catalogue
2.3 MATCH RETURN command syntax
2.5 CREATE create multiple labels
2.7 DELETE clause and REMOVE clause
3.1.4 the shortest path returned by the shortestpath function
3.2 CQL multi depth relation node
2. Query direct connection node
3.4.5 viewing and deleting indexes
3.5.2 attribute constraint (available in enterprise version)
Part II Neo4j CQL
2.1 introduction to CQL
CQL stands for Cypher query language. Like relational databases with query language SQL, Neo4j uses CQL as the query language.
Neo4j CQL
- The query language of Neo4j graphic database.
- A declarative pattern matching language.
- Follow SQL syntax.
- Grammar is a very simple, human and readable format.
Common Neo4j CQL commands / terms are as follows:
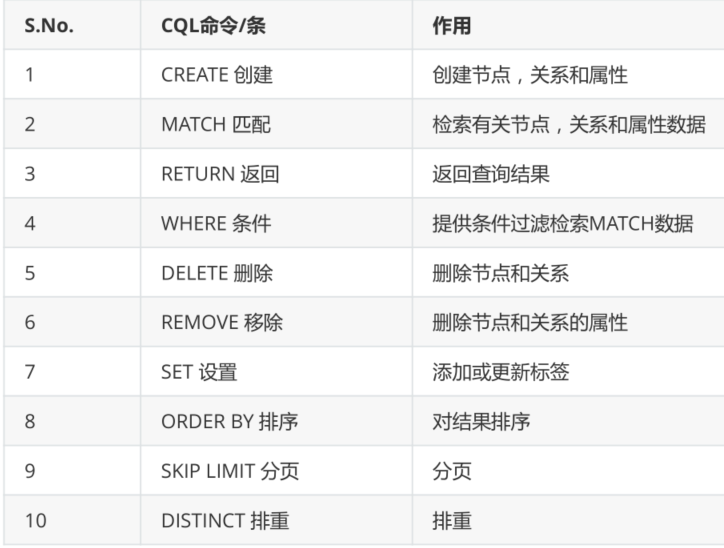
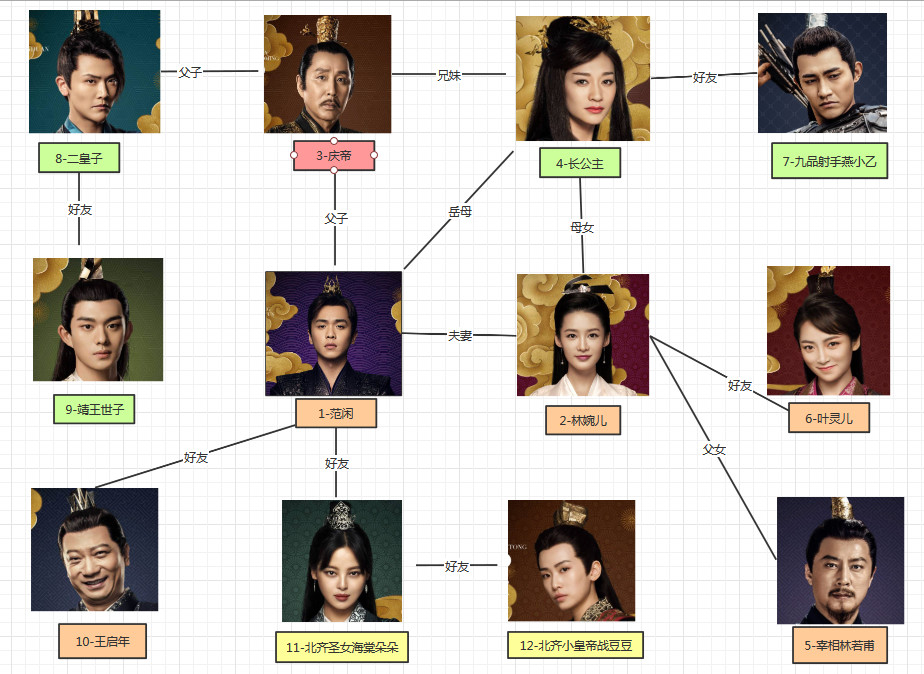
After completing the above grammar, we are based on the relationship pictures of TV characters:
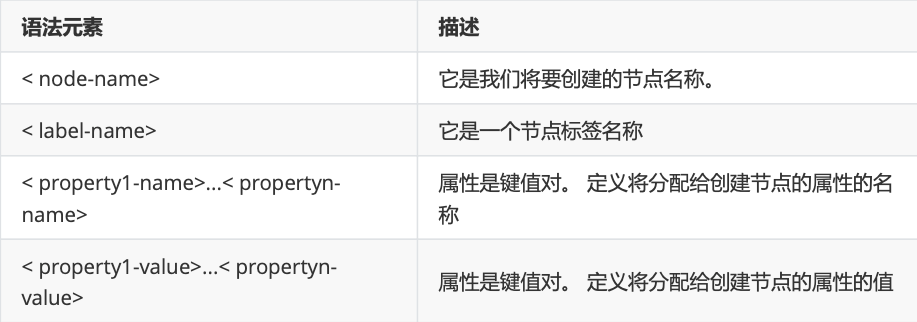
2.2 CREATE
CREATE (<node-name>:<label-name>
{<property1-name>:<property1-Value>,
........,
<propertyn-name>:<propertyn-Value>})Syntax description:
give an example:
CREATE (person:Person)
CREATE (person:Person
{cid:1,name:"Fan Xian",age:24,gender:0,character:"A",money:1000});
CREATE (person:Person
{cid:2,name:"Lin Waner",age:20,gender:1,character:"B",money:800});
CREATE (person:Person
{cid:3,name:"Qing Emperor",age:49,gender:0,character:"A",money:8900});2.3 MATCH RETURN command syntax
