In this blog, let's talk about Downloader Middleware in graph, that is, Download middleware related knowledge.
Downloader Middlerware
First, let's take a look at the position of Middleware in the scene data stream. The black arrow in the figure below is to download middleware.
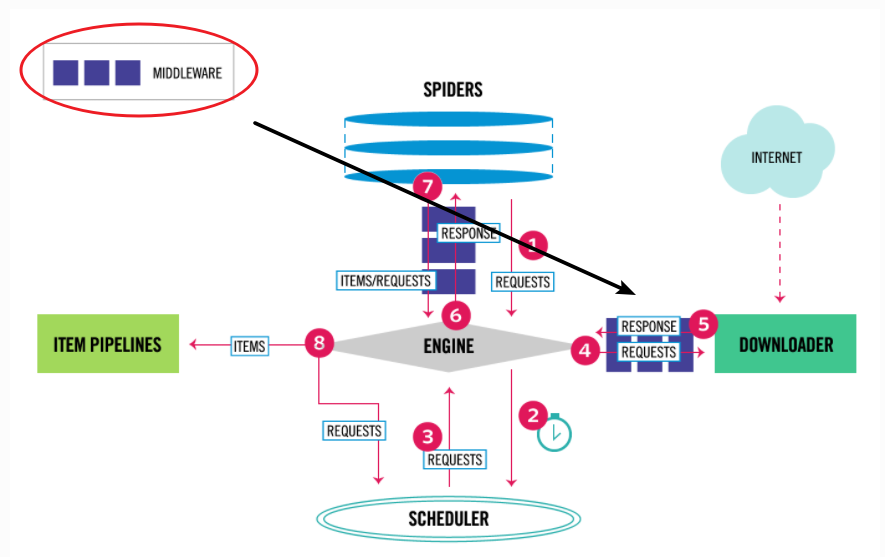
It can be seen from the above figure that both Requests and responses will pass through downloader middleware, so you need to pay attention to this point in subsequent code writing.
It is very easy to open the middleware. You only need to remove the comments of the following code in the settings.py file.
DOWNLOADER_MIDDLEWARES = {
'mid_test.middlewares.MidTestDownloaderMiddleware': 543,
}
In fact, the settings.py file is only the basic configuration of a scene project. In addition, there is a default in the scene framework_ Settings.py file, downloader inside_ MIDDLEWARES_ Base contains more download middleware, and they are loaded by default after the start of the sweep project, as shown in the following figure.
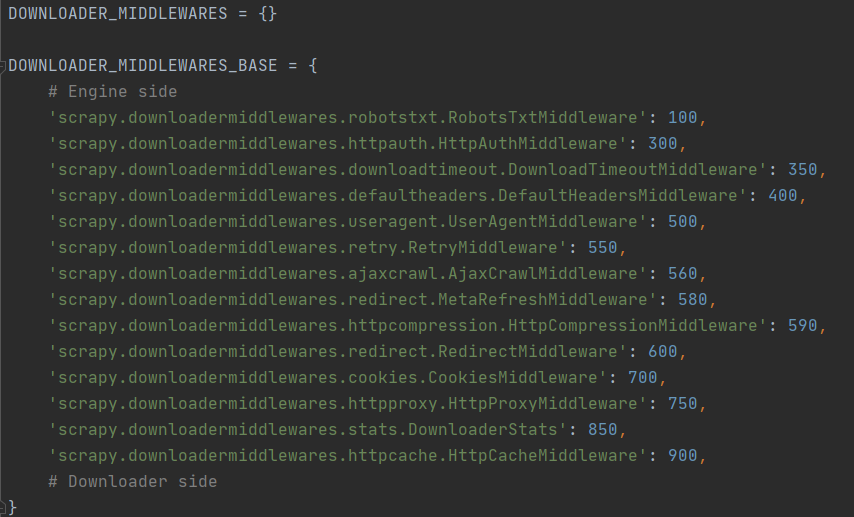 We are setting downloader_ When creating middlewares, you need to pay attention to the priority problem. The reason is that there is a process when writing custom download middleware later_ Request () method and 1 process_response() method, which will sort the middleware according to priority and make intermediate calls in order.
We are setting downloader_ When creating middlewares, you need to pay attention to the priority problem. The reason is that there is a process when writing custom download middleware later_ Request () method and 1 process_response() method, which will sort the middleware according to priority and make intermediate calls in order.
Another thing to note is that if you want to block DOWNLOADER_MIDDLEWARES_ The middleware set in base needs to be in downloader_ It can only be assigned a value of None in middlewares. For example, the following code will mask the robotxtmiddleware middleware.
DOWNLOADER_MIDDLEWARES = {
'myproject.middlewares.CustomDownloaderMiddleware': 543,
'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': None,
}
Knowledge of custom download Middleware
The website used in this case preparation is http://httpbin.org , the site can directly return the relevant parameters of the request header, which is very convenient for testing.
Before formally writing the code, add a new field in the settings.py file to facilitate the output of the print log (shielding the output of some debugging logs).
LOG_LEVEL = 'WARNING'
Write your own download Middleware
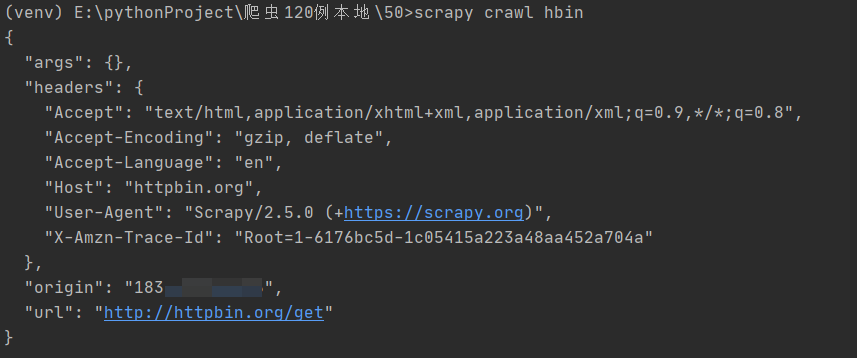
The default request code is shown below, and the returned data is below the code.
import scrapy
class HbinSpider(scrapy.Spider):
name = 'hbin'
allowed_domains = ['httpbin.org']
start_urls = ['http://httpbin.org/get']
def parse(self, response):
print(response.text)
After requesting the target site, the returned data is as follows:
Next, enable the middleware, and then modify the relevant parameters of the request. The main operation file is middlewares.py, and the process should be implemented_ request(),process_response(),process_exception(),spider_ The opened () method (which can be implemented only partially).
process_request(request, spider)
This method is called for each request by downloading the middleware.
The return value of this method must be None, Response object, Request object or IgnoreRequest error.
- Return to None: no impact. Other requests continue to be processed;
- Return Response: call process directly_ The Response () method;
- Return Request: add a new Request to the scheduling queue;
- Return IgnoreRequest: process_ The exception () method is executed.
Next, write a useragentmiddleware middleware to replace the default middleware and implement your own proxy settings.
Add the following code to the middlewares.py file
class UserAgentMiddleware(object):
def process_request(self, request, spider):
request.headers.setdefault('User-Agent',
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36')
return None
Add the following code to the settings.py file
DOWNLOADER_MIDDLEWARES = {
'mid_test.middlewares.UserAgentMiddleware': 543, # Configure your own middleware. You can modify the name to MyUserAgentMiddleware
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware':None # Overlay configuration
}
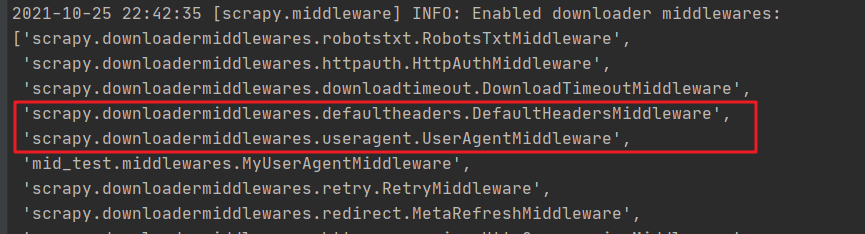
If the original configuration is not overwritten, we will find that the priority of the middleware we write is not as high as that of UserAgentMiddleware, that is, the loading sequence shown in the figure below.
process_response(request, response, spider)
This method can download the middleware to perform some data processing when returning the response data. By default, it returns either the response object or the request object, logic and process_ The request () method is basically the same.
class MyUserAgentMiddleware(object):
def process_request(self, request, spider):
request.headers.setdefault('User-Agent',
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36')
return None
def process_response(self, request, response, spider):
print(response) # Simply output the response
return response
process_exception(request, exception, spider)
It is used to handle exceptions. It returns None by default. It can also return Response object and Request object.
The general scenario is to return the Request object. When an exception occurs, you can re initiate the Request.
Built in download Middleware
All built-in middleware can be viewed from the scratch command line.
> scrapy settings --get DOWNLOADER_MIDDLEWARES_BASE
According to the priority, I will introduce it to you.
RobotsTxtMiddleware
Check the middleware source code and see that when the robotstxt in the settings.py file_ When obey is set to True, the robots.txt protocol is respected.
HttpAuthMiddleware
The core logic of HTTP authentication is as follows:
def spider_opened(self, spider):
usr = getattr(spider, 'http_user', '')
pwd = getattr(spider, 'http_pass', '')
if usr or pwd:
self.auth = basic_auth_header(usr, pwd)
def process_request(self, request, spider):
auth = getattr(self, 'auth', None)
if auth and b'Authorization' not in request.headers:
request.headers[b'Authorization'] = auth
DownloadTimeoutMiddleware
To set the timeout of the request, you need to configure download in the settings.py file_ The timeout value, and then manually download it to the meta_ Timeout parameter assignment.
def process_request(self, request, spider):
if self._timeout:
request.meta.setdefault('download_timeout', self._timeout)
DefaultHeadersMiddleware
Set default_ REQUEST_ The default request header specified by headers.
UserAgentMiddleware
Requested user agent settings.
RetryMiddleware
Number of retries requested.
MetaRefreshMiddleware and RedirectMiddleware
The above two middleware inherit from BaseRedirectMiddleware and are related to redirection.
HttpCompressionMiddleware
Support for gzip (deflate) data is provided.
CookiesMiddleware
Support for Cookie related capabilities.
HttpProxyMiddleware
Proxy related settings.
DownloaderStats
Download statistics of middleware.
HttpCacheMiddleware
Provides a low-level cache for all HTTP requests and responses.
The content of this blog is the foreshadowing of the knowledge of sketch, and some knowledge points will be repeatedly used in subsequent blogs. Please master it.
Write it at the back
Today is the 253rd / 365 day of continuous writing.
Look forward to attention, praise, comment and collection.
More wonderful
"100 crawlers, column sales, you can learn a series of columns after buying"
