
📢📢📢📣📣📣
🌻🌻🌻 Hello, everyone. My name is Dream. I'm an interesting Python blogger. I have a small white one. Please take care of it 😜😜😜
🏅🏅🏅 CSDN is a new star creator in Python field. I'm a sophomore. Welcome to cooperate with me
💕 Introduction note: this paradise is never short of genius, and hard work is your final admission ticket! 🚀🚀🚀
💓 Finally, may we all shine where we can't see and make progress together 🍺🍺🍺
🍉🍉🍉 "Ten thousand times sad, there will still be Dream, I have been waiting for you in the warmest place", singing is me! Ha ha ha~ 🌈🌈🌈
🌟🌟🌟✨✨✨
Let's take a closer look at the reptiles and finish off for urllib~
1, post request KFC official website
stay KFC official website Chinese restaurant query to find all stores in the specified location.
1. Analysis page
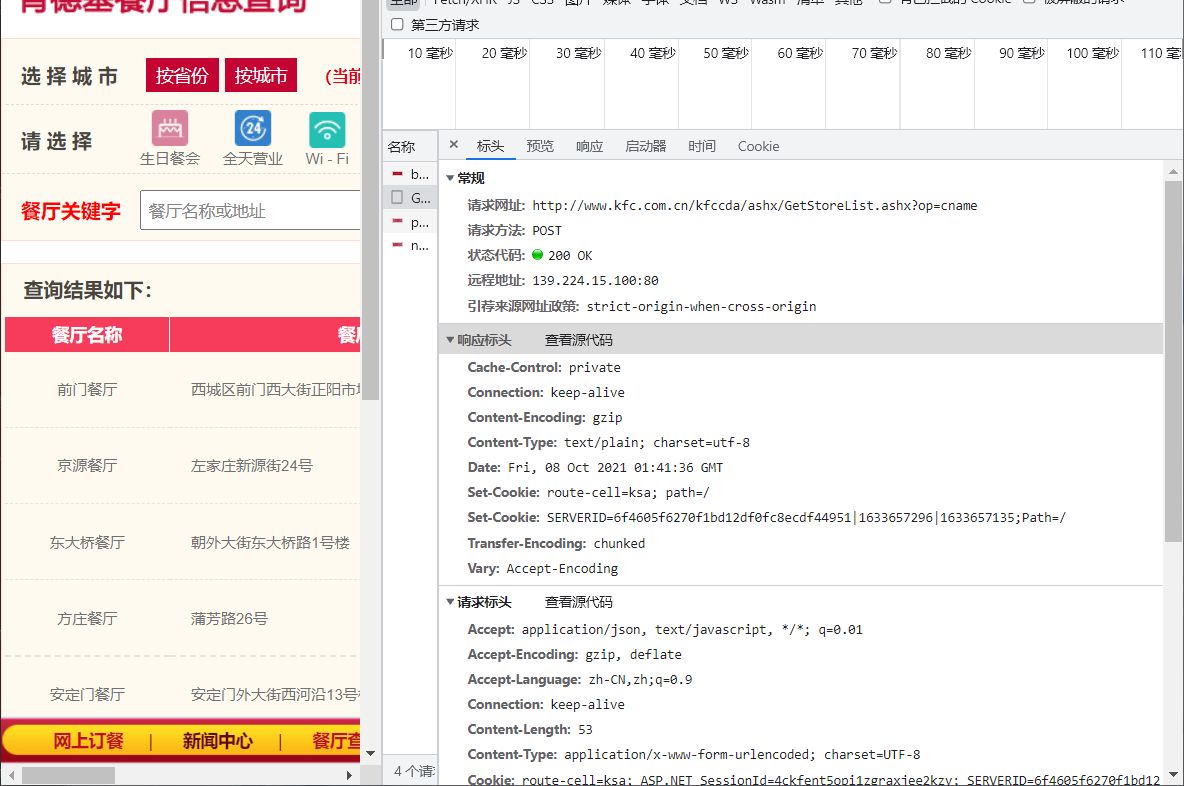
first page:
Request URL: http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname ,
Request method: POST
Data:
cname: Beijing
pid:
pageIndex: 1
pageSize: 10
Page 2:
> Request URL: http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname, > Request method: POST > `Data: ` > cname: Beijing pid: pageIndex: 2 pageSize: 10
It can be found that only data is different between pages, so we just need to change the data.
