introduction
Full backup is to back up all data contents. There are a lot of duplicate data in the backup data, and the time of full backup and recovery is very long. The solution to the problem of full backup is to use incremental backup. Incremental backup is to back up the files or contents added or changed since the last backup.
1, MySQL incremental backup
1. Features of incremental backup
-
The advantages of incremental backup are no duplicate data, small amount of backup and short time; The disadvantages are also obvious. All incremental backups can be restored only after the last full backup and full backup, and all incremental backups are reversely restored one by one, which is complicated
-
MySQL does not provide a direct incremental backup method, but it can indirectly realize incremental backup through MySQL binary logs
-
The meaning of binary log to backup is as follows:
① The binary log holds all operations that update or possibly update the database
② Binary logs are recorded after starting the MySQL server, and a new log file is re created after the file reaches the size set by max_binlog_size or after receiving the flush logs command
③ We only need to execute flushlogs method regularly to re create new logs, generate binary file sequence, and save these logs to a safe place in time to complete an incremental backup for a period of time
2. Examples
- ① Enable binary log function
[root@mysql ~]#vim /etc/my.cnf log-bin=mysql-bin #Open the binary log file named MySQL bin binlog_format = MIXED #Specifies that the binary log record format is MIXED [root@mysql ~]#systemctl restart mysqld.service #View binary log files [root@mysql /usr/local/mysql/data]#ls -l /usr/local/mysql/data/mysql-bin.* -rw-r----- 1 mysql mysql 154 10 June 26-14:53 /usr/local/mysql/data/mysql-bin.000001 -rw-r----- 1 mysql mysql 19 10 June 26-14:53 /usr/local/mysql/data/mysql-bin.index
There are three different recording formats for binary log: state (based on SQL STATEMENT), row (based on row) and mixed (mixed mode). The default format is state
(1) STATEMENT (based on SQL statement):
Every sql related to the modified sql will be recorded in binlog
