1, Game problem analysis
2, Data reading
After downloading the data, anaconda and python 3.8 are recommended for data reading and model training
First install the required module package:
pip version:
Add domestic sources to pip to increase download speed_ 202xxx blog - CSDN blog
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
conda version:
Create a new conda virtual environment:
conda create --name py38 python=3.8 conda activate py38
conda add domestic source_ 202xxx blog - CSDN blog
conda install pandas
Read data with, train_dir is the storage path of the training set, and nrows is the number of rows of read data
import pandas as pd train_dir = '../data/train_set.csv' nrows=None train_df = pd.read_csv(train_dir, sep='\t', nrows=nrows)
View the first 5 news data
train_df.head()
| label | text | |
|---|---|---|
| 0 | 2 | 2967 6758 339 2021 1854 3731 4109 3792 4149 15... |
| 1 | 11 | 4464 486 6352 5619 2465 4802 1452 3137 5778 54... |
| 2 | 3 | 7346 4068 5074 3747 5681 6093 1777 2226 7354 6... |
| 3 | 2 | 7159 948 4866 2109 5520 2490 211 3956 5520 549... |
| 4 | 3 | 3646 3055 3055 2490 4659 6065 3370 5814 2465 5... |
3, Data analysis
Sentence length distribution
Count the length of each news (number of words)
import matplotlib.pyplot as plt
train_df['text_len'] = train_df['text'].apply(lambda x: len(x.split(' ')))
print(train_df['text_len'].describe())Use the describe() function to get the statistical characteristic value of the news length
count 200000.000000 mean 907.207110 std 996.029036 min 2.000000 25% 374.000000 50% 676.000000 75% 1131.000000 max 57921.000000 Name: text_len, dtype: float64
The total number of training data news is 200000, of which the shortest news word number is 2, the longest news word number is 57921, and the average purple potato is 907.2
Draw a histogram of sentence length:
_ = plt.hist(train_df['text_len'], bins=200)
plt.xlabel('Text char count')
plt.title("Histogram of char count") It can be seen that most sentences are less than 6000 in length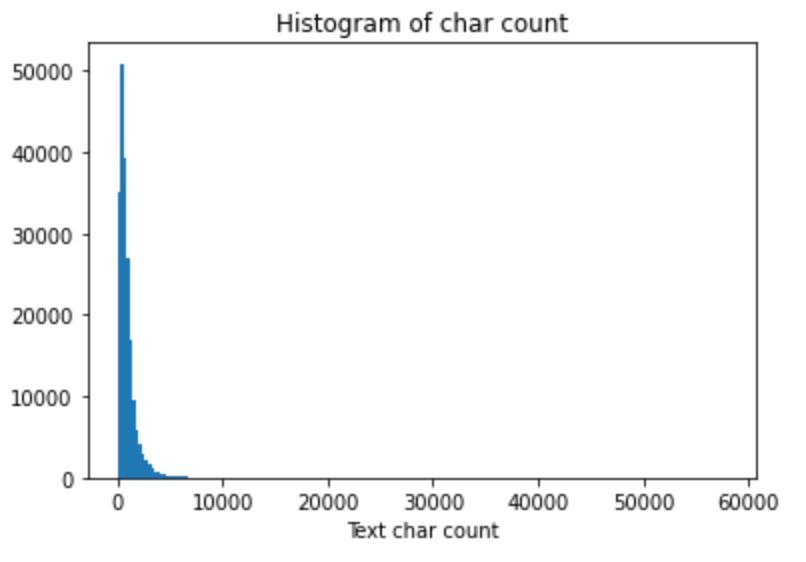
News category distribution
Draw the statistical histogram of news category labels
train_df['label'].value_counts().astype("object").plot(kind='bar')
plt.title('News class count')
plt.xlabel("category")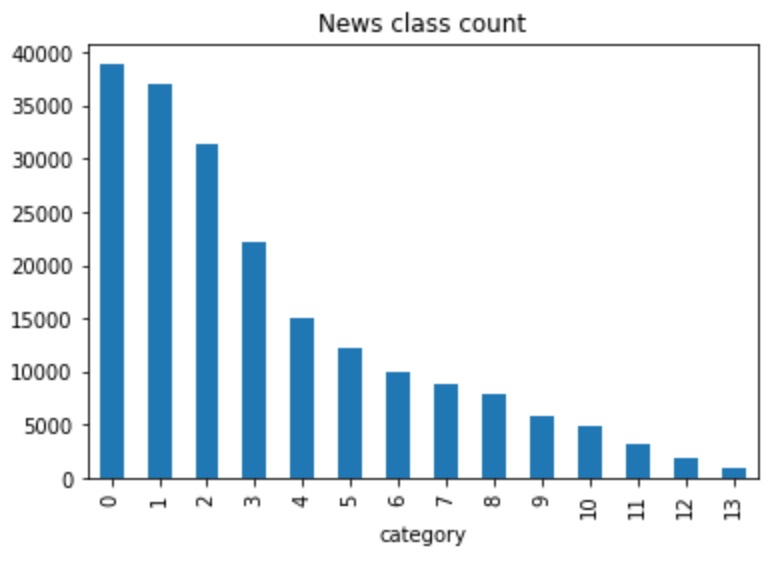
The corresponding relationships of labels in the dataset are as follows: {technology ': 0,' stock ': 1,' Sports': 2, 'entertainment': 3, 'current affairs': 4,' society ': 5,' education ': 6,' Finance ': 7,' home ': 8,' game ': 9,' real estate ': 10,' fashion ': 11,' lottery ': 12,' constellation ': 13}
It can be seen that the largest number of news is science and technology, and the least is constellation.
Character distribution statistics
Combine all characters of training data and count the frequency of each character
from collections import Counter
all_lines = ' '.join(list(train_df['text']))
word_count = Counter(all_lines.split(" "))
word_count = sorted(word_count.items(), key=lambda d:d[1], reverse = True)
print(len(word_count))
print(word_count[0])
print(word_count[-1])It can be seen that the number of characters used in the training data is 6869, of which the most used character number is "3750", which has been used 7.48 million times, and the least character number is "3133", which has been used twice:
6869
('3750', 7482224)
('3133', 1)Now the characters of each article are de duplicated and re counted
from collections import Counter
train_df['text_unique'] = train_df['text'].apply(lambda x: ' '.join(list(set(x.split(' ')))))
all_lines = ' '.join(list(train_df['text_unique']))
word_count = Counter(all_lines.split(" "))
word_count = sorted(word_count.items(), key=lambda d:int(d[1]), reverse = True)
print(word_count[0])
print(word_count[1])
print(word_count[2])You can get 197997 articles with the number "3750", and the total number of articles is 200000, so you can guess that it is punctuation.
('3750', 197997)
('900', 197653)
('648', 191975)4, Operation idea
1. Suppose character 3750, character 900 and character 648 are punctuation marks of sentences, please analyze the average number of sentences in each news story?
A: count the number of characters 3750, 900 and 648 in each news. The number of sentences in each news = the number of punctuation. Therefore, averaging can get the average number of sentences in each news. It is equivalent to knowing that the number of characters 3750 in 200000 news articles is 7482224 times, the number of characters 900 is 3262544, and the number of characters 648 is 4924890. The average number of sentences per news is 78
#Assignment 1
from collections import Counter
all_lines = ' '.join(list(train_df['text']))
word_count = Counter(all_lines.split(" "))
print(word_count["3750"])
print(word_count["900"])
print(word_count["648"])
print((word_count["3750"] + word_count["900"] + word_count["648"])/train_df.shape[0])2. Count the characters that appear most frequently in each type of news?
Answer: group and splice the text news in df according to the label, and calculate the maximum characters and number of news in each label
train_df_label = train_df[["label", "text"]].groupby("label").apply(lambda x:" ".join(x["text"])).reset_index()
train_df_label.columns = [["label", "text"]]
from collections import Counter
train_df_label['text_max'] = train_df_label["text"].apply(lambda x:sorted(Counter(x["text"].split(" ")).items(), key=lambda d:int(d[1]), reverse = True)[0], axis = 1)
train_df_label| label | text | text_max | |
|---|---|---|---|
| 0 | 0 | 3659 3659 1903 1866 4326 4744 7239 3479 4261 4... | (3750, 1267331) |
| 1 | 1 | 4412 5988 5036 4216 7539 5644 1906 2380 2252 6... | (3750, 1200686) |
| 2 | 2 | 2967 6758 339 2021 1854 3731 4109 3792 4149 15... | (3750, 1458331) |
| 3 | 3 | 7346 4068 5074 3747 5681 6093 1777 2226 7354 6... | (3750, 774668) |
| 4 | 4 | 3772 4269 3433 6122 2035 4531 465 6565 498 358... | (3750, 360839) |
| 5 | 5 | 2827 2444 7399 3528 2260 6127 1871 119 3615 57... | (3750, 715740) |
| 6 | 6 | 5284 1779 2109 6248 7039 5677 1816 5430 3154 1... | (3750, 469540) |
| 7 | 7 | 6469 1066 1623 1018 3694 4089 3809 4516 6656 3... | (3750, 428638) |
| 8 | 8 | 2087 730 5166 3300 7539 1722 5305 913 4326 669... | (3750, 242367) |
| 9 | 9 | 3819 4525 1129 6725 6485 2109 3800 5264 1006 4... | (3750, 178783) |
| 10 | 10 | 26 4270 1866 5977 3523 3764 4464 3659 4853 517... | (3750, 180259) |
| 11 | 11 | 4464 486 6352 5619 2465 4802 1452 3137 5778 54... | (3750, 83834) |
| 12 | 12 | 2708 2218 5915 4559 886 1241 4819 314 4261 166... | (3750, 87412) |
| 13 | 13 | 1903 2112 3019 3607 7539 3864 4939 4768 3420 2... | (3750, 33796) |
5, Summary
According to different dimensions, the characteristics of news are extracted respectively to prepare for model training.