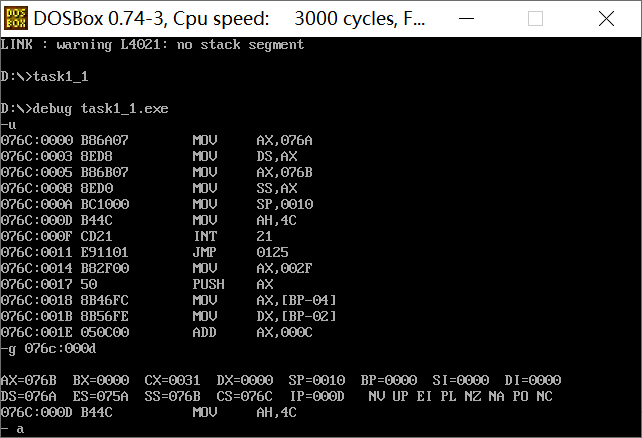
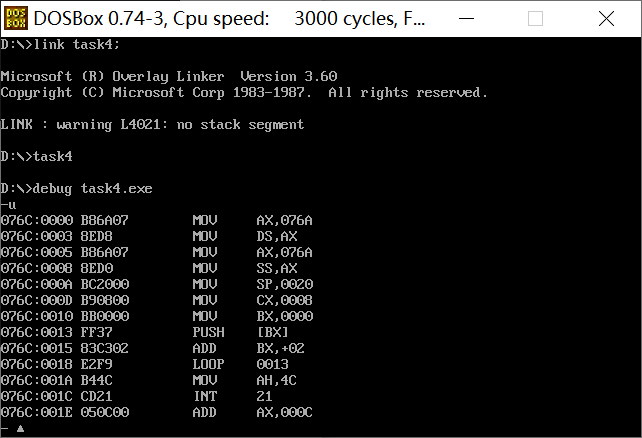
Answer: ① at this time, register DS=076A, SS=076B, CS=076C;
② Assuming that after the program is loaded, the segment address of the code segment is X, the segment address of the data segment is X-2h, and the segment address of the stack is X-1h.
Reason: 16B memory is reserved for both data segment and stack segment, and memory address = segment address * 16 + offset address, so the address difference between adjacent segments is 1h
Task 1-2
Task task1_2.asm source code:
assume ds:data, cs:code, ss:stack data segment db 4 dup(0) data ends stack segment db 8 dup(0) stack ends code segment start: mov ax, data mov ds, ax mov ax, stack mov ss, ax mov sp, 8 mov ah, 4ch int 21h code ends end start
task1_2. Screenshot of observing the values of registers DS, CS and SS at the end of debugging to line17 and before line19:

Answer:
① At this time, register DS=076A, SS=076B, CS=076C;
② Assuming that after the program is loaded, the segment address of the code segment is X, the segment address of the data segment is X-2h, and the segment address of the stack is X-1h.
Reason: the memory allocated by the system is in 16B units, and the allocated memory is 16 multiples. If it is insufficient, it will be made up. Therefore, 16B space is reserved for the data segment and stack segment of this program; The difference between adjacent segment addresses is 1h.
Tasks 1-3:
Task task1_3.asm source code:
assume ds:data, cs:code, ss:stack data segment db 20 dup(0) data ends stack segment db 20 dup(0) stack ends code segment start: mov ax, data mov ds, ax mov ax, stack mov ss, ax mov sp, 20 mov ah, 4ch int 21h code ends end start
task1_3. Screenshot of observing the values of registers DS, CS and SS at the end of debugging to line17 and before line19:

Answer:
① At this time, register DS=076A, SS=076C, CS=076E;
② Assuming that after the program is loaded, the segment address of the code segment is X, the segment address of the data segment is X-4h, and the segment address of the stack is X-2h.
Reason: the allocated segment memory is 16 times, so 32B space is reserved for the data segment and stack segment of this program; The difference between adjacent segment addresses is 2h.
Tasks 1-4:
Task task1_4.asm source code:
assume ds:data, cs:code, ss:stack code segment start: mov ax, data mov ds, ax mov ax, stack mov ss, ax mov sp, 20 mov ah, 4ch int 21h code ends data segment db 20 dup(0) data ends stack segment db 20 dup(0) stack ends end start
task1_4. Screenshot of observing the values of registers DS, CS and SS at the end of debugging to line17 and before line19:

Answer:
① At this time, register DS=076C, SS=076E, CS=076A;
② Assuming that after the program is loaded, the segment address of the code segment is X, the segment address of the data segment is X+2h, and the segment address of the stack is X+4h.
Reason: the address order between segments is allocated according to the compilation order.
Tasks 1-5:
① The amount of memory space actually allocated to this segment is (ceil)(N/16)*16 (ceil is rounded up)
② Only task1_4.asm can still be executed correctly. end start informs the compiler that the entry of the program is at start. Removing start may lead to an error in the location of the CS segment address. task1_4. The sequence of the middle section is CS, DS and SS. After removing start, the beginning of the program area pointed to by CS: IP is also a code segment, so the program can be executed correctly.
Operation method of assembler:
1. Find a free memory area with sufficient capacity with a starting address of SA: 0000 (i.e. the offset address of the starting address is 0).
2. In the first 256 bytes of this memory area, a data area called program segment prefix (PSP) is created. DOS uses PSP to communicate with the loaded program.
3. Start from 256 bytes of this memory area (after PSP), load the program, and the address of the program is set to SA+10H:0; The free memory area starts from SA: 0, 0 ~ 255 bytes are PSP, and the program is stored from 256 bytes. In order to better distinguish PSP and program, DOS will be divided into different segments, as follows:
Free memory area: SA: 0
PSP area: SA: 0
Program area: SA+10H: 0
Note: Although the physical addresses of PSP area and program area are continuous, they have different segment addresses.
4. Store the segment address (SA) of the memory area in DS, initialize other relevant registers, and set CS: IP to point to the entry of the program (SA+10H: 0).
Determination of ds and cs addresses during program loading:
1. For ds, when the program is loaded, the ds segment address points to the PSP address. To point to the data segment, you need to assign values in the program;
2. For cs, the segment address is determined by the start specified by end start; If there is no start, cs: ip points to (SA+10H: 0).
Experiment task 2:
Assembly source code:
assume cs:code code segment start:mov ax,0b800h mov ds,ax mov bx,0f00h mov cx,80 mov dx,0403h s:mov ds:[bx],dx add bx,2 loop s mov ah,4ch int 21h code ends end start
Before running the program:
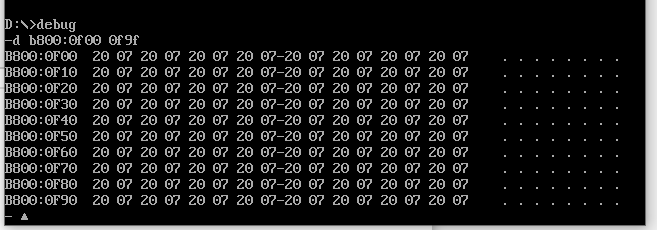
After the program runs

Experiment task 3:
Source code:
assume cs:code data1 segment db 50, 48, 50, 50, 0, 48, 49, 0, 48, 49 ; ten numbers data1 ends data2 segment db 0, 0, 0, 0, 47, 0, 0, 47, 0, 0 ; ten numbers data2 ends data3 segment db 16 dup(0) data3 ends code segment start: mov bx, 0 ;Offset address of corresponding position mov ax, data1 mov ds, ax mov cx, 0ah s: mov ax, [bx] add ax, [bx+10h] ;data1 and data2 Data addition of mov [bx+20h], ax ;put to data3 In paragraph inc bx loop s mov ah, 4ch int 21h code ends end start
Disassembly:
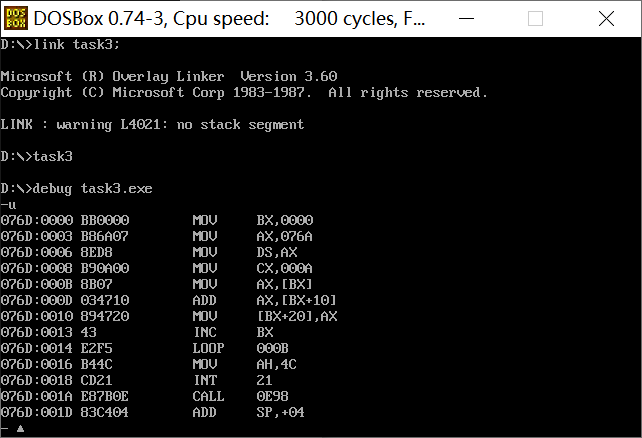
Before operation:

After operation:
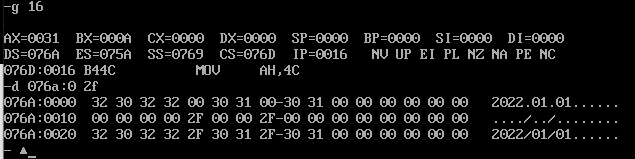
The three lines are data1, data2 and data3 respectively. It can be seen that data1 and data2 at the corresponding position are added and stored in data3.
Experiment task 4:
Source code:
assume cs:code data1 segment dw 2, 0, 4, 9, 2, 0, 1, 9 data1 ends data2 segment dw 8 dup(?) data2 ends code segment start: mov ax, data1 mov ds, ax mov ax, data1+02h mov ss, ax ;take data2 Used as stack segment mov sp, 20h ;The top of the stack points to the high address mov cx, 8 mov bx, 0 s: push [bx] add bx,2 loop s mov ah, 4ch int 21h code ends end start
Disassembly:
Before operation:

After operation:
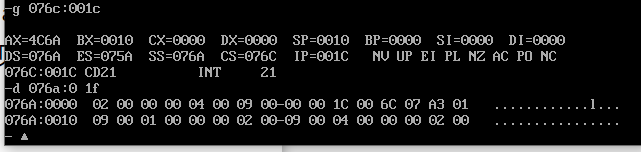
The two lines are segments data1 and data2 respectively. You can see that the contents of data1 have been stored in data2 in reverse order; At the same time, it is noted that the value at 076A:0b~076A:0f in data1 changes because the program is interrupted and the FALG, CS and IP at this time are stored in the stack space
Experiment task 5:
Source code:
assume cs:code, ds:data data segment db 'Nuist' db 2, 3, 4, 5, 6 data ends code segment start: mov ax, data mov ds, ax mov ax, 0b800H mov es, ax mov cx, 5 mov si, 0 mov di, 0f00h s: mov al, [si] and al, 0dfh mov es:[di], al mov al, [5+si] mov es:[di+1], al inc si
add di, 2 loop s mov ah, 4ch int 21h code ends end start
Operation results:


The function of line19: convert 0dfh into binary to 1101 1111, and its bitwise and subsequent third bit becomes 0, and other bits remain unchanged; According to the ASCII code table, the difference between upper and lower case letters lies in the third bit, so changing the third bit to 0 is to convert lower case letters into upper case letters (upper case letters remain the same).
Operation results after modifying line4 to db 5 dup(2):

Result after modification to db 5 dup(5):

Experiment task 6:
Source code:
assume cs:code, ds:data data segment db 'Pink Floyd ' db 'JOAN Baez ' db 'NEIL Young ' db 'Joan Lennon ' data ends code segment start: mov ax, data mov ds, ax mov bx, 0 ;Row offset address mov cx, 4 ;Four lines mov si, 0 ;Letter pointer in word s1: ;Enter outer circulation mov di, cx ;Save the number of cycles mov cx, 4 ;The first word in each line is 4 letters, so the number of memory cycles is 4 s2: ;Enter inner circulation mov al, [bx+si] ;Take out the letters one by one or al, 20h ;And 20 h Bitwise or convert to lowercase mov [bx+si], al ;Return to the original position inc si ;Next letter loop s2 ;End of inner loop add bx, 10h ;Go to the next line mov si, 0 ;Letter pointer reset mov cx, di ;Recovery cycle test times loop s1 ;End of outer cycle mov ah, 4ch int 21h code ends end start
Disassembly:
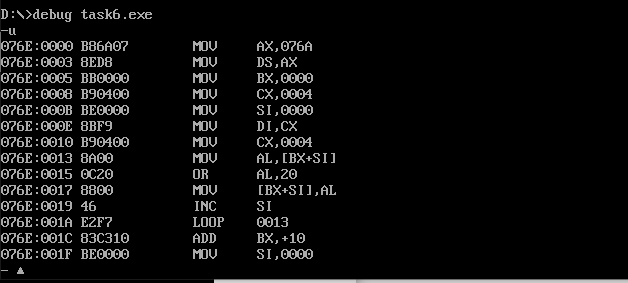
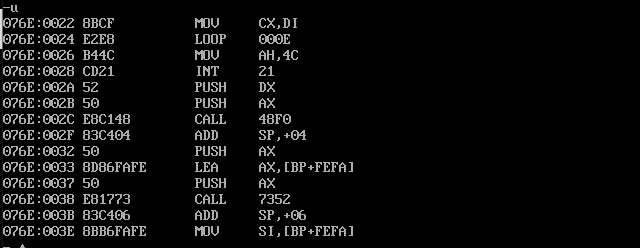
Operation results:
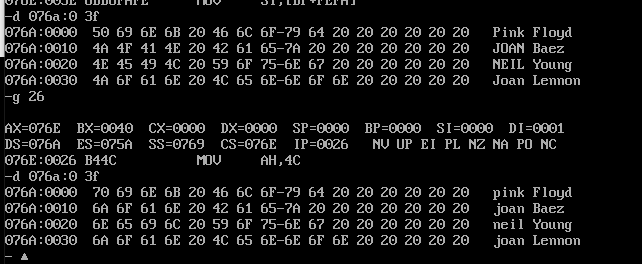
You can see that the first word of each line in the data segment is converted to lowercase.
Experiment task 7:
Source code:
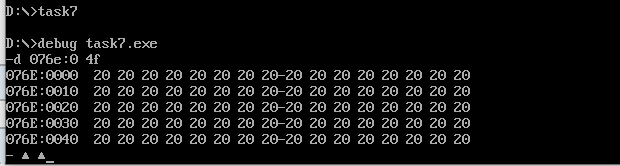
assume cs:code, ds:data, es:table data segment db '1975', '1976', '1977', '1978', '1979' dd 16, 22, 382, 1356, 2390 dw 3, 7, 9, 13, 28 data ends table segment db 5 dup( 16 dup(' ') ) ; table ends code segment start: mov ax, data mov ds, ax mov ax, table mov es, ax ;target table address mov bx, 0 ;table Row address of mov si, 0 ;data Data pointer in segment mov cx, 5 ;Write 5 lines at a time mov di, 0 ;table Pointer in each line in ;Write year year: ;Outer loop, write one line at a time mov ax, cx ;Number of save cycles mov cx, 4 ;The year of each line accounts for 4 bytes, and it takes 4 times to write by byte year1: ;Inner loop, write one byte, that is, one number at a time mov dl, ds:[si] ;Memory cells cannot be moved directly. Borrow dl Take by word mov es:[bx+di], dl inc si ;data The data in is continuous, so it is taken by word+1 inc di ;Year in table The offset address of each row in the is 0~3 loop year1 add bx, 10h ;Go to the next line mov di, 0 ;di Return to initial position mov cx, ax ;Number of recovery cycles loop year ;Write revenue mov cx, 5 mov bx, 0 mov di, 5 income: mov ax, cx mov cx, 2 ;The income is stored as double words, but only single words can be taken at a time, and 2 cycles are required for each line income1: mov dx, ds:[si] ;Take by word mov es:[bx+di], dx add si, 2 ;Move 2 bytes per word add di, 2 loop income1 add bx, 10h ;next row mov di, 5 ;Return to the initial position written in each line mov cx, ax loop income ;Write employee mov cx, 5 mov bx, 0 mov di, 0ah employee: mov dx, ds:[si] ;Take by word mov es:[bx+di], dx add si, 2 add bx, 10h loop employee ;Write in per capita income mov cx, 5 mov bx, 0 mov di, 0dh avgincome: mov dx, es:[bx+7] ;The divisor is a double word, that is, 32 bits dx 16 bits high, ax Save low 16 bits mov ax, es:[bx+5] div word ptr es:[bx+0ah] ;The divisor is 16 bits and the quotient exists ax In, the remainder exists dx in mov es:[bx+di], ax add bx, 10h loop avgincome mov ah, 4ch int 21h code ends end start
View the screenshot of the original data information of the table segment:
Screenshot after operation:
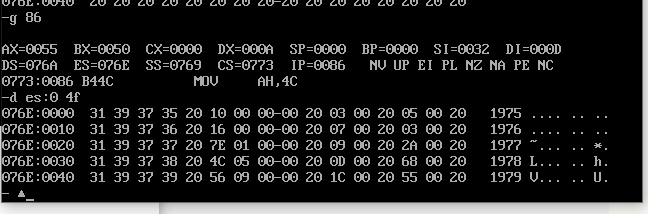
You can see that the data in the data segment has been saved in the table segment according to the structure, and the calculation result of per capita income is correct.