Disadvantages: the amount of logs is too large, such as sleep() function, last_insert_id() >, user defined fuctions (udf), master-slave replication and other architectures. There will be problems when logging
Summary: adding, deleting, modifying and querying records through sql statements. If high concurrency is used, there may be errors, time differences or delays, which may not be the recovery we think about. You may delete or modify it first, which may be reversed. The accuracy is low
(2) Row (row based)
Only change records are recorded, not the sql context
Disadvantages: if update... set... where true is encountered, the amount of binlog data will become larger and larger
Summary: update and delete use multiple rows of data to record changes in rows, not the context of sql. For example, sql statements record one ROW, but ROW may record 10 rows, but the accuracy is high. When concurrency is high, due to the amount of operations and low performance, records are recorded
(3) MIXED recommends using general statements, using statements, and using ROW to store functions.
② Each week, select a time period with a lighter server load or a time period with less user access for backup
#Full backup of tables mysqldump -uroot -p123123 SCHOOL CLASS01 > /opt/SCHOOL_CLASS01_$(date +%F).sql #Perform a full backup of the library mysqldump -uroot -p123123 --all-databases SCHOOL > /opt/SCHOOL_$(date +%F).sql #Execute with planned tasks crontab -e 30 1 * * 3 mysqldump -uroot -p123123 SCHOOL CLASS01 > /opt/SCHOOL_CLASS01_$(date +%F).sql 30 1 * * 3 mysqldump -uroot -p123123 --all-databases SCHOOL > /opt/SCHOOL_$(date +%F).sql #The database and tables are fully backed up at 1:30 a.m. every Wednesday
③ Incremental backup can be performed every day to generate new binary log files
ls /usr/local/mysql/data mysqladmin -uroot -p123456 flush-logs
④ Insert new data to simulate the addition or change of data
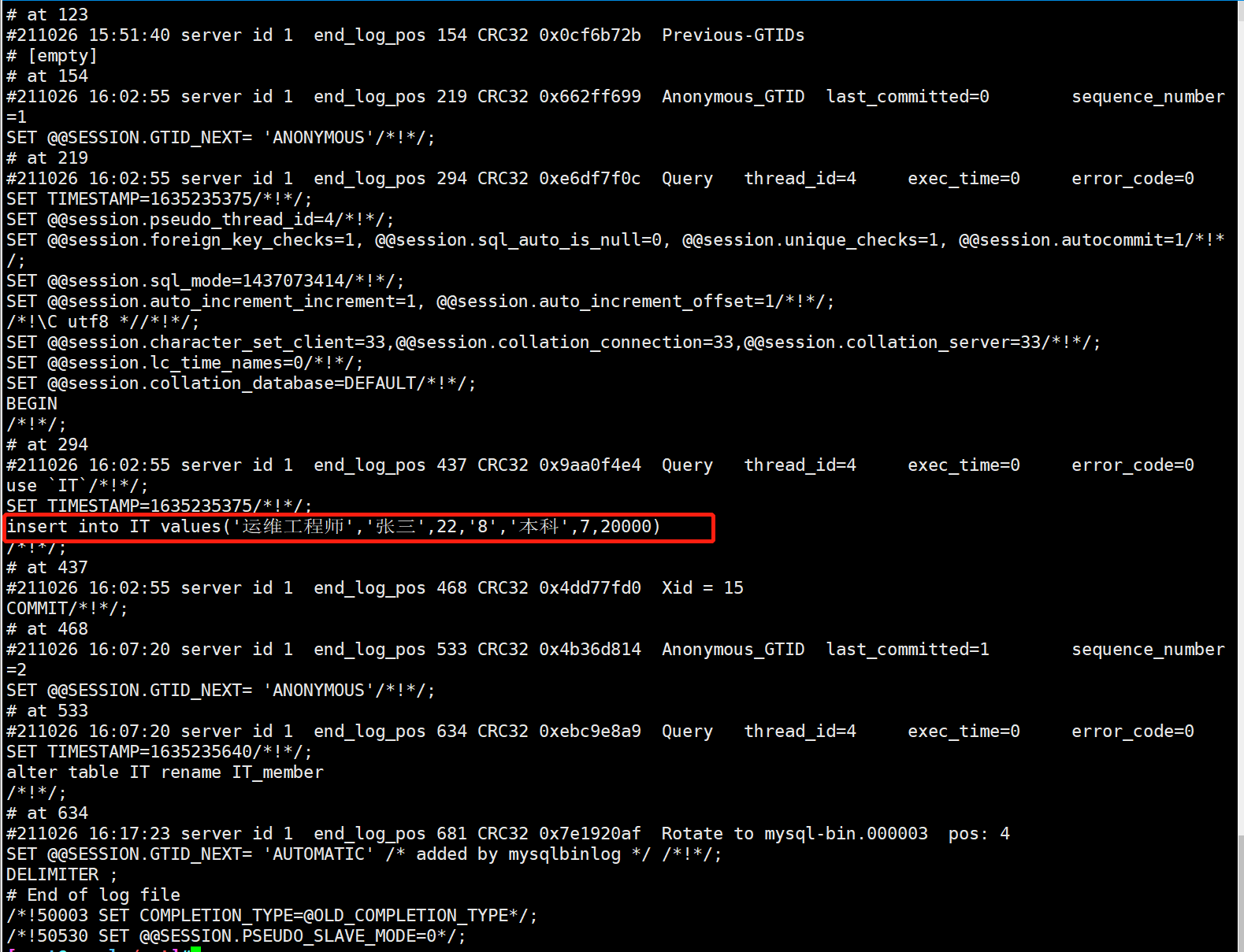
mysql> insert into IT_member values('Operation and maintenance engineer','Zhang San',22,'8','undergraduate',7,20000);
Query OK, 1 row affected (0.01 sec)
mysql> select * from IT_member;
+--------------------+-----------+--------+----------+--------+--------+----------+
