The 100 case tutorial of Python crawler was written from July 30, 2018 to October 28, 2020 for nearly 800 days. It is still one of the best-selling columns in the field of Python crawler.
However, over time, some of the 100 Python crawlers captured the target website, and the address has become invalid. It's time for iterative upgrading.
On May 21, 2021, 120 upgraded Python crawlers were launched.
The update is as follows:
The update frequency is faster. 100 cases were completed in 800 days last time and 120 cases were completed in 300 days this time;
Update all target websites;
Update the latest framework;
The overall technical idea of Python crawler will not change, so you can still buy the original column to learn.
The purchase and preview address is https://dream.blog.csdn.net/category_9280209.html.
The update frequency of the column is 2 ~ 3 articles per week, ranging from shallow to deep. The column is written by older programmers.
The starting point of everything, 10 line code set, beauty
Prelude
Before formally writing crawler learning, complete the following contents first:
Can install Python environment, for example, install version 3.5, and switch to other versions;
Proficient in developing tools, such as VSCode and PyCharm;
Proficient in Python third-party libraries;
Can run Python script files and output hello world.
With the above skills, you can rest assured and boldly buy this column for learning.
As of May 20, 2021, the latest version of Python is version 3.9.5 on the official website. You can use this version directly or any version above 3.0.
Target data source analysis
The target address to be captured this time is:
http://www.netbian.com/mei/index.htm
You can join the group if you need the source code: 867538707 Get materials to learn!
Grab target:
Grab the pictures of the website, with a target of 2000.
The Python framework used is:
requests library, re module
Other technical stack supplements:
regular expression
Target site address rule:
http://www.netbian.com/mei/index.htm
http://www.netbian.com/mei/index_2.htm
http://www.netbian.com/mei/index_3.htm
Conclusion, the list page rule is http://www.netbian.com/mei/index_ {page}. htm.
Data range
164 pages in total;
20 pieces of data per page.
Label and page address of the picture
The label location code of the picture is as follows:
<li><a href="/desk/23397.htm" title="Lu Xuanxuan white shirt skirt professional dress beauty model wallpaper update time: 2021-04-11" target="_blank"><img src="http://Img.netbian.com/file/2021/0411/small30caf1465200926b08db3893c6f35f6c1618152842. JPG "ALT =" Lu Xuanxuan white shirt skirt professional dress beauty model wallpaper "> < b > Lu Xuanxuan white shirt skirt professional dress beauty model wallpaper</b></a></li>
The page address is / desk/23397.htm.
The sorting requirements are as follows
Generate URL addresses of all list pages;
Traverse the URL address of the list page and obtain the address of the picture detail page;
Enter the details page to obtain the large picture;
Save the picture;
After getting 2000 pictures, start enjoying them.
Code implementation time
After installing the requests module in advance, use pip install requests. If the access fails, switch to the domestic pip source.
Leave a little homework after class, how to set the global pip source.
The code structure is as follows:
import requests
# Grab function
def main():
pass
# analytic function
def format():
pass
# Storage function
def save_image():
pass
if __name__ == '__main__':
main()
First implement 10 lines of code to catch the beauty graph. For example, you need to know some front-end knowledge and regular expression knowledge before officially starting.
For example, when viewing a web page through a developer tool, the image materials are all in the < div class = "list" > and < div class = "page" > tags. The first thing to do is to disassemble the string and take out the target data part.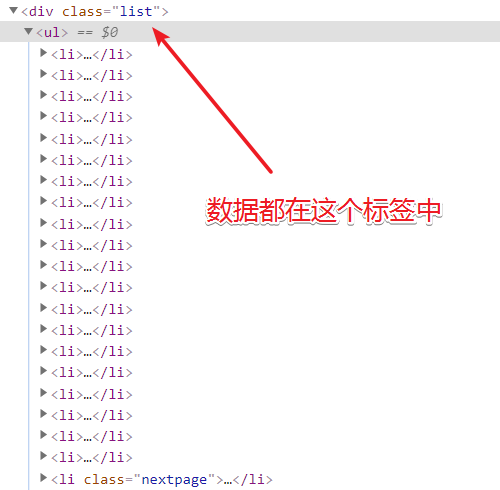
adopt requests Get the web page source code, the code is as follows.
