1. General
torch.nn.Embedding is used to turn a number into a vector of a specified dimension. For example, number 1 becomes a 128 dimensional vector and number 2 becomes another 128 dimensional vector. However, these 128 dimensional vectors are not immutable. These 128 dimensional vectors are the real input of the model (that is, the first layer of the model) (numbers 1 and 2 are not, and can be counted as the first layer of the model). Then these 128 dimensional vectors will participate in the model training and be updated, so that number 1 will have a better representation of 128 dimensional vectors.
Obviously, this is very similar to the full connection layer, so many people say that the Embedding layer is a special case of the full connection layer.
2.Embedding
import numpy as np import torch.nn as nn import torch
For example, we have two words,
vocab={"I":0,"you":1}
There are two ways to turn these two words into vectors:
2.1 full connection layer
vocab={"I":0,"you":1}
vocab_vec=torch.eye(2)#To construct a one hot vector, you need to use two two-dimensional vectors to represent these two words.
print(vocab_vec)
tensor(
[[1., 0.],
[0., 1.]]
)
However, it is well known that one hot vector does not have any semantic information, and in this one hot, the space is huge. We need a low dimensional dense vector to replace the one hot vector. Very simple, just a linear layer.
fc=nn.Linear(2,2)#It turns out that the vector dimension of a word is 2. For simplicity, after we connect it all, it is still 2 fc(vocab_vec)

The above is the representation of the two words we want, and then input the above into the subsequent layer of the model for training. In this way, since the parameters of the linear layer fc will change continuously, the above value fc(vocab_vec) will certainly change accordingly.
2.2 Embedding layer
It will be simpler and more convenient to use this. We don't need to construct a one hot vector. As we said at the beginning, the Embedding layer directly converts a number into a vector of the dimension you want, which is a good thing! For example, when you don't have enough memory, you don't need to store an extra one hot matrix like the above method.
vocab={"I":0,"you":1}
embedding=torch.nn.Embedding(vocab_size,emb_size)#It turns out that the vector dimension of a word is 2. For simplicity, after we connect it all, it is still 2
Then, if we want to get the vectors of our two words ("I" and "you"), we only need to input the numbers of "I" and "you", rather than the one hot vector. For example, the number of "I" is 0 and the number of "you" is 1:
me=torch.tensor([0],dtype=torch.int64) you=torch.tensor([1],dtype=torch.int64)
Then pass the above parameters into the embedding layer.
print(embedding(me)) print(embedding(you))
tensor([[0.6188, 1.5322]], grad_fn=<EmbeddingBackward>)
tensor([[-0.8198, -0.9139]], grad_fn=<EmbeddingBackward>)
You get the vector of the above two words. Of course, we can also combine to get:
meyou=torch.tensor([0,1],dtype=torch.int64) print(embedding(meyou))
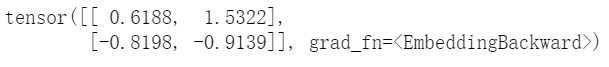
Similarly, the vector obtained above is input into the follow-up of the model. After training, the parameters of the Embedding layer will change, so we get a better word vector.
ending
It can be seen that Embedding and Linear are almost the same. The difference is that the input is different. One is the input number, and the latter is the input one-hot vector. Traditionally, we use Embedding instead of Linear in the first layer of the model. The subsequent of the model will no longer use Embedding, but Linear.
Add: when we define the above, the parameters are initialized.
fc=nn.Linear(2,2) embedding=torch.nn.Embedding(vocab_size,emb_size)
Sometimes, we may think it is not initialized well and want to specify it according to our. What should we do? 1. Assign values directly with nn.Parameter.
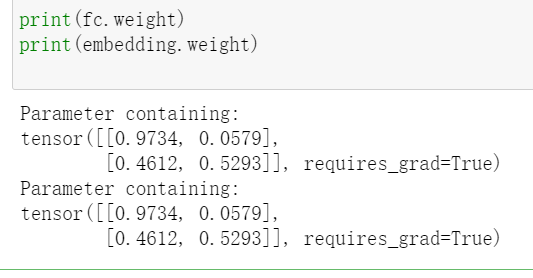
myemb=nn.Parameter(torch.rand(2,2))#(0,1) uniformly distributed parameters print(fc.weight)#customary fc.weight=myemb#modify print(embedding.weight)#customary embedding.weight=myemb#modify

Let's review the modified:
Of course, there are many other methods. 2. Use. data:
embedding.weight.data.uniform_(-1,1)#Then it is changed to the uniform distribution of (- 1,1).
embedding.weight#Check it out

Moreover, the above two methods are applicable to embedding and Linear. However, there is another method for embedding. 3.nn.Embedding.from_pretrained
a=torch.tensor([[1,2],[2,2]],dtype=torch.float32) embedding=nn.Embedding.from_pretrained(a) embedding.weight