| post | full name | Age | staff ID | education | Years | salary |
+--------------------+-----------+--------+----------+--------+--------+----------+
| Cloud computing Engineer | Gu Lei | 18 | 1 | undergraduate | 6 | 18888.00 |
| Cloud computing Engineer | Cui Peiwen | 19 | 2 | undergraduate | 7 | 19999.00 |
| Operation and maintenance engineer | Zhang San | 22 | 8 | undergraduate | 7 | 20000.00 |
+--------------------+-----------+--------+----------+--------+--------+----------+
3 rows in set (0.00 sec)
⑤ Generate a new binary and view its contents
cd /usr/local/mysql/data/ mysqladmin -uroot -p123456 flush-logs
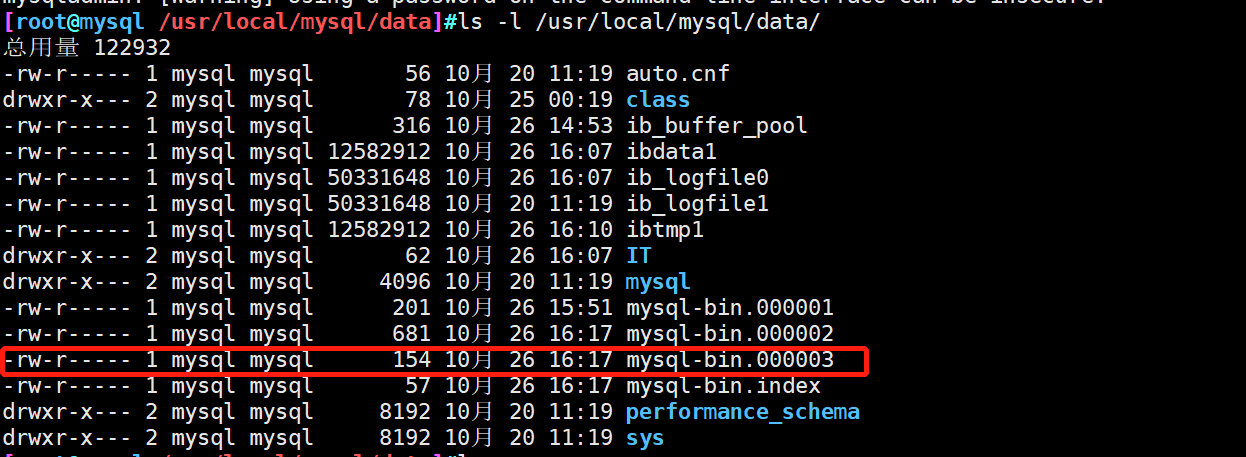
Note: the database operation in the previous step ④ will be saved in mysql-bin.00000 2 file, and then we test that the operation of deleting the database will be saved in mysql-bin.00000 3 file (so that the database will still be deleted when we recover based on the mysql-bin.00000 2 log)
#Copy the binary 02 recording changes to the / opt directory cp mysql-bin.000002 /opt/ cd /opt/ #The 64 bit encoding mechanism is used to decode and read the details by line mysqlbinlog --no-defaults --base64-output=decode-rows -v /opt/mysql-bin.000002
2, MySQL incremental recovery
1. Scenario of incremental recovery
When the data is sent incorrectly, you should choose whether to use full backup recovery or incremental backup recovery according to the actual situation
Scenario of incremental backup:
① Artificial SQL statements destroy the database
② Send system failure before the next full backup, resulting in database data loss
③ In the master-slave architecture, the master database failed to send data
According to the situation of data loss, it can be divided into two categories:
① Only data changed after a full backup is lost
② Lose all data after full backup
2. Recovery of changed data after loss of full backup
#Add table contents
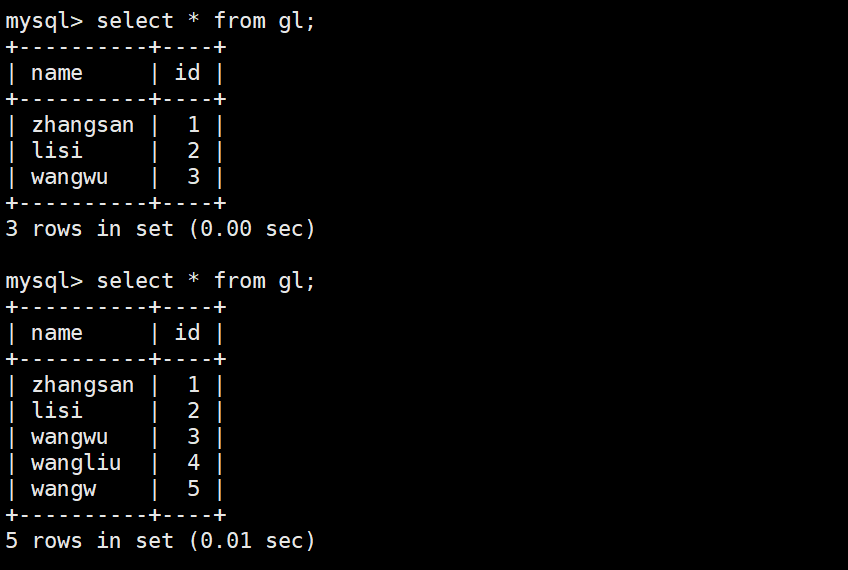
mysql> insert into gl values ('wangliu',4);
mysql> insert into gl values ('wangw',5);
#Intercepting log files
mysqladmin -u root -p123456 flush-logs
[root@mysql /usr/local/mysql/data]#ls #Generate 03 and save the operation of adding data in 02
mysql-bin.000001 mysql-bin.000002 mysql-bin.000003 ......
#Delete the two inserted data to simulate the failure of data loss after full backup
mysql> delete from gl where id=4;
mysql> delete from gl where id=5;
#Restore using binary files
mysqlbinlog --no-defaults mysql-bin.000002 | mysql -uroot -p
3. Lose all data after full backup
#Create new databases and data tables
mysql> create database class;
mysql> use class;
mysql> create table gl(name char(8),ID int not null,primary key (ID));
mysql> insert into gl values('zhangsan','1');
......
mysql> insert into gl values('laal','6');
mysql> select * from gl where id;
+----------+----+
| name | ID |
+----------+----+
| zhangsan | 1 |
| wangwu | 2 |
| wangliu | 3 |
| lisi | 4 |
| wb | 5 |
| laal | 6 |
+----------+----+
#Full backup
mysqldump -uroot -p123456 class gl > /opt/class_gl_$(date +%F).sql
#Refresh log
mysqladmin -u root -p flush-logs
#Continue adding information to the database table
insert into gl values('ssa',7);
insert into gl values('sa',8);
mysql> select * from gl;
+----------+----+
| name | ID |
+----------+----+
| zhangsan | 1 |
| wangwu | 2 |
| wangliu | 3 |
| lisi | 4 |
| wb | 5 |
| laal | 6 |
| ssa | 7 |
| sa | 8 |
+----------+----+
#Delete library class to simulate fault
mysql> drop database class;
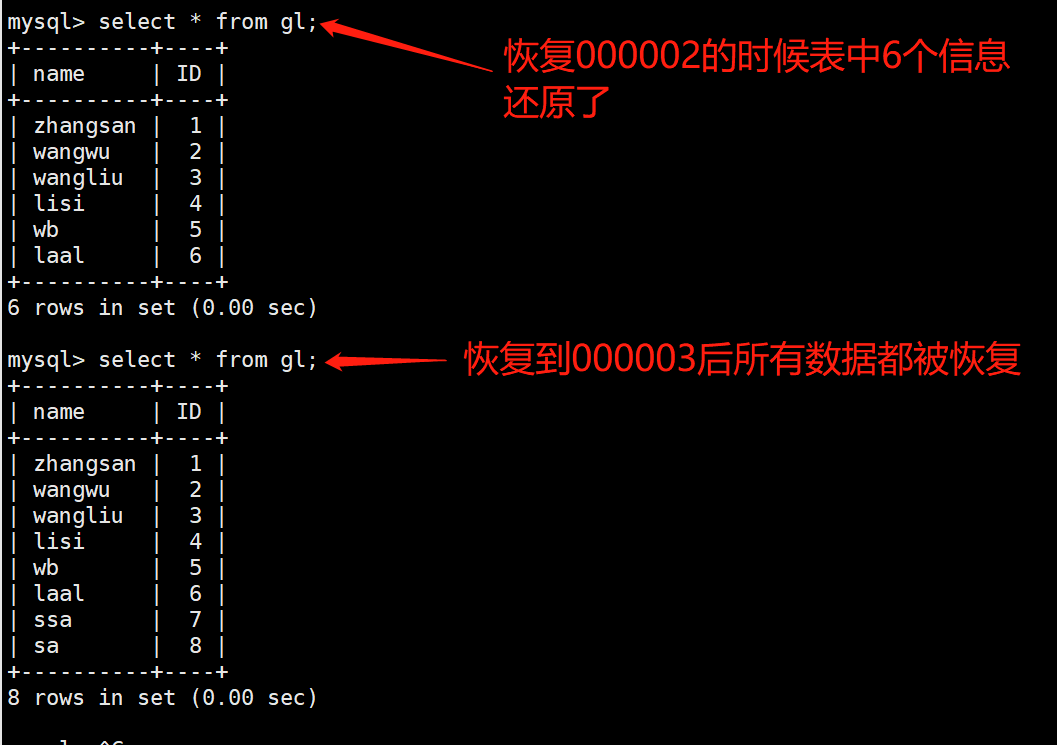
#Restore the data based on the full backup of 00000 1, restore 00000 2 and 00000 3 in turn, and verify the results
mysqlbinlog --no-defaults mysql-bin.000001 | mysql -uroot -p
mysqlbinlog --no-defaults mysql-bin.000002 | mysql -uroot -p
mysqlbinlog --no-defaults mysql-bin.000003 | mysql -uroot -p
4. Point in time and location based recovery
Binary log can be used to realize recovery based on point in time and location. For example, if a table is deleted due to misoperation, it is useless to completely recover, because there are misoperation statements in the log. What we need is to recover to the state before the misoperation, skip the misoperation statements, and then recover the subsequent operation statements
4.1 point in time based recovery
Point in time based recovery is to import the binary file of a certain starting time into the database, so as to skip a certain wrong point in time to realize data recovery
