The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation
In this paper, DenseNets is extended to solve the problem of semantic segmentation. The best results were obtained on the urban scene benchmark data sets (CamVid and Gatech), without further post-processing modules (such as CRF) and pre training models. In addition, due to the excellent structure of the model, this square root is much less than the best network parameters currently published on these data sets.
The idea behind DenseNets is to connect each layer with all layers in a feedforward way, which can make the network easier to train and more accurate.
The main contributions are:
- For the semantic segmentation task, the structure of DenseNets is extended to the full convolution network;
- A method of up sampling path in dense network is proposed, which has better performance than other up sampling paths.
- It is proved that the network can produce good results on the standard benchmark data set.
https://arxiv.org/abs/1611.09326
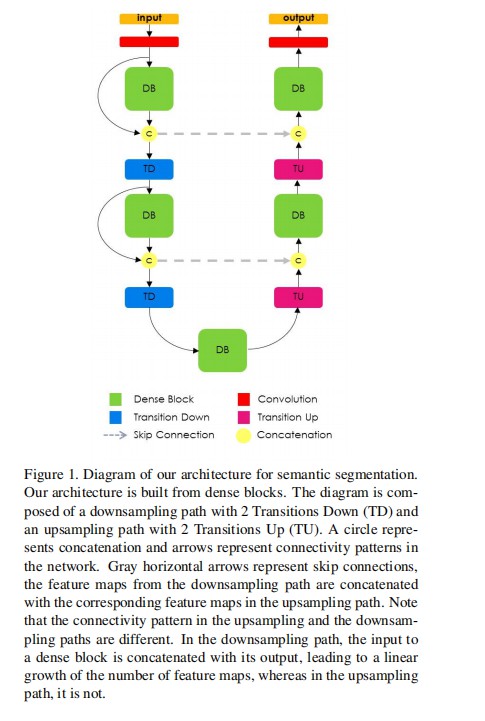
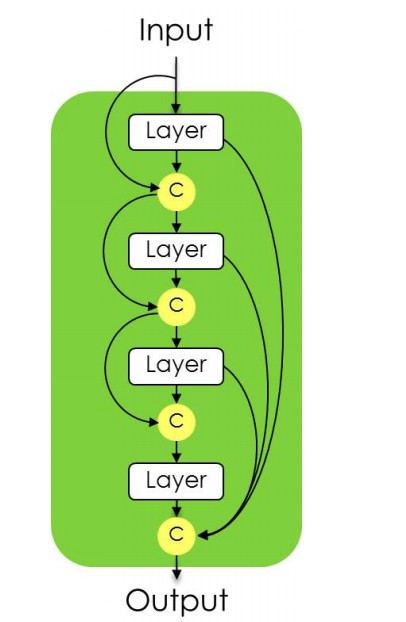
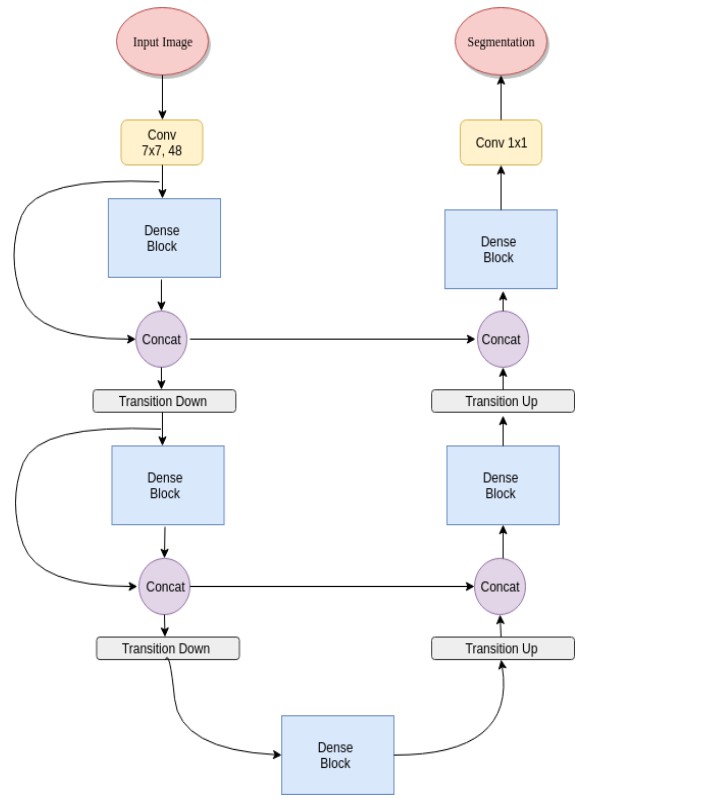
-
DenseBlock: BatchNormalization + Activation [ Relu ] + Convolution2D + Dropout
-
TransitionDown: BatchNormalization + Activation [ Relu ] + Convolution2D + Dropout + MaxPooling2D
-
TransitionUp: Deconvolution2D (Convolutions Transposed)

Thesis structure:
-
Abstract
The structure of a typical image segmentation model is: a down sampling module is used to extract rough semantic information; Then, a trained up sampling model is used to restore the size of the image; Finally, a post-processing unit is used to refine the model prediction.A new network architecture DenseNet was discovered
Extend DenseNets to semantic segmentation
-
Introduction
In order to compensate for the loss caused by the pooling layer, FCN introduces the skip connections jump connection structure in the path between down sampling and up sampling.This structure helps to increase accuracy and help rapid training optimization.
