Micro front end is a popular technical architecture at present. Many readers privately asked me about its principle. In order to clarify the principle, I will lead you to implement a micro front-end framework from scratch, which includes the following functions:
• how to perform route hijacking • how to render sub applications • how to implement JS sandbox and style isolation • function of improving experience
In addition, in the process of implementation, the author will also talk about what technical solutions can be used to realize the micro front end and what implementation methods are available when doing the above functions.
Here is the final output warehouse address of this article: Toy micro [1].
Implementation scheme of micro front end
There are many implementation schemes for the micro front end, such as:
1.qiankun[2], ICESTAR [3] implements JS and style isolation by itself 2.emp[4], Webpack 5 Module Federation scheme 3.iframe, WebComponent and other schemes, browser native isolation, but there are some problems
Update: there was an error here. The author mistakenly said that the technical solution of ICESTAR was iframe.
However, the scenario problems solved by so many implementation solutions are still divided into two categories:
• single instance: there is only one sub application on the current page, generally using qiankun • multiple instances: there are multiple sub applications on the current page, and browser native isolation schemes, such as iframe or WebComponent, can be used
Of course, it does not mean that a single instance can only use qiankun. The browser native isolation scheme is also feasible, as long as you accept the shortcomings they bring:
The biggest feature of iframe is that it provides a browser native hard isolation scheme, which can perfectly solve problems such as style isolation and js isolation. However, his biggest problem is that his isolation cannot be broken through, resulting in the failure to share the context between applications, resulting in the problems of development experience and product experience.
The above is taken from Why Not Iframe[5].
The implementation scheme of this paper is consistent with qiankun, but the functions and principles involved are general. You also need these for another implementation scheme.
Front work
Before the official start, we need to build a development environment. Here, you can arbitrarily choose the technology stack of the main / sub applications, such as React for the main application and Vue for the sub application. Each application initializes the project with the corresponding scaffold tool. There is no need to initialize the project with everyone here. Remember that if it's a React project, you need to execute the yarn eject again.
It is recommended that you directly use the example folder in the author's warehouse [6]. All the configurations are configured. You just need to follow the author step by step to build a micro front-end. In the example, the main application is React and the sub application is Vue. Finally, the directory structure we generated is roughly as follows:

Screenshot 10.15.01 PM, August 30, 2021
text
Before reading the text, I assume that readers have used the micro front-end framework and understand its concepts. For example, they know that the main application is responsible for the overall layout and the configuration and registration of sub applications. If you haven't used it yet, you are recommended to briefly read any of the micro front-end framework usage documents.
Application registration
After we have the main application, we need to register the information of sub applications in the main application, including the following blocks:
• name: sub application NOUN • entry: resource entry of the sub application • container: node where the main application renders the sub application • activeRule: under which routes the sub application is rendered
In fact, this information is very similar to registering routes in the project. entry can be regarded as a component to be rendered, container can be regarded as a node for route rendering, and activeRule can be regarded as a rule for how to match routes.
Next, let's implement the function of this registered sub application:
// src/types.tsexport interface IAppInfo { name: string; entry: string; container: string; activeRule: string;}// src/start.tsexport const registerMicroApps = (appList: IAppInfo[]) => { setAppList(appList);};// src/appList/index.tslet appList: IAppInfo[] = [];export const setAppList = (list: IAppInfo[]) => { appList = list;};export const getAppList = () => { return appList;};The above implementation is very simple. You only need to save the appList passed in by the user.
routing detours
After having a list of sub applications, we need to start the micro front end to render the corresponding sub applications, that is, we need to judge the path and render the corresponding applications. However, before proceeding to the next step, we need to consider a problem: how to monitor the change of routing to determine which sub application to render?
For projects with non SPA (single page application) architecture, this is not a problem at all, because we only need to judge the current URL and render the application when starting the micro front end; However, in the SPA architecture, the change of route will not cause page refresh, so we need a way to know the change of route, so as to judge whether it is necessary to switch sub applications or do nothing.
If you understand the principle of Router library, you should be able to think of a solution immediately. If you don't understand, you can read the author's previous article [7].
In order to take care of readers who don't understand, the author first briefly talks about the routing principle.
