Note source: Dark horse programmers have a comprehensive and in-depth study of Java Concurrent Programming and a full set of tutorials of JUC concurrent programming
Note source: AC_Jobim JUC concurrent programming tutorial
Some personal opinions are attached. If there are mistakes, please correct them!
1, ThreadLocal details
Good blog:
Hit the nail on the head ThreadLocal
Java: here comes the knowledge about ThreadLocal
From simple to deep, fully analyze ThreadLocal
1.1 use of ThreadLocal
ThreadLocal functions:
- ThreadLocal can realize that each thread has its own copy of local variables, and different threads will not interfere with each other. It mainly solves the problem of allowing each thread to bind its own value. By using the get() and set() methods, it can obtain the default value or change its value to the value of the copy stored in the current process, so as to avoid thread safety problems.
Usage scenario of ThreadLocal:
- In Java multi-threaded programming, in order to ensure the safe access of multiple threads to shared variables, synchronized is usually used to ensure that only one thread operates on shared variables at the same time. In this case, you can put class variables into ThreadLocal objects to make variables have independent copies in each thread, so that one thread will not be modified by another thread when reading variables.
- When transferring objects across layers, using ThreadLocal can avoid multiple transfers and break the constraints between layers.
- Data isolation between threads
- Conduct transaction operation, which is used to store thread transaction information.
- Database connection, Session management.
Difference between ThreadLocal and Synchronized:
| synchronized | ThreadLocal | |
|---|---|---|
| principle | The synchronization mechanism uses the way of exchanging time for space, and only provides a variable for different threads to queue up for access | ThreadLocal uses the method of exchanging space for time to provide a copy of variables for each thread, so as to achieve the same access without interference |
| emphasis | Synchronization of accessing resources between multiple threads | In multithreading, the data between each thread is isolated from each other |
Introduction to common API s of ThreadLocal
/**
Returns the value of the thread local variable in the current thread copy. If the variable has no value for the current thread, it is initialized first. Call the initialValue method to get the returned value.
*/
public T get() {}
/**
Returns the "initial value" of this thread local variable of the current thread. This method will be called the first time the thread uses the get method to access the variable
Unless the set method is invoked before the thread, in this case, the initialValue method will not be invoked by the thread.
Usually, this method is called at most once per thread, but it may be called again in the case of subsequent calls to remove and get.
*/
protected T initialValue() {
return null;
}
/**
Deletes the value of the current thread local variable. If the thread local variable is subsequently called get by the current thread, its value will be reinitialized by calling its initialValue method, unless its value is called set by the current thread during the transition. This may cause the initialValue method to be called multiple times in the current thread.
*/
public void remove() {}
/**
Sets a copy of this thread local variable of the current thread to the specified value. Most subclasses will not need to override this method, but only rely on the initialValue method to set the value of thread local variables
*/
public void set(T value) {}
/**
Create thread local variables. The initial value of the variable is determined by the Supplier's get method on the method. jdk1.8.
*/
public static <S> ThreadLocal<S> withInitial(Supplier<? extends S> supplier) {}
ThreadLocal is easy to use. The following code is used to buy tickets for two threads, which do not affect each other.
class House {
ThreadLocal<Integer> threadLocal = ThreadLocal.withInitial(() -> 0);
public void saleHouse() {
Integer value = threadLocal.get();
value++;
threadLocal.set(value);
}
}
/**
* Two threads, each of which operates on its own data
*/
public class ThreadLocalDemo {
public static void main(String[] args) {
House house = new House();
new Thread(() -> {
try {
for (int i = 1; i <=3; i++) {
house.saleHouse(); // Thread t1 increased three times
}
System.out.println(Thread.currentThread().getName()+"\t"+"---"+house.threadLocal.get()); //t1 ---3
}finally {
house.threadLocal.remove();// If the custom ThreadLocal variable is not cleared, subsequent business logic and memory leakage may be affected
}
},"t1").start();
new Thread(() -> {
try {
for (int i = 1; i <=2; i++) {
house.saleHouse(); // Thread t2 was added twice
}
System.out.println(Thread.currentThread().getName()+"\t"+"---"+house.threadLocal.get()); //t2 ---2
}finally {
house.threadLocal.remove();
}
},"t2").start();
System.out.println(Thread.currentThread().getName()+"\t"+"---"+house.threadLocal.get()); //main ---0
}
}
Print results:

You can see that each thread has its own threadLocal value
SimpleDateFormat thread safe usage:

- Using SimpleDateFormat in multithreading has thread safety problems. If you do not want to use it, it is recommended to create an independent format instance for each thread. If multiple threads access a format at the same time, it must maintain external synchronization. Solution: 1. Define SimpleDateFormat as a local variable; 2. Use ThreadLocal, also known as thread local variable or thread local storage; 3. Lock
Example of correct use of code: (build date conversion tool class)
public class DateUtils {
private static final ThreadLocal<SimpleDateFormat> sdf_threadLocal =
ThreadLocal.withInitial(()-> new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"));
/**
* ThreadLocal You can ensure that each thread can get its own SimpleDateFormat object, so there will be no competition.
* @param stringDate
* @return
* @throws Exception
*/
public static Date parseDateTL(String stringDate)throws Exception {
return sdf_threadLocal.get().parse(stringDate);
}
public static void main(String[] args) throws Exception {
for (int i = 1; i <=30; i++) {
new Thread(() -> {
try {
System.out.println(DateUtils.parseDateTL("2020-11-11 11:11:11"));
} catch (Exception e) {
e.printStackTrace();
}
},String.valueOf(i)).start();
}
}
}
1.2 implementation principle of ThreadLocal
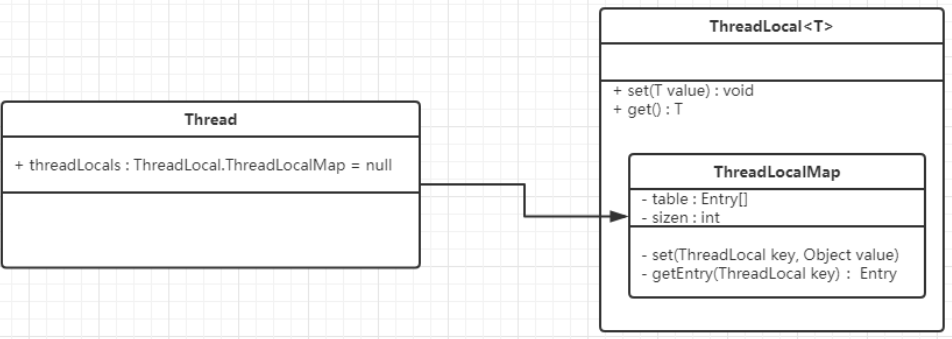
Relationship between Thread, ThreadLocal, ThreadLocalMap and Entry:
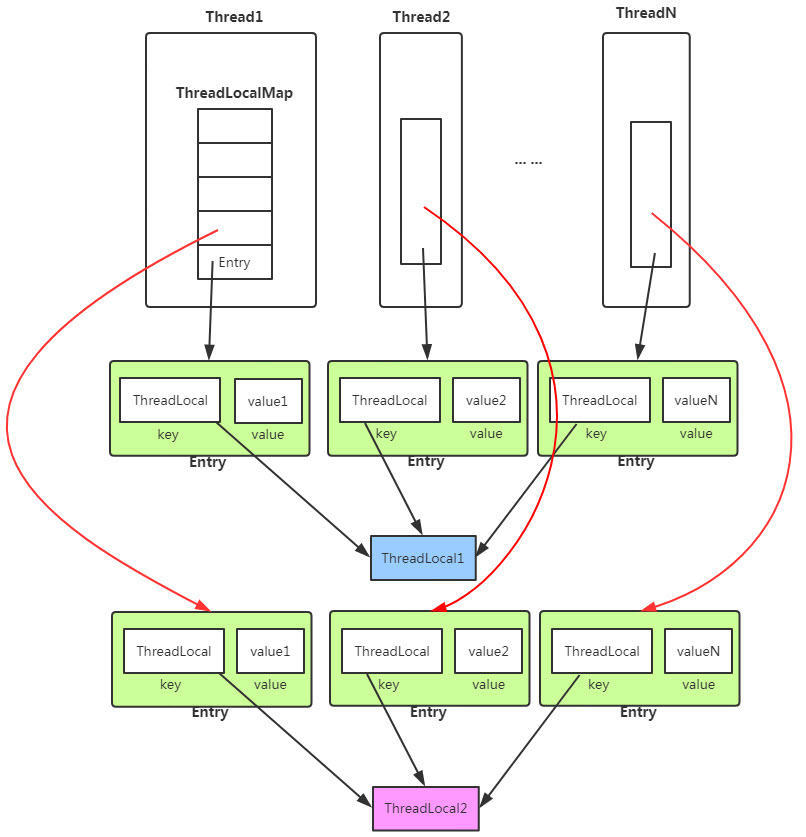
- Firstly, ThreadLocalMap stores Entry key value pairs in the form of array. It is a static internal class of Thread, and Entry is the static internal class of ThreadLocalMap. The key of Entry is ThreadLocal from new, and value is the value set in. Therefore, a Thread can have multiple ThreadLocal value key value pairs.
- The JVM maintains a thread version of Map < thread, t > (through the set method of ThreadLocal object, the ThreadLocal object is put into threadloadmap as a key). When each thread needs to use this T, it uses the current thread to get it from the Map. In this way, each thread has its own independent variables,
-
set method analysis
- First, get the current thread and get a Map according to the current thread
- If the obtained Map is not empty, set the parameter to the Map (the reference of the current ThreadLocal is used as the key)
- If the Map is empty, create a Map for the thread and set the initial value
// Function: sets the copy of this thread local variable of the current thread to the specified value public void set(T value) { // Get the current thread Thread t = Thread.currentThread(); // Get the ThreadLocalMap corresponding to the thread ThreadLocalMap map = getMap(t); // If the map is not empty, set the key value pair. This represents the ThreadLocal object that calls this method if (map != null) map.set(this, value); else // 1) The ThreadLocalMap object does not exist for the current Thread // 2) Then createMap is called to initialize the ThreadLocalMap object // 3) And store t (the current thread) and value (the value corresponding to t) as the first entry in ThreadLocalMap createMap(t, value); } /** * Get the ThreadLocalMap maintained corresponding to the current Thread * * @param t the current thread Current thread * @return the map Corresponding maintained ThreadLocalMap */ ThreadLocalMap getMap(Thread t) { return t.threadLocals; } /** *Create the maintained ThreadLocalMap corresponding to the current Thread * * @param t Current thread * @param firstValue The value of the first entry stored in the map */ void createMap(Thread t, T firstValue) { //This here is threadLocal that calls this method t.threadLocals = new ThreadLocalMap(this, firstValue); } -
get method analysis
- First, get the current thread and get a Map according to the current thread
- If the obtained Map is not empty, use the reference of ThreadLocal in the Map as the key to obtain the corresponding Entry e in the Map, otherwise go to 4
- If e is not null, return e.value, otherwise go to 4
- If the Map is empty or e is empty, obtain the initial value value through the initialValue function, and then use the reference and value of ThreadLocal as the firstKey and firstValue to create a new Map
public T get() { // Gets the current thread object Thread t = Thread.currentThread(); // Gets the ThreadLocalMap object maintained in this thread object ThreadLocalMap map = getMap(t); // If this map exists if (map != null) { // With the current ThreadLocal as the key, call getEntry to obtain the corresponding storage entity e ThreadLocalMap.Entry e = map.getEntry(this); // Judge e as empty if (e != null) { @SuppressWarnings("unchecked") // Get the value value corresponding to the storage entity e // That is, the value of this ThreadLocal corresponding to the current thread we want T result = (T)e.value; return result; } } /* Initialization: there are two situations in which the current code is executed The first case: the map does not exist, which means that this thread does not maintain a ThreadLocalMap object The second case: the map exists, but there is no entry associated with the current ThreadLocal */ return setInitialValue(); } // Initialization operation private T setInitialValue() { // Call initialValue to get the initialized value // This method can be overridden by subclasses. If it is not overridden, it returns null by default T value = initialValue(); // Gets the current thread object Thread t = Thread.currentThread(); // Gets the ThreadLocalMap object maintained in this thread object ThreadLocalMap map = getMap(t); // Determine whether the map exists if (map != null) // If it exists, call map.set to set the entity entry map.set(this, value); else // 1) The ThreadLocalMap object does not exist for the current Thread // 2) Then createMap is called to initialize the ThreadLocalMap object // 3) And store t (the current thread) and value (the value corresponding to t) as the first entry in ThreadLocalMap createMap(t, value); // Returns the set value value return value; } -
remove method analysis
- First, get the current thread and get a Map according to the current thread
- If the obtained Map is not empty, the entry corresponding to the current ThreadLocal object will be removed
/** * Delete the entity entry corresponding to ThreadLocal saved in the current thread */ public void remove() { // Gets the ThreadLocalMap object maintained in the current thread object ThreadLocalMap m = getMap(Thread.currentThread()); // If this map exists if (m != null) // map.remove is called if it exists // Delete the corresponding entity entry with the current ThreadLocal as the key m.remove(this); }
Principle of ThreadLocal:
- Each Thread object contains a member variable threadLocals of ThreadLocalMap type, which stores the data stored in this Thread
There is a ThreadLocal object and its corresponding value - ThreadLocalMap is composed of Entry objects, which inherit from WeakReference < ThreadLocal <? > >, An Entry consists of a ThreadLocal Object and an Object. It can be seen that the key of the Entry is a ThreadLocal Object and is a weak reference. When there is no strong reference to the key, the key will be recycled by the garbage collector
- When the set method is executed, ThreadLocal will first obtain the current thread object, and then obtain the ThreadLocalMap pair of the current thread
Elephant. Then take the current ThreadLocal object as the key and store the value in the ThreadLocalMap object. - The get method executes similarly. ThreadLocal will first get the current thread object, and then get the ThreadLocalMap of the current thread
Object. Then take the current ThreadLocal object as the key to obtain the corresponding value. - The key value of ThreadLocalMap is ThreadLocal object, and there can be multiple ThreadLocal variables, so it is saved in the map
- ThreadLocal itself does not store values. It is just used as a key to let the thread obtain values from ThreadLocalMap
- Since each thread contains its own private ThreadLocalMap containers, these containers are independent of each other and do not affect each other, so they will not exist
Thread safety, so there is no need to use synchronization mechanism to ensure the mutual exclusion of multiple threads accessing the container.
1.3 ThreadLocal memory leak
Good blog: ThreadLocal memory leak problem
What is a memory leak?
- For some reason, the heap memory that has been dynamically allocated in the Memory Leak program is not released or cannot be released, resulting in waste in the system, slowing down the running speed of the program and even system crash. The accumulation of memory leaks will eventually lead to memory overflow
- That is, the memory occupied by objects or variables that will no longer be used cannot be recycled, which is a memory leak.
1.3.1 strong, soft, weak, virtual and four references
-
Strong reference
Strong references are the most commonly used references. If an object has a strong reference, the garbage collector will never recycle it.
Object o=new Object(); // Strong reference o=null; // Help the garbage collector recycle this object 12
-
Soft reference
If an object has only soft references, the memory space is enough, and the garbage collector will not recycle it; If the memory space is insufficient, the memory of these objects will be reclaimed. As long as the garbage collector does not recycle it, the object can be used by the program. Soft references can be used to implement memory sensitive caching.
//When we run out of memory, soft will be recycled SoftReference<MyObject> softReference = new SoftReference<>(new Object()); 12
-
Weak reference
For objects with only weak references, as soon as the garbage collection mechanism runs, the memory occupied by the object will be reclaimed regardless of whether the memory space of the JVM is sufficient.
//Once the garbage collection mechanism runs, it will recycle the memory occupied by the object. WeakReference < MyObject > WeakReference = new WeakReference < > (New object()); twelve
-
Phantom reference
As the name suggests, it is virtual. Unlike other references, virtual references do not determine the life cycle of objects. If an object only holds virtual references, it may be recycled by the garbage collector at any time, just as it does not have any references. It cannot be used alone or access objects through it.
The virtual reference must be used in conjunction with the reference queue. When the garbage collector prepares to recycle an object, if it finds that it still has a virtual reference, it will add the virtual reference to the associated reference queue before recycling the memory of the object.
ReferenceQueue<MyObject> referenceQueue = new ReferenceQueue();//It is associated with the reference queue. When the virtual reference object is recycled, it will enter the ReferenceQueue. Phantom reference < MyObject > phantom reference = new phantom reference < > (New myobject(), ReferenceQueue); one hundred and twenty-three
1.3.2 cause analysis
Reason for ThreadLocal memory leak:
The key used in ThreadLocalMap is a weak reference to ThreadLocal, while value is a strong reference.

Therefore, if ThreadLocal is not strongly referenced by the outside, the key will be cleaned up during garbage collection, and the value will not be cleaned up. In this way, an Entry with null key will appear in ThreadLocalMap. If we do not take any measures, value will never be recycled by GC, and memory leakage may occur at this time.
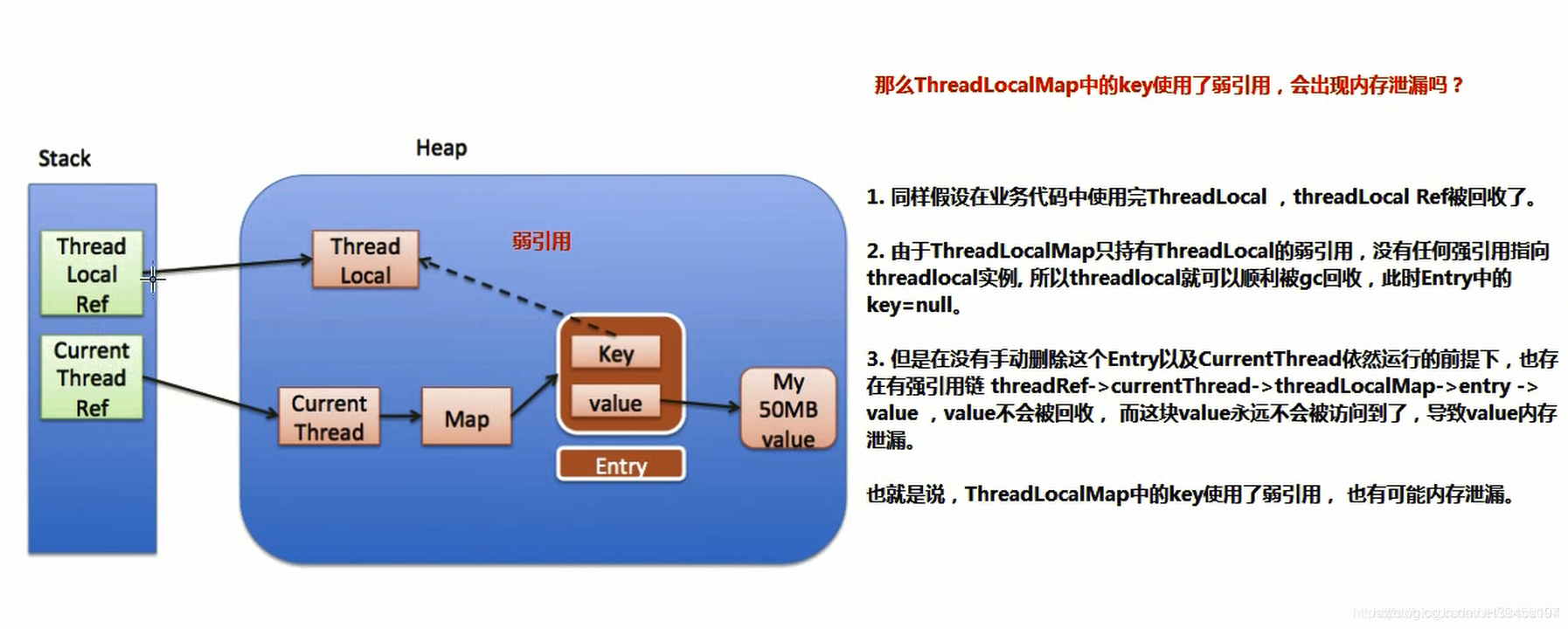
-
Assuming that the key in ThreadLocalMap uses a strong reference, will there be a memory leak?
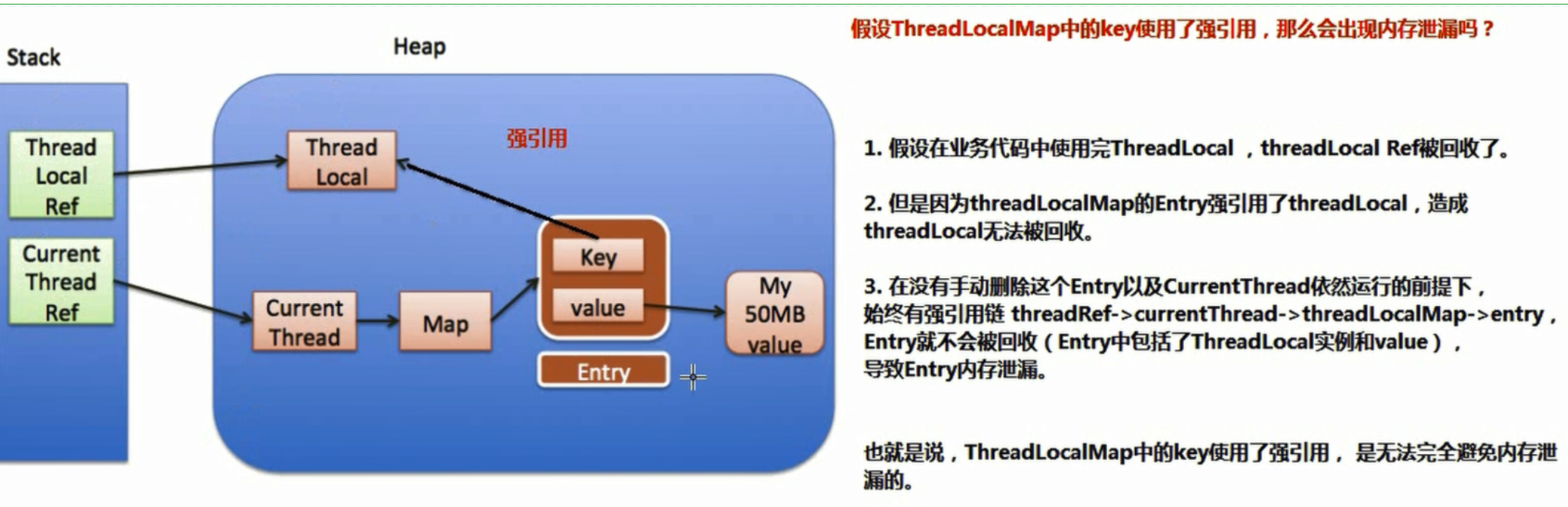
The key in ThreadLocalMap uses strong reference, which can not completely avoid memory leakage
Therefore, the root cause of ThreadLocal memory leak is:
- This Entry is not manually deleted
- CurrentThread the current Thread is still running. Because the life cycle of ThreadLocalMap is as long as that of Thread, if the corresponding key is not manually deleted, it will lead to memory leakage, not weak reference.
So why do key s use weak references?
- In fact, in the set/getEntry method in ThreadLocalMap, it will judge that the key is null (that is, ThreadLocal is null). If it is null, it will set the value to null.
- This means that after using ThreadLocal, the currentthread is still running. Even if you forget to call the remove method, the weak reference can provide one more guarantee than the strong reference: the ThreadLocal of the weak reference will be recycled. The corresponding value will be cleared the next time ThreadLocaIMap calls any method in set/get/remove, so as to avoid memory leakage
2, AQS details
Good blog:
Introduction to Lock and getting to know AQS
AQS(AbstractQueuedSynchronizer) detailed explanation and source code analysis
2.1 AQS introduction
What is AQS?
- AQS, the full name of AbstractQueuedSynchronizer, is located under the java.util.concurrent.locks package.
- It is a framework implementation provided by JDK1.5 for realizing blocking lock and a series of synchronizers that depend on FIFO waiting queue (First Input First Output first in first out). It is a locking mechanism other than the synchronized keyword provided by java. AQS can be understood as a queue.
- Our commonly used ReentrantLock, Semaphore, CountDownLatch, CyclicBarrier and other concurrency classes are implemented based on AQS. The specific usage is to inherit AQS and implement its template method to achieve the management of synchronization status.
The functions of AQS can be divided into two types: exclusive lock and shared lock
- Exclusive lock: only one thread can hold a lock at a time. eg: ReentrantLock is an exclusive lock
- Shared lock: allows multiple threads to obtain locks at the same time and access shared resources concurrently. Eg: readlock and CountDownLatch in reentrantreadwritelock
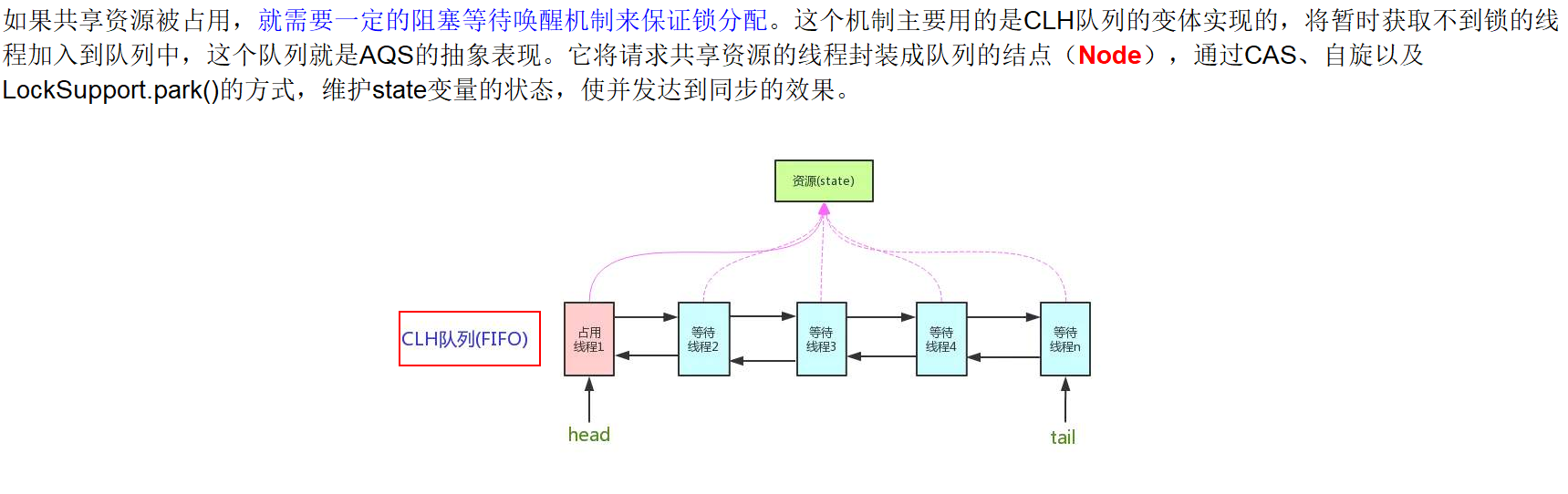
The core idea of AQS is that if the requested shared resource is idle, the thread requesting the resource is set as a valid worker thread, and the shared resource is set to the locked state. If the requested shared resources are occupied, a set of mechanisms for thread blocking and waiting and lock allocation when waking up are required. This mechanism AQS is implemented with CLH queue lock, that is, the thread that cannot obtain the lock temporarily is added to the queue.
AQS design is based on the template method mode, and the general usage is:
1. The user inherits AbstractQueuedSynchronizer and overrides the specified method. (these rewriting methods are very simple, nothing more than the acquisition and release of shared resource state)
2. Combine AQS into the implementation of user-defined synchronization components and call their template methods, which will call the methods rewritten by the user.
Let's take a look at these rewritable methods defined by AQS:
- protected boolean tryAcquire(int arg): get the synchronization status exclusively. If you try to get it, it returns true successfully. Otherwise, it returns false
- protected boolean tryRelease(int arg): exclusively release the synchronization status. Other threads waiting will have the opportunity to obtain the synchronization status at this time;
- protected int tryAcquireShared(int arg): shared acquisition of synchronization status. If the return value is greater than or equal to 0, it means successful acquisition; Otherwise, the acquisition fails;
- Protected Boolean tryrereleaseshared (int ARG): shared release synchronization status. Success is true and failure is false
- Protected Boolean ishldexclusively(): whether it is occupied by threads in exclusive mode.
Template method provided by AQS:
-
Exclusive lock
void acquire(int arg);// Exclusively obtain the synchronization status. If the acquisition fails, insert the synchronization queue to wait; void acquireInterruptibly(int arg);// The same as the acquire method, but the interrupt can be detected when waiting in the synchronization queue; boolean tryAcquireNanos(int arg, long nanosTimeout);// The timeout waiting function is added on the basis of acquire interrupt. If the synchronization status is not obtained within the timeout time, false is returned; boolean release(int arg);// Release the synchronization state, which wakes up the next node in the synchronization queue
-
Shared lock
void acquireShared(int arg);// The difference between shared mode and exclusive mode is that multiple threads obtain synchronization status at the same time; void acquireSharedInterruptibly(int arg);// On the basis of acquireShared method, the function of responding to interrupt is added; boolean tryAcquireSharedNanos(int arg, long nanosTimeout);// The function of timeout waiting is added on the basis of acquire shared interrupt; boolean releaseShared(int arg);// Shared release synchronization status
Usage Summary:
- First, we need to inherit the AbstractQueuedSynchronizer class, and then we need to rewrite the corresponding methods according to our requirements. For example, to implement an exclusive lock, we need to rewrite the tryAcquire and tryRelease methods. To implement a shared lock, we need to rewrite tryacquiresered and tryrereleaseshared;
- Then, the template method in AQS can be invoked in our components, and these template methods will be invoked to those methods that we rewrote before. In other words, we only need a small amount of work to implement our own synchronization components. The rewritten methods are only simple operations to obtain and release the shared resource state. As for operations such as resource acquisition failure and thread blocking, AQS naturally helps us.
2.2 AQS source code analysis
Basic realization of AQS:
-
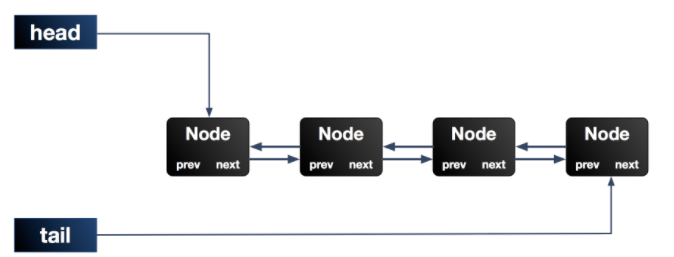
AQS maintains a shared resource state and completes the queuing work of the resource acquisition thread through the built-in FIFO. (this built-in synchronization queue is called "CLH" queue). The queue consists of Node nodes one by one. Each Node maintains a prev reference and a next reference, pointing to its own predecessor and successor nodes respectively. AQS maintains two pointers to the head and tail of the queue respectively.
-
In fact, it is a double ended two-way linked list.
-
When the thread fails to obtain resources (for example, the attempt to set the state state fails when trying to acquire), it will be constructed as a node to join the CLH queue, and the current thread will be blocked in the queue (implemented through LockSupport.park, which is actually in the waiting state). When the thread holding the synchronization state releases the synchronization state, it will wake up the subsequent node, and then the node thread will continue to participate in the contention for the synchronization state.
AQS internal structure code:
static final class Node {} //
private transient volatile Node head;
private transient volatile Node tail;
private volatile int state; // Synchronization status
Node structure:
static final class Node {
// Indicates that the thread has been canceled (wait timeout or interrupted)
static final int CANCELLED = 1;
// Indicates that the thread is ready for resource release
static final int SIGNAL = -1;
// Indicates that the node is in the waiting queue and the node thread is waiting to wake up
static final int CONDITION = -2;
// Indicates that the next shared synchronization state will be propagated unconditionally
static final int PROPAGATE = -3;
// The default value of Node initialization
volatile int waitStatus;
/**Predecessor node of current node */
volatile Node prev;
/** Successor node of current node */
volatile Node next;
/** Threads in the queue associated with the current node */
volatile Thread thread;
/** ...... */
}
Analyze the execution process of AQS with unfair lock in ReentrantLock
-
Analysis code
public class AQSDemo { public static void main(String[] args) { ReentrantLock lock = new ReentrantLock(); new Thread(()-> { lock.lock(); //Thread A acquires the lock try { System.out.println(Thread.currentThread().getName()+"----lock"); Thread.sleep(3000); //Occupied the lock for 3 seconds } catch (InterruptedException e) { e.printStackTrace(); } finally { System.out.println(Thread.currentThread().getName()+"----unlock"); lock.unlock(); } },"ThreadA").start(); new Thread(()-> { lock.lock(); //Thread B scrambles for lock try { System.out.println(Thread.currentThread().getName()+"----lock"); } catch (Exception e) { e.printStackTrace(); } finally { System.out.println(Thread.currentThread().getName()+"----unlock"); lock.unlock(); } },"ThreadB").start(); new Thread(()-> { lock.lock(); //Thread C scrambles for lock try { System.out.println(Thread.currentThread().getName()+"----lock"); } catch (Exception e) { e.printStackTrace(); } finally { System.out.println(Thread.currentThread().getName()+"----unlock"); lock.unlock(); } },"ThreadC").start(); }
}
- Execution results:

------
**lock()function**
```java
//lock method of ReentrantLock
public void lock() {
sync.lock();
}
//lock() function in NonfairSync
final void lock() {
//Use CAS settings to set the value of state to 1, which is also the process of obtaining the lock. Only when state is 0 can it be set successfully. Setting successfully is equivalent to the success of the current thread in obtaining the lock.
// In ReentrantLock, state is used to identify the status of the current lock. state = 0: the lock is not held by another thread. If state > 0, the lock is held by other threads. The number of states represents the number of reentries.
if (compareAndSetState(0, 1))
//After the current thread obtains the lock successfully, set the owner as the current thread
setExclusiveOwnerThread(Thread.currentThread());
else
//If the lock acquisition fails, it indicates that the current lock has been occupied by other threads
acquire(1);
}
Call the acquire() method of AQS to obtain the exclusive lock:
- Call tryAcquire again to acquire the lock.
- If tryAcquire fails to acquire the lock, addWaiter will be called to add the current thread to the waiting queue and return to the current thread node.
- Call acquirequeueueued to suspend the current thread in the queue.
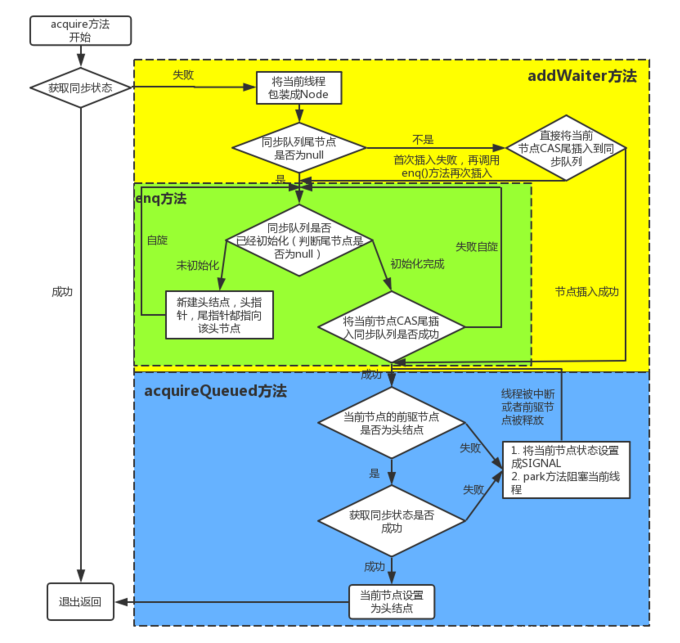
public final void acquire(int arg) {
//Whether the synchronization status is obtained successfully again. If it is successful, the method ends and returns
//If it fails, the addWaiter() method is called first, and then the acquirequeueueueued () method is called
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
-
The tryAcquire() method attempts to acquire the lock
//NonfairSync protected final boolean tryAcquire(int acquires) { return nonfairTryAcquire(acquires); } //Execute the nonfairTryAcquire method of Sync final boolean nonfairTryAcquire(int acquires) { //Get the current thread final Thread current = Thread.currentThread(); //Get the current state int c = getState(); //Only when c == 0, it indicates that the current lock is not occupied, and CAS attempts to replace it. Judge in advance here. In order to improve performance and prevent CAS operation every time if (c == 0) { if (compareAndSetState(0, acquires)) { setExclusiveOwnerThread(current); return true; } } //If it is executed here, it indicates that the current lock has been occupied //Judge whether the thread occupying the lock is the current thread. If so, it is reentrant else if (current == getExclusiveOwnerThread()) { int nextc = c + acquires; if (nextc < 0) // overflow throw new Error("Maximum lock count exceeded"); setState(nextc); return true; } return false; } -
When a thread fails to acquire an exclusive lock, it will add the current thread to the synchronization queue and suspend the node
-
addWaiter() method to add the current thread to the synchronization queue
private Node addWaiter(Node mode) { //Create a new Node with the current thread Node node = new Node(Thread.currentThread(), mode); // Try the fast path of enq; backup to full enq on failure Node pred = tail; //Here, it is judged that tail is not equal to null. Indicates that there are already waiting threads in the queue. Directly try to append the current thread to the end of the queue if (pred != null) { //Inserts the current node tail into the synchronization queue node.prev = pred; if (compareAndSetTail(pred, node)) { pred.next = node; return node; } } //The tail node of the current synchronization queue is null, indicating that the current thread is the first thread to join the synchronization queue and wait enq(node); return node; }enq() method, which processes the queue entry operation when the tail node of the current synchronization queue is null, that is, the first thread to join the synchronization queue and wait
private Node enq(final Node node) { //This is an endless loop, which is used because when the current thread is added to the queue, //CAS may fail due to the success of other ready-made early join. At this time, it will continue to cycle and try to join again until the join is successful. for (;;) { Node t = tail; //Here, we first judge that if there is no waiting thread in the queue, we will directly initialize a Node //And point both head and tail to the initialized node. Then execute a second loop to add the current thread to the queue. if (t == null) { // Must initialize if (compareAndSetHead(new Node())) tail = head; } else { //Otherwise, try to add the current ready-made to the queue through CAS. If the join fails, continue to cycle and try to join until it returns successfully. node.prev = t; if (compareAndSetTail(t, node)) { t.next = node; return t; } } } } -
Execute the acquirequeueueueued() method to suspend the node thread
//Executing this method indicates that the current thread has been added to the waiting queue. //All this method has to do is suspend the current thread. final boolean acquireQueued(final Node node, int arg) { boolean failed = true; try { boolean interrupted = false; //This is an endless loop. Only the thread that has obtained the lock can exit. //After the suspended thread is awakened, it will preempt the lock again. If the preemption fails, it will continue to be suspended. In the unfair lock, the new thread can preempt the lock resources. //Suspended threads may be awakened by interrupts. After the interrupt wakes up, the lock cannot be acquired. So it will be suspended again. for (;;) { //Gets the previous node of the current thread node final Node p = node.predecessor(); //Here, p == head. In order to ensure that the wake-up sequence of thread nodes from the queue must be released from front to back in sequence if (p == head && tryAcquire(arg)) { //So far, there are two situations: //1. The attempt to acquire the lock before suspending succeeded. //2. After the lock is released and the thread wakes up from the queue, the thread acquires the lock successfully. //If the current thread acquires a lock, the current thread node is removed from the queue. setHead(node); p.next = null; // help GC failed = false; return interrupted; } //Here you can start to suspend the current thread. First judge whether the thread can be suspended through shouldParkAfterFailedAcquire, and then suspend the current thread through parkAndCheckInterrupt if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt()) //The returned value of parkAndCheckInterrupt is whether to interrupt the wake-up. If so, the interrupted value is assigned to true. When the current thread obtains the lock, it needs to return interrupted and process the interrupt again interrupted = true; } } finally { if (failed) cancelAcquire(node); } } }The shouldParkAfterFailedAcquire method is used to set the precursor node to the SIGNAL state and wake up the user later
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) { //Get the status of the previous node of the current node, and judge whether to suspend the current thread through the waitStatus of the previous node int ws = pred.waitStatus; //If the previous node's waitstatus = = global, it is suspended if (ws == Node.SIGNAL) return true; if (ws > 0) { do { node.prev = pred = pred.prev; } while (pred.waitStatus > 0); pred.next = node; } else { // Set the precursor node of the current node to the SIGNAL state, and the user will wake up later // The first time the program executes, it returns false. It also performs a second loop, and finally returns true from line 6 compareAndSetWaitStatus(pred, ws, Node.SIGNAL); } return false; }If shouldParkAfterFailedAcquire returns true, the waitstatus of the previous node is already SIGNAL. At this point, execute parkAndCheckInterrupt to suspend the current thread
private final boolean parkAndCheckInterrupt() { //Suspend the current thread LockSupport.park(this); //After suspending, the thread can be woken up because of an interrupt. Therefore, after waking up, it can directly judge whether it is an interrupt wake-up. interrupted returns the interrupt state and resets the interrupt flag of the thread. return Thread.interrupted(); }
-
After ThreadA, ThreadB and ThreadC execute the lock method, the queue is:
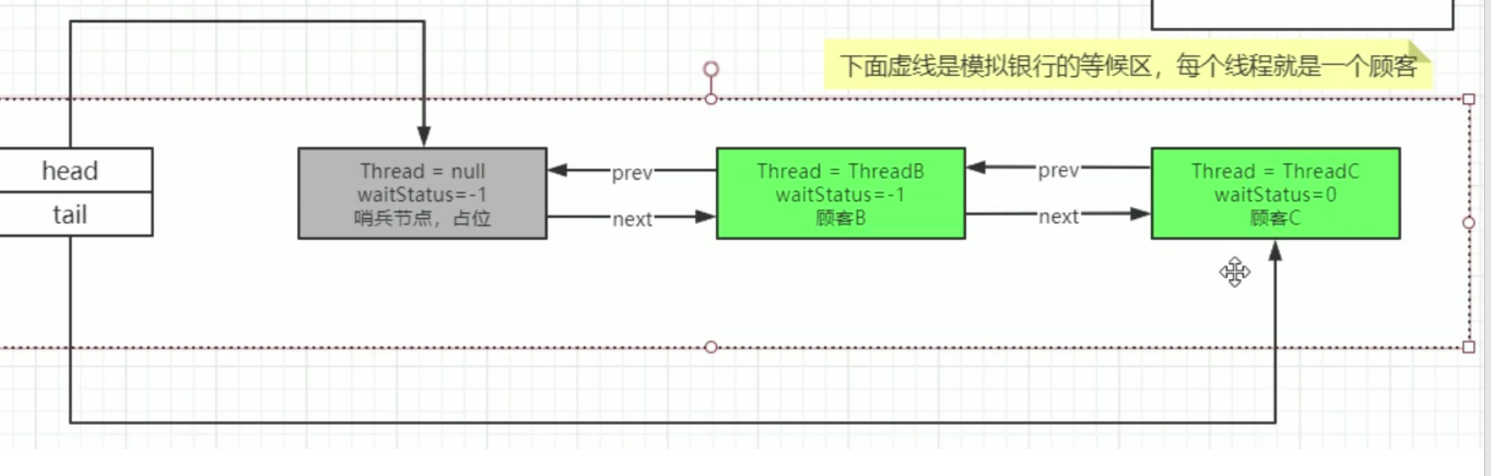
Summary:
- First, tryAcquire obtains the synchronization status. If it is successful, it will be returned directly; Otherwise, enter the next link;
- If the thread fails to obtain the synchronization status, it constructs a node and adds it to the synchronization queue. This process should ensure thread safety;
- The node thread added to the queue enters the spin state. If the second node (i.e. the precursor node is the head node), it has the opportunity to try to obtain the synchronization state; Otherwise, when the state of its precursor node is SIGNAL, the thread enters the blocking state until it is interrupted or awakened by the precursor node.
unlock() function
// Unlock() method public void unlock() {sync. Release (1);} / / release() method public final boolean release(int arg) {/ / release the lock, that is, subtract the state until state == 0, indicating that the release is successful. if (tryRelease(arg)) {/ / when the thread is suspended, it is judged whether the previous node is SIGNAL == -1. / / if it is 0, it will be changed to SIGNAL. When the thread is awakened, it will be modified to 0 if (h != null && h.waitStatus != 0) unparkSuccessor(h); return true; } return false;}12345678910111213141516171819
tryRelease() method, release of exclusive lock
//This method is very simple, that is, subtract releases from the state value of state and re assign the value// When the final state == 0 returns true, the identification lock is released successfully. If it is a re-entry lock, it needs to be released multiple times. Protected final Boolean tryrelease (int releases) {int c = getstate() - releases; if (thread. Currentthread()! = getexclusiveownerthread()) throw new illegalmonitorstateexception(); Boolean free = false; if (C = = 0) {free = true; setexclusiveownerthread (null);} setstate (c); / / set state to 0 return free;} 1234567891011121314
The unparksuccess() method wakes up the thread of the queue. The unparksuccess() method will be executed only when the head node pointed to by the head is not null and the status value of the node is not 0
private void unparkSuccessor(Node node) { // If the waitstatus of the head node is < 0, it is assigned 0 int WS = node.waitstatus; if (ws < 0) compareAndSetWaitStatus(node, ws, 0); // The successor node of the head node s = node.next; If (s = = null | s.waitstatus > 0) {s = null; for (node T = tail; t! = null & & T! = node; t = t.prev) if (t.waitstatus < = 0) s = t;} if (s! = null) / / wake up the thread LockSupport.unpark(s.thread);}12345678910111213141516171819
-
After ThreadB releases the lock, ThreadB obtains the queue status after the lock:
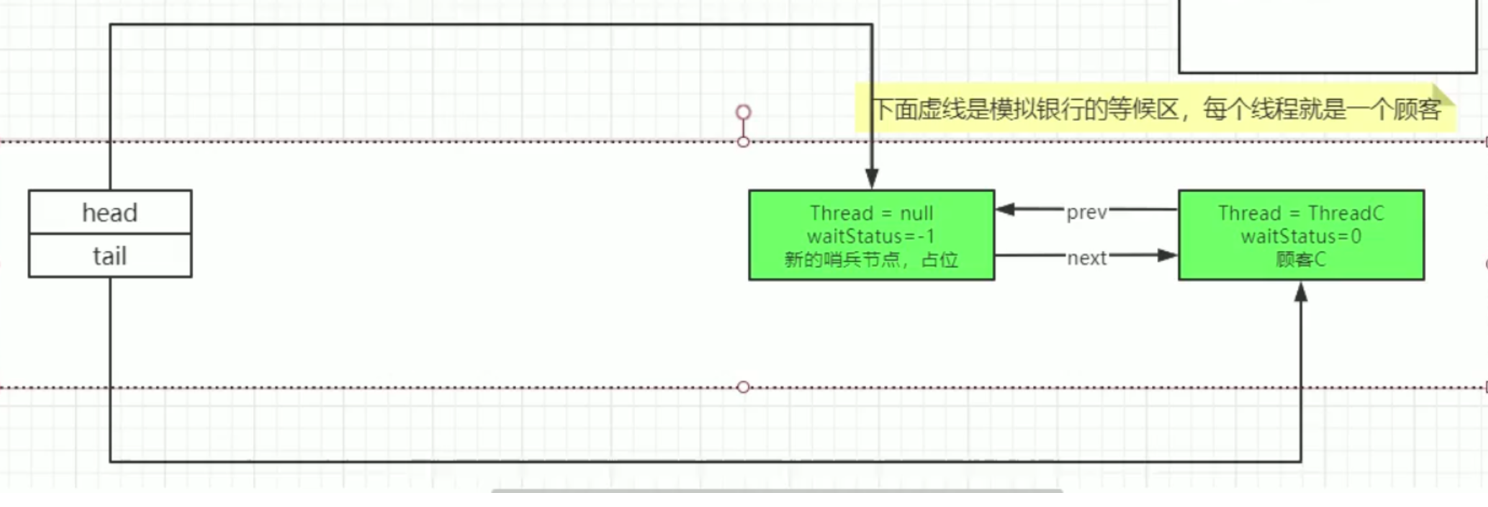
-
When the lock is released, the head node and subsequent nodes will wake up. However, because it is an unfair lock, if a new thread competes for the lock, it may also obtain the lock.
-
If a node in the queue acquires a lock, the previous sentinel node will be removed from the queue, and the node will act as a sentinel node.
Process summary:
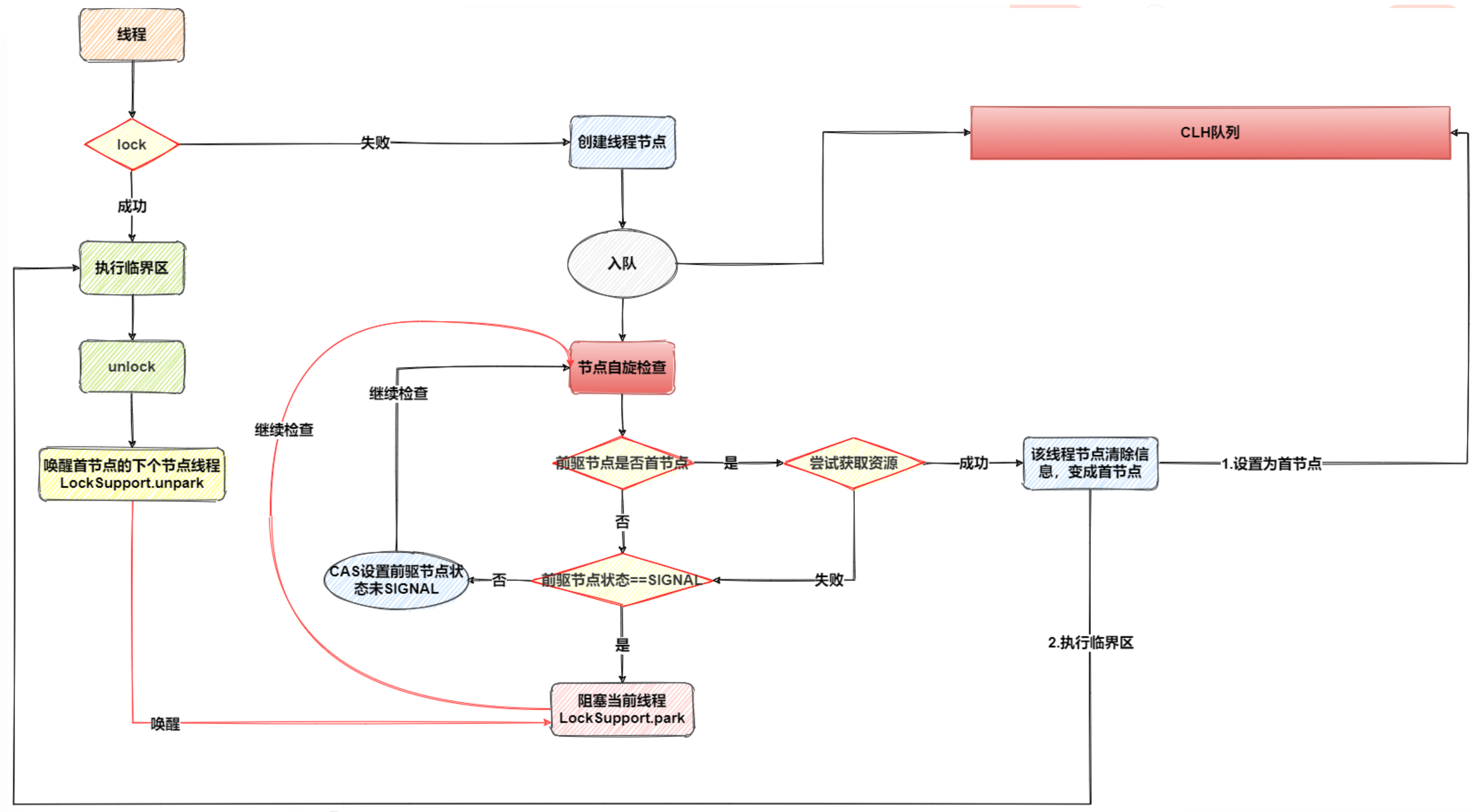
2.3 ReentrantLock
Features of ReentrantLock
- Reentrant: if the same thread obtains the lock for the first time, it has the right to obtain the lock again because it is the owner of the lock
- Interruptible: use lockinterruptible() to lock
- Support fair lock
- Multiple conditional variables are supported
- Obtaining a lock that can be timed out: try to obtain a lock within a period of time through tryLock(long timeout, TimeUnit unit)
Use of ReentrantLock
public void test(){ private Lock lock = new ReentrantLock(); lock.lock(); // Lock operation try {dosomething();} catch (exception E) {/ / ignored} finally {lock. Unlock(); / / the lock must be released in finally}} 1234567891011
Internal structure of ReentrantLock:
- The underlying layer of ReentrantLock is implemented based on AbstractQueuedSynchronizer (AQS has been mentioned above).
- ReentrantLock implements the Lock interface. A special component sync is defined internally. Sync inherits AbstractQueuedSynchronizer and provides the implementation of releasing resources. NonfairSync and FairSync are subclasses based on sync extension, that is, the unfair mode and fair mode of ReentrantLock
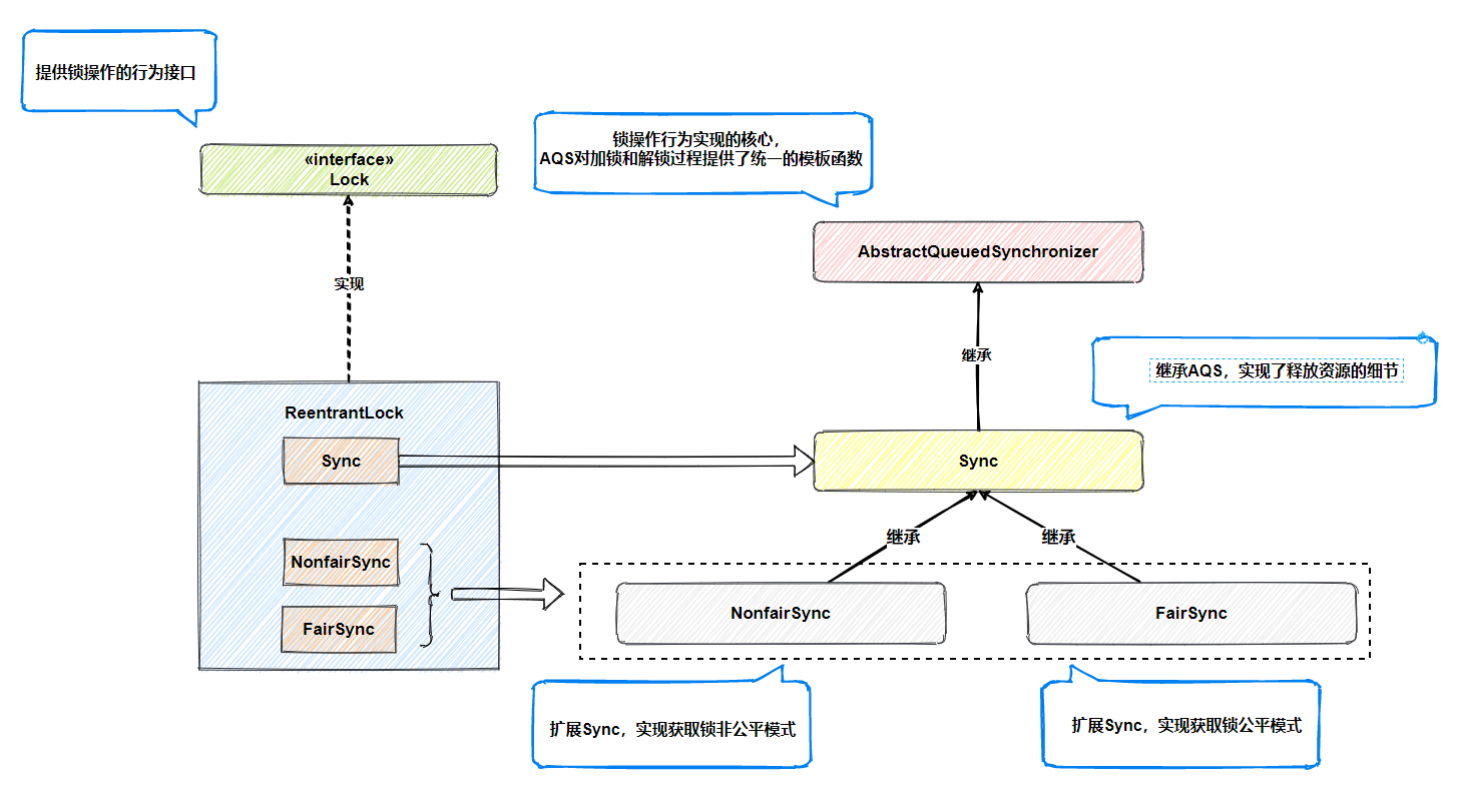
Common methods of ReentrantLock:
// Get the lock void lock()// Acquire lock response interrupt void lockInterruptibly() throws InterruptedException// Returns whether the lock acquisition was successful or not. boolean tryLock()// Returns whether the lock acquisition is successful or not. The lock acquisition can be timed out - response interrupt boolean tryLock(long time, TimeUnit unit) throws InterruptedException// Release the lock void unlock()// Create condition variable newcondition(); 1234567891011121314151617
Fair lock and fair lock:
-
NonfairSync is used at the bottom layer of non fair lock, and FairSync is called at the bottom layer of fair lock
-
The processes of the two are basically the same. The only difference is that the hasQueuedPredecessors function is used to judge before C A S is executed
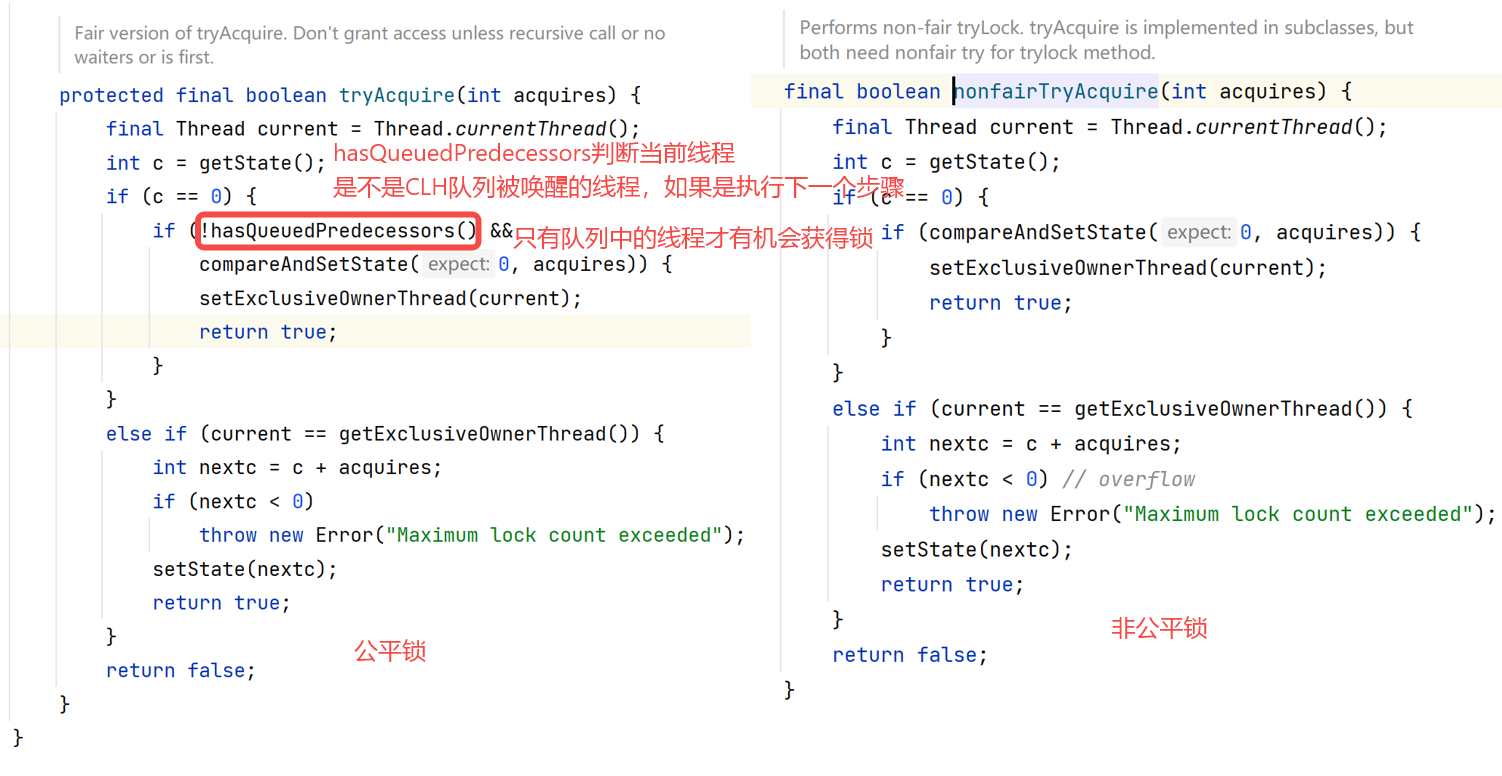
Condition variable:
-
The condition class can realize the functions of synchronized, wait and notify. In addition, it is more flexible than the latter. Condition can realize the multi-channel notification function, that is, multiple condition (i.e. object monitor) instances can be created in a Lock object, and the thread object can be registered in the specified condition, so that thread notification can be selected, More flexible in scheduling threads.
-
API introduction:
// Causes the current thread to wait until it receives a signal or is interrupted. void await() / / causes the current thread to wait until it receives a signal, is interrupted, or reaches the specified waiting time. Boolean await (long time, timeunit) / / causes the current thread to wait until it receives a signal, is interrupted, or reaches the specified waiting time. long awaitNanos(long nanosTimeout) / / causes the current thread to wait until it receives the signal. Void awaituninterruptible() / / causes the current thread to wait until it receives a signal, is interrupted, or reaches the specified deadline. boolean awaitUntil(Date deadline) / / wake up a waiting thread. void signal() / / wake up all waiting threads. void signalAll()1234567891011121314151617181920
-
Code example:
@Slf4j(topic = "c.TestCondition")public class Test01 { static ReentrantLock lock = new ReentrantLock(); static Condition waitCigaretteQueue = lock.newCondition(); static Condition waitBreakFastQueue = lock.newCondition(); static volatile boolean hasCigarette = false; static volatile boolean hasBreakfast = false; public static void main(String[] args) { new Thread(() -> { try { lock.lock(); while (!hasCigarette) { try { waitCigaretteQueue.await(); } catch (InterruptedException e) { e.printStackTrace(); } } log.debug("Wait until its smoke"); } finally { lock.unlock(); } }).start(); new Thread(() -> { try { lock.lock(); while (!hasBreakfast) { try { waitBreakFastQueue.await(); } catch (InterruptedException e) { e.printStackTrace(); } } log.debug("Wait until it's breakfast"); } finally { lock.unlock(); } }).start(); sleep(1); sendBreakfast(); sleep(1); sendCigarette(); } private static void sendCigarette() { lock.lock(); try { log.debug("Here comes the cigarette"); hasCigarette = true; waitCigaretteQueue.signal(); } finally { lock.unlock(); } } private static void sendBreakfast() { lock.lock(); try { log.debug("Breakfast is coming"); hasBreakfast = true; waitBreakFastQueue.signal(); } finally { lock.unlock(); } }}123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869Execution result: the Condition is used to wake up the thread with the specified Condition

What is the difference between Synchronized and ReentrantLock?
| category | synchronized | ReentrantLock |
|---|---|---|
| Underlying implementation | The implementation of synchronized involves lock upgrading, including no lock, bias lock, spin lock, and applying for heavyweight lock from the OS. It is a JVM level lock and a Java keyword, which is completed through the monitor object (monitorenter and monitorexit). | ReentrantLock is a class. The bottom layer is based on AQS and implemented through CAS+CLH queue |
| Lock release | Synchronized does not require the user to manually release the lock. After the synchronized code is executed, the system will automatically let the thread release the occupation of the lock | ReentrantLock requires the user to release the lock manually. If the lock is not released manually, it may lead to deadlock. It is generally completed through the lock() and unlock() methods combined with the try/finally statement block |
| Is it interruptible | synchronized is a non interruptible type of lock, unless an exception occurs in the locked code or normal execution is completed | ReentrantLock can be interrupted, set the timeout method through trylock(long timeout,TimeUnit unit) or place lockInterruptibly() in the code block, calling interrupt method to interrupt. |
| Fair lock | synchronized is a non fair lock | ReentrantLock can select either fair lock or non fair lock. If it is empty, the default value is false, which is a non fair lock. If it is true, it is a fair lock |
| Lock type | Reentrant non interruptible non fair non interruptible, unless an exception is thrown or normal operation is completed. | Reentrant, interruptible and fair (both) can be interrupted through lock. Lockinterruptible() |
| Thread scheduling | synchronized wakes up one thread or all threads randomly through the wait()/notify()/notifyAll() method of the Object class | ReentrantLock realizes the precise wake-up of threads by binding Condition and await()/singal() |
2.4 ReentrantReadWriteLock read / write lock
- Read / write lock means that a resource can be accessed by multiple read threads or by one write thread, but there cannot be read / write threads at the same time
- There are two static internal classes in ReentrantReadWriteLock: ReadLock read Lock and WriteLock write Lock. These two locks implement the Lock interface. Reentrant readwritelock supports reentry. The synchronization function depends on a user-defined synchronizer (AbstractQueuedSynchronizer), and the read-write state is the synchronization state of its synchronizer
Acquisition and release of write lock:
- Write lockwritelock is an exclusive lock that supports re-entry. If the current thread has acquired a write lock, the write state is increased. If the read lock has been acquired when the current thread acquires the read lock, or the thread is not a thread that has acquired the write lock, the current thread enters the waiting state. Read / write lock ensures that the operation of the write lock is visible to the read lock. Write lock release reduces the write state each time. When the current write state is 0, it indicates that the write lock has been released.
Acquisition and release of read lock:
- Read lock ReadLock is a shared lock that supports re-entry (the shared lock is a shared node. The shared node will wake up a series of times until it encounters a read node). It can be obtained by multiple threads at the same time. When no other write thread accesses it (the write state is 0), the read lock can always be obtained successfully, and all it does is to increase the read state (thread safety). If the current thread has acquired a read lock, the read state is increased. If the write lock has been acquired when the current thread acquires the read lock, it enters the waiting state.
Lock degradation:
-
Lock demotion means that a write lock is demoted to a read lock. Lock demotion refers to the process of acquiring a read lock and then releasing a write lock at the same time as the currently owned write lock
-
Official website lock degradation cases:
class CachedData { Object data; // Whether it is valid. If it fails, recalculate the data volatile Boolean cachevalid; final ReentrantReadWriteLock rwl = new ReentrantReadWriteLock(); Void processcacheddata() {RWL. Readlock(). Lock(); if (! Cachevalid) {/ / the read lock must be released before obtaining the write lock. RWL. Readlock(). Unlock(); RWL. Writelock(). Lock(); try {/ / judge whether other threads have obtained the write lock and updated the cache to avoid repeated updating if (! Cachevalid) {data =... Cachevalid = true;} / / demote to read lock and release write lock, so that other threads can read the cache RWL. Readlock(). Lock();} finally {RWL. Writelock(). Unlock();}} //When you run out of data, release the read lock try {use (data);} finally {RWL. Readlock(). Unlock();}}} 123456789101112131416171819202122232425262728293031
Read / write lock code example:
@Slf4j(topic = "c.TestReadWriteLock")public class TestReadWriteLock { public static void main(String[] args) throws InterruptedException { DataContainer dataContainer = new DataContainer(); new Thread(() -> { dataContainer.write(); }, "t1").start(); new Thread(() -> { dataContainer.read(); }, "t2").start(); new Thread(() -> { dataContainer.read(); }, "t3").start(); }}@Slf4j(topic = "c.DataContainer")class DataContainer { private Object data; private ReentrantReadWriteLock rw = new ReentrantReadWriteLock(); private ReentrantReadWriteLock.ReadLock r = rw.readLock(); private ReentrantReadWriteLock.WriteLock w = rw.writeLock(); public Object read() { r.lock(); log.debug("Acquire read lock..."); try { log.debug("read"); sleep(1); return data; } finally { log.debug("Release read lock..."); r.unlock(); } } public void write() { w.lock(); log.debug("Get write lock..."); try { log.debug("write in"); sleep(1); } finally { log.debug("Release write lock..."); w.unlock(); } }}123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354
Execution results:
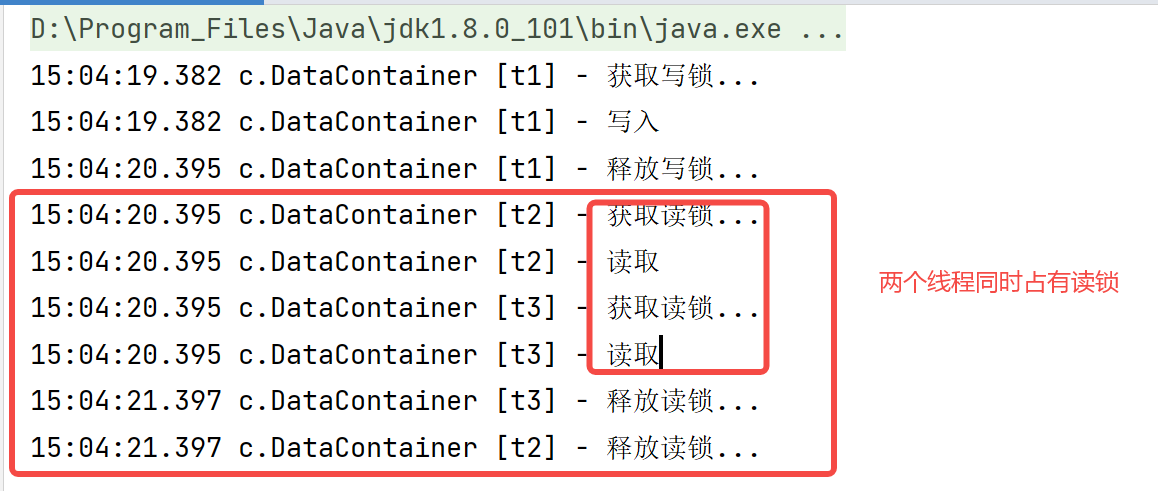
After JDK 8, StampedLock (postmark lock) is added. StampedLock supports the tryOptimisticRead() method (optimistic read) , a stamp verification is required after reading. If the verification passes, it indicates that there is no write operation during this period, and the data can be used safely. If the verification fails, the read lock needs to be obtained again to ensure data security. After StampedLock obtains the lock optimistically, other threads will not be blocked when trying to obtain the write lock (which can solve the problem of read-write lock and lock starvation)
2.5 Semaphore
-
Semaphore, also known as "semaphore", is also a very useful tool class. It is equivalent to a concurrency controller, which limits the number of threads that can access a resource or resource pool at the same time. Semaphore internally maintains a set of virtual licenses, and the number of licenses can be specified through the parameters of the constructor. Before accessing a specific resource, you must use acquire() Method to obtain a license. If the number of licenses is 0, the thread will block until a license is available. After accessing the resource, use the release() method to release the license.
-
Semaphore (int permissions, Boolean Fair) provides two parameters. Permissions represents the length of the resource pool; fair represents fair or unfair permissions.
-
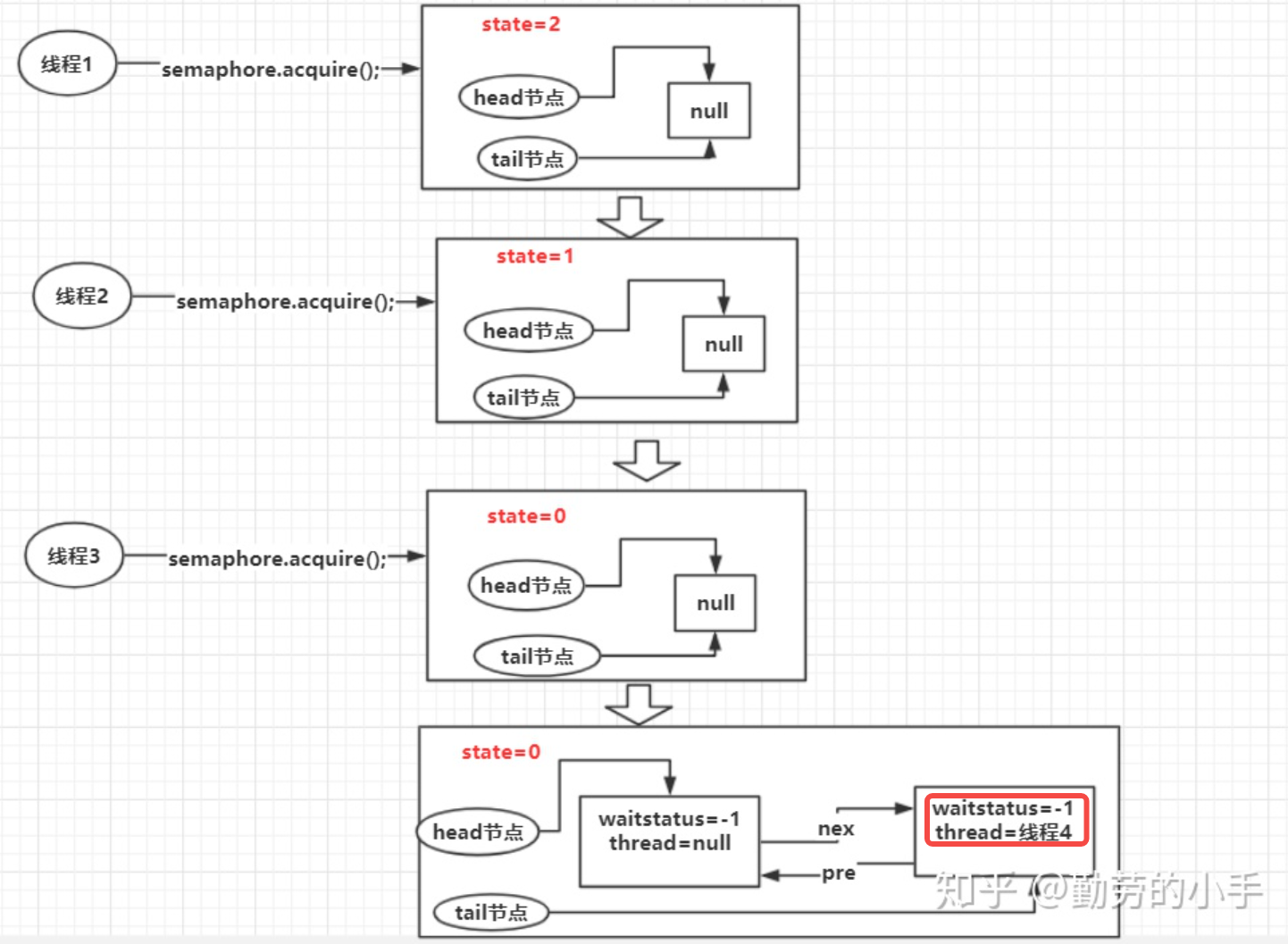
Schematic diagram: thread 1, thread 2, thread 3 and thread 4 respectively call semaphore.acquire() so that the variable is 3. The change of queue information in the whole process is as follows:
Code example:
-
Scenario: a fixed length resource pool. When the pool is empty, the request for resources will fail. You can use * * Semaphore * * to block the request when the pool is empty and unblock it when it is not empty. You can also use * * Semaphore * * to turn any kind of container into a bounded blocking container
public class SemaphoreDemo { public static void main(String[] args) { // Create an unbounded process pool ExecutorService exec = Executors.newCachedThreadPool(); / / configure that only 5 threads can access final semaphore semaphore semaphore = new semaphore (3); / / simulate 10 client access for (int i = 0; I < 5; I + +) {int num = I; runnable task = (() - > {try {/ / get the license semaphore. Acquire(); System.out.println("get the license:" + num); / / sleep random seconds (indicating the operation is in progress) TimeUnit.SECONDS.sleep((int)(Math.random()*10+1)) ; / / release the license after accessing semaphore. Release(); / / availablepermissions() refers to the number of licenses left. System.out.println("---------- how many licenses are left at present:" + semaphore. Availablepermissions());} catch (interruptedexception E) {e.printstacktrace();}}; exec.execute (task);} / / exit thread pool exec. Shutdown();}} 123456789101112131416171819202122232425262728293031 -
Execution results:

2.6 CountdownLatch
-
CountDownLatch is a synchronization tool class that allows one or more threads to wait until other threads finish executing.
-
Description of common methods:
CountDownLatch(int count); //Construct a method to create a counter with a value of count. await(); / / block the current thread and add the current thread to the blocking queue. Await (long timeout, timeunit); / / block the current thread within the timeout time. Once the time passes, the current thread can execute. countDown() 1234 / / decrement the counter by 1. When the counter decrements to 0, the current thread will wake up all threads in the blocking queue.1234
Code example:
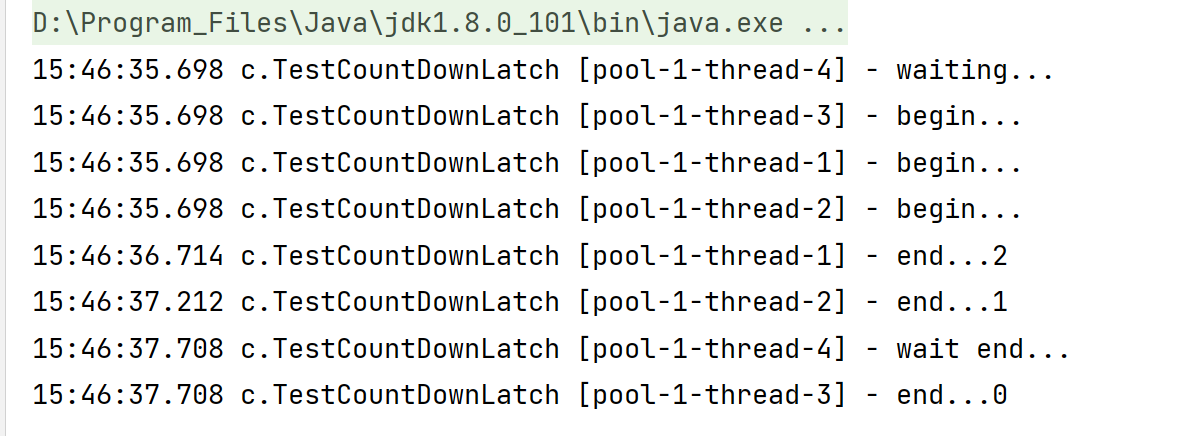
@Slf4j(topic = "c.TestCountDownLatch")public class TestCountDownLatch { public static void main(String[] args) { CountDownLatch latch = new CountDownLatch(3); ExecutorService service = Executors.newFixedThreadPool(4); service.submit(() -> { log.debug("begin..."); sleep(1); latch.countDown(); //At the end of thread T1 execution, decrement the counter by 1 log. Debug ("end... {}", latch. Getcount());}, "t1"); Service. Submit (() - > {log. Debug ("begin..."); sleep (1.5); latch. Countdown(); / / T2 after thread execution ends, decrement the counter by 1 log. Debug ("end... {}", latch. Getcount());}, "T2"); Service. Submit (() - > {log. Debug ("begin..."); sleep (2); latch. Countdown(); / / T3 after thread execution ends, decrement the counter by 1 log. Debug ("end... {}", latch. Getcount());}, "T3"); Service. Submit (() - > {try {log. Debug ("waiting..."); latch. Await(); / / T4 thread waits for the other three threads to finish executing log. Debug ("wait end...");} catch (interruptedexception E) {e.printstacktrace();}}, "T4");}} 123456789101112131415161718192021222324252627282930313233343536373839
Execution results:
- Compared with join, join belongs to the underlying API and is relatively cumbersome to use. Moreover, for methods using thread pool, you can't use join to wait for the thread to end.
- For operations waiting for the thread to finish executing, CountdownLatch can be used when the return value is not required, and Future can be used when the return value is required
2.7 CyclicBarrier
- CyclicBarrier is also called synchronization barrier. CyclicBarrier can cooperate with multiple threads to make multiple threads wait in front of the barrier until all threads reach the barrier, and then continue to perform the following actions together. When constructing, set the count number. When each thread executes to a time when synchronization is required, call the await() method to wait. The number of waiting + 1. When the number of waiting threads meets the count number, continue to execute
Code example: two threads execute simultaneously and loop three times
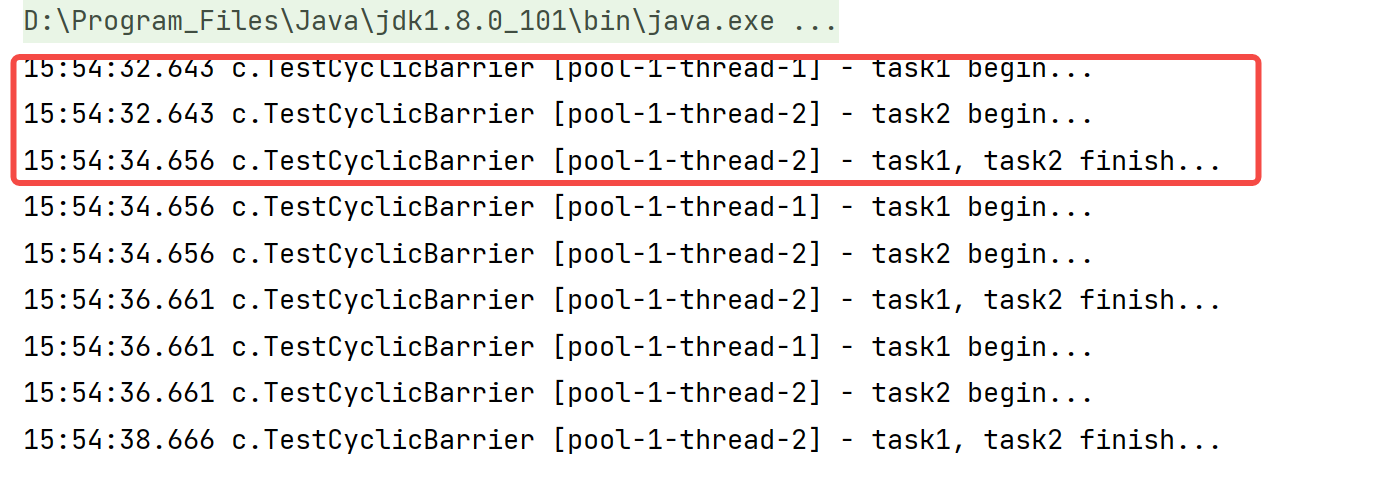
@Slf4j(topic = "c.TestCyclicBarrier")public class TestCyclicBarrier { public static void main(String[] args) { ExecutorService service = Executors.newFixedThreadPool(2); // Note: the expected effect can be achieved only when the number of threads is the same as the count of CyclicBarrier. CyclicBarrier = new CyclicBarrier (2, () - > {log. Debug ("Task1, task2 finish...);})// It can be used repeatedly. When the count becomes 0, it will be restored to 2 for (int i = 0; I < 3; I + +) {/ / Task1 task2 Task1 service. Submit (() - > {log. Debug ("Task1 begin..."); sleep (1); try {barrier. Await(); / / 2-1 = 1} catch (InterruptedException | BrokenBarrierException e) { e.printStackTrace(); } }); service.submit(() -> { log.debug("task2 begin..."); sleep(2); try { barrier.await(); // 1-1=0 } catch (InterruptedException | BrokenBarrierException e) { e.printStackTrace(); } }); } service.shutdown(); } }123456789101112131415161718192021222324252627282930313233343536
Execution results:
What is the difference between CyclicBarrier and CountDownLatch?
- CountDownLatch: one or more threads that wait for other threads to complete something before executing;
- CyclicBarrier: multiple threads wait for each other until they reach the same synchronization point, and then continue to execute together. It can be reused
CountDownLatch is a counter. Threads complete one record after another, but the count is not increasing but decreasing. The CyclicBarrier is more like a valve. It needs all threads to arrive before the valve can be opened and then continue to execute.
3, Thread safe collection class
Legacy thread safe collection:
- Vector
Like ArrayList, Vector is an array with variable length. Unlike ArrayList, Vector is thread safe. It adds the synchronized keyword to almost all public methods. Due to the performance degradation caused by locking, this mandatory synchronization mechanism is redundant when the same object does not need to be accessed concurrently, so now Vector has been abandoned - HashTable
HashTable is similar to HashMap. The difference is that HashTable is thread safe. It adds the synchronized keyword to almost all public methods. Another difference is that K and V of HashTable cannot be null, but HashMap can. It is now abandoned for performance reasons
Collections packaging method:
-
The Collections class provides multiple synchronizedXxx() methods, which can wrap the specified collection into a thread synchronized collection, so as to solve the thread safety problem when multiple threads access the collection concurrently
List<E> synArrayList = Collections.synchronizedList(new ArrayList<E>());Set<E> synHashSet = Collections.synchronizedSet(new HashSet<E>());Map<K,V> synHashMap = Collections.synchronizedMap(new HashMap<K,V>());...1234567
-
Internally, it uses the decoration mode to generate a specific synchronized Collection according to the incoming Collection. Each synchronization operation of the generated Collection holds the mutex lock, so it is a thread safe Collection when operating again.
Collections in the java.util.concurrent package
3.1 ConcurrentHashMap
3.1.1 JDK 7 analysis
Source code analysis
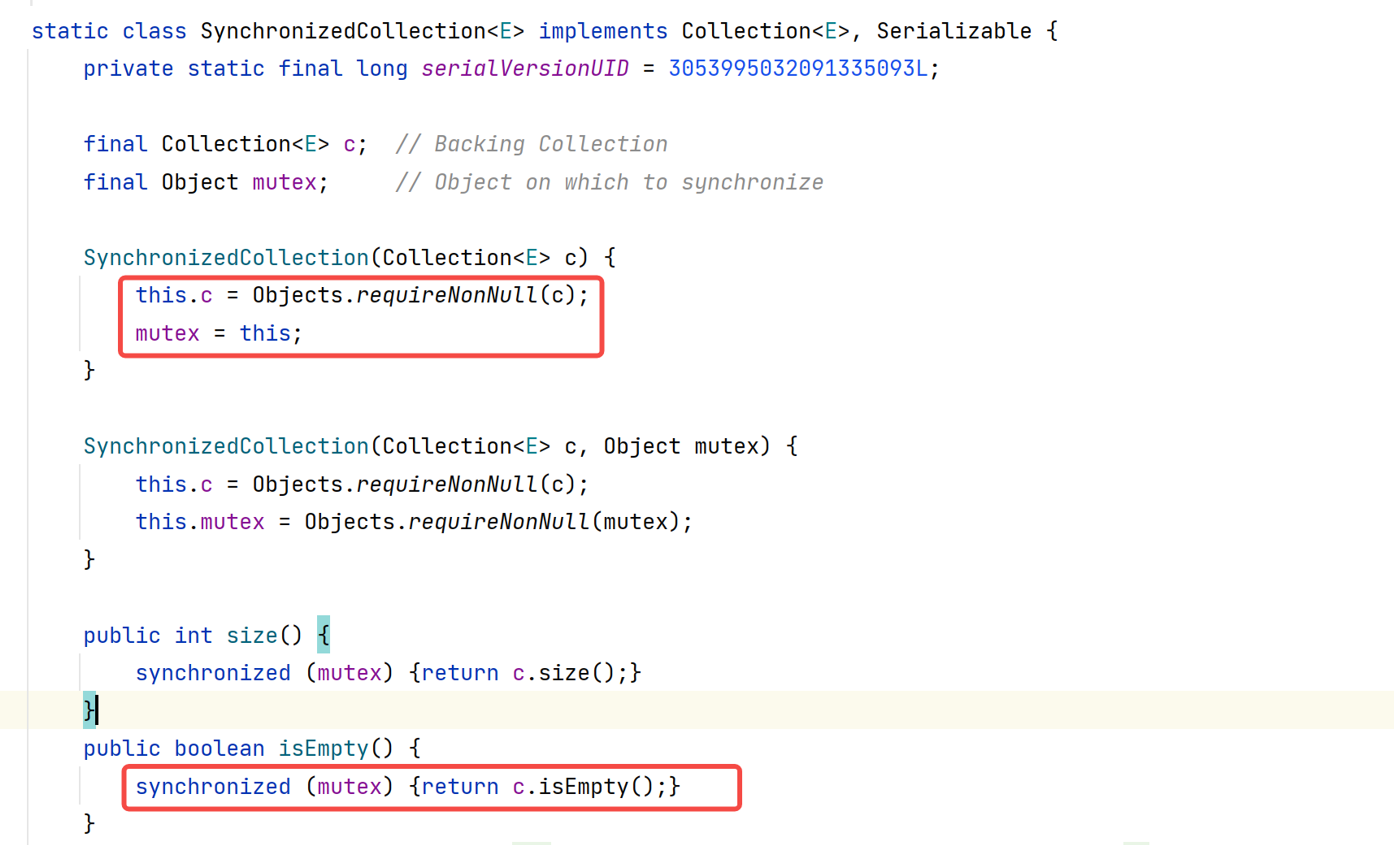
In JDK1.7, the data structure of ConcurrentHashMap consists of a Segment array and multiple hashentries, as shown in the following figure:
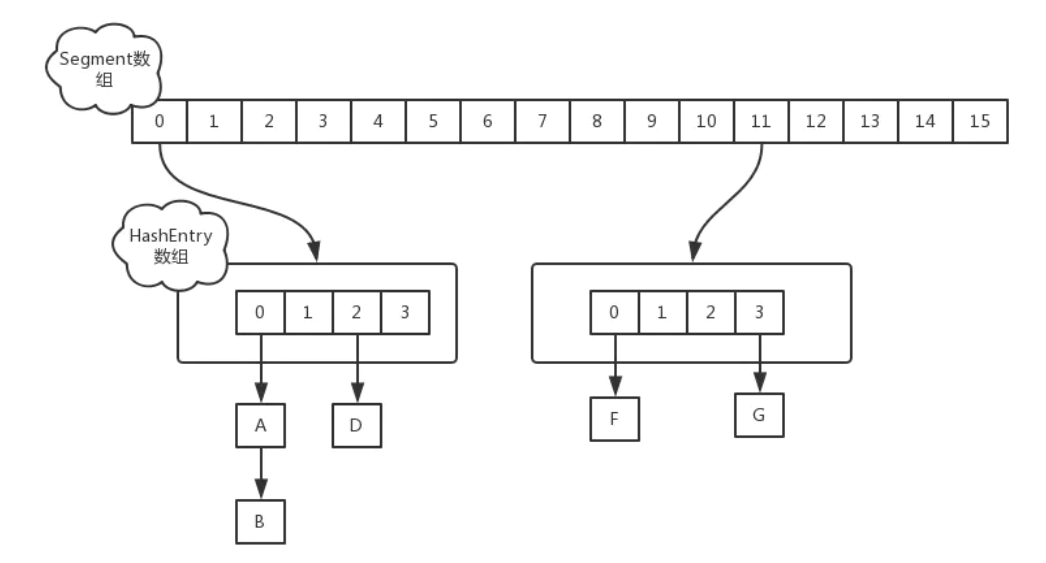
-
Underlying data structure of ConcurrentHashMap:
-
There is a final modified Segment array in ConcurrentHashMap
final Segment<K,V>[] segments; //The default size of the Segments array is 16. This capacity cannot be changed after initialization (equivalent to concurrency) 1
-
Data structure of Segment:
static final class Segment<K,V> extends ReentrantLock implements Serializable { transient volatile HashEntry<K,V>[] table; //The number of elements in the storage structure transient int count; //Segment transient int modcount; transient int threshold; / / if the number of elements in the Segment exceeds this value, the Segment will be expanded. final float loadFactor; / / load factor is used to determine the threshold}1234567 -
**HashEntry structure: * * the elements in the Segment are stored in the linked list array in the form of HashEntry
static final class HashEntry<K,V> { final int hash; final K key; volatile V value; volatile HashEntry<K,V> next;}123456
-
-
put process
-
Steps of put operation:
- First, calculate the hash value of the key
- Secondly, find the array position of the Segment to be operated according to the hash value
- If the Segment is empty, call the ensuesegment () method; otherwise, directly call the put method of the queried Segment to insert the value
public V put(K key, V value) { Segment<K,V> s; // concurrentHashMap does not allow null key/value if (value = = null) throw new nullpointerexception(); int hash = hash(key); // Calculate the segment subscript int j = (hash > > > segmentshift) & segmentmask// Obtain the segment object and judge whether it is null. If yes, create the segment if ((s = (segment < K, V >) unsafe.getobject (segments, (J < < sshift) + SBASE)) = = null) {/ / you can't determine whether the segment is really null at this time, because other threads also find that the segment is null, / / so use cas in ensuesegment to ensure the security of the segment s = ensuesegment (J);} / / enter the put process of segment return s.put (key, hash, value, false);} 1234567891011121341516171819 -
Call the put method of Segment
In the put method of Segment, first call the tryLock() method to obtain the lock, then locate the corresponding HashEntry through the hash algorithm, and then traverse the whole linked list. If the key value is found, insert the element directly; If no corresponding key is found, you need to call the rehash() method to expand the capacity of the table saved in the Segment, double the original capacity, and insert the corresponding element after the expansion. After inserting a key/value pair, you need to add 1 to the count attribute that counts the number of elements in the Segment. Finally, after the insertion is successful, you need to use unLock() to release the lock.
final V put(K key, int hash, V value, boolean onlyIfAbsent) { // Attempt to lock hashentry < K, V > node = trylock()? Null: / / if it fails, enter the scanAndLockForPut process. / / if it is a multi-core cpu, try lock 64 times at most, and enter the lock process. / / during the attempt, you can also check whether the node is in the linked list. If not, create scanAndLockForPut(key, hash, value)// After execution, segment has been locked successfully, and V oldvalue can be executed safely; Try {hashentry < K, V > [] tab = table; / / use the hash value to find the array subscript int index = (tab. Length - 1) & hash; / / return the element at the corresponding position in the array (linked list header) hashentry < K, V > first = entryat (tab, index); for (hashentry < K, V > e = first;) {if (E! = null) {/ / if a value already exists, overwrite the old value K; if ((k = e.key) = = key | (e.hash = = hash & & key. Equals (k))) {oldvalue = e.value; if (! Onlyifabsent) {e.value = value; + + modcount;} break;} e = e.next;} else {/ / add / / 1) before waiting for the lock, the node has been created, and the next points to the chain header if (node! = null) //If it is not empty, it means to create a new node for the newly created value node.setnext (first); else / / 2) node = new hashentry < K, V > (hash, key, value, first) ; int c = count + 1; / / 3) if the threshold of the segment is exceeded, the segment needs to be expanded. If (c > threshold & & tab. Length < maximum_capability) rehash (node); else / / take node as the chain header, and insert setentryat (tab, index, node) ; + + modcount; count = C; oldvalue = null; break;}}} finally {unlock(); / / finally release the lock} return oldvalue;} 123456789101112131415161718192021222324252627282930133343536373839404142434445464748495051525354555657
-
-
get method
Get is not locked, and the UNSAFE method is used to ensure visibility. In the process of capacity expansion, get takes the content from the old table first, and take the content from the new table after get
public V get(Object key) { Segment<K,V> s; // Manually integrate access methods to reduce overhead hashentry < K, V > [] tab; / / 1. Hash value int h = hash (key); long u = (((H > > > segmentshift) & segmentmask) < < sshift) + SBASE; / / 2. Find the corresponding segment if ((s = (segment < K, V >) unsafe.getobjectvolatile (segments, U))! = null & & (tab = s.table)! = null) {/ / 3. Find the linked list at the corresponding position of the segment internal array, and traverse for (hashentry < K, V > e = (hashentry < K, V >) unsafe.getobjectvolatile (tab, ((long) (((tab. Length - 1) & H)) < tshift + tbase); e! = null; E = e.next) {K; if ((k = e.key) = = key | (e.hash = = H & & key. Equals (k))) return e.value; } } return null;}1234567891011121314151617181920
summary
- Concurrent HashMap adopts the lock segmentation technology, which is subdivided internally by the Segment array, and each Segment is assembled by the HashEntry array.
- The process of locating an element in ConcurrentHashMap requires two Hash operations. The first Hash is to locate the Segment and the second Hash is to locate the head of the linked list where the element is located (the side effect of this structure is that the Hash process is longer than that of ordinary HashMap) However, the advantage is that when writing, you can only operate on the Segment where the element is located without affecting other segments. In the most ideal case, ConcurrentHashMap can support the write operation of the maximum number and size of segments at the same time
3.1.2 JDK 8 analysis
Source code analysis
-
Important attributes and internal class structure
// The default value is 0 / / during initialization, it is - 1 / / during capacity expansion, it is - (1 + number of capacity expansion threads) / / after initialization or capacity expansion, it is the threshold size of the next capacity expansion private transient volatile int sizeCtl// The entire ConcurrentHashMap is a Node [] static class Node < K, V > implements map. Entry < K, V > {final int hash; final K key; volatile V Val; volatile Node < K, V > next;} / / hash table transient volatile Node < K, V > [] table// New hash table private transient volatile Node < K, V > [] nexttable during capacity expansion// During capacity expansion, if a bin is migrated, ForwardingNode is used as the head Node of the old table bin. Static final class ForwardingNode < K, V > extends Node < K, V > {} / / it is used to occupy bits during compute and computeifabsend. After calculation, it is replaced with ordinary nodestatic final class reservationnode < K, V > extends Node < K, V > {} //Use TreeNode as the storage structure instead of Node to convert to black mangrove static final class TreeNode < K, V > extends Node < K, V > {} / / as the head Node of TreeBin, store root and first. Equivalent to TreeBin is the container that encapsulates TreeNode static final class TreeBin < K, V > extends Node < K, V > {} 1234567891011213141516171819202122232425 -
For initialization operation, ConcurrentHashMap is lazy initialization. When the put operation is called for the first time, the initTable() method is called for initialization
private final Node<K,V>[] initTable() { Node<K,V>[] tab; int sc; //Only an empty table can enter the initialization operation. While ((tab = table) = = null | tab. Length = = 0) {if ((SC = sizeCtl) < 0) / / sizeCtl < 0 indicates that other threads are already initializing or expanding, suspend the current thread Thread.yield(); / / try to set sizeCtl to - 1 (indicating initialization table) else if (u.compareandswapint) (this, sizeCtl, SC, - 1)) {/ / obtain the lock and create a table. At this time, other threads will yield in the while() loop until the table creates a try {if ((tab = table) = = null | tab. Length = = 0) {int n = (SC > 0)? SC: default_capability; node < K, V > [] NT = (node < K, V > []) new node <?,? > [n] ; / / initialize table = tab = NT; SC = n - (n > > > 2); / / record the size of the next expansion}} finally {sizeCtl = SC;} break;}} return tab;} 12345678910112131415161718192021222324 -
put operation
-
If there is no initialization, first call the initTable () method to perform the initialization process
-
Then, the hash value is calculated to determine where to put it in the array
-
If there is no hash conflict, directly insert CAS. If there is a hash conflict, take out this node
-
If the hash value of the extracted node is MOVED(-1), it means that the array is being expanded and copied to a new array, and the current thread will also help with the copy
-
If this node is neither empty nor expanding, then
Lock and add through synchronized
, and then judge whether the currently fetched node location stores a linked list or a tree
- If it is a linked list, traverse the whole linked list until the key of the node is compared with the key to be placed. If the key is equal and the hash value of the key is also equal, it means that it is the same key, and the value is overwritten. Otherwise, it is added to the end of the linked list
- If it is a tree, call the putTreeVal method to add this element to the tree
- Finally, after the completion of the addition, call addCount () method to count size and determine how many nodes there are in the node (note is the number before adding). If more than 8 are reached, then treeifyBin method is called to try to convert the linked list into tree, or expand the array.
-
public V put(K key, V value) { return putVal(key, value, false); } final V putVal(K key, V value, boolean onlyIfAbsent) { // It follows that null keys and null values are not supported if (key == null || value == null) throw new NullPointerException(); // Get hash int hash = spread(key.hashCode()); // Used to record the length of the corresponding linked list int binCount = 0; for (Node<K,V>[] tab = table;;) {//Iterate over table Node<K,V> f; int n, i, fh; // If the array is "empty", initialize the array. Lazy initialization is used if (tab == null || (n = tab.length) == 0) // Initialize the array and initialize the table tab = initTable(); // Find the array subscript corresponding to the hash value to get the first node f else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { // If the array is empty, // Use a CAS operation to put the new value into it. The put operation is almost over and can be pulled to the last side // If CAS fails, there are concurrent operations. Just go to the next cycle if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) break; // no lock when adding to empty bin } // If capacity expansion is in progress, perform capacity expansion first else if ((fh = f.hash) == MOVED) // Help with data migration tab = helpTransfer(tab, f); else { // That is to say, f is the head node of this position, and it is not empty V oldVal = null; // If the above conditions are not met, lock the head node of the linked list or red black tree, that is, there is a hash conflict synchronized (f) { if (tabAt(tab, i) == f) { if (fh >= 0) { // The hash value of the header node is greater than 0, indicating that it is a linked list // Used to accumulate and record the length of the linked list binCount = 1; // Traversal linked list for (Node<K,V> e = f;; ++binCount) { K ek; // If an "equal" key is found, judge whether to overwrite the value, and then you can break if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) e.val = value; break; } // At the end of the linked list, put the new value at the end of the linked list Node<K,V> pred = e; if ((e = e.next) == null) { pred.next = new Node<K,V>(hash, key, value, null); break; } } } else if (f instanceof TreeBin) { // Red black tree Node<K,V> p; binCount = 2; // Call the interpolation method of red black tree to insert a new node if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } // Bincount! = 0 indicates that the linked list operation is being performed above if (binCount != 0) { // Determine whether to convert the linked list into a red black tree. The critical value is the same as HashMap, which is 8 if (binCount >= TREEIFY_THRESHOLD) // This method is slightly different from that in HashMap, that is, it does not necessarily carry out red black tree conversion, // If the length of the current array is less than 64, you will choose to expand the array instead of converting to a red black tree // This method has been mentioned above treeifyBin(tab, i); if (oldVal != null) return oldVal; break; } } } // Increase size count addCount(1L, binCount); return null; } 1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071727374757677787980818283848586878889909192 -
-
get operation
- Find the corresponding position of the array according to the hash value: (n - 1) & H
- If the location is null, you can return null directly
- If the node at this location is exactly what we need, return the value of this node
- If the hash value of the node at this location is less than 0, it indicates that the capacity is being expanded or it is a red black tree. At this time, call the find method to find it
- Otherwise, it is a linked list and can be traversed and compared
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
// The spread method ensures that the returned result is a positive number
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
// If the header node is already the key to be found
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
// A negative hash indicates that the bin is in capacity expansion or treebin. In this case, call the find method to find it
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
// Normally traverse the linked list and compare with equals
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
1234567891011121314151617181920212223
summary
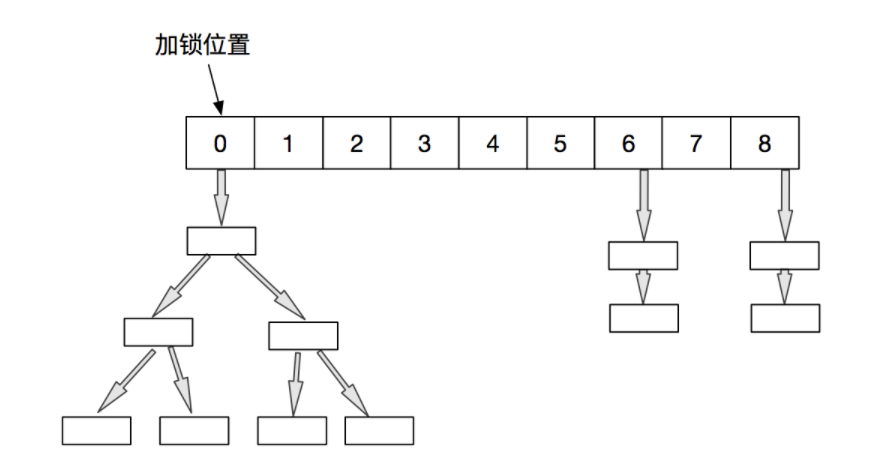
In JDK1.8, Node + CAS + Synchronized is used to ensure concurrency security. Synchronized only locks the first node of the current linked list or red black binary tree, so that concurrency will not occur as long as the hash does not conflict,
- When adding elements for the first time, initialization will be carried out. The default initial length is 16. When adding elements to the map, the position of the array will be determined by the sum of hash value and array length. If they are placed in the same position, they will be stored in the form of linked list first, and the number of elements in the same position reaches more than 8, If the length of the array is less than 64, the array will be expanded. If the length of the array is greater than or equal to 64, the linked list of the node will be converted into a tree.
- The put() method will first check whether the table is initialized, and if not, initialize the table. After locating the subscript, if there is a special node representing rehash in the subscript, it will help to expand the capacity, otherwise it will be updated or inserted. If the number of linked lists meets the conditions, it will become a red black tree. When finally increasing the total number of nodes in the map, if the total number exceeds 0.75 times the length of the table, the capacity will be expanded. During capacity expansion, the subscripts will be divided into several tasks in reverse order, and other threads can help to complete the capacity expansion
- When get(), it will locate the subscript according to the key, and then traverse the linked list or array to find the corresponding node. If the subscript is a special node representing rehash, it will query the data in the temporary expansion table
- During remove(), the linked list or red black tree in the subscript will be traversed according to the subscript. If the subscript is a special node representing rehash, the group will be expanded
Differences between concurrent HashMap in JDK7 and JDK8:
- JDK1.7 uses ReentrantLock+Segment+HashEntry, while JDK1.8 uses synchronized+CAS + array (Node) + (linked list Node | red black tree TreeNode)
- JDK7 uses the Segment lock mechanism of Segment to realize thread safety, and locks the Segment that needs to be modified. JDK8 uses CAS+synchronized to ensure thread safety. Synchronized only locks the first node of the current linked list or red black binary tree
- Why does JDK 1.8 use the built-in lock synchronized instead of the reentrant lock
- JDK1.8 uses red and black trees to optimize linked lists
How many times is the capacity of concurrent HashMap expanded each time?
2X in the transfer method, a node array twice the original array will be created to store the original data.
3.2 CopyOnWriteArrayList
CopyOnWriteArrayList is a thread safe version of ArrayList. It uses a method called copy on write, which is suitable for concurrent scenarios with more reads and less writes. When a new element is added to CopyOnWriteArrayList, first copy it from the original array, and then write to the new array. After writing, point the original array reference to the new array.
CopyOnWriteArraySet is a thread safe version of HashSet
-
The entire add operation of CopyOnWriteArrayList is performed under the protection of lock (JDK1.8)
public boolean add(E e) { final ReentrantLock lock = this.lock; lock.lock(); try { // Get old array Object[] elements = getArray(); int len = elements.length; // Copy a new array (this is a time-consuming operation, but it does not affect other read threads) Object[] newElements = Arrays.copyOf(elements, len + 1); // Add new element newElements[len] = e; // Replace old array setArray(newElements); return true; } finally { lock.unlock(); } } 123456789101112131415161718In Java 11, reentrant locks are no longer used, but synchronized
-
The read operation of CopyOnWriteArrayList is unlocked
-
There are several cases of concurrent thread reading:
1. If the write operation is not completed, directly read the data of the original array;
2. If the write operation is completed, but the reference does not point to the new array, the original array data is also read;
3. If the write operation is completed and the reference has pointed to the new array, the data is read directly from the new array.