MATCH
(
<node-name>:<label-name>
)
RETURN
<node-name>.<property1-name>,
...
<node-name>.<propertyn-name>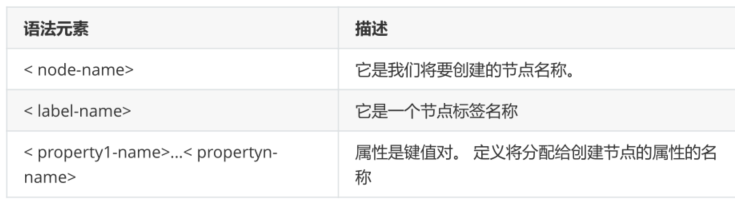
give an example:
MATCH (person:Person) return person MATCH (person:Person) return person.name,person.age
2.4 relationship creation
- Create a relationship without attributes using an existing node
MATCH (<node1-name>:<node1-label-name>)
,(<node2-name>:<node2-label-name>)
CREATE
(<node1-name>)-[<relationship-name>:<relationship-label-name>]->(<node2-name>)
RETURN Corresponding contentSyntax description:
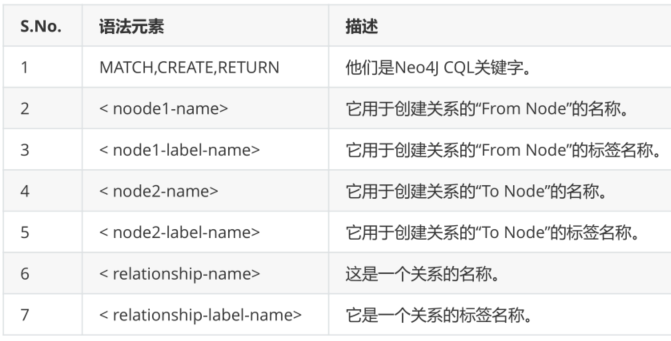
// Create relationship
match (person:Person {name:"Fan Xian"})
,(person2:Person {name:"Lin Waner"})
create
(person)-[r:Couple]->(person2);
// Query relation
match
p = (person:Person {name:"Fan Xian"})-[r:Couple]->(person2:Person)
return p
match
(p1:Person {name:"Fan Xian"})-[r:Couple]-(p2:Person)
return p1,p2
match
(p1:Person {name:"Fan Xian"})-[r:Couple]-(p2:Person)
return r- Create relationships with attributes using existing nodes
MATCH (<node1-label-name>:<node1-name>)
,(<node2-label-name>:<node2-name>)
CREATE
(<node1-label-name>)-[<relationship-label-name>:<relationship-name>{<define-properties-list>}]->(<node2-label-name>)
RETURN <relationship-label-name>
# Where < define properties list > is the list of properties (name value pairs) assigned to the newly created relationship.
