preface
Recently, a customer of the company used PostgreSql to store data. In the export function, it was found that in the case of big data, the memory will grow until it overflows. Because the fetchSize is set for stream query in the export function, there will be no memory overflow. Then the investigation found that all the data were obtained, which would certainly overflow the memory.
What is stream query? Link here after writing the next article.
catalogue
1. Troubleshooting ideas
First of all, since the memory overflows, you must first check the overflow place and why it overflows.
1.1 the received bug is the export function. The memory keeps growing and does not release until it overflows. At this time, it is simple. Directly open the java built-in jvisualvm to monitor the memory occupation and thread dump during export
1.2 after monitoring by jvisualvm, it is found that the thread has no deadlock or the wait is too long, and it is found that the thread with the longest time is in the CSVExport method. At this time, it can be judged that this method causes memory overflow
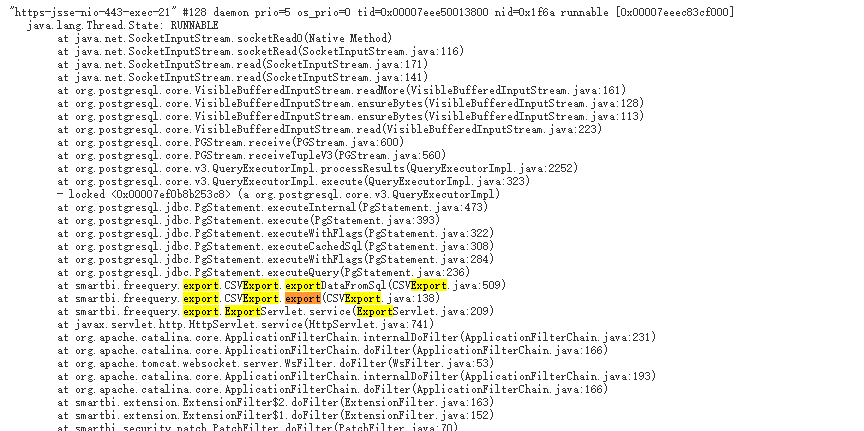
1.3 then go to the memory monitoring interface to see which object has occupied the memory all the time. Later, it is found that it is celldata (product data storage object). It is found that the number of instances is very high and the memory is not released during GC in eden area. It is obvious that all the data in the database are obtained.
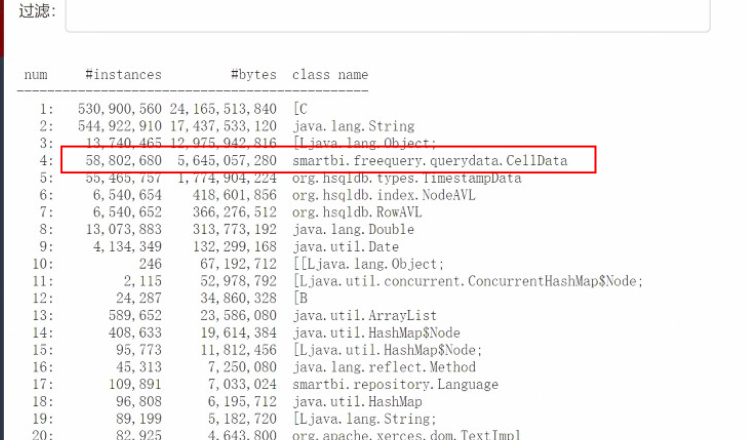
Link: See this blog for the calculation method of object memory.
1.4 but I'm confused again, because in our export system, if it is big data export, fetchSize will be set and cursor query will be set to obtain data. At this time, all data will not be obtained in memory. If all data is in memory, the only possibility is that cursor query does not take effect. At this point, we need to solve why the cursor query does not take effect
2. Solving process
1.1 first of all, we should understand that the cursor query does not take effect, which may be due to the problem of database settings, such as Mysql cursor query does not take effect For ordinary databases such as oracle, simply set setFetchSize() to jdbc to start cursor query. However, the current source database is PostgreSql. At this time, you have to look at the PostgreSql document and source code to see when to start cursor query.
1.2 through documents: https://jdbc.postgresql.org/documentation/head/connect.html , it is found that stream query is indeed supported
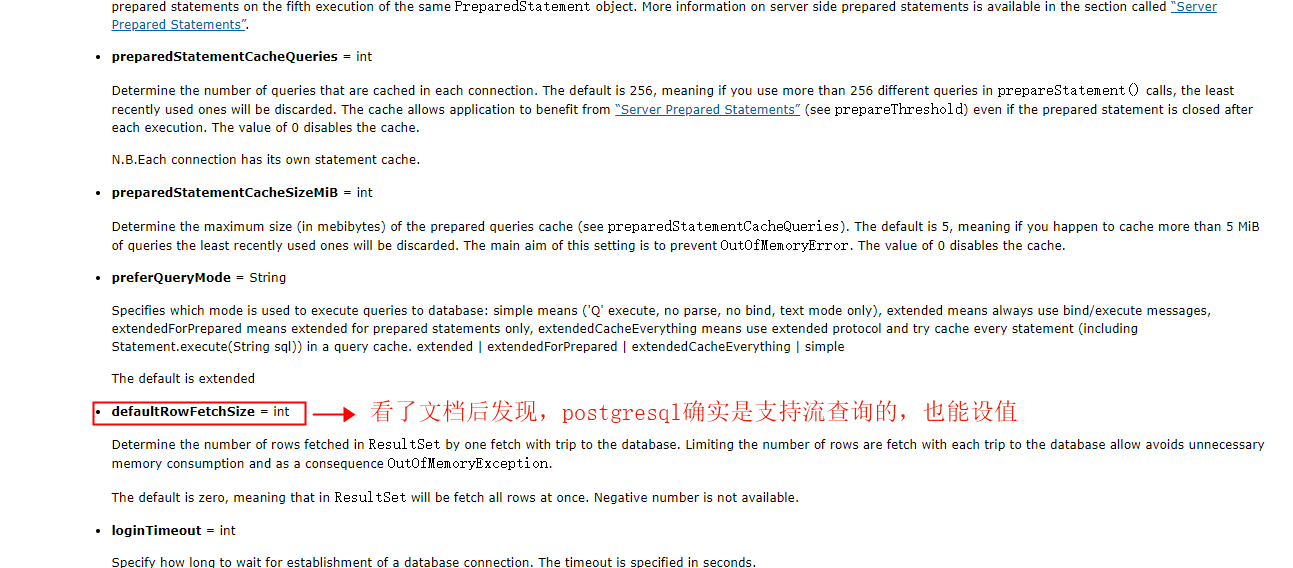
1.3 the problem of invalid mysql cursor query has been handled before, so it is suspected that it is the problem of connection string, but it is found that nothing is set, but preferQueryMode =simple is set, and then try to remove this attribute. Later, we found that we succeeded in using stream query to obtain data! But why? You have to follow the source code (the memory overflow problem has been solved at this time)
3. Source code analysis
1. First, we have to get the source code of postgreSql: https://github.com/pgjdbc Pull down the jdbc source code of postgreSql from GitHub
2. Since jdbc packages data by returning resultSet, to judge whether it is a streaming query, basically, you need to find a method similar to getResultSet to see how to open the query logic
3. Find class:
postgresql-9.4.1212.jre7-sources.jar!/org/postgresql/jdbc/PgPreparedStatement.java
It is found that the method is executeInternal
private void executeInternal(CachedQuery cachedQuery, ParameterList queryParameters, int flags)
throws SQLException {
closeForNextExecution();
// Enable cursor-based resultset if possible.
if (fetchSize > 0 && !wantsScrollableResultSet() && !connection.getAutoCommit()
&& !wantsHoldableResultSet()) {
flags |= QueryExecutor.QUERY_FORWARD_CURSOR;
}
if (wantsGeneratedKeysOnce || wantsGeneratedKeysAlways) {
flags |= QueryExecutor.QUERY_BOTH_ROWS_AND_STATUS;
// If the no results flag is set (from executeUpdate)
// clear it so we get the generated keys results.
//
if ((flags & QueryExecutor.QUERY_NO_RESULTS) != 0) {
flags &= ~(QueryExecutor.QUERY_NO_RESULTS);
}
}
if (isOneShotQuery(cachedQuery)) {
flags |= QueryExecutor.QUERY_ONESHOT;
}
// Only use named statements after we hit the threshold. Note that only
// named statements can be transferred in binary format.
if (connection.getAutoCommit()) {
flags |= QueryExecutor.QUERY_SUPPRESS_BEGIN;
}
// updateable result sets do not yet support binary updates
if (concurrency != ResultSet.CONCUR_READ_ONLY) {
flags |= QueryExecutor.QUERY_NO_BINARY_TRANSFER;
}
Query queryToExecute = cachedQuery.query;
if (queryToExecute.isEmpty()) {
flags |= QueryExecutor.QUERY_SUPPRESS_BEGIN;
}
if (!queryToExecute.isStatementDescribed() && forceBinaryTransfers
&& (flags & QueryExecutor.QUERY_EXECUTE_AS_SIMPLE) == 0) {
// Simple 'Q' execution does not need to know parameter types
// When binaryTransfer is forced, then we need to know resulting parameter and column types,
// thus sending a describe request.
int flags2 = flags | QueryExecutor.QUERY_DESCRIBE_ONLY;
StatementResultHandler handler2 = new StatementResultHandler();
connection.getQueryExecutor().execute(queryToExecute, queryParameters, handler2, 0, 0,
flags2);
ResultWrapper result2 = handler2.getResults();
if (result2 != null) {
result2.getResultSet().close();
}
}
StatementResultHandler handler = new StatementResultHandler();
result = null;
try {
startTimer();
connection.getQueryExecutor().execute(queryToExecute, queryParameters, handler, maxrows,
fetchSize, flags);
} finally {
killTimerTask();
}
result = firstUnclosedResult = handler.getResults();
if (wantsGeneratedKeysOnce || wantsGeneratedKeysAlways) {
generatedKeys = result;
result = result.getNext();
if (wantsGeneratedKeysOnce) {
wantsGeneratedKeysOnce = false;
}
}
}
In fact, it can be found that there are flags | = queryexecution.query_ FORWARD_ Cursor's judgment means that the current way to obtain data is to directly use the value obtained from the variable flags. Then we can see that if you want to query by cursor, you need to meet this judgment:
fetchSize > 0 && !wantsScrollableResultSet() && !connection.getAutoCommit()
&& !wantsHoldableResultSet()
/** First
1, fetchSize Set it to be greater than 0 (we set fetchsize, so it must be greater than 0)
2,wantsScrollableResultSet()Must be false (later)
3,connection.getAutoCommit()It cannot be submitted automatically. In this case, jdbc.setCommit(false) is sufficient
4, !wantsHoldableResultSet() (The code directly returns false, so this is not considered) */
// In the source code
protected boolean wantsScrollableResultSet() {
return resultsettype != ResultSet.TYPE_FORWARD_ONLY;
}
// statement defaults to TYPE_FORWARD_ONLY. In fact, wantsScrollableResultSet can also be ignored
But for now, if all four of our conditions are true, we should call flags | = queryexecution.query in the method_ FORWARD_ CURSOR; But why not?
Because: flags is not a boolean, but an int type, which is mainly used to match the query by value size
// I won't post the code. Let me see the path myself
/**
processResults Method to get data
postgresql-9.4.1212.jre7-sources.jar!/org/postgresql/core/v3/QueryExecutorImpl.java*/
/**
In fact, the general process is like this
1,Calculate the falls value through a series of judgments
2,Judge the value of falls in the processResults method. If it is greater than xx, other queries will be used.
3,On the whole, because preferQueryMode =simple was set just now, the following judgment will be entered. Look at the enumeration of queryexecution class, QUERY_EXECUTE_AS_SIMPLE is very large. If this value is set, it will directly overwrite the cursor query.
*/
if (connection.getPreferQueryMode() == PreferQueryMode.SIMPLE) {
flags |= QueryExecutor.QUERY_EXECUTE_AS_SIMPLE;
}
summary
To sum up, if PostgreSql wants to use cursor query, it needs the following conditions
1. fechSize setting > 0
2. jdbc connection string cannot be added with preferQueryMode =simple
3. autocommit needs to be set to false