2. Coding
1. Code entry
if __name__=='__main__':
start_page = int(input(''))
end_page = int(input(''))
for page in range(start_page,end_page+1):
# Customization of request object
request=creat_request(page)
# Get page source code
content=get_content(request)
# download
down_load(page,content)
2. Request object customization
Don't forget to decode the data in the post request: encode('utf-8 ')
def creat_request(page):
base_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
data={
'cname': 'Beijing',
'pid':'',
'pageIndex':page,
'pageSize': '10'
}
data = urllib.parse.urlencode(data).encode('utf-8')
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36'
}
request=urllib.request.Request(url=base_url,headers=headers,data=data)
return request
Return don't forget to write. You have to return a data for each function.
3. Get the page source code
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
4. Download page content
def down_load(page,content):
with open('kfc_'+str(page)+'.json','w',encoding='utf-8') as fp:
fp.write(content)
5. Source code
# -*-coding:utf-8 -*-
# @Author: it's time. I love brother Xu
# Ollie, do it!!!
# post request
# first page:
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# cname: Beijing
# pid:
# pageIndex: 1
# pageSize: 10
# Page 2
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# cname: Beijing
# pid:
# pageIndex: 2
# pageSize: 10
import urllib.request
import urllib.parse
# base_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
def creat_request(page):
base_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
data={
'cname': 'Beijing',
'pid':'',
'pageIndex':page,
'pageSize': '10'
}
data = urllib.parse.urlencode(data).encode('utf-8')
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36'
}
request=urllib.request.Request(url=base_url,headers=headers,data=data)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(page,content):
with open('kfc_'+str(page)+'.json','w',encoding='utf-8') as fp:
fp.write(content)
if __name__=='__main__':
start_page = int(input(''))
end_page = int(input(''))
for page in range(start_page,end_page+1):
# Customization of request object
request=creat_request(page)
# Get page source code
content=get_content(request)
# download
down_load(page,content)
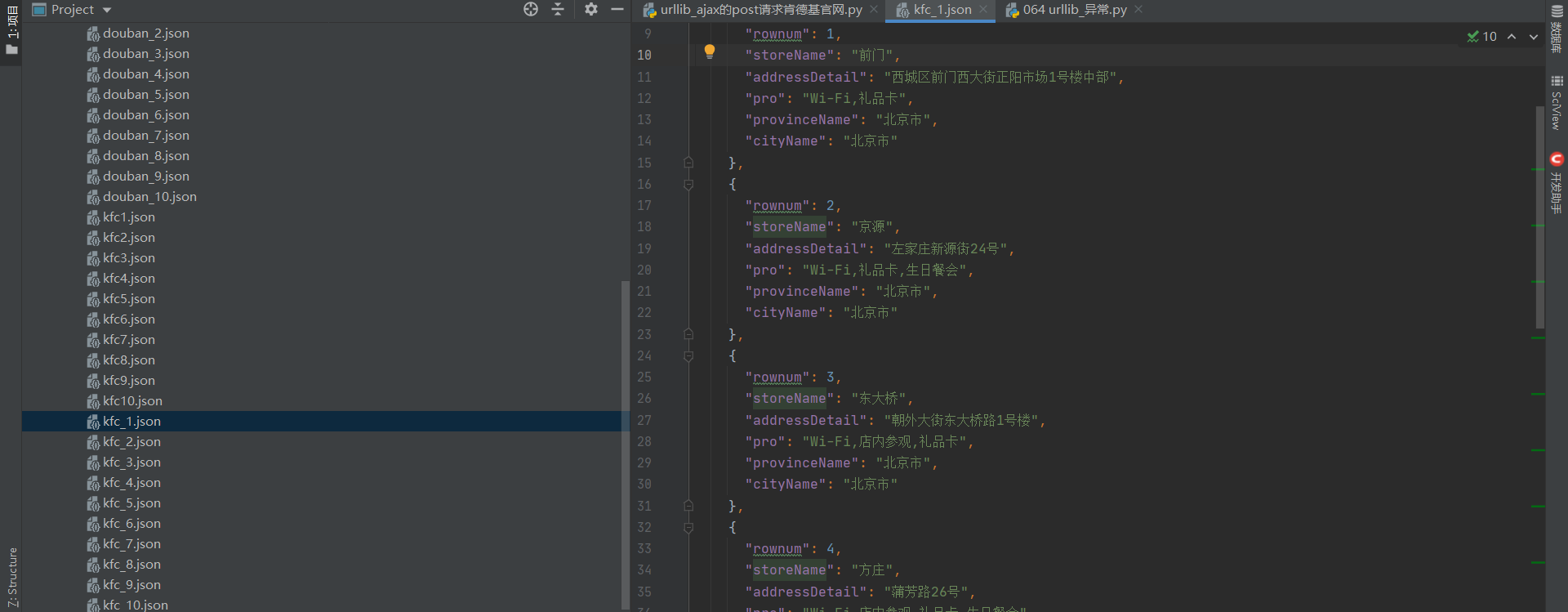
6. Crawling results
Climb page 1-10:
2, URLError\HTTPError exception analysis
The HTTPError class is a subclass of the URLError class
# -*-coding:utf-8 -*-
# @Author: it's time. I love brother Xu
# Ollie, do it!!!
import urllib.request
import urllib.error
url = 'https://blog.csdn.net/m0_37816922/article/details/120'
# url = 'http://xuxuxu.com'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36'
}
try:
request = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
# print(content)
# except urllib.error.HTTPError:
# print('system upgrading... ')
except urllib.error.URLError:
print('As I said, the system is being upgraded...')
When sending a request through urllib, it may fail. At this time, if you want to make your code more robust, you can catch exceptions through try ‐ exception. There are two types of exceptions, URLError\HTTPError
3, cookie solution QQ space login
1. Normal climbing
Analysis page: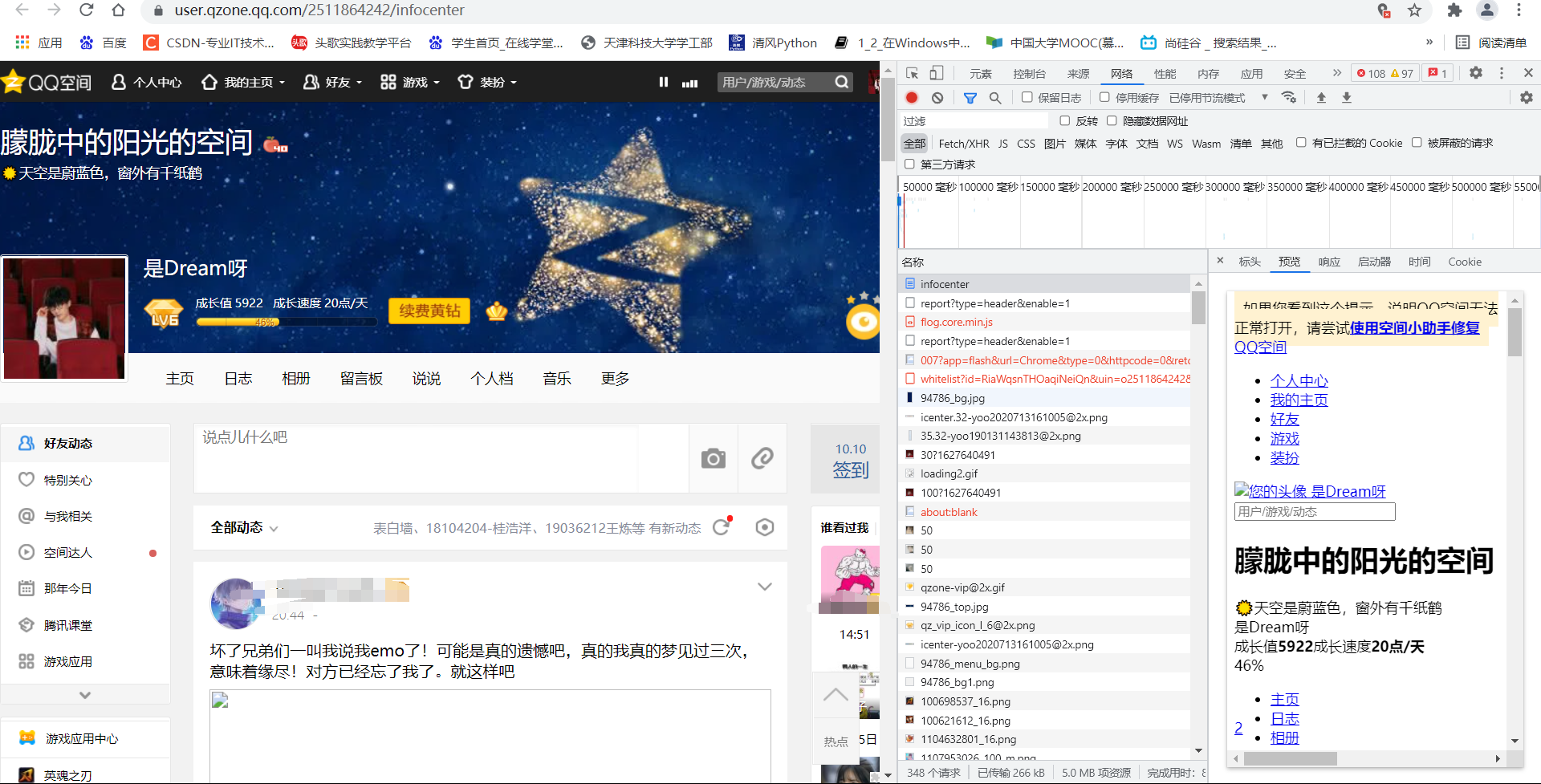
Find the connector, read the headers and get the page content:
# -*-coding:utf-8 -*-
# @Author: it's time. I love brother Xu
# Ollie, do it!!!
import urllib.request
url = 'https://user.qzone.qq.com/2511864242/infocenter'
headers={
# ':authority':' user.qzone.qq.com',
# ':method':' GET',
# ':path':' /2511864242/infocenter',
# ':scheme':' https',
# 'accept':' text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
# 'accept-encoding':' gzip, deflate, br',
# 'accept-language':' zh-CN,zh;q=0.9',
# 'cache-control':' max-age=0',
# 'cookie':' 2511864242_totalcount=13496; 2511864242_todaycount=2; RK=ECihmXLCuq; ptcz=641b0fe4634b74d761ce9c469c93f3766a6ad2639d4490f37aeb876008c0eba7; tvfe_boss_uuid=1261d53129453d07; o_cookie=2511864242; eas_sid=X0nkgoLJGuyN43gKCxXdODxpVi; QZ_FE_WEBP_SUPPORT=1; cpu_performance_v8=0; nutty_uuid=b2d3e37a-bdbd-488e-9f21-3b53e541dfee; __Q_w_s_hat_seed=1; _ga=GA1.2.118587915.1626953898; fqm_pvqid=39ed0947-c27f-433b-b69a-f45b9890024c; luin=o2511864242; lskey=00010000de072c8e6e48fa1574db17cc9090c4a164266c5036e26a0c559f714d2b597dfb256d9a9440358b1d; pgv_pvid=6039633865; ptui_loginuin=tustaixueshenghui@163.com; _gid=GA1.2.1366085169.1633784022; uin=o2511864242; _qpsvr_localtk=0.7957179321058889; skey=@Ysdnvfow4; p_uin=o2511864242; pt4_token=IPJ09cE1ONrApR1DDtSPKXtObrnyYWHykLFRh5JRyKc_; p_skey=aKyCTikz4zFyYTIAZ4OAdlzt77pg0t8h3EImRUrZGDI_; Loading=Yes; pgv_info=ssid=s4493287755; qz_screen=1536x864; qzmusicplayer=qzone_player_2511864242_1633869885141; qqmusic_uin=; qqmusic_key=; qqmusic_fromtag=',
# 'if-modified-since: Sun, 10 Oct 2021 12:44':'32 GMT',
# 'sec-ch-ua':' "Chromium";v="94", "Google Chrome";v="94", ";Not A Brand";v="99"',
# 'sec-ch-ua-mobile':' ?0',
# 'sec-ch-ua-platform':' "Windows"',
# 'sec-fetch-dest':' document',
# 'sec-fetch-mode':' navigate',
# 'sec-fetch-site':' none',
# 'sec-fetch-user':' ?1',
# 'upgrade-insecure-requests':' 1',
'user-agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36',