{
<property1-name>:<property1-value>,
<property2-name>:<property2-value>,
...
<propertyn-name>:<propertyn-value>
}match
(person:Person {name:"Fan Xian"}),(person2:Person {name:"Lin Waner"})
create
(person)-[r:Couple{mary_date:"12/12/2014",price:55000}]->(person2)
return r;- Create a relationship without attributes using a new node
CREATE
(<node1-label-name>:<node1-name>)
-[<relationship-label-name>:<relationship-name>]
->(<node1-label-name>:<node1-name>)create
(person1:Person {cid:4,name:"Long Princess",age:49,gender:1,character:"A",money:5000})
-[r:Friend]
->(person2:Person {cid:7,name:"Jiupin shooter Yan Xiaoyi",age:48,gender:0,character:"B",money:1000})- Create a relationship with attributes using a new node
CREATE
(<node1-label-name>:<node1-name>{<define-properties-list>})
-[<relationship-label-name>:<relationship-name>{<define-properties-list>}]
->(<node1-label-name>:<node1-name>{<define-properties-list>})create
(person1:Person {cid:9,name:"King Jing Shizi",age:23,gender:0,character:"A",money:3000})
<-[r:Friend {date:"11-02-2000"}]
->(person2:Person {cid:8,name:"Second prince",age:24,gender:0,character:"B",money:6000})The types that can be used for the properties of relationships and nodes
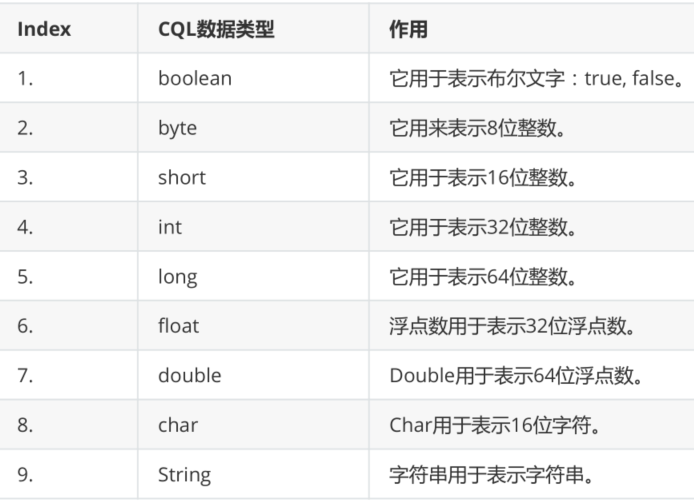
2.5 CREATE create multiple labels
CREATE
(<node-name>:<label-name1>:<label-name2>.....:<label-namen>)
# For example:
CREATE
(person:Person:Beauty:Picture {cid:20,name:"Little beauty"})2.6 WHERE clause
# Simple WHERE clause
WHERE <condition>
# Complex WHERE clause
WHERE <condition> <boolean-operator> <condition>The comparison operators in where are the same as those in previous mysql, such as =! = < > >< etc.
MATCH
(person:Person)
WHERE
person.name = 'Fan Xian' OR person.name = 'King Jing Shizi'
RETURN person2.7 DELETE clause and REMOVE clause
DELETE clause
- Delete node.