# Grab function
def main():
url = "http://www.netbian.com/mei/index.htm"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"
}
res = requests.get(url=url, headers=headers, timeout=5)
res.encoding = "GBK"
print(res.text)
Use the get method of the requests module to obtain web page data. The parameters are the request address, request header and waiting time.
The user agent in the request header field can use the content I provided to you first, or it can be obtained through the developer tool.
After the data returns to the Response object, set the data code through res.encoding="GBK", which can be obtained from the web page source code.
Request to the data source code, that is, start parsing the data. If regular expressions are used, it is recommended to cut the target data first.
Clipping string is a relatively conventional operation in Python, which can be realized by writing code directly.
The two strings mentioned above are also used.
# analytic function
def format(text):
# Process string
div_html = '<div class="list">'
page_html = '<div class="page">'
start = text.find(div_html) + len(div_html)
end = text.find(page_html)
origin_text = text[start:end]
Finally get origin_text Is our target text.
Parsing target text through re module
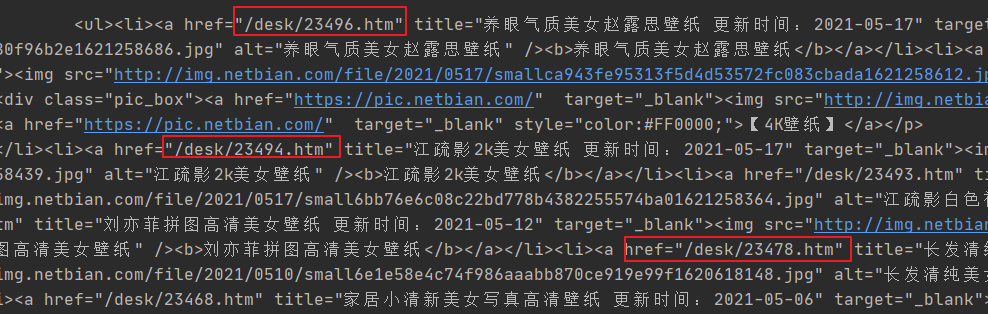
The target text returned above is as follows. The goal of this section is to obtain the address of the picture details page.
The technology used is the re module. Of course, it needs to be used with regular expressions. For regular expressions, you can follow the eraser a little bit.
# analytic function
def format(text):
# Process string
div_html = '<div class="list">'
page_html = '<div class="page">'
start = text.find(div_html) + len(div_html)
end = text.find(page_html)
origin_text = text[start:end]
pattern = re.compile('href="(.*?)"')
hrefs = pattern.findall(origin_text)
print(hrefs)
The re.compile method passes the regular expression, which is a syntax structure to retrieve the specific content of the string.
for example
.: represents any single character except line feed (\ n, \ r);
*: indicates that the preceding subexpression is matched zero or more times;
?: when this character follows any other restrictor (*, +,?, {n}, {n,}, {n,m}), the matching mode is non greedy, and non greedy is to reduce matching;
(): for group extraction.
With this knowledge, go back to the code to see the implementation.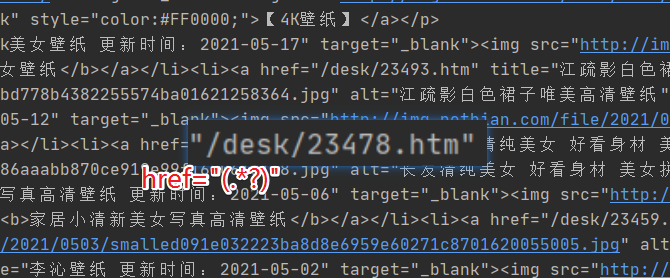
Suppose there is a string: href="/desk/23478.htm", using href="(.*?)" One of them can be / desk/23478.htm After matching, parentheses are also used to facilitate subsequent extraction.
The final output content is shown in the figure below.

Cleaning and crawling results
Some of the link addresses are incorrect and need to be removed from the list. In this step, use the list generator to complete the task.
pattern = re.compile('href="(.*?)"')
hrefs = pattern.findall(origin_text)
hrefs = [i for i in hrefs if i.find("desk")>0]
print(hrefs)
Grab inner page data
After obtaining the list page address, you can obtain the page data in the picture. The technology used here is consistent with the logic above.