}
# Customization of request object
request = urllib.request.Request(url=url,headers = headers)
# Impersonate the browser to send a request to the server
response = urllib.request.urlopen(request)
# Obtain corresponding data
# content = response.read().decode('utf-8')
content = response.read().decode('utf-8')
# Save data locally
with open('qq1.html','w',encoding='utf-8') as fp:
fp.write(content)
Results obtained:
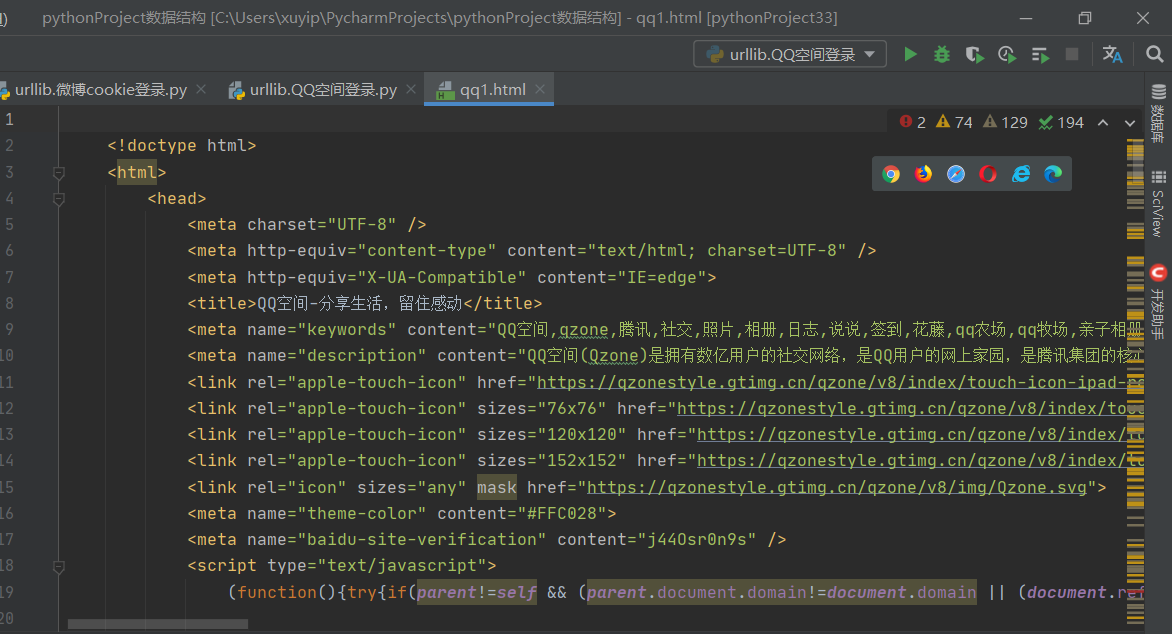
After entering, you will find that you only entered the login interface, but did not log in:

2. Use cookie s to solve problems:
Write all data in the request header to headers:
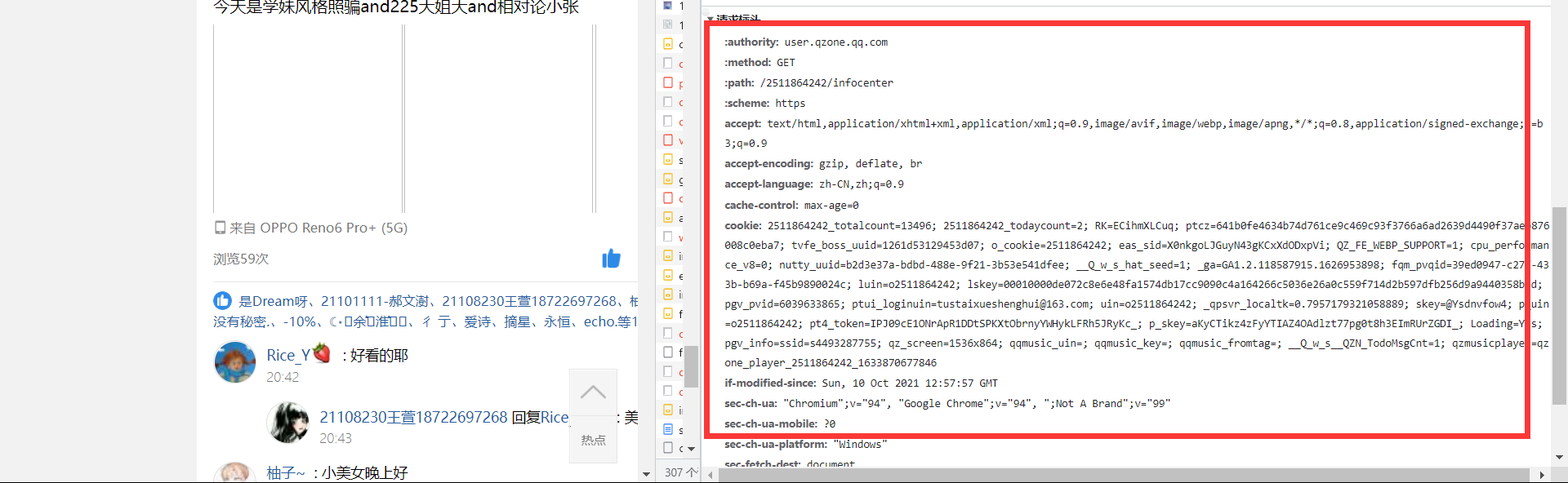
':authority':' user.qzone.qq.com', ':method':' GET', ':path':' /2511864242/infocenter', ':scheme':' https', 'accept':' text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9', 'accept-encoding':' gzip, deflate, br', 'accept-language':' zh-CN,zh;q=0.9', 'cache-control':' max-age=0', 'cookie':' 2511864242_totalcount=13496; 2511864242_todaycount=2; RK=ECihmXLCuq; ptcz=641b0fe4634b74d761ce9c469c93f3766a6ad2639d4490f37aeb876008c0eba7; tvfe_boss_uuid=1261d53129453d07; o_cookie=2511864242; eas_sid=X0nkgoLJGuyN43gKCxXdODxpVi; QZ_FE_WEBP_SUPPORT=1; cpu_performance_v8=0; nutty_uuid=b2d3e37a-bdbd-488e-9f21-3b53e541dfee; __Q_w_s_hat_seed=1; _ga=GA1.2.118587915.1626953898; fqm_pvqid=39ed0947-c27f-433b-b69a-f45b9890024c; luin=o2511864242; lskey=00010000de072c8e6e48fa1574db17cc9090c4a164266c5036e26a0c559f714d2b597dfb256d9a9440358b1d; pgv_pvid=6039633865; ptui_loginuin=tustaixueshenghui@163.com; _gid=GA1