DenseNet: parameter efficiency; implicit deep supervision; feature reuse; For skip connections and multi-scale supervision
The main contributions of this paper: the DenseNet network architecture is introduced into FCN, and the exploration of characteristic graph is alleviated, that is, only the first few layers are used; An upsampling path based on deny blocks is proposed; State of the art in several data sets.
-
Related Work
Main improvement measures:Improve the path of up sampling (from simple bilinear interpolation - > unpolling or transferred convolutions - > skip connections);
Introduce extensive semantic understanding; Extended convolution; RNNS; Unsupervised global image descriptor; A semantic module based on extended convolution is proposed to expand the network
Give FCN the ability to structure: add a CRF module (Conditional Random Fields)
-
Fully Convolutional DenseNets
a down sampling path;an upsampling path;skip connections;
Skip join helps the up sampling path recover spatial details from the down sampling path by reusing feature mapping.
The goal of our model is to further utilize feature reuse by extending the more complex DenseNet architecture, while avoiding feature explosion on the sampling path on the network.DenseNetss review; DenseNets to FCNS; Semantic segmentation;
-
Experiments
Two benchmark data sets; IOU;Training details: HeUniform and RMSprop;
Two data sets;
-
Conclusion
formula

code
modularization
from keras.layers import Activation,Conv2D,MaxPooling2D,UpSampling2D,Dense,BatchNormalization,Input,Reshape,multiply,add,Dropout,AveragePooling2D,GlobalAveragePooling2D,concatenate
from keras.layers.convolutional import Conv2DTranspose
from keras.models import Model
import keras.backend as K
from keras.regularizers import l2
from keras.engine import Layer,InputSpec
from keras.utils import conv_utils
def BN_ReLU_Conv(inputs, n_filters, filter_size=3, dropout_p=0.2):
'''Apply successivly BatchNormalization, ReLu nonlinearity, Convolution and Dropout (if dropout_p > 0)'''
l = BatchNormalization()(inputs)
l = Activation('relu')(l)
l = Conv2D(n_filters, filter_size, padding='same', kernel_initializer='he_uniform')(l)
if dropout_p != 0.0:
l = Dropout(dropout_p)(l)
return l
def TransitionDown(inputs, n_filters, dropout_p=0.2):
""" Apply first a BN_ReLu_conv layer with filter size = 1, and a max pooling with a factor 2 """
l = BN_ReLU_Conv(inputs, n_filters, filter_size=1, dropout_p=dropout_p)
l = MaxPooling2D((2,2))(l)
return l
def TransitionUp(skip_connection, block_to_upsample, n_filters_keep):
'''Performs upsampling on block_to_upsample by a factor 2 and concatenates it with the skip_connection'''
#Upsample and concatenate with skip connection
l = Conv2DTranspose(n_filters_keep, kernel_size=3, strides=2, padding='same', kernel_initializer='he_uniform')(block_to_upsample)
l = concatenate([l, skip_connection], axis=-1)
return l
def SoftmaxLayer(inputs, n_classes):
"""
Performs 1x1 convolution followed by softmax nonlinearity
The output will have the shape (batch_size * n_rows * n_cols, n_classes)
"""
l = Conv2D(n_classes, kernel_size=1, padding='same', kernel_initializer='he_uniform')(inputs)
l = Reshape((-1, n_classes))(l)
l = Activation('softmax')(l)#or softmax for multi-class
return l
Using TensorFlow backend.
FC_DenseNet
def FC_DenseNet(
input_shape=(None, None, 3),
n_classes=1,
n_filters_first_conv=48,
n_pool=5,
growth_rate=16,
n_layers_per_block=[4, 5, 7, 10, 12, 15, 12, 10, 7, 5, 4],
dropout_p=0.2
):
if type(n_layers_per_block) == list:
print(len(n_layers_per_block))
elif type(n_layers_per_block) == int:
n_layers_per_block = [n_layers_per_block] * (2 * n_pool + 1)
else:
raise ValueError
#####################
# First Convolution #
#####################
inputs = Input(shape=input_shape)
stack = Conv2D(filters=n_filters_first_conv, kernel_size=3, padding='same', kernel_initializer='he_uniform')(inputs)
n_filters = n_filters_first_conv
#####################
# Downsampling path #
#####################
skip_connection_list = []
for i in range(n_pool):
for j in range(n_layers_per_block[i]):
l = BN_ReLU_Conv(stack, growth_rate, dropout_p=dropout_p)
stack = concatenate([stack, l])
n_filters += growth_rate
skip_connection_list.append(stack)
stack = TransitionDown(stack, n_filters, dropout_p)
skip_connection_list = skip_connection_list[::-1]
#####################
# Bottleneck #
#####################
block_to_upsample = []
for j in range(n_layers_per_block[n_pool]):
l = BN_ReLU_Conv(stack, growth_rate, dropout_p=dropout_p)
block_to_upsample.append(l)
stack = concatenate([stack, l])
block_to_upsample = concatenate(block_to_upsample)
#####################
# Upsampling path #
#####################
for i in range(n_pool):
n_filters_keep = growth_rate * n_layers_per_block[n_pool + i]
stack = TransitionUp(skip_connection_list[i], block_to_upsample, n_filters_keep)
block_to_upsample = []
for j in range(n_layers_per_block[n_pool + i + 1]):
l = BN_ReLU_Conv(stack, growth_rate, dropout_p=dropout_p)
block_to_upsample.append(l)
stack = concatenate([stack, l])
block_to_upsample = concatenate(block_to_upsample)
#####################
# Softmax #
#####################
output = SoftmaxLayer(stack, n_classes)
model = Model(inputs=inputs, outputs=output)
return model