# analytic function
def format(text, headers):
# Process string
div_html = '<div class="list">'
page_html = '<div class="page">'
start = text.find(div_html) + len(div_html)
end = text.find(page_html)
origin_text = text[start:end]
pattern = re.compile('href="(.*?)"')
hrefs = pattern.findall(origin_text)
hrefs = [i for i in hrefs if i.find("desk") > 0]
for href in hrefs:
url = f"http://www.netbian.com{href}"
res = requests.get(url=url, headers=headers, timeout=5)
res.encoding = "GBK"
format_detail(res.text)
break
Added in the first cycle break, jump out of the loop, format_detail The function is used to format the inner page data, still in the form of format string.
Since only one picture per page is the target data, the re.search Retrieve and call the of the object at the same time group Methods the data were extracted.
Duplicate code was found and will be optimized later.
def format_detail(text):
# Process string
div_html = '<div class="pic">'
page_html = '<div class="pic-down">'
start = text.find(div_html) + len(div_html)
end = text.find(page_html)
origin_text = text[start:end]
pattern = re.compile('src="(.*?)"')
image_src = pattern.search(origin_text).group(1)
# Save picture
save_image(image_src)
To save the picture, you need to import it in advance time Module to rename the picture.
use requests.get Method directly requests the picture address and calls the address of the response object content Property, get the binary stream, and then use f.write Store as a picture.
# Storage function
def save_image(image_src):
res = requests.get(url=image_src, timeout=5)
content = res.content
with open(f"{str(time.time())}.jpg", "wb") as f:
f.write(content)
Get the first picture and post it to the blog for record.

Optimize code
The code repetition logic is extracted and encapsulated into a common function. The final sorted code is as follows:
import requests
import re
import time
# Request function
def request_get(url, ret_type="text", timeout=5, encoding="GBK"):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"
}
res = requests.get(url=url, headers=headers, timeout=timeout)
res.encoding = encoding
if ret_type == "text":
return res.text
elif ret_type == "image":
return res.content
# Grab function
def main():
url = "http://www.netbian.com/mei/index.htm"
text = request_get(url)
format(text)
# analytic function
def format(text):
origin_text = split_str(text, '<div class="list">', '<div class="page">')
pattern = re.compile('href="(.*?)"')
hrefs = pattern.findall(origin_text)
hrefs = [i for i in hrefs if i.find("desk") > 0]
for href in hrefs:
url = f"http://www.netbian.com{href}"
print(f"Downloading:{url}")
text = request_get(url)
format_detail(text)
def split_str(text, s_html, e_html):
start = text.find(s_html) + len(e_html)
end = text.find(e_html)
origin_text = text[start:end]
return origin_text
def format_detail(text):
origin_text = split_str(text, '<div class="pic">', '<div class="pic-down">')
pattern = re.compile('src="(.*?)"')
image_src = pattern.search(origin_text).group(1)
# Save picture
save_image(image_src)
# Storage function
def save_image(image_src):
content = request_get(image_src, "image")
with open(f"{str(time.time())}.jpg", "wb") as f:
f.write(content)
print("Picture saved successfully")
if __name__ == '__main__':
main()
Run the code to get the running effect shown in the figure below.
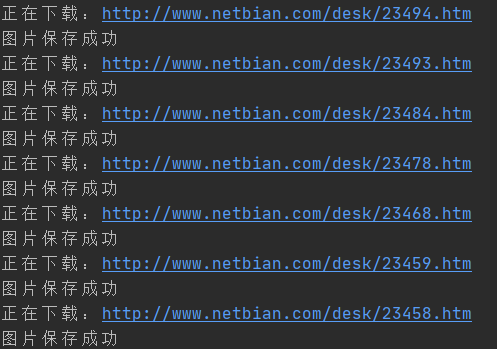
Target 2000 sheets
The crawling of 20 pictures has been obtained. The following target is 2000. You can grab them in this simple way at the beginning of learning.
What needs to be reformed in this step is main Function:
# Grab function
def main():
urls = [f"http://www.netbian.com/mei/index_{i}.htm" for i in range(2, 201)]
url = "http://www.netbian.com/mei/index.htm"
urls.insert(0, url)
for url in urls:
print("The address of the crawl list page is:", url)
text = request_get(url)
format(text)