.2.1366085169.1633784022; uin=o2511864242; _qpsvr_localtk=0.7957179321058889; skey=@Ysdnvfow4; p_uin=o2511864242; pt4_token=IPJ09cE1ONrApR1DDtSPKXtObrnyYWHykLFRh5JRyKc_; p_skey=aKyCTikz4zFyYTIAZ4OAdlzt77pg0t8h3EImRUrZGDI_; Loading=Yes; pgv_info=ssid=s4493287755; qz_screen=1536x864; qzmusicplayer=qzone_player_2511864242_1633869885141; qqmusic_uin=; qqmusic_key=; qqmusic_fromtag=', 'if-modified-since: Sun, 10 Oct 2021 12:44':'32 GMT', 'sec-ch-ua':' "Chromium";v="94", "Google Chrome";v="94", ";Not A Brand";v="99"', 'sec-ch-ua-mobile':' ?0', 'sec-ch-ua-platform':' "Windows"', 'sec-fetch-dest':' document', 'sec-fetch-mode':' navigate', 'sec-fetch-site':' none', 'sec-fetch-user':' ?1', 'upgrade-insecure-requests':' 1', 'user-agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36',
Among these data, the data at the beginning must be useless. Just remove it. In fact, only cookies are useful, so we keep the cookie data:
Your login information is carried in the cookie. If there is a cookie after login, we can carry the cookie to any interface.
# -*-coding:utf-8 -*-
# @Author: it's time. I love brother Xu
# Ollie, do it!!!
import urllib.request
url = 'https://user.qzone.qq.com/2511864242/infocenter'
headers={
# ':authority':' user.qzone.qq.com',
# ':method':' GET',
# ':path':' /2511864242/infocenter',
# ':scheme':' https',
# 'accept':' text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
# 'accept-encoding':' gzip, deflate, br',
# 'accept-language':' zh-CN,zh;q=0.9',
# 'cache-control':' max-age=0',
# 'cookie':' 2511864242_totalcount=13496; 