- Delete nodes and related nodes and relationships.
match
p = (:Person {name:"Lin Waner"})-[r:Couple]-(:Person)
delete rREMOVE clause
- Delete the label of a node or relationship
- Delete attributes of a node or relationship
MATCH (person:Person {name:"Little beauty"})
REMOVE person.cid2.8 SET clause
- Add a new attribute to an existing node or relationship
- Update attribute values
MATCH (person:Person {cid:1})
SET person.money = 3456,person.age=252.9 ORDER BY clause
The "ORDER BY" clause sorts the results returned by the MATCH query.
We can sort rows in ascending or descending order.
By default, it sorts rows in ascending order. If we want to sort them in descending order, we need to use the DESC clause.
MATCH (person:Person) RETURN person.name,person.money ORDER BY person.money DESC
2.10 SKIP and LIMIT
Neo4j CQL has provided a "SKIP" clause to filter or limit the number of rows returned by the query. It refines the results at the top of the CQL query result set.
Neo4j CQL has provided a "LIMIT" clause to filter or LIMIT the number of rows returned by the query. It trims the results at the bottom of the CQL query result set
MATCH (person:Person) RETURN ID(person),person.name,person.money ORDER BY person.money DESC skip 4 limit 2
2.11 DISTINCT weight removal
This function is used like the distinct keyword in SQL and returns all different values
MATCH (p:Person) RETURN Distinct(p.character)
Part III Neo4j CQL advanced
3.1 CQL function
3.1.1 string function
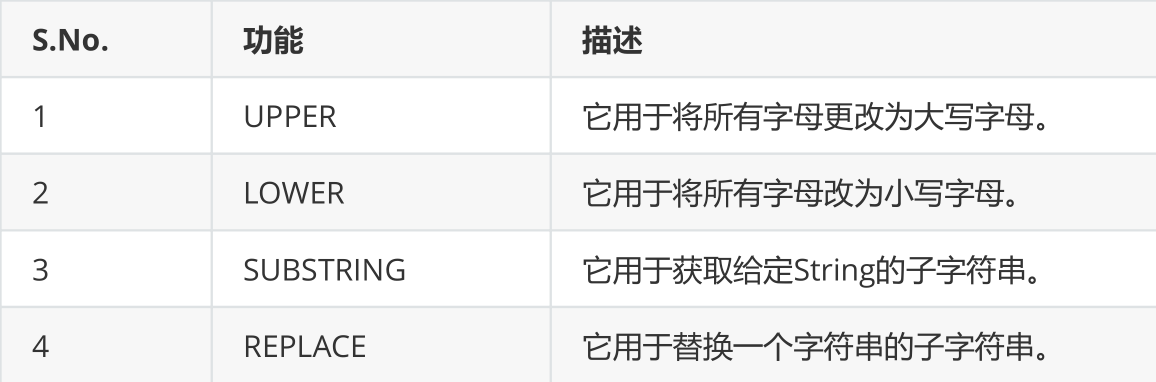
MATCH (p:Person) RETURN ID(p),LOWER(p.character)
match(p:Person)
return
p.character,
lower(p.character),
p.name,
substring(p.name,2),
replace(p.name,"son","z i")3.1.2 aggregate function