At present, single page applications use routing in two ways:
1.hash mode, that is, the #2.histoy mode carried in the URL, that is, the common URL format
The author will use two illustrations to show which events and API s are involved in the two modes:

img
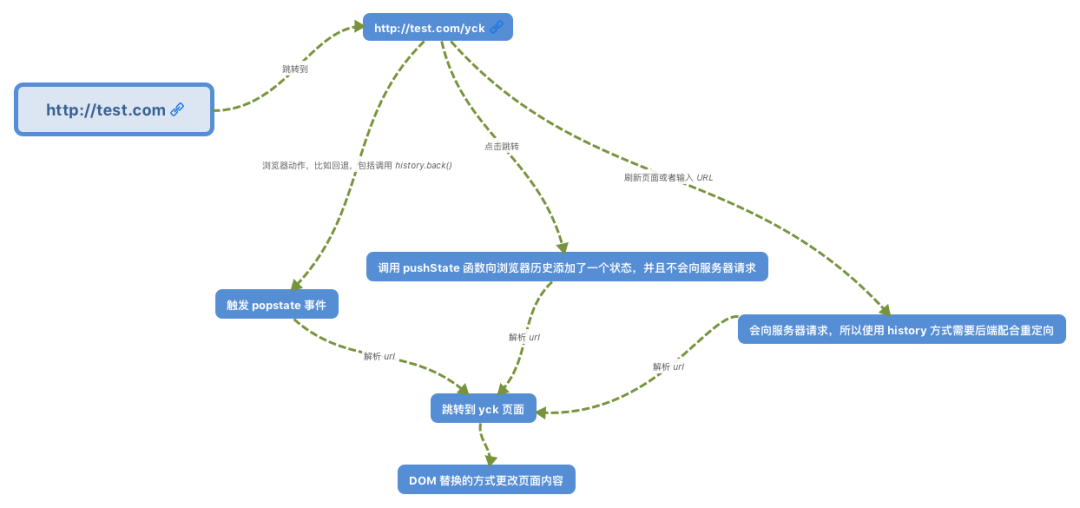
img
From the above figure, we can find that two events will be involved in routing change:
•popstate•hashchange
Therefore, we certainly need to monitor these two events. In addition, calling pushState and replaceState will also cause routing changes, but will not trigger events. Therefore, we need to rewrite these two functions.
After knowing what events to listen to and what functions to rewrite, let's implement the code:
// src/route/index.ts / / save the original method const originalpush = window.history.pushstate; const originalReplace = window.history.replaceState; Export const hijackroute = () = > {/ / rewrite the method window.history.pushstate = (... Args) = > {/ / call the original method originalpush.apply (window.history, args); / / change the logic of the URL, which is actually how to handle the sub application / /...}; window.history.replacestate = (... Args) = > {originalreplace.apply (window.history, args) ; / / url change logic / /...}; / / listen to events and trigger URL change logic window.addeventlistener ("hashchange", () = > {}); window.addeventlistener ("pop state", () = > {}); / / rewrite window.addeventlistener = hijackeventlistener (window. Addeventlistener); window.removeeventlistener = hijackeventlistener (window. Removeeventlistener);}; const capturedListeners: Record<EventType, Function[]> = { hashchange: [], popstate: [],}; const hasListeners = (name: EventType, fn: Function) => { return capturedListeners[name].filter((listener) => listener === fn).length;}; Const hijackeventlistener = (func: function): any = > {return function (Name: string, FN: function) {/ / save the callback function if (name = = = "hashchange" | name = = = "pop state") {if (! Haslisteners (name, FN)) {capturedlisteners [name]. Push (FN); return;} else {capturedlisteners [name] = capturedListeners[name].filter( (listener) => listener !== fn ); } } return func.apply(window, arguments); };};// It is used after subsequent rendering sub applications to execute the callback function export function callcapturedlisteners() {if (historyevent) {object. Keys (capturedlisteners). Foreach ((eventName) = > {const listeners = capturedlisteners [eventName as eventtype] if (listeners. Length) {listeners. Foreach ((listener) = > { // @ts-ignore listener.call(this, historyEvent) }) } }) historyEvent = null }}The above code looks at many lines. The actual work is very simple. It is generally divided into the following steps:
1. rewrite the pushState and replaceState methods. After the original method is invoked in the method, how to handle the logic of the sub application 2. monitor the hashchange and popstate events, how to handle the logic of the sub application after the event is triggered, and 3. to rewrite the listener / remove event function. If the hashchange and popstate events are monitored, the callback function is saved for later use.
Application lifecycle
After implementing route hijacking, we now need to consider how to implement the logic of handling sub applications, that is, how to handle sub applications, load resources, mount and unload sub applications. See here, do you think this is very similar to components. Components also need to handle these things, and will expose the corresponding life cycle to users to do what they want to do.
Therefore, for a sub application, we also need to implement a set of life cycle. Since the sub application has a life cycle, the main application must also have a life cycle, and it must correspond to the sub application life cycle.
So here we can sort out the life cycle of main / sub applications.
For the main application, it is divided into the following three life cycles:
1.beforeLoad: before attaching the sub application 2.mounted: after attaching the sub application 3.unmounted: uninstall the sub application
Of course, if you want to increase the life cycle, there is no problem at all. The author has only realized three for simplicity.
For the sub application, the general is also divided into the following three life cycles:
1.bootstrap: triggered when the application is loaded for the first time, which is often used to configure the global information of sub applications. 2.mount: triggered when the application is mounted, which is often used to render sub applications. 3.unmount: triggered when the application is unloaded, which is often used to destroy sub applications
Next, we will implement the registration main application life cycle function:
// Src / types.tsexport interface ilifecycle {beforeload?: lifecycle | lifecycle []; mounted?: lifecycle | lifecycle []; unmounted?: lifecycle | lifecycle [];} / / SRC / start.ts / / rewrite the previous export const registermicroapps = (applist: iappinfo [], lifecycle?: ilifecycle) = > {setapplist (applist); lifecycle & & setlifecycle (lifecycle);} ;// src/lifeCycle/index.tslet lifeCycle: ILifeCycle = {};export const setLifeCycle = (list: ILifeCycle) => { lifeCycle = list;};Because it is the life cycle of the main application, we register it when we register the sub application.
Then the lifecycle of the sub application:
// src/enums.ts / / set subapplication statusexport enum appstatus {not_loaded = "not_loaded", loading = "loading", loaded = "loaded", bootstrapping = "bootstrapping", not_mounted = "not_mounted", mounting = "mounting", mounted = "mounted", unmounting = "unmounting",} / / Src / lifecycle / index.tsexport const runbeforeload = Async (app: iiinternalappinfo) = > {app. Status = appstatus. Loading; await runlifecycle ("beforeload", APP); app = await loading sub app resources; app. Status = appstatus. Loaded;}; export const runboost = async (app: iiinternalappinfo) = > {if (app. Status! = = appstatus. Loaded) {return app;} app.status = AppStatus.BOOTSTRAPPING; await app.bootstrap?.(app); app.status = AppStatus.NOT_MOUNTED;};export const runMounted = async (app: IInternalAppInfo) => { app.status = AppStatus.MOUNTING; await app.mount?.(app); app.status = AppStatus.MOUNTED; await runLifeCycle("mounted", app);};export const runUnmounted = async (app: IInternalAppInfo) => { app.status = AppStatus.UNMOUNTING; await app.unmount?.(app); app.status = AppStatus.NOT_MOUNTED; await runLifeCycle("unmounted", app);};const runLifeCycle = async (name: keyof ILifeCycle, app: IAppInfo) => { const fn = lifeCycle[name]; if (fn instanceof Array) { await Promise.all(fn.map((item) => item(app))) ; } else { await fn?.(app); }};The above code looks a lot, and the actual implementation is also very simple. The summary is:
• set sub application status for logical judgment and optimization. For example, when an application status is not not_ When loaded (each application is initially in NOT_LOADED state), there is no need to repeatedly load resources when rendering the application next time • if processing logic is required, for example, beforeLoad, we need to load sub application resources • execute the main / sub application life cycle. Note the execution sequence here. You can refer to the life cycle execution sequence of parent and child components
Improve route hijacking
After implementing the application life cycle, we can now improve the logic of "how to deal with sub applications" that was not done in the previous route hijacking.
This logic is actually very simple after we finish the life cycle, which can be divided into the following steps:
1. Judge whether the current URL is consistent with the previous URL. If it is consistent, continue. 2. Use the URL to match the corresponding sub application. At this time, there are several situations: • start the micro front end for the first time, and only render the sub application that matches successfully • do not switch the sub application, and there is no need to process the sub application • switch the sub application, and find the previously rendered sub application for unloading, Then render the sub application that matches successfully. 3. Save the current URL for the next step
After sorting out the steps, let's implement it:
let lastUrl: string | null = nullexport const reroute = (url: string) => { if (url !== lastUrl) { const { actives, unmounts } = Match routes and find qualified sub applications // Execute lifecycle promise.all (unmounts. Map (async (APP) = > {await rununmounted (APP)}). Concat (active. Map (async (APP) = > {await runbeforeload (APP) await runboost (APP) await runmounted (APP)})). Then (() = > {/ / execute the function callcapturedlisteners()})} lasturl = URL | location. Href}The above code body is executing the life cycle functions in order, but the function matching the route is not implemented, because we need to consider some problems first.
You must have used routing in project development at ordinary times. You should know that the principle of routing matching mainly consists of two parts:
• nested relationships • path syntax
Nesting relationship means that if my current route is set to / vue, then similar routes like / vue or / vue/xxx can match this route unless we set excart, that is, exact matching.
Path syntax the author here directly takes an example from the document:
<Route path="/hello/:name"> // Match / hello/michael and / hello / Ryan < route path = "/ Hello (/: name)" > / / match / hello, /hello/michael and / hello / Ryan < route path = "/ files / *. *" > / / match / files/hello.jpg and / files/path/to/hello.jpg
In this way, the implementation of Route matching is still troublesome. Do we have a simple way to realize this function? The answer must be yes. As long as we read the source code of the Route library, we can find that they all use the path to regexp [8] library internally. Interested readers can read the library documents by themselves. The author has brought it here. We only look at the use of one of the API s.

Screenshot: 10.31.03 PM, September 2, 2021
With the solution, we can quickly implement the following routing matching functions:
export const getAppListStatus = () => { // List of applications to render const active: iiinternalappinfo [] = [] / / list of applications to uninstall const unmounts: iiinternalappinfo [] = [] / / get the list of registered sub applications const list = getapplist() as iiinternalappinfo [] list. Foreach ((APP) = > {/ / match route const isactive = match (app. Activerule, {end: false}) (location. Pathname) //Judge application status switch (app. Status) {case appstatus. Not_loaded: case appstatus. Loading: case appstatus. Loaded: case appstatus. Bootstrapping: case appstatus. Not_mounted: isactive & & activities. Push (APP) break case appstatus. Mounted:! Isactive & & unmounts. Push (APP) break}}) return { actives, unmounts }}After completing the above functions, do not forget to call in the reroute function. At this point, the route hijacking function has been completely completed. The complete code can read [9] here.
Perfect life cycle
Previously, in the process of implementing the life cycle, we still have a very important step "loading sub application resources", which we will finish in this section.
Since we want to load resources, we must first need a resource entry. Just like the npm package we use, each package must have an entry file. Back to the registerMicroApps function, we first passed in the entry parameter to this function, which is the resource entry of the sub application.
There are actually two schemes for resource entry:
1.JS Entry2.HTML Entry
Both schemes are literal. The former loads all static resources through JS, while the latter loads all static resources through HTML.
JS Entry is a method used in single spa [10]. However, it is a little restrictive. Users need to package all files together. Unless your project is insensitive to performance, you can basically pass this scheme.
HTML Entry is much better. After all, all websites use HTML as the entry file. In this scheme, we basically do not need to change the packaging method, which is almost non-invasive to user development. We only need to find the static resources in HTML, load and run to render the sub application, so we chose this scheme.
Next, let's start to implement this part.
load resources
First, we need to get the HTML content. Here, we can get things by calling the native fetch.
// src/utilsexport const fetchResource = async (url: string) => { return await fetch(url).then(async (res) => await res.text())}// src/loader/index.tsexport const loadHTML = async (app: IInternalAppInfo) => { const { container, entry } = app const htmlFile = await fetchResource(entry) return app}In the author's warehouse [11] example, after we switch the route to / vue, we can print out the contents of the loaded HTML file.
<!DOCTYPE html><html lang=""> <head> <meta charset="utf-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width,initial-scale=1.0"> <link rel="icon" href="/favicon.ico"> <title>sub</title> <link href="/js/app.js" rel="preload" as="script"><link href="/js/chunk-vendors.js" rel="preload" as="script"></head> <body> <noscript> <strong>We're sorry but sub doesn't work properly without JavaScript enabled. Please enable it to continue.</strong> </noscript> <div id="app"></div> <!-- built files will be auto injected --> <script type="text/javascript" src="/js/chunk-vendors.js"></script> <script type="text/javascript" src="/js/app.js"></script></body></html>
We can see some static resource URL s of relative paths in this file. Next, we need to load these resources. However, we should note that these resources can be loaded correctly only under their own BaseURL. If they are under the BaseURL of the main application, they must report a 404 error.
Then we need to pay attention to one thing: because we load the resources of sub applications under the URL of the main application, it is likely to trigger cross domain restrictions. Therefore, in the development and production environment, we must pay attention to cross domain processing.
For example, if the sub application of the development environment is Vue, the cross domain processing method:
// vue.config.jsmodule.exports = { devServer: { headers: { 'Access-Control-Allow-Origin': '*', }, },}Next, we need to deal with the paths of these resources first, splice the relative paths into the correct absolute paths, and then fetch.
// Src / utilsexport function getcompletionurl (SRC: string | null, baseuri: String) {if (! SRC) return Src / / if the URL is already at the beginning of the protocol, directly return if (/^(https|http)/.test(src)) return src / / splice the URL through the native method return new URL (SRC, getcompletionbaseurl (baseuri)). Tostring()} //Obtain the complete BaseURL / / because the user may fill / / xxx or https://xxx Urlexport function getcompletionbaseurl (URL: String) {return URL. Startswith ('/ /')? ` ${location. Protocol} ${URL} `: URL}The functions of the above code will not be repeated. The comments have been very detailed. Next, we need to find the resources in the HTML file and go to fetch.
Since we are looking for resources, we have to parse the HTML content:
// Src / loader / parse.tsexport const parsehtml = (parent: HtmlElement, app: iiinternationalappinfo) = > {const children = array. From (parent. Children) as HtmlElement [] children. Length & & children. Foreach ((item) = > parsehtml (item, APP)) for (const dom of children) {if (/ ^ (link) $/ I.Test (DOM. TagName)) {/ / processing link} else if (/ ^ (script) $/ I.Test (DOM. TagName)) {/ / process script} else if (/ ^ (IMG) $/ I.Test (DOM. TagName) & & dom. Hasattribute ('src ')) {/ / process pictures. After all, the picture resources must 404 dom. SetAttribute ('src', getcompletionurl (DOM. Getattribute ('src '), app. Entry)!)}} return {}}}Parsing the content is still simple. We can recursively find the elements, find the link, script and img elements and do the corresponding processing.
First, let's look at how we deal with link:
// src/loader/parse.ts / / complete parseHTML logic if (/ ^ (link) $/ I.Test (DOM. TagName)) {const data = parselink (DOM, parent, APP) data & & links. Push (data)} const parselink = (link: HtmlElement, parent: HtmlElement, app: iiinternalappinfo) = > {const rel = link. Getattribute ('rel ') const href = link. Getattribute ('href') Let comment: comment | null / / judge whether to obtain CSS resources if (REL = = = 'stylesheet' & & href) {comment = document. Createstatement (` link replaced by micro '/ / @ TS ignore Comment & & parent.replacechild (comment, script) return getcompletionurl (href, app. Entry)} else if (href) {link. SetAttribute ('href', getcompletionurl) (href, app.entry)!) }}When dealing with the link tag, we only need to deal with CSS resources, and these resources of other preload / prefetch can directly replace href.
// src/loader/parse.ts / / complete parseHTML logic if (/ ^ (link) $/ I.Test (DOM. TagName)) {const data = parsescript (DOM, parent, APP) data.text & & inlinescript.push (data. Text) data.url & & scripts.push (data. URL)} const parsescript = (script: HtmlElement, parent: HtmlElement, app: iiinternalappinfo) = > {let comment: comment | null const SRC = script. Getattribute ('src ') / / SRC indicates that it is a JS file, but no SRC indicates that it is inline script, that is, the JS code is written directly into the tag if (SRC) {comment = document. Createcomponent ('script replaced by micro')} else if (script. InnerHTML) {comment = document. Createcomponent ('inline script replaced by micro') } // @ts-ignore comment && parent.replaceChild(comment, script) return { url: getCompletionURL(src, app.entry), text: script.innerHTML }}When dealing with script tags, we need to distinguish between JS files and inline code. The former also needs fecth to get the content at one time.
Then we will return all parsed scripts, links and inlinescript in parseHTML.
Next, we load CSS first and then JS files in order:
// src/loader/index.tsexport const loadHTML = async (app: IInternalAppInfo) => { const { container, entry } = app const fakeContainer = document.createElement('div') fakeContainer.innerHTML = htmlFile const { scripts, links, inlineScript } = parseHTML(fakeContainer, app) await Promise.all(links.map((link) => fetchResource(link))) const jsCode = ( await Promise.all(scripts.map((script) => fetchResource(script))) ).concat(inlineScript) return app}Above, we have realized from loading HTML files to parsing files to finding out all static resources to finally loading CSS and JS files. However, in fact, our implementation is still a little rough. Although we have implemented the core content, there are still some details that are not considered.
Therefore, we can also consider directly using the third-party library to realize the process of loading and parsing files. Here we choose the import HTML entry [12] library. The internal work is consistent with our core, but many details are handled.
If you want to use this library directly, you can change the loadHTML into this:
export const loadHTML = async (app: IInternalAppInfo) => { const { container, entry } = app // Template: Processed HTML content / / getExternalStyleSheets: fetch CSS file / / getExternalScripts: fetch JS file const {template, getExternalScripts, getExternalStyleSheets} = await importentry (entry) const DOM = document.queryselector (container) if (! DOM) {throw new error ('container does not exist ')} //Mount HTML on the micro front-end container dom.innerHTML = template / / load the file await getExternalStyleSheets() const jscode = await getExternalScripts() return app}Run JS
When we get all the JS content, we should run JS. After this step is completed, we can see that the sub application is rendered on the page.
The content of this section can be written in a few lines of code if it is simple. If it is complex, it will need to consider many details. Let's implement the simple part first, that is, how to run JS.
For a JS string, there are roughly two ways to execute it:
1.eval(js string)2.new Function(js string)()
Here, we choose the second method:
const runJS = (value: string, app: IInternalAppInfo) => { const code = ` ${value} return window['${app.name}'] ` return new Function(code).call(window, window)}I don't know if you still remember that we set a name attribute for each sub application when registering the sub application. This attribute is actually very important and will be used in subsequent scenarios. In addition, when setting the name for the sub application, don't forget to slightly change the packaging configuration and set one of the options to the same content.
For example, if we set name: vue for a sub application of Vue in one of the technology stacks, we also need to set the following settings in the packaging configuration:
// Vue.config.jsmodule.exports = {configurewebpack: {output: {/ / same as name library: `vue `},},}After this configuration, we can access the contents export ed from the JS entry file of the application through window.vue:
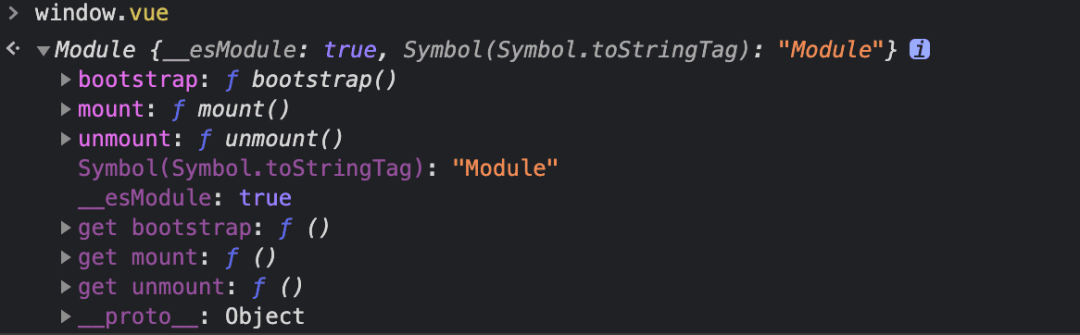
Screenshot: 11.23.26 am, September 5, 2021
You can see in the figure above that these exported functions are the life cycle of sub applications, and we need to call these functions.
Finally, we call runJS in loadHTML.
export const loadHTML = async (app: IInternalAppInfo) => { const { container, entry } = app const { template, getExternalScripts, getExternalStyleSheets } = await importEntry(entry) const dom = document.querySelector(container) if (!dom) { throw new Error('Container does not exist ') } dom.innerHTML = template await getExternalStyleSheets() const jsCode = await getExternalScripts() jsCode.forEach((script) => { const lifeCycle = runJS(script, app) if (lifeCycle) { app.bootstrap = lifeCycle.bootstrap app.mount = lifeCycle.mount app.unmount = lifeCycle.unmount } }) return app}After completing the above steps, we can see that the sub application is rendered normally!

Screenshot: 12.30.51 PM, September 5, 2021
But this step is not over yet. Let's consider this question: what if the sub application changes the global variable? At present, all of our applications can access and change the content on the window. If there is a global variable conflict between applications, it will cause problems. Therefore, we need to solve this problem next.
JS sandbox
If we want to prevent the sub application from directly modifying the properties on the window and access the contents on the window, we can only make a fake window for the sub application, that is, implement a JS sandbox.
There are many schemes to implement sandbox, such as:
1. Snapshot 2.Proxy
Let's talk about the snapshot scheme first. In fact, this scheme is very simple to implement. To put it bluntly, it is to record all the contents of the current window before mounting the sub application, and then let the sub application play at will until the window before mounting is restored when uninstalling the sub application. This scheme is easy to implement. The only disadvantage is that the performance is slow. Interested readers can directly look at qiankun's implementation [13], and there is no code posted here.
Let's talk about Proxy, which is also the scheme we choose. Many readers should have known how to use it. After all, Vue3's responsive principle is rotten. If you don't understand it, you can read the MDN document by yourself [14].
export class ProxySandbox { proxy: any running = false constructor() { // Create a fake window const fakeWindow = object. Create (null) const proxy = new proxy (fakeWindow, {set: (target: any, P: string, value: any) = > {/ / if the current sandbox is running, set the value directly to fakeWindow. If (this. Running) {target [P] = value} return true}, get (target: any, P: String): any {/ / prevent users from skipping classes switch (P) {case 'window': case 'self': case 'globalthis': return proxy} / / if the property does not exist on fakeWindow, but exists on window / / take if (! Window. Hasownproperty. Call) from window (target, P) & & window.hasownproperty (P)) {/ / @ TS ignore const value = window [P] if (typeof value = = = 'function') return value. Bind (window) return value} return target [P]}, has() {return true},}) this.proxy = proxy} / / activate sandbox active() {this. Running = true} / / deactivate sandbox inactive() {this. Running = false}}The above code is just a sandbox of the first version. The core idea is to create a fake window. If the user sets the value, it will be set on fakeWindow, so that the global variable will not be affected. If the user takes the value, it will judge whether the attribute exists on fakeWindow or window.
Of course, in actual use, we still need to improve this sandbox and deal with some details. It is recommended that you directly read qiankun's source code [15]. The amount of code is small, which is nothing more than dealing with a lot of boundary conditions.
In addition, it should be noted that both snapshot and Proxy sandbox are required. The former is the degradation scheme of the latter. After all, not all browsers support Proxy.
Finally, we need to modify the code in runJS to use the sandbox:
const runJS = (value: string, app: IInternalAppInfo) => { if (!app.proxy) { app.proxy = new ProxySandbox() // Hang the sandbox on the global attribute / / @ TS ignore window. _current_proxy_ = app. Proxy. Proxy} / / activate sandbox app.proxy.active() / / replace the global environment with sandbox and call JS const code = ` return (window = > {${value} return window ['${app. Name}']} (window. _current_proxy_) ` return new function (code)}So far, we have actually completed the core functions of the whole micro front end. Because the text expression is difficult to connect all the function improvement steps of the context, if you have something wrong when reading the article, it is recommended to look at the source code of the writer's warehouse [16].
Next, we will do some improved functions.
Improved function
prefetch
Our current approach is to load sub applications after matching a sub application successfully, which is not efficient enough. We prefer that users can load other sub application resources when browsing the current sub application, so that users don't have to wait when switching applications.
There is not much code to implement. We can finish it immediately by using our previous import HTML entry:
// Src / start.tsexport const start = () = > {const list = getapplist() if (! List. Length) {throw new error ('Please register the app first ')} hijackroute() reroute (window. Location. Href) / / judge that the child app in NOT_LOADED status only needs prefetch list. Foreach ((APP) = > {if ((app as iiinternalappinfo). Status = = = appstatus. NOT_LOADED) {prefetch (app as IInternalAppInfo) } })}// src/utils.tsexport const prefetch = async (app: IInternalAppInfo) => { requestIdleCallback(async () => { const { getExternalScripts, getExternalStyleSheets } = await importEntry( app.entry ) requestIdleCallback(getExternalStyleSheets) requestIdleCallback(getExternalScripts) })}There is nothing else to say about the above code. Let's mainly talk about the function requestIdleCallback.
The window.requestIdleCallback() method queues functions called during the browser's idle time. This enables developers to perform background and low priority work on the main event loop without delaying key events, such as animation and input response.
We use this function to prefetch when the browser is idle. In fact, this function is also useful in React, but we have implemented a polyfill version internally. Because some problems of this API (respond once in 50ms at the fastest) have not been solved, but there will be no problems in our scenario, so we can use it directly.
Resource caching mechanism
After we load the resources once, the user certainly does not want to load the resources again when entering the application next time. Therefore, we need to implement the resource caching mechanism.
In the previous section, we used import HTML entry and built-in caching mechanism. If you want to implement it yourself, you can refer to the internal implementation method [17].
In short, it is to cache the file content of each request under an object. When making the next request, first judge whether the value stored in the object exists. If it exists, just take it out and use it directly.
Global communication and status
This part is not implemented in the author's code. If you are interested in doing it yourself, the author can provide some ideas.
In fact, global communication and status can be regarded as an implementation of publish subscribe mode. As long as you have handwritten events, it should not be a difficult problem to implement this.
In addition, you can also read qiankun's global state implementation [18], a total of 100 lines of code.
Reference link
[1] toy-micro: https://github.com/KieSun/toy-micro [2] qiankun: https://github.com/umijs/qiankun [3] icestark: https://github.com/ice-lab/icestark [4] emp: https://github.com/efoxTeam/emp [5] Why Not Iframe: https://www.yuque.com/kuitos/gky7yw/gesexv [6] Warehouse: https://github.com/KieSun/toy-micro [7] Article: https://github.com/KieSun/awesome-frontend-source-interpretation/blob/master/article/vue/VueRouter%20%E6%BA%90%E7%A0%81%E6%B7%B1%E5%BA%A6%E8%A7%A3%E6%9E%90.md [8] path-to-regexp: https://github.com/pillarjs/path-to-regexp [9] Here: https://github.com/KieSun/toy-micro/blob/main/src/route/index.ts [10] single-spa: https://github.com/single-spa/single-spa [11] Warehouse: https://github.com/KieSun/toy-micro [12] import-html-entry: https://github.com/kuitos/import-html-entry [13] Implementation of Qiankun: https://github.com/umijs/qiankun/blob/master/src/sandbox/snapshotSandbox.ts [14] MDN document: https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/Proxy [15] Source code of Qiankun: https://github.com/umijs/qiankun/blob/master/src/sandbox/proxySandbox.ts#L177 [16] Source code of warehouse: https://github.com/KieSun/toy-micro [17] Internal implementation method: https://github.com/kuitos/import-html-entry/blob/master/src/index.js#L85 [18] qiankun's global state implementation: https://github.com/umijs/qiankun/blob/master/src/globalState.ts [19] Source code: https://github.com/KieSun/toy-micro