What is out of order execution
Disordered execution [1] is simply the execution order of the code in the program, which may be adjusted by the compiler and CPU according to some strategy (commonly known as "disordered") - although from the perspective of single thread, disordered execution does not affect the execution result.
Why do we need to execute out of order
The main reason is that the pipeline technology is adopted inside the CPU [2]. Abstractly and simply, the execution process of a CPU instruction can be divided into four stages: fetch, decode, execute and write back.
These four stages are completed by four independent physical execution units. In this case, if there is no dependency between instructions, the latter instruction does not need to wait until the previous instruction is fully executed. However, after the previous instruction completes the fetch operation, the latter instruction can start to execute the fetch operation.
The ideal situation is shown in the figure below: there is no dependency between instructions, which can maximize the parallelism of the pipeline.
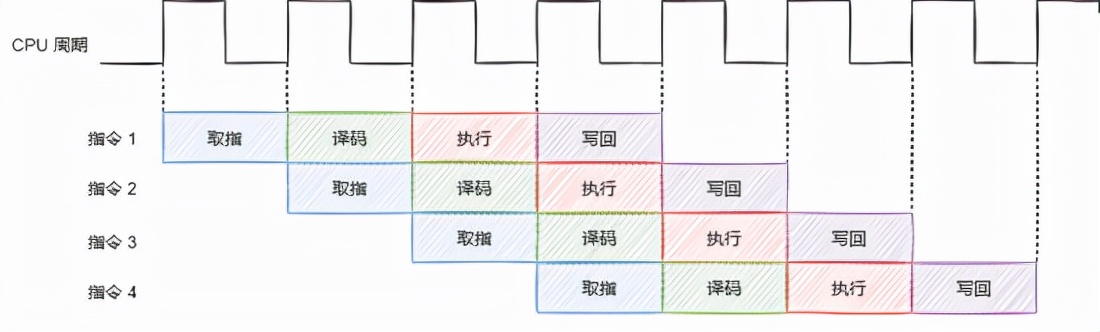
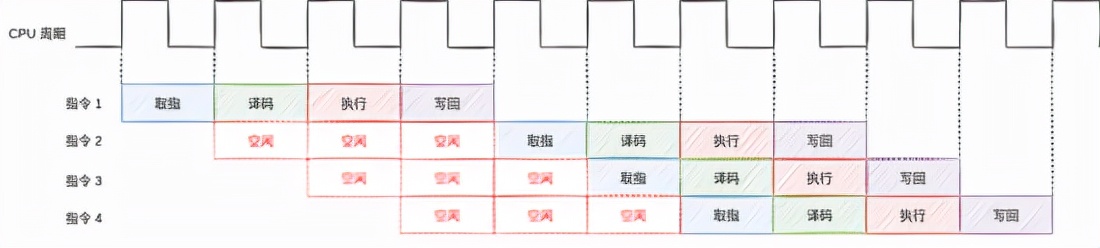
stay Execute in sequence In this case, once the instruction dependency is encountered, the pipeline will stop. For example:
Instruction 1: Load R3 <- R1(0) # Load data from memory into R3 register Instruction 2: Add R3 <- R3, R1 # Addition depends on the execution result of instruction 1 Instruction 3: Sub R1 <- R6, R7 # subtraction Instruction 4: Add R4 <- R6, R8 # addition
In the above pseudo code, instruction 2 depends on the execution result of instruction 1. Before the execution of instruction 1 is completed, instruction 2 cannot be executed, which will greatly reduce the execution efficiency of the pipeline.
It is observed that instruction 3 and instruction 4 do not depend on other instructions. It can be considered to "disorder" these two instructions before instruction 2.
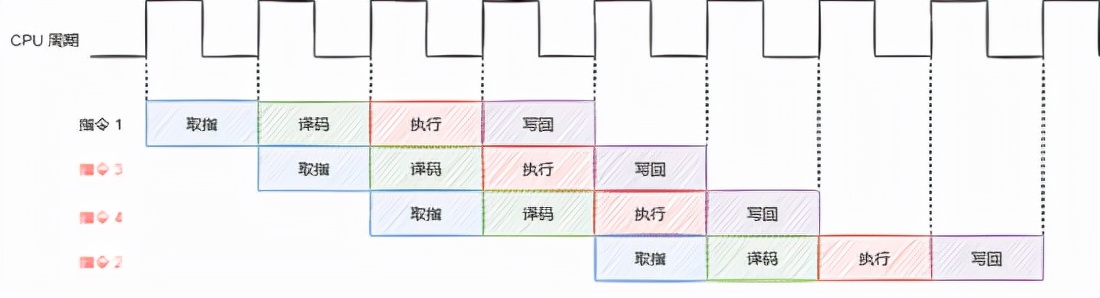
In this way, the pipeline execution unit can be in working state as much as possible.