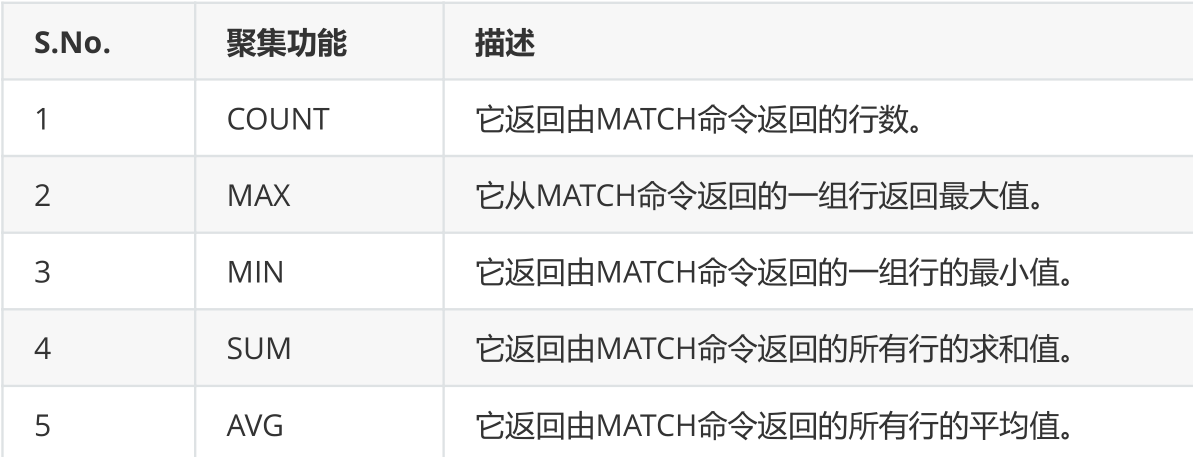
MATCH (p:Person) RETURN MAX(p.money),SUM(p.money)
3.1.3 relation function
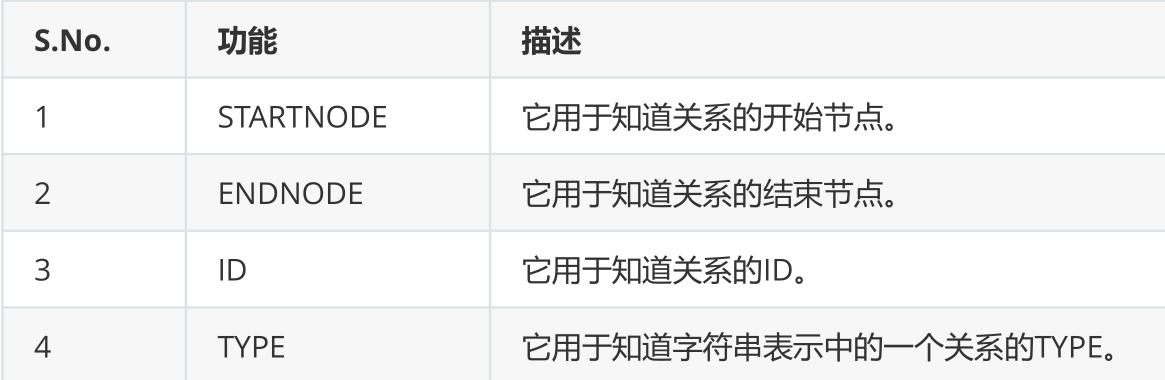
match p = (:Person {name:"Lin Waner"})-[r:Couple]-(:Person)
RETURN STARTNODE(r)3.1.4 the shortest path returned by the shortestpath function
MATCH p=shortestPath( (node1)-[*]-(node2) ) RETURN length(p), nodes(p)
MATCH p=shortestPath
((person:Person {name:"Wang Qinian"})
-[*]-(person2:Person {name:"Jiupin shooter Yan Xiaoyi"}) )
RETURN length(p), nodes(p)3.2 CQL multi depth relation node
1. Use the with keyword
The query three-level relationship nodes are as follows: with can use the previous query results as the subsequent query criteria
match (na:Person)-[re]->(nb:Person) where na.name="Fan Xian" WITH na,re,nb match (nb:Person)-[re2]->(nc:Person) return na,re,nb,re2,nc match (na:Person)-[re]->(nb:Person) where na.name="Lin Waner" WITH na,re,nb match (nb:Person)-[re2]->(nc:Person) return na,re,nb,re2,nc match (na:Person)-[re]-(nb:Person) where na.name="Lin Waner" WITH na,re,nb match (nb:Person)-[re2]->(nc:Person) return na,re,nb,re2,nc match (na:Person)-[re]-(nb:Person) where na.name="Lin Waner" WITH na,re,nb match (nb:Person)-[re2:Friends]->(nc:Person) return na,re,nb,re2,nc
2. Query direct connection node
match
(na:Person{name:"Fan Xian"})
-[re]->(nb:Person)
-[re2]->(nc:Person)
return na,re,nb,re2,ncFor convenience, you can assign the query result to a variable and then return it
match data=
(na:Person{name:"Fan Xian"})
-[re]->(nb:Person)
-[re2]->(nc:Person)
return data3. Use depth operator
When implementing multi depth relational node query, it is obviously cumbersome to use the above methods.
