Preface: there are various ways to save data. The simplest way is to directly save it as a text file, such as TXT, JSON, CSV, etc. in addition, Excel is also a popular storage format. Through this article, you will master how to operate Excel through some third-party libraries (xlrd/xlwt/pandas/openpyxl) to store and read data. This article is enough! Recommended collection!
1, TXT text storage
1.1 applicable mode
TXT text is compatible with almost any platform, but it is not conducive to retrieval. If the requirements for retrieval and data structure are not high and convenience is sought, TXT text storage format can be adopted
1.2 basic writing method
file = open('demo.txt','a',encoding='utf-8')
file.write(data)
file.close()
The first parameter of the open() method indicates the name of the target file to be saved, and the absolute path can also be specified. The second parameter a indicates that the text is written in the form of append, so that the previously written content will not be overwritten. This append method is generally used in Crawlers. The third parameter specifies the encoding of the file as utf-8, then writes the data, and finally closes the file with the close() method
1.3 opening mode
The above parameter a means that each time text is written, the previously written data will not be cleared, but new data will be written at the end of the text. This is an opening method, and there are other ways to open files:
| r | Open file as read-only |
|---|---|
| rb | Open a file as binary read-only |
| r+ | Open a file read-write |
| rb+ | Open a file in binary read-write mode |
| w | Open file as write |
| wb | Open a file as binary write |
| w+ | Open a file read-write |
| wb+ | Open a file in binary read-write mode |
| a | Open a file in append mode |
| ab | Open a file in binary append mode |
| a+ | Open a file read-write |
| ab+ | Open a file in binary append mode |
b above represents binary, + represents read-write mode, r represents read and w represents write
1.4 simplified writing
If you use the with as syntax to write data, the file will be closed automatically, so you don't need to call the close() method, which is abbreviated as follows:
with open('demo.txt','a',encoding='utf-8') as f:
f.write(data)
2, JSON file storage
2.1 applicable mode
JSON, the full name of which is JavaScript Object Notation, is a JavaScript object tag. It is concise in structure but highly structured. It uses a combination of objects and arrays to represent data. It is a lightweight data exchange format, which is somewhat similar to XML. If there are requirements for data structure, this method can be considered according to the needs
2.2 basic writing method
Python provides a json library to read and write json files. By calling the loads() method of the json library, you can convert json text strings into json objects, and by calling dumps() method, you can convert json objects into text strings, as follows:
1 import json
2
3 with open('demo.json','w',encoding='utf-8') as f:
4 f.write(json.dumps(data,indent=2,ensure_ascii=False))
1 import json
2
3 with open('demo.json','r',encoding='utf-8') as f:
4 data = f.read()
5 data = json.loads(data)
6 price = data.get('price')
7 location = data.get('location')
8 size = data.get('size')
indent represents the number of indented characters, ensure_ascii=False specifies the output code of the file, so that Chinese can be output
Note: JSON data needs to be enclosed in double quotation marks instead of single quotation marks. The code is as follows:
1 [
2 {
3 "name":"makerchen',
4 "gender":"male",
5 "hobby":"running"
6 }
7 ]
2.3 store JSON data in TXT format
If we want to store the data in TXT format and change the data into a json structure, we can do this:
1 import json
2
3 with open('demo.txt','a',encoding='utf-8') as f:
4 f.write(json.dumps(data,indent=4,ensure_ascii=False) + '\n')
3, CSV file storage
3.1 applicable mode
CSV, fully called comma separated values, can be called character separated values or comma separated values in Chinese. It stores table data in plain text. The text is separated by commas by default. CSV is equivalent to the plain text form of a structured table. It is more concise than Excel file and is very convenient to save data
3.2 single line write
1 import csv
2
3 with open('demo.csv','w',encoding='utf-8') as csvf:
4 writer = csv.writer(csvf)
5 writer.writerow(['id','name','gender'])
6 writer.writerow(['100','makerchen','male'])
7 writer.writerow(['101','makerliu','female'])
8 writer.writerow(['102','makerqin','male'])
First call the writer() method of the csv library to initialize the write object, and then call the writerow() method to pass in the data of each row to complete the write
Excel works as follows:
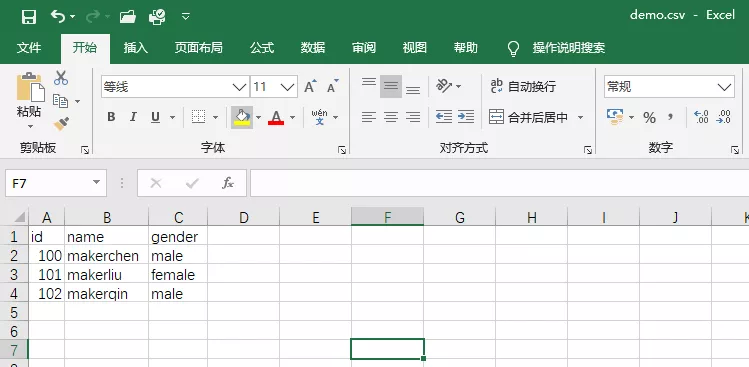
If you want to modify the separator between columns, you can pass in the parameter delimiter. The code is as follows:
1 import csv
2
3 with open('demo.csv','w',encoding='utf-8') as csvf:
4 writer = csv.writer(csvf,delimiter=' ')
5 writer.writerow(['id','name','gender'])
6 writer.writerow(['100','makerchen','male'])
7 writer.writerow(['101','makerliu','female'])
8 writer.writerow(['102','makerqin','male'])
This means that each column of data is separated by spaces
3.3 multiline write
Call writerows() method to write multiple lines at the same time. At this time, the parameter needs to be a two-dimensional list. The code is as follows:
1 import csv
2
3 with open('demo.csv','w',encoding='utf-8') as csvf:
4 writer = csv.writer(csvf)
5 writer.writerow(['id','name','gender'])
6 writer.writerows(['100','makerchen','male'],
7 ['101','makerliu','female'],['102','makerqin','male'])
3.4 dictionary writing
Generally, the data extracted by the crawler is structured data, which is generally represented by a dictionary. The code is as follows:
1 import csv
2
3 with open('demo.csv','w',encoding='utf-8') as csvf:
4 fieldnames = ['id','name','gender']
5 writer = csv.DictWriter(csvf,fieldnames=fieldnames)
6 writer.writeheader()
7 writer.writerow({'id':'100','name':'makerchen','gender':'male'})
8 writer.writerow({'id':'101','name':'makerliu','gender':'female'})
9 writer.writerow({'id':'102','name':'makerqin','gender':'male'})
First, the header information is defined by fieldnames, and then passed to DictWriter to initialize a dictionary to write the object, then write the header information in writeheader() method, and finally call writerow() method to pass the dictionary.
If you want to append writing, you can change the second parameter of the open() method to a, and the code is as follows:
1 with open('demo.csv','a',encoding='utf-8') as csvf
3.5 reading CSV files
We can read the contents of the file just written. The code is as follows:
1 import csv
2
3 with open('demo.csv','r',encoding='utf-8') as csvf:
4 datas = csv.reader(csvf)
5 for data in datas:
6 print(data)
The output results are as follows:
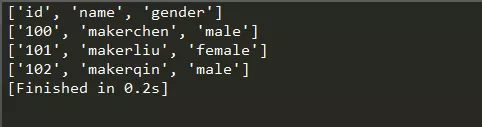
Output the contents of each line through traversal, and each line is in the form of a list
Note: if the CSV file contains Chinese, you also need to specify the file code
Of course, you can also use read in the pandas library_ The CSV () method reads the data from CSV:
1 import pandas as pd
2
3 data = pd.read_csv('demo.csv')
4 print(data)
This method is used more in data analysis, and it is also a convenient method to read CVS files
4, Excel file storage
4.1 xlwt data writing
Excel files contain text, values, formulas and formats, which are not included in CSV. The default opening code is Unicode. It is a popular data storage format
Basic write mode
Here, we call the xlwt library to write Excel data. The code is as follows:
1 import xlwt
2
3 file = xlwt.Workbook(encoding='utf-8')
4 table = file.add_sheet('data')
5 datas = [
6 ['python trainee','Guiyang','undergraduate'],
7 ['java trainee','Hangzhou','undergraduate'],
8 ['Reptile Engineer','Chengdu','master']
9 ]
10 for i,p in enumerate(datas):
11 for j,q in enumerate(p):
12 table.write(i,j,q)
13 file.save('demo.xls')
We first import the xlwt library, then call the Workbook() method to initialize an object that can manipulate the Excel form, and specify the encoding format as utf-8, then create a specified table to write to the data, create a two-dimensional array in the form of a list, and specify the location where we want to add data by two for loops. i here represents the ordinal number of the location of the outer list element. j represents the sequence number of the location of the inner list element, p and Q represent the element values of the outer list and the inner list respectively, table.write(i,j,q) represents inserting data Q in row i and column j, and finally saving the excel file.
The operation effect is as follows:
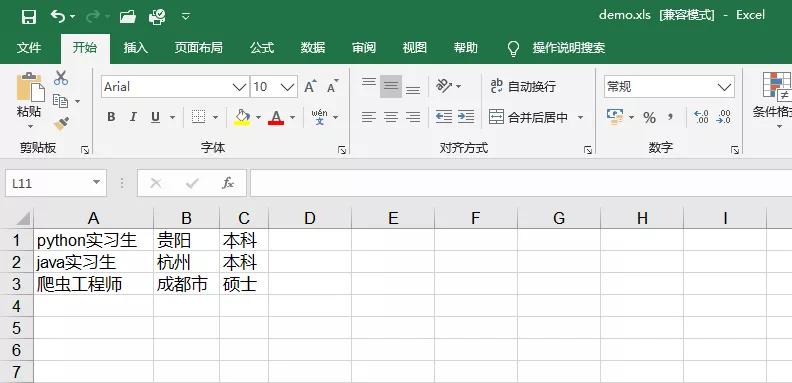
Write mode with serial number
The code is as follows:
1 import xlwt
2
3 file = xlwt.Workbook(encoding = 'utf-8')
4 table = file.add_sheet('data')
5 data = {
6 "1":['python trainee','Guiyang','undergraduate'],
7 "2":['java trainee','Hangzhou','undergraduate'],
8 "3":['Reptile Engineer','Chengdu','master']
9 }
10 ldata = []
11 num = [a for a in data]
12 #The for loop specifies to take out the key value and store it in num, that is, the sequence number
13 num.sort()
14 print(num)
15 #After the dictionary data is taken out, it needs to be sorted first to avoid sequence number confusion
16 for x in num:
17 #The for loop saves the keys and values in the data dictionary in ldata in batches
18 t = [int(x)]
19 for a in data[x]:
20 print(t)
21 t.append(a)
22 print(t)
23 ldata.append(t)
24 print(ldata)
25
26 for i,p in enumerate(ldata):
27 #Write data to the file. i and j are the number of sequence numbers returned by the enumerate() function
28 for j,q in enumerate(p):
29 # print i,j,q
30 table.write(i,j,q)
31 file.save('demo.xls')
The console output is as follows: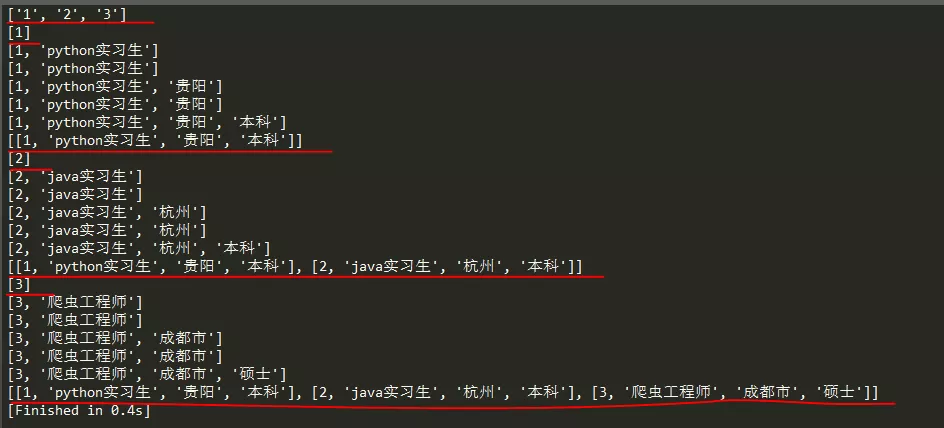 From the above figure, num is a list with sequence numbers. Its value is the key in data, t is a list, and its first value is the sequence number. We convert it into an integer, then use the for loop to traverse each field value of value in data, and add these field values to the list t in turn; Because we need to insert the data into Excel in the form of two-dimensional array to locate the insertion position, we need to build a list ldata, and finally add the list t to the list ldata, so as to form a two-dimensional array. The following writing method is the same as the first writing method above
From the above figure, num is a list with sequence numbers. Its value is the key in data, t is a list, and its first value is the sequence number. We convert it into an integer, then use the for loop to traverse each field value of value in data, and add these field values to the list t in turn; Because we need to insert the data into Excel in the form of two-dimensional array to locate the insertion position, we need to build a list ldata, and finally add the list t to the list ldata, so as to form a two-dimensional array. The following writing method is the same as the first writing method above
Excel works as follows:
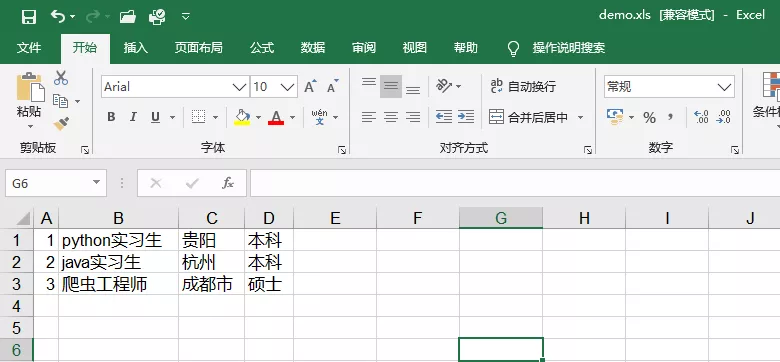
Note: due to the compatibility of Excel versions supported by xlwt, only Excel 97-2003(.xls) is supported, and Excel 2010(.xlsx) and Excel 2016(*.xlsx) are not supported. Therefore, the suffix must be. xls when saving, otherwise the following error message may appear:

4.2 xlrd data reading
Here we use the data demo.xls just written to read. The code is as follows:
1 import xlrd
2
3 def read(xlsfile):
4 file = xlrd.open_workbook(xlsfile) # Get the book object of Excel file and instantiate the object
5 sheet0 = file.sheet_by_index(0) # Get the sheet object through the sheet index
6 # sheet1 = book.sheet_by_name(sheet_name) # It is obtained through the sheet name. Of course, if you know the sheet name, you can specify it directly
7 nrows = sheet0.nrows # Get the total number of rows
8 ncols = sheet0.ncols # Gets the total number of columns
9 list = []
10 for i in range(nrows):
11 list.append([])
12 for j in range(ncols):
13 # print(sheet0.cell_value(i, j))
14 list[i].append(str(sheet0.cell_value(i, j)))
15 print(list)
16 return list
17
18
19 def excel_to_data():
20 list = read('demo.xls')
21 for lis in list:
22 print(lis)
23
24 if __name__ == '__main__':
25 excel_to_data()
First, call open of xlrd_ The Workbook () method creates an object to manipulate the Excel file, and then uses the sheet_by_index(index) method or sheet_ by_ The name (sheet_name) method obtains the sheet object according to the index and sheet name, then obtains the total number of rows and columns of the data, and calls the cell of the sheet object through two for loops_ Value (I, J) get the value of the cell, convert it into string type, and then add it to the list according to the index to form a two-dimensional array, output and return it. Finally, traverse each element of the two-dimensional array (each list) for output
The console output is as follows:
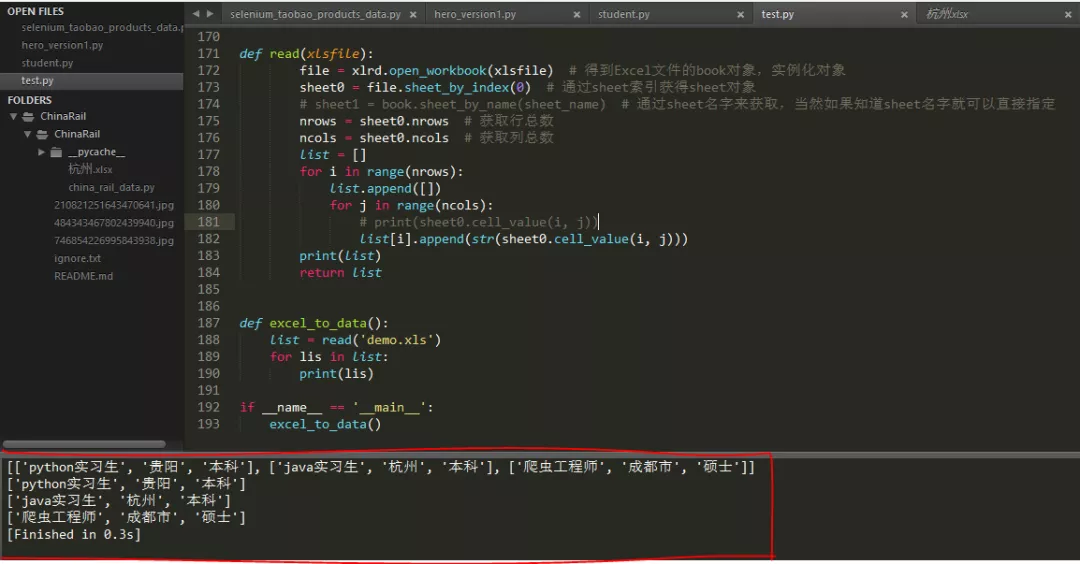
Note: xlrd supports reading Excel files with suffix. xls and. xlsx; And whether xlwt or xlrd, the starting index position of the data is 0
4.3 pandas writing or reading Excel
pandas read
We still use the demo.xls above:
1 import pandas as pd
2
3 data = pd.read_excel('demo.xls')
4 print(data)
5 print(type(data))
Let's take a look at the console output:
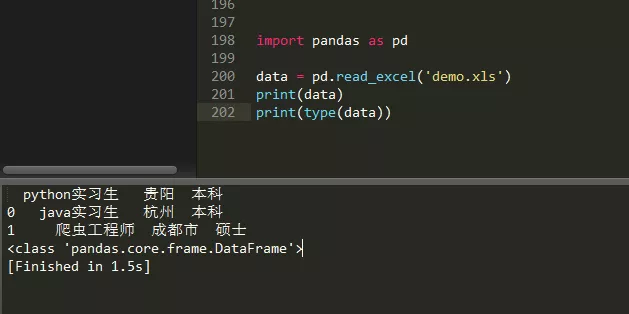 We can observe the read through the pandas library_ Excel () method seems simpler, but it is more inclined to data analysis. Note that the data type is DataFrame, and the output data has serial numbers
We can observe the read through the pandas library_ Excel () method seems simpler, but it is more inclined to data analysis. Note that the data type is DataFrame, and the output data has serial numbers
pandas write
1 import pandas as pd
2
3 data = pd.DataFrame([['python trainee','Guiyang','undergraduate'],['java trainee','Hangzhou','undergraduate'],['Reptile Engineer','Chengdu','master']])
4 data.to_excel('demo.xlsx')
Excel works as follows:
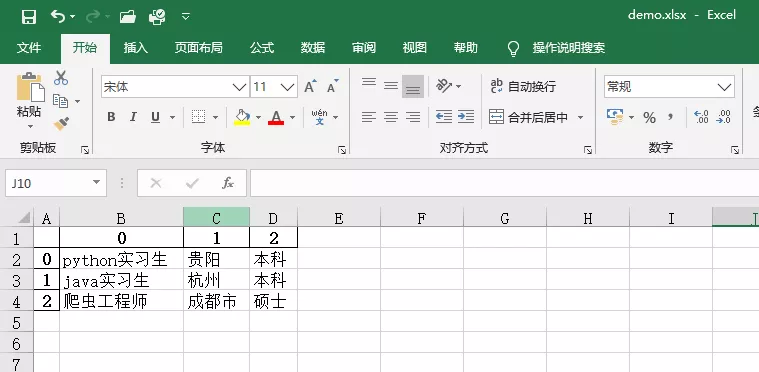
The data stored by the DataFrame() method of pandas library is with index serial number, which is convenient for data analysis and modeling
Note: the pandas library supports Excel tables with the suffix. xlsx
4.4 openpyxl writing or reading Excel
openpyxl write
1 import openpyxl
2
3 wb = openpyxl.Workbook()
4 ws = wb.create_sheet('data')
5 ws.cell(row=1,column=1).value="position"
6 ws.cell(row=1,column=2).value="position"
7 ws.cell(row=1,column=3).value="academic degree"
8 wb.save('demo.xlsx')
Excel works as follows:
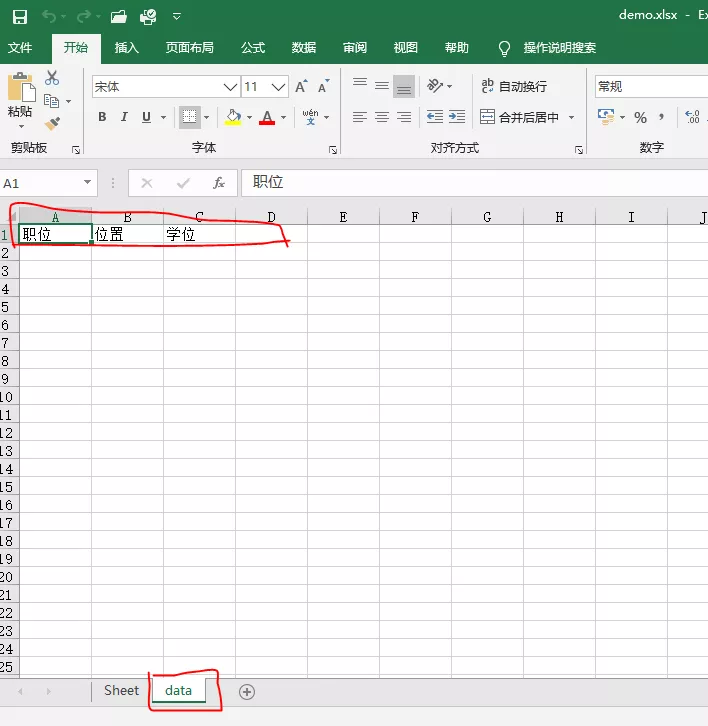
openpyxl read
1 import openpyxl
2
3 wb = openpyxl.load_workbook('demo.xlsx')
4 ws = wb.get_sheet_by_name('data')
5 rows = ws.max_row
6 columns = ws.max_column
7 datas = []
8 for i in range(1,rows+1):
9 for j in range(1,columns+1):
10 datas.append(str(ws.cell(i,j).value))
11 print(datas)
The console output is as follows:
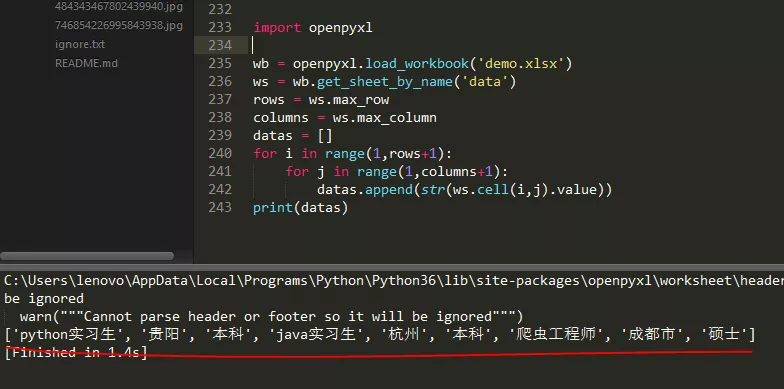
Note: openpyxl only supports Excel files with the suffix. xlsx, and the index position for reading or writing data is 1
I recommend xlrd, xlwt and pandas. When these libraries operate Excel files, the starting index position of data is 0, which is more convenient, but it can also be determined according to personal usage habits and needs
5, Author Info
Author: Xiao Hong's daily fishing
The original WeChat official account: "little hung starsky technology", focusing on algorithms, crawlers, websites, game development, etc., we look forward to your attention. Let's grow together and Coding together.
Reprint: Please specify the source (Note: from the official account: Xiao Hong Xing Kong technology, author: Xiao Hong's daily fishing routine)