In general, by disorderly execution and reasonably adjusting the execution order of instructions, the operation efficiency of the pipeline can be improved and the execution of instructions can be parallel as much as possible.
Compiler Fence
In the multithreaded environment, the existence of out of order execution is easy to break some expectations and cause some unexpected problems.
There are two cases of out of order execution:
- At compile time, the compiler rearranges instructions.
- During the running period, the CPU executes instructions out of order.
Let's take a look at an example of compiler instruction rearrangement:
#include <atomic>
// Sequential repeater
std::atomic<int> timestamp_oracle{0};
// Number currently processed
int now_serving_ts{0};
int shared_value;
int compute();
void memory_reorder() {
// Get a number atomically
int ts = timestamp_oracle.fetch_add(1);
// Lock: judge whether it is the current turn of this number, otherwise it will cycle, etc
while (now_serving_ts != ts);
// Critical area: start processing request
shared_value = compute();
// Compiler memory barrier
asm volatile("" : : : "memory");
// Unlock: next number to process
now_serving_ts = ts + 1;
}
Briefly explain this Code:
- This program processes the requests of each thread in order by maintaining a "signer timestamp_oracle".
- Each thread first takes a number from the "signer", and then constantly judges whether it is its turn to execute, similar to the logic of spin lock.
- After each thread is executed, switch the "number" to the next one.
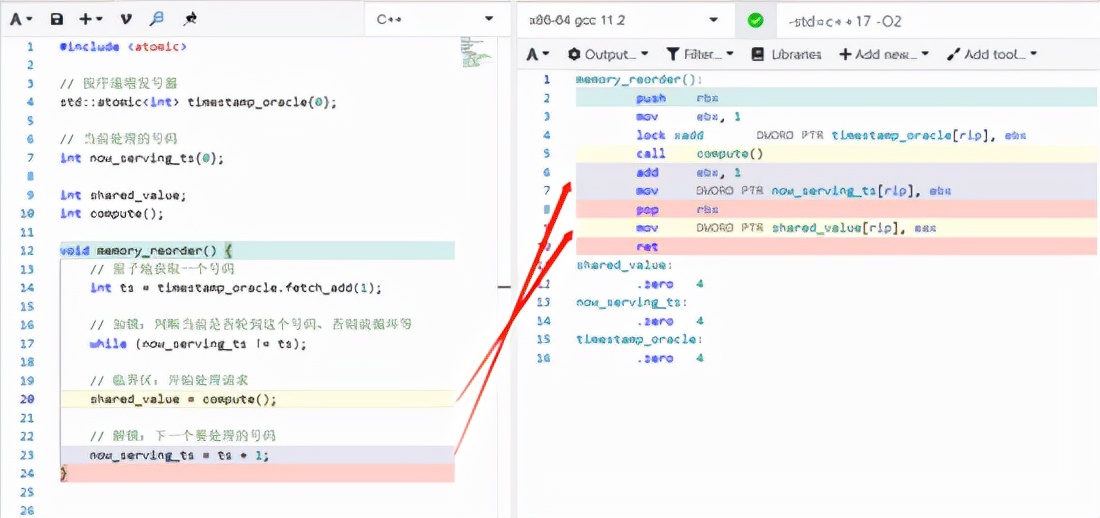
Under the compilation optimization option of O1, the compiled assembly instructions are not rearranged (it can be seen from the background color of the left and right code lines).
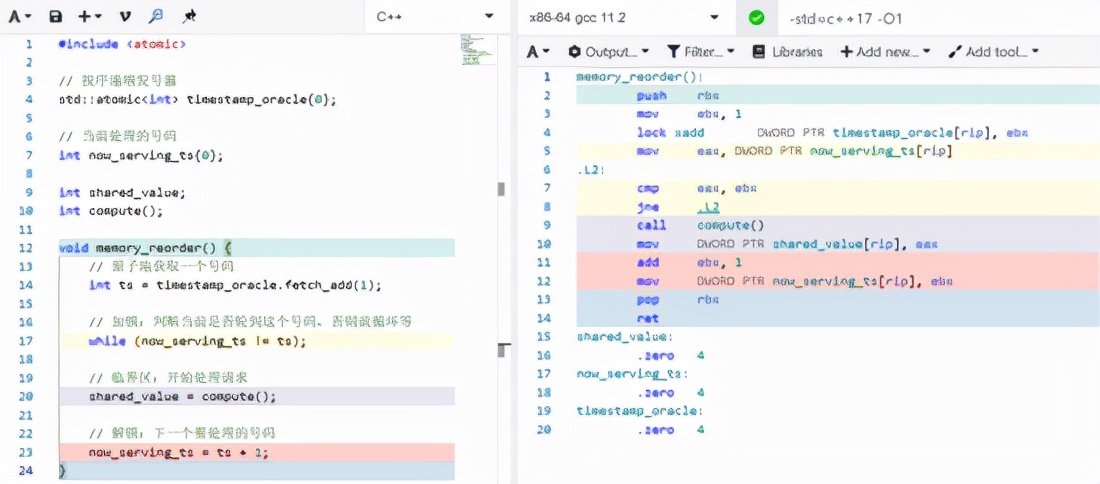
Under the compilation optimization option of O2, the instruction is rearranged, and the instruction rearrangement here breaks the expectation of the program. First switch the now_serving_ts, and then update the shared_value, resulting in the concurrent modification of the shared_value.
To prevent the compiler from rearranging the instructions of these two sentences, you need to insert a compiler fence between them.
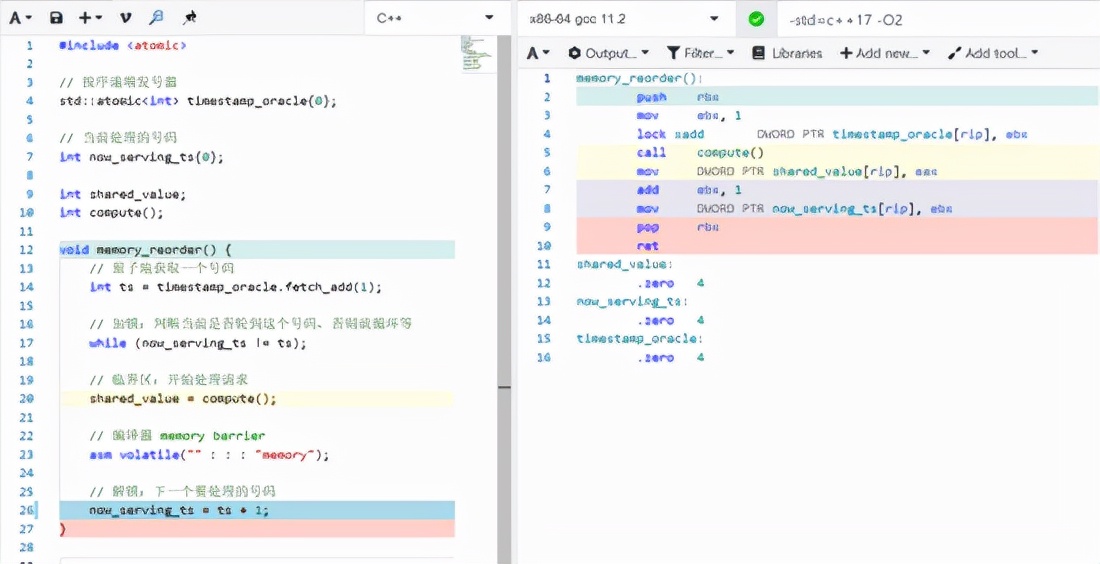
asm volatile("": : :"memory");
This is the way to write the compiler fence of GCC extension. This instruction tells the compiler (GCC official document [3]):
- Prevent the memory access operation above the fence instruction from being moved to the bottom, and prevent the memory access operation below from being moved to the top, that is, to prevent disorder.
- Let the compiler flush all memory variables cached in registers into memory, and then read these values from memory again.
For point 2, sometimes we only need to refresh some variables. Refreshing all registers does not necessarily meet our expectations, and it will introduce unnecessary overhead. GCC supports compiler fence for specified variables.
write(x)
asm volatile("": "=m"(y) : "m"(x):)
read(y)
The middle inline assembly instruction tells the compiler not to disorderly write(x) and read(y).
CPU Fence
Let's take an example:
int x = 0;
int y = 0;
int r0, r1;
// CPU1
void f1()
{
x = 1;
asm volatile("": : :"memory");
r0 = y;
}
// CPU2
void f2()
{
y = 1;
asm volatile("": : :"memory");
r1 = x;
}
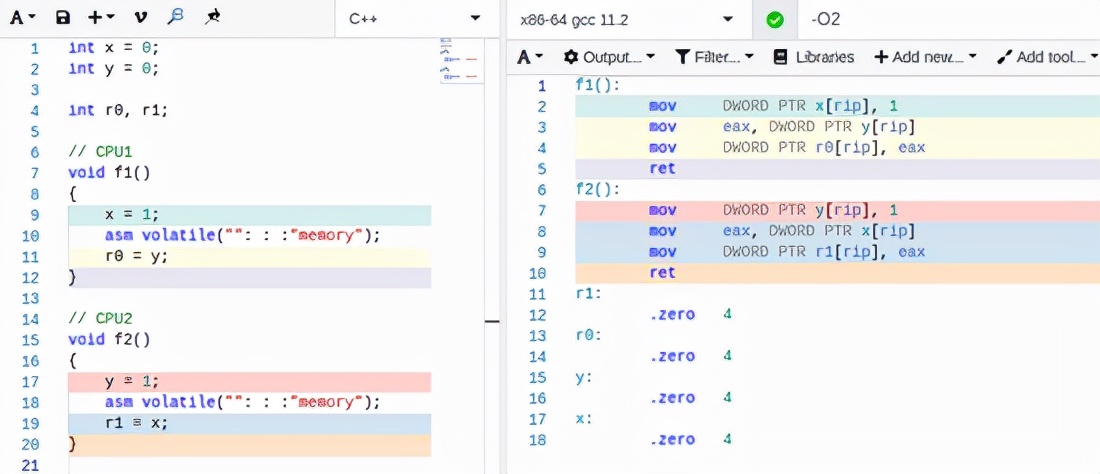
In the above example, due to the existence of compiler fence, the compiler will not rearrange the instructions inside function f1 and function f2.
At this time, if the CPU is not out of order during execution, it is impossible r0 == 0 && r1 == 0 Unfortunately, this can happen due to the out of order execution of the CPU. See the following example:
#include <iostream>
#include <thread>
int x = 0;
int y = 0;
int r0 = 100;
int r1 = 100;
void f1() {
x = 1;
asm volatile("": : :"memory");
r0 = y;
}
void f2() {
y = 1;
asm volatile("": : :"memory");
r1 = x;
}
void init() {
x = 0;
y = 0;
r0 = 100;
r1 = 100;
}
bool check() {
return r0 == 0 && r1 == 0;
}
std::atomic<bool> wait1{true};
std::atomic<bool> wait2{true};
std::atomic<bool> stop{false};
void loop1() {
while(!stop.load(std::memory_order_relaxed)) {
while (wait1.load(std::memory_order_relaxed));
asm volatile("" ::: "memory");
f1();
asm volatile("" ::: "memory");
wait1.store(true, std::memory_order_relaxed);
}
}
void loop2() {
while (!stop.load(std::memory_order_relaxed)) {
while (wait2.load(std::memory_order_relaxed));
asm volatile("" ::: "memory");
f2();
asm volatile("" ::: "memory");
wait2.store(true, std::memory_order_relaxed);
}
}
int main() {
std::thread thread1(loop1);
std::thread thread2(loop2);
long count = 0;
while(true) {
count++;
init();
asm volatile("" ::: "memory");
wait1.store(false, std::memory_order_relaxed);
wait2.store(false, std::memory_order_relaxed);
while (!wait1.load(std::memory_order_relaxed));
while (!wait2.load(std::memory_order_relaxed));
asm volatile("" ::: "memory");
if (check()) {
std::cout << "test count " << count << ": r0 == " << r0 << " && r1 == " << r1 << std::endl;
break;
} else {
if (count % 10000 == 0) {
std::cout << "test count " << count << ": OK" << std::endl;
}
}
}
stop.store(true);
wait1.store(false);
wait2.store(false);
thread1.join();
thread2.join();
return 0;
}
The above program can easily run the results of R0 = = 0 & & R1 = = 0, such as:
test count 56: r0 == 0 && r1 == 0
To prevent the CPU from executing out of order, we need to use CPU fence. We can modify the compiler fence in functions f1 and f2 to CPU fence:
void f1() {
x = 1;
asm volatile("mfence": : :"memory");
r0 = y;
}
void f2() {
y = 1;
asm volatile("mfence": : :"memory");
r1 = x;
}
In this way, it will not appear r0 == 0 && r1 == 0 The situation has changed.
summary
The disordered execution of instructions is mainly caused by two factors:
- Compile time instruction rearrangement.
- During the running period, the CPU executes out of order.
Whether the instruction rearrangement during compilation or the out of order execution of the CPU is mainly to make the instruction pipeline inside the CPU "full" and improve the parallelism of instruction execution.
The above examples of inserting fence use GCC extension syntax. In fact, the C + + standard library has provided similar encapsulation: std::atomic_thread_fence [4], which is cross platform and better readable.
In some scenarios of lock free programming and pursuing extreme performance, you may need to manually insert appropriate fences in appropriate places. There are too many details involved here, which is very error prone. Atomic variable operation will automatically insert appropriate fences according to different memory order s. It is recommended to give priority to using atomic variables.