Variable number of relationships - > nodes can use - [: TYPE*minHops..maxHops] -.
Query:
match data=(na:Person{name:"Fan Xian"})-[*1..2]-(nb:Person)
return data3.3 transactions
In order to maintain data integrity and ensure good transaction behavior, Neo4j also supports ACID feature.
be careful:
(1) All data modification operations to Neo4j database must be encapsulated in transactions.
(2) The default isolation level is READ_COMMITTED.
(3) Deadlock protection has been built into core transaction management. (Neo4j will detect the deadlock and throw an exception before the deadlock occurs. Before the exception is thrown, the transaction will be marked as rollback. When the transaction ends, the transaction will release the lock it holds, and the deadlock caused by the lock of the transaction will be released, and other transactions can continue to execute. When the user needs it, the transaction that threw the exception can try to execute again.)
(4) Unless otherwise specified, the operations of Neo4j API are thread safe, and there is no need to use external synchronization methods for Neo4j database operations.
3.4 index
3.4.1 introduction
Neo4j CQL supports indexes on node or relational attributes to improve application performance.
You can create indexes on attributes with the same label name.
These index columns can be used on operators such as MATCH or WHERE to improve the execution of CQL.
3.4.2 creating a single index
CREATE INDEX ON :Label(property)
For example:
CREATE INDEX ON :Person(name)
3.4.3 create composite index
CREATE INDEX ON :Person(age, gender)
3.4.4 full text mode index
The previous conventional pattern index can only accurately match strings or pre suffix indexes (startswitch, endswitch, contains). The full-text index will tokenize the index string value, so it can match terms anywhere in the string. How the index string is tokenized and decomposed into terms depends on the analyzer that configures the full-text schema index. Indexes are created through attributes, which is convenient to quickly find nodes or relationships.
Create and configure full-text schema indexes
Create a full-text schema index using db.index.fulltext.createNodeIndex and db.index.fulltext.createRelationshipIndex. When creating an index, each index must specify a unique name for each index to refer to the relevant specific index when querying or deleting the index. The full-text schema index is then applied to the label list or relationship type list, to the node and relationship indexes, respectively, and then to the attribute name list.
call db.index.fulltext.createNodeIndex
("Index name",[Label,Label],[attribute,attribute])
call db.index.fulltext.createNodeIndex
("nameAndDescription",["Person"],["name", "description"])
call db.index.fulltext.queryNodes
("nameAndDescription", "Fan Xian")
YIELD node, score
RETURN node.name, node.description, score3.4.5 viewing and deleting indexes
call db.indexes or: schema
DROP INDEX ON :Person(name)
DROP INDEX ON :Person(age, gender)
call db.index.fulltext.drop("nameAndDescription")
3.5 constraints
3.5.1 uniqueness constraints
effect
- Avoid duplicate records.
- Enforce data integrity rules
Create uniqueness constraint
CREATE CONSTRAINT ON (variable:<label_name>) ASSERT variable.<property_name> IS UNIQUE
Specific examples:
CREATE CONSTRAINT ON (person:Person) ASSERT person.name IS UNIQUE
Delete uniqueness constraint
DROP CONSTRAINT ON (cc:Person) ASSERT cc.name IS UNIQUE
3.5.2 attribute constraint (available in enterprise version)
CREATE CONSTRAINT ON (p:Person) ASSERT exists(p.name)
3.5.3 viewing constraints
call db.constraints :schema