Data persistence
That is, save the data to a permanent storage device (such as disk).
1. redis persistence – two methods
I redis Two persistence methods are provided: RDB(Redis DataBase)and AOF(Append Only File).
RDB (Redis DataBase): generate snapshots of redis stored data at different time points and store them on disks and other media;
characteristic: 1.Periodicity 2.Does not affect data writing #RDB starts the child process and backs up all data. The current process continues to provide data reading and writing. When the backup is complete, replace the old backup file. 3.Efficient #Restore all data at once 4.Poor integrity #The data between the point of failure and the last backup cannot be recovered.
AOF (Append Only File) implements persistence from another perspective, that is, record all write instructions executed by redis. When redis restarts next time, you can realize data recovery by repeating these write instructions from front to back.
characteristic: 1.Real time 2.Good integrity 3.Large volume #Instructions to record data and instructions to delete data will be recorded.
II RDB and AOF Both methods can also be used at the same time. In this case, if redis If it is restarted, it will be used preferentially AOF This is because AOF The data recovery integrity of this method is higher. 3, How to select the mode? Cache: do not turn on any persistence mode stripped of Party membership and expelled from public office:because RDB The data is not real-time, but when using both, the server will only find AOF file,therefore RDB Save it as a precaution. The official recommendation is to use both at the same time. This can provide a more reliable persistence scheme. Fast write speed ------------AOF Slow write speed ------------RDB
Persistent configuration
RDB is on by default:
[root@redis-master src]# cd .. [root@redis-master redis]# vim redis.conf #dbfilename: the file where persistent data is stored locally dbfilename dump.rdb

#dir: path where persistent data is stored locally dir /data/application/redis/data

##When the snapshot is triggered, save
##The following is a snapshot only after at least one change operation after 900 seconds
##For the setting of this value, you need to be careful to evaluate the change operation intensity of the system
##You can turn off the snapshot function by saving ''
#save time. The following indicates that one key has been changed. Persistent storage is performed every 900s; 10 keys 300s are changed for storage; Change 10000 keys 60s for storage.
save 900 1 save 300 10 save 60 10000

yes means to stop writing the RDB snapshot file when there is an error in persistence using the bgsave command. no means to ignore the error and continue writing the file. The "error" may be due to disk full / disk failure / OS level exception, etc
stop-writes-on-bgsave-error yes
##Whether to enable rdb file compression is "yes" by default. Compression often means "additional cpu consumption" and short network transmission time
rdbcompression yes
Note: each snapshot persistence is to write the memory data to the disk completely. If the amount of data is large and there are many write operations, it will inevitably cause a large number of disk io operations, which may seriously affect the performance.
Generally, the above is used. You can choose one from the other according to your own situation
AOF off by default – on
[root@redis-master src]# cd .. [root@redis-master redis]# vim redis.conf Amend as follows:
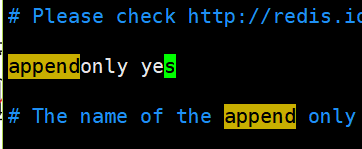
1,This option is aof Function switch, default to“ no",Can pass“ yes"To open aof function,Only in“ yes"Next, aof rewrite/Features such as file synchronization take effect ==================================== 2,appoint aof File name appendfilename appendonly.aof ==================================== 3,appoint aof The file synchronization policy in operation has three legal values: always everysec no,Default to everysec appendfsync everysec always #The AOF file is written every time data modification occurs everysec #Synchronize every second. This policy is the default policy / default policy of AOF no #Never synchronized. Efficient, but data is not persisted
After the persistence function is enabled, the data will be automatically recovered through the persistent file after redis is restarted
RDB snapshot backup recovery
redis database backup and recovery (dump.rdb snapshot), two machines
Same configuration as redis
Backup machine redis.conf Profile content: bind 0.0.0.0 dbfilename dump.rdb dir /data/application/redis/data save 900 1 save 300 10 save 60 10000 stop-writes-on-bgsave-error yes rdbcompression yes
Back up the data and write something on the main redis
Backup data: [root@redis-slave-1 redis]# src/redis-cli 127.0.0.1:6379> set name3 qianfeng OK 127.0.0.1:6379> set name4 tianyun OK
Execute backup command
127.0.0.1:6379> BGSAVE Perform a backup, or SAVE
Check whether the data appears
[root@redis-slave-1 redis]# ls data/ dump.rdb

Copy to the backup directory of the second Redis
[root@redis-slave-1 redis]# scp data/dump.rdb 192.168.62.135:/data/application/redis/data
Machine to recover data:
Modify redis.conf configuration file

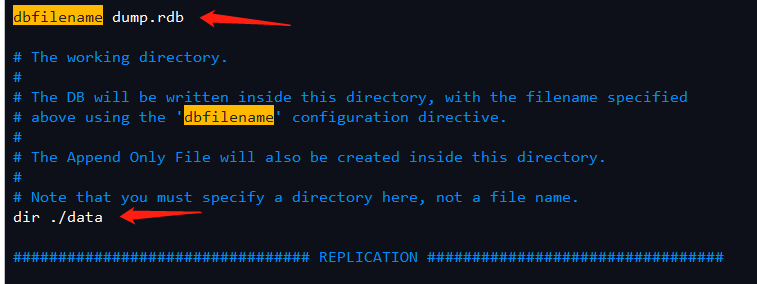
Store the dump.rdb data file in the directory specified by the configuration file and start it directly
Key point: if pull has been started, you need to kill the Redis process and start it again
[root@redis-master redis]# src/redis-server redis.conf & [root@redis-master redis]# src/redis-cli [root@redis-master redis]# 127.0.0.1:6379> get name3 "qianfeng" 127.0.0.1:6379> get name4 "tianyun"