Use mysqlbinlog plus the – stop datetime option to indicate the time point at which to end, and the following misoperated statements will not be executed
The – start datetime option means that the following statement is executed
Using them together, you can skip the misoperation statements and complete the recovery work
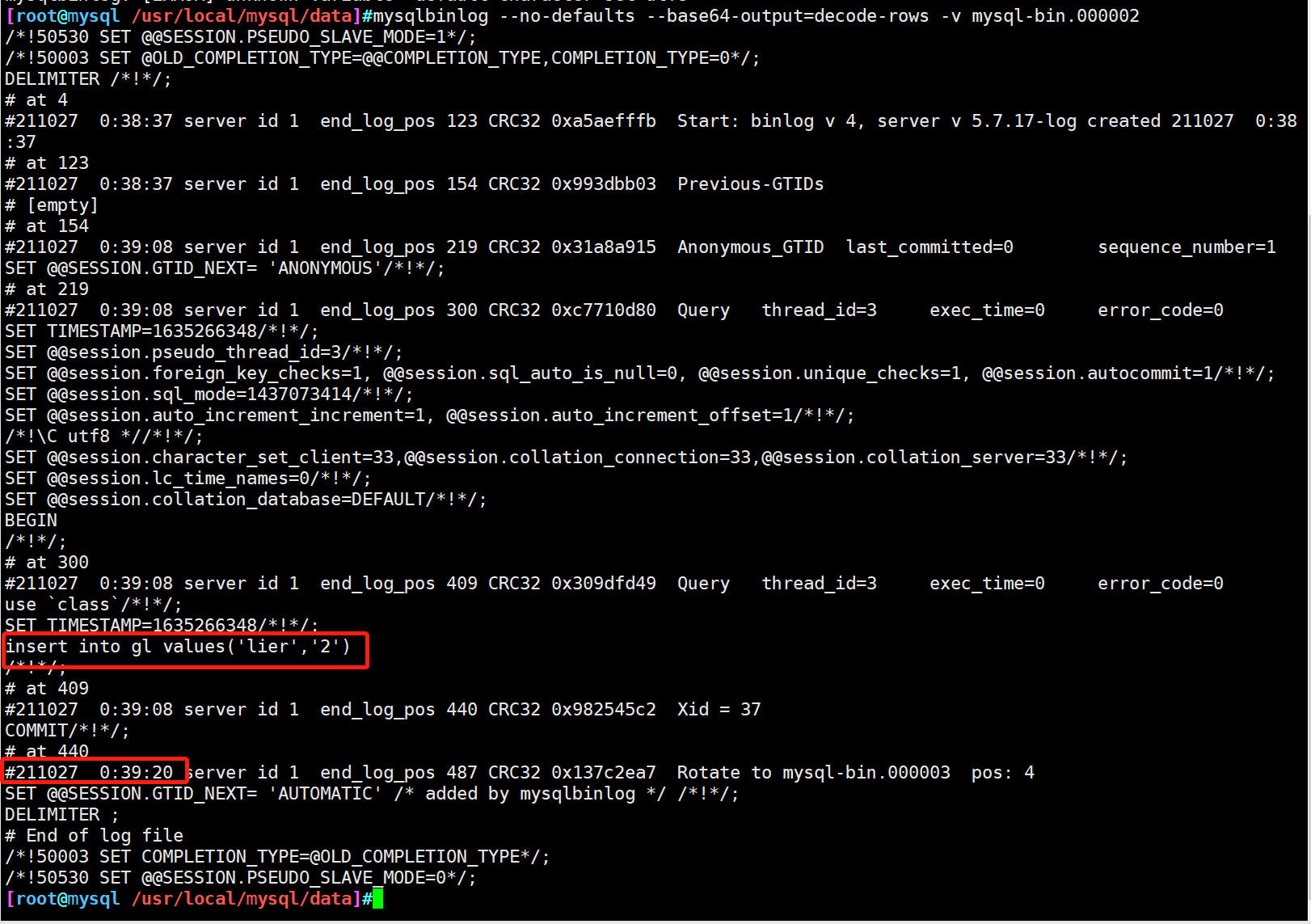
It should be noted that the date format saved in the binary file needs to be adjusted to be separated by "-"
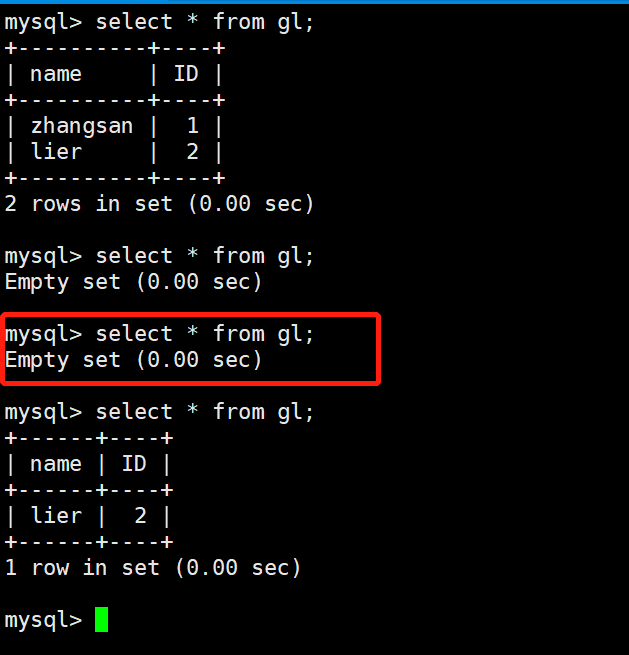
#Recover data for user "lier" mysql -uroot -p123456 -e "truncate table class.gl;" #Clear table data mysql -uroot -p123123 -e "select * from class.gl;" mysqlbinlog --no-defaults --stop-datetime='2021-10-27 0:39:20' mysql-bin.000002 |mysql -uroot -p123456 mysql -uroot -p123456 -e "select * from class.gl;"
4.2 location based recovery
Location based recovery is the use of point in time based recovery. There may be both correct and wrong operations at a point in time. Location based recovery is a more accurate method.
#Decode and read the details of binary file 02 (incremental backup) by line using 64 bit encoding mechanism mysqlbinlog --no-defaults --base64-output=decode-rows -v mysql-bin.000001
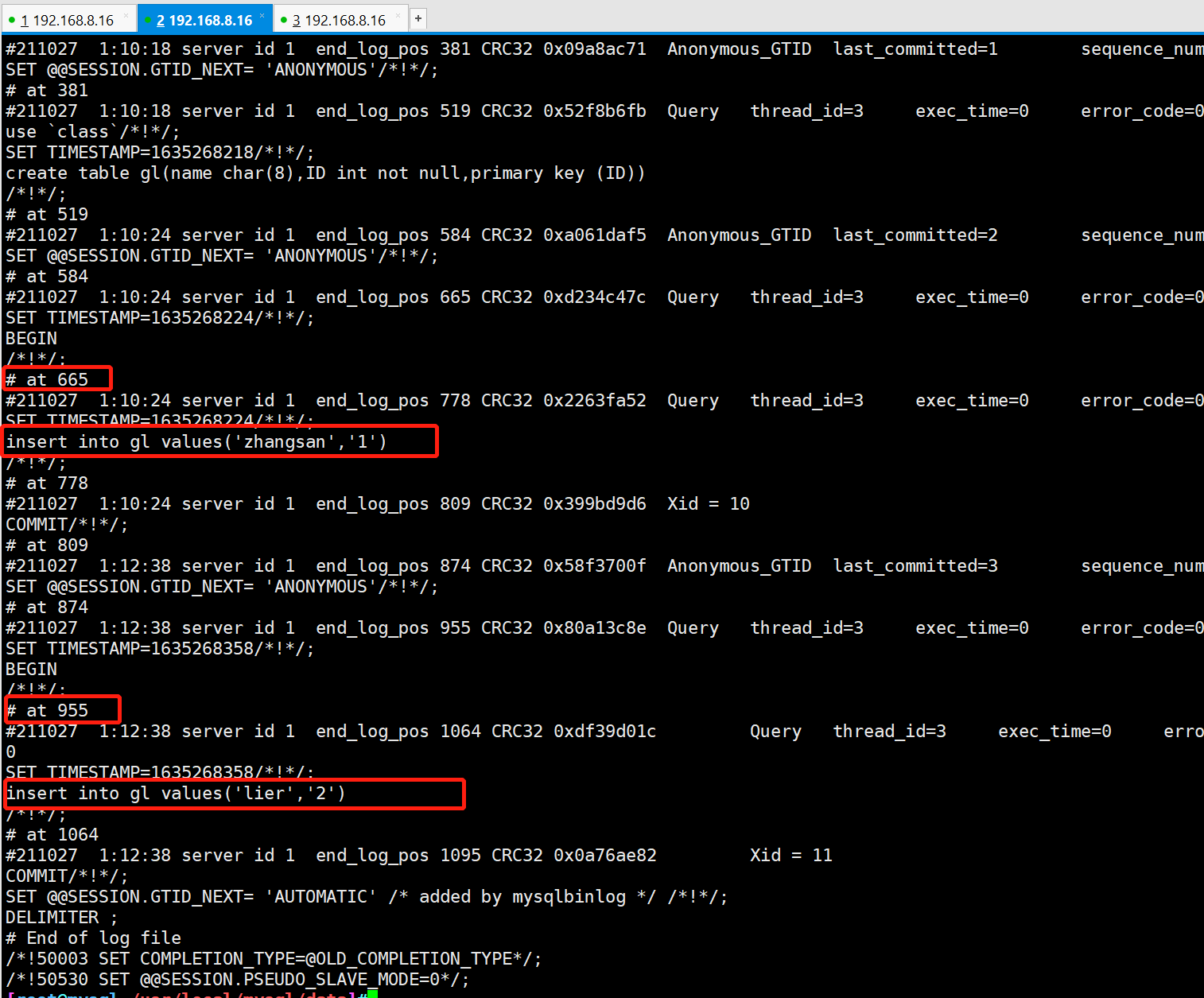
#Only the data before "778" is restored, that is, the data of "lier" is not restored mysql -uroot -p123456 -e "select * from class.gl;" mysql -uroot -p123456 -e "truncate table class.gl;" mysql -uroot -p123456 -e "select * from class.gl;" mysqlbinlog --no-defaults --stop-position='778' mysql-bin.000001 | mysql -uroot -p123456 mysql -uroot -p123456 -e "select * from class.gl;"
#Recover only the data of "lier" mysql -uroot -p123456 -e "select * from class.gl;" mysqlbinlog --no-defaults --start-position='955' mysql-bin.000001 | mysql -uroot -p123456 mysql -uroot -p123456-e "select * from class.gl;"
5. Idea of specifying enterprise backup strategy
- Specify the enterprise backup strategy according to the actual reading and writing frequency of the enterprise database and the importance of the data
- If the data is updated frequently, it should be backed up more frequently
- If the data is more important, backup it when there are appropriate updates
- Perform full backup in the period when the database pressure is low, such as once a week, and then add backup every day
- According to the size of the company, small and medium-sized companies can be fully prepared once a day, while large companies can be fully prepared once a week, with additional preparation once a day, and try to realize the master-slave replication architecture for enterprises
summary
- Incremental backup using split log
- Incremental backup needs to be performed one by one according to the time sequence of log files
- Data can be recovered more accurately by using time and location-based recovery