2511864242_todaycount=2; RK=ECihmXLCuq; ptcz=641b0fe4634b74d761ce9c469c93f3766a6ad2639d4490f37aeb876008c0eba7; tvfe_boss_uuid=1261d53129453d07; o_cookie=2511864242; eas_sid=X0nkgoLJGuyN43gKCxXdODxpVi; QZ_FE_WEBP_SUPPORT=1; cpu_performance_v8=0; nutty_uuid=b2d3e37a-bdbd-488e-9f21-3b53e541dfee; __Q_w_s_hat_seed=1; _ga=GA1.2.118587915.1626953898; fqm_pvqid=39ed0947-c27f-433b-b69a-f45b9890024c; luin=o2511864242; lskey=00010000de072c8e6e48fa1574db17cc9090c4a164266c5036e26a0c559f714d2b597dfb256d9a9440358b1d; pgv_pvid=6039633865; ptui_loginuin=tustaixueshenghui@163.com; _gid=GA1.2.1366085169.1633784022; uin=o2511864242; _qpsvr_localtk=0.7957179321058889; skey=@Ysdnvfow4; p_uin=o2511864242; pt4_token=IPJ09cE1ONrApR1DDtSPKXtObrnyYWHykLFRh5JRyKc_; p_skey=aKyCTikz4zFyYTIAZ4OAdlzt77pg0t8h3EImRUrZGDI_; Loading=Yes; pgv_info=ssid=s4493287755; qz_screen=1536x864; qzmusicplayer=qzone_player_2511864242_1633869885141; qqmusic_uin=; qqmusic_key=; qqmusic_fromtag=',
# 'if-modified-since: Sun, 10 Oct 2021 12:44':'32 GMT',
# 'sec-ch-ua':' "Chromium";v="94", "Google Chrome";v="94", ";Not A Brand";v="99"',
# 'sec-ch-ua-mobile':' ?0',
# 'sec-ch-ua-platform':' "Windows"',
# 'sec-fetch-dest':' document',
# 'sec-fetch-mode':' navigate',
# 'sec-fetch-site':' none',
# 'sec-fetch-user':' ?1',
# 'upgrade-insecure-requests':' 1',
'user-agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36',
}
# Customization of request object
request = urllib.request.Request(url=url,headers = headers)
# Impersonate the browser to send a request to the server
response = urllib.request.urlopen(request)
# Obtain corresponding data
# content = response.read().decode('utf-8')
content = response.read().decode('utf-8')
# Save data locally
with open('qq1.html','w',encoding='utf-8') as fp:
fp.write(content)
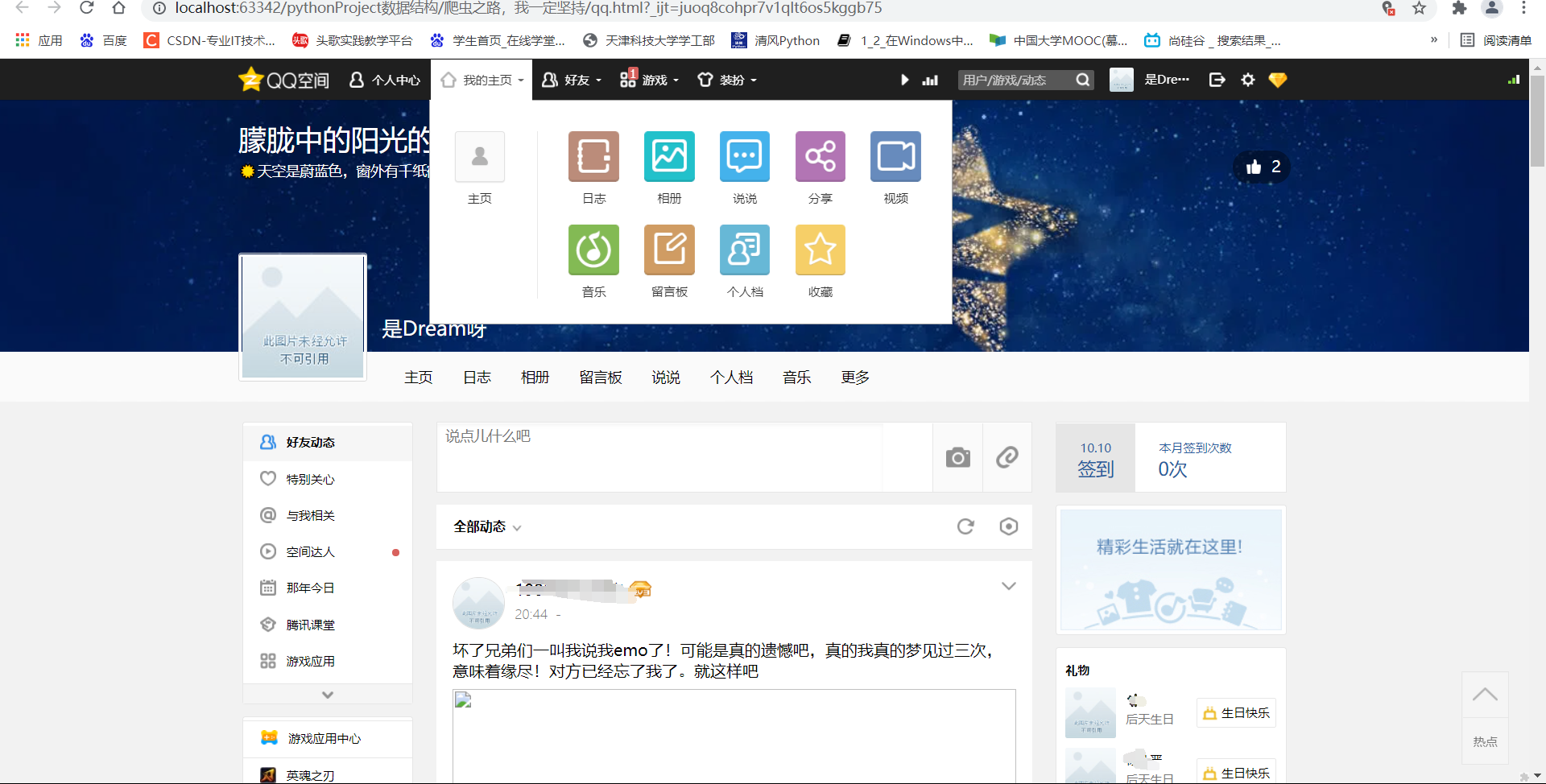
View results:
Sure enough, I went into QQ space:
4, Handler processor
Why learn handler?
urllib.request.urlopen(url): the request header cannot be customized. urllib.request.Request(url,headers,data): the request header can be customized
Handler: Customize more advanced request headers (with the complexity of business logic, the customization of request objects can no longer meet our needs (dynamic cookie s and proxies cannot use the customization of request objects)
# -*-coding:utf-8 -*-
# @Author: it's time. I love brother Xu
# Ollie, do it!!!
import urllib.request
url = 'https://www.baidu.com'
# The customization of request object is the first means to solve anti crawling
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36'
}
request = urllib.request.Request(url=url,headers=headers)
# handler build_opener open
# (1) Get handler object
handler = urllib.request.HTTPHandler()
# (2) Get opener object
opener = urllib.request.build_opener(handler)
# Call the open method
response = opener.open(request)
content = response.read().decode('utf-8')
print(content)
5, Agent basic usage
Access your own ip: ip
1. Common functions of agents?
- Break through their own IP access restrictions and visit foreign sites.
- Access to internal resources of some units or groups: FTP of a University (provided that the proxy address is within the allowable access range of the resource) and use the free proxy server in the address section of the education network can be used for various FTP download and upload, as well as various data query and sharing services open to the education network.
- Improve access speed expansion: usually, the proxy server sets a large hard disk buffer. When external information passes through, it will also be saved to the buffer. When other users access the same information again, the information will be directly taken out of the buffer and passed to users to improve access speed.
- Hide real IP extension: Internet users can also hide their IP in this way to avoid attacks.
2. Code configuration agent
- Create a Reuqest object
- Create ProxyHandler object
- Creating an opener object with a handler object
- Send the request using the opener.open function
1. Normally access this page:
# -*-coding:utf-8 -*-
# @Author: it's time. I love brother Xu
# Ollie, do it!!!
import urllib.request
url='https://www.baidu.com/s?wd=ip'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
# Request object customization
request = urllib.request.Request(url=url,headers=headers)
# Impersonate browser access server
response = urllib.request.urlopen(request)
# Get response information
content = response.read().decode('utf-8')
# preservation
with open('daili.html','w',encoding='utf-8') as fp:
fp.write(content)
2. Use the handler method
Access using proxy ip: Fast proxy free IP
Use proxy ip to hide your real ip.
# -*-coding:utf-8 -*-
# @Author: it's time. I love brother Xu
# Ollie, do it!!!
import urllib.request
url='https://www.baidu.com/s?wd=ip'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
# Request object customization
request = urllib.request.Request(url=url,headers=headers)
proxies={
'http':'118.24.219.151:16817'
}
handler = urllib.request.ProxyHandler(proxies=proxies)
opener = urllib.request.build_opener(handler)
# Impersonate browser access server
# response = urllib.request.urlopen(request)
response = opener.open(request)
# Get response information
content = response.read().decode('utf-8')
# preservation
with open('yincangdaili1.html','w',encoding='utf-8') as fp:
fp.write(content)
📢📢📢 Final benefits
☀️☀️☀️ The last little benefit: if you want to get started with python quickly, this detailed PPT can quickly help you lay a solid foundation for python. If you need it, you can download it A complete set of Python introductory basic tutorials + Xiaobai quