catalogue
preface
Recently, I was on a business trip and found that there was Xiaoqiang in my hotel. So when I was bored on a business trip, I wrote some crawler code to play. Asking is the occasion. This article mainly crawls the 100 titles of CSDN's comprehensive hot list, then extracts keywords by word segmentation and counts the word frequency.
I think it's still useful for other bloggers. You can see what titles can be on the hot list and share it. By the way, tell me about my methods to solve various problems.
environment
The IDE used is spyder (some are not used to looking at the interface, bear with it, it's not critical)
Chrome river is used for page crawling. As for the reason, I will say later.
Word splitter: jieba
Crawl page address: https://blog.csdn.net/rank/list
Crawler code
Here's why we don't use requests to directly obtain the page source code, mainly because the page can't directly request the source code. Instead, scroll to the bottom of the page to display all 100 ranked articles.
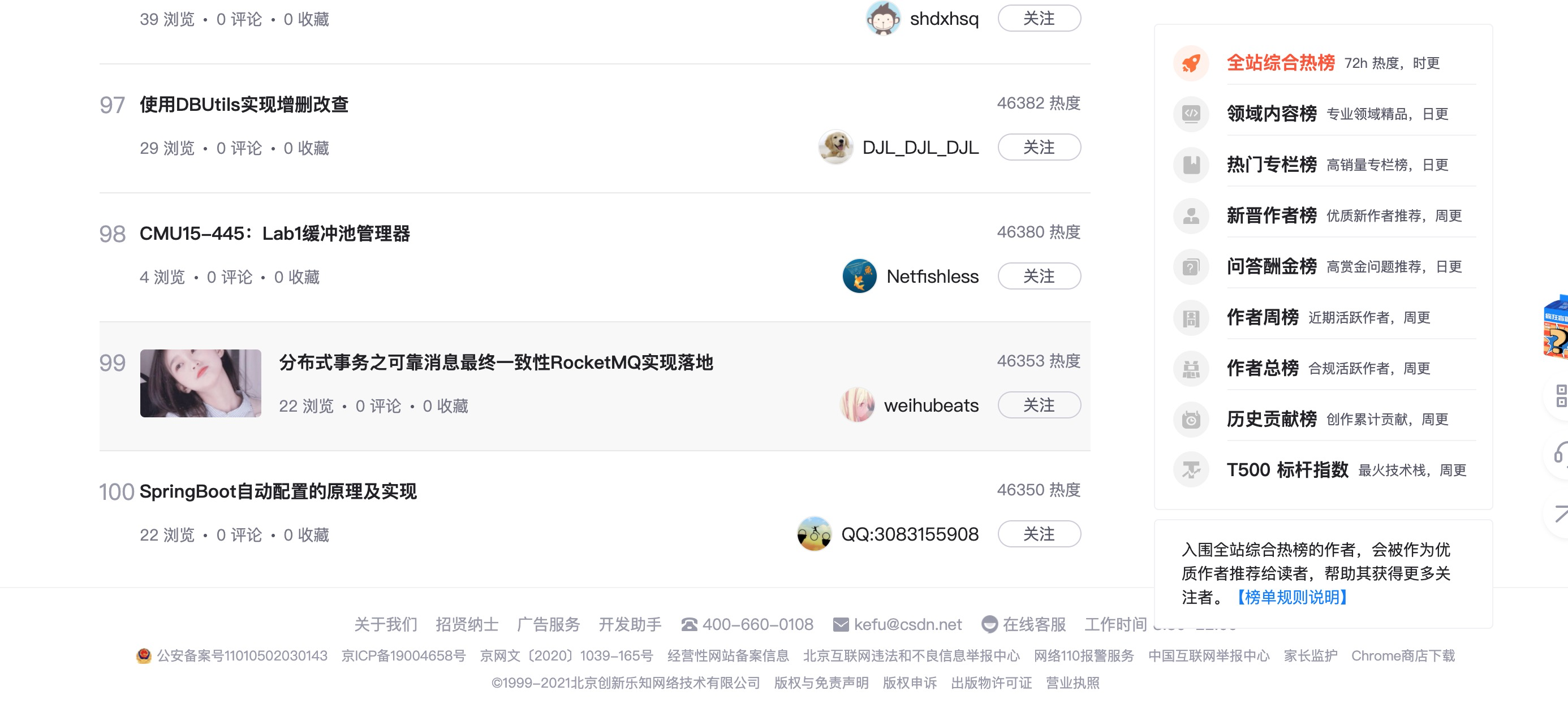
So my idea is to use chrome driver and execute js to scroll the page to the bottom.
Here we need to explain that the download of chrome River depends on the version of your google browser. My notebook is mac. You can click chrome in the upper left corner, and then click About Google Chrome to see your browser version.
Share the download address of chromedriver: google chrome driver download address
Briefly explain the principle of driver, which is to simulate the operation of the browser to open the url, just as we click by hand. We can talk about the specific principle another day.
No more nonsense, on the crawler tool code
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Thu Nov 4 17:15:06 2021
@author: huyi
"""
from selenium import webdriver
import time
# =============================================================================
# Crawling dynamic sliding loading web page
# =============================================================================
def pa(url):
driver = webdriver.Chrome('/usr/local/bin/chromedriver')
driver.get(url)
js = '''
let height = 0
let interval = setInterval(() => {
window.scrollTo({
top: height,
behavior: "smooth"
});
height += 500
}, 500);
setTimeout(() => {
clearInterval(interval)
}, 20000);
'''
driver.execute_script(js)
time.sleep(20)
source = driver.page_source
driver.close()
return source
Code description
1. The code is mainly a tool method, which uses diver to open the browser. Then simulate the scroll down operation through js code.
2. You can adjust the timeout according to your network conditions. Avoid ending before scrolling to the bottom, because the network card of my hotel is relatively large.
3. Return to the page source code for subsequent xpath parsing.
Verify it
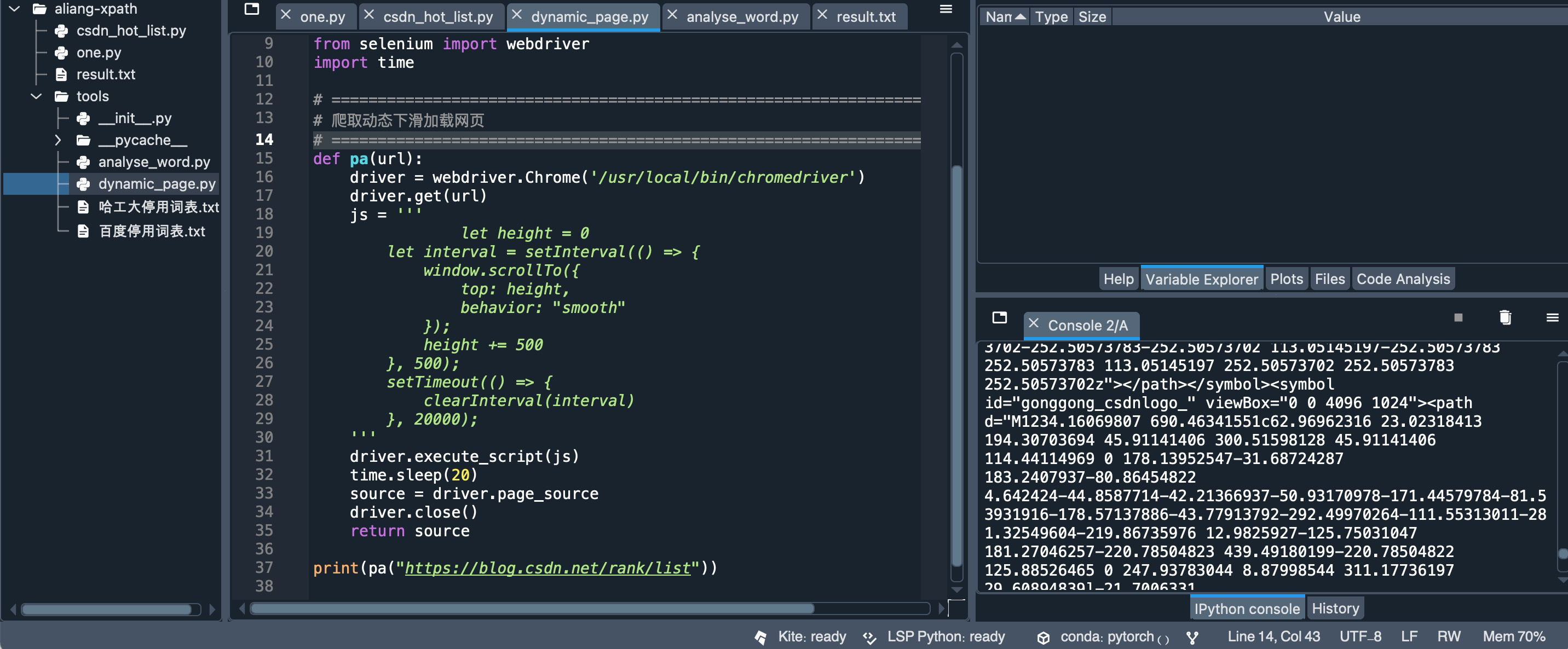
OK, I have got the page source code.
Keyword extraction code
We also prepare the keyword extraction method. No nonsense, code.
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Thu Nov 4 21:53:22 2021
@author: huyi
"""
import jieba.analyse
def get_key_word(sentence):
result_dic = {}
words_lis = jieba.analyse.extract_tags(
sentence, topK=3, withWeight=True, allowPOS=())
for word, flag in words_lis:
if word in result_dic:
result_dic[word] += 1
else:
result_dic[word] = 1
return result_dic
Code description
1. Briefly, the method takes the three words with the highest weight, which can be adjusted according to your preference.
2. Make a count of the same words to facilitate the word frequency statistics of 100 title keywords.
Main program code
The main program is to extract the title in the source code and use lxml to obtain the title. Then output the result text after word frequency statistics.
No nonsense, code.
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Thu Nov 4 14:01:38 2021
@author: huyi
"""
from lxml import etree
from tools.dynamic_page import pa
from tools.analyse_word import get_key_word
csdn_url = 'https://blog.csdn.net/rank/list'
source = etree.HTML(pa(csdn_url))
titles = source.xpath("//div[@class='hosetitem-title']/a/text()")
key_word_dic = {}
for x in titles:
if x:
for k, v in get_key_word(x).items():
if k.lower() in key_word_dic:
key_word_dic[k.lower()] += v
else:
key_word_dic[k.lower()] = v
word_count_sort = sorted(key_word_dic.items(),
key=lambda x: x[1], reverse=True)
with open('result.txt', mode='w', encoding='utf-8') as f:
for y in word_count_sort:
f.write('{},{}\n'.format(y[0], y[1]))
Code description
1. How to get xpath? google browser supports right-click direct copy, but it is recommended to learn about xpath related syntax.
2. Unify English words in lowercase to avoid repetition.
3. The output is arranged in reverse order of word frequency, and the one with the most times is in the front.
Verification results
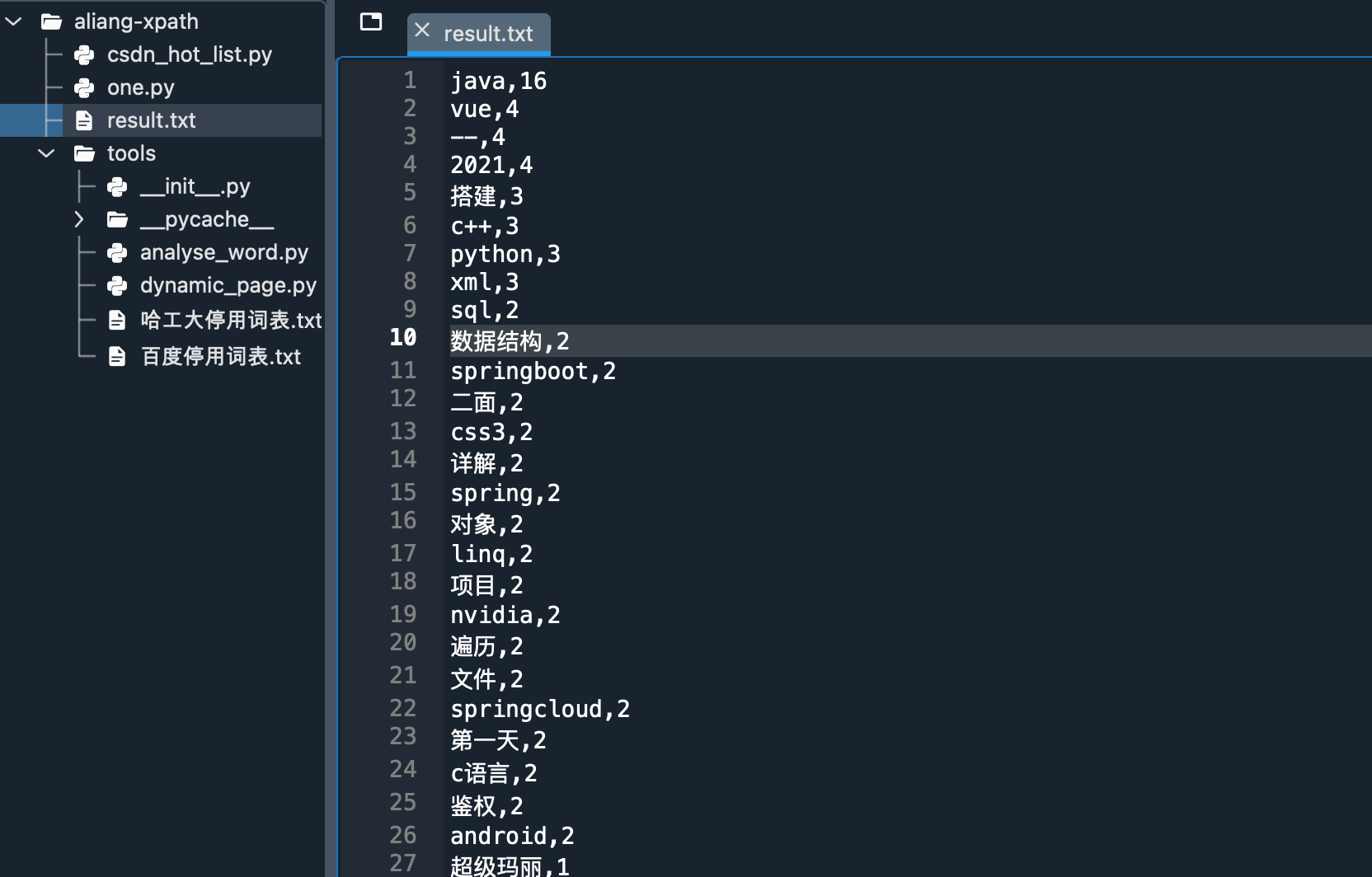
OK, not surprisingly, java is yyds.
summary
You can see that there are some symbols in the final statistics. What do you say? You can get rid of jieba stop words and see how you filter them.
To be clear, this case study is only for exploration and use, not for malicious attacks.
If this article works for you, please don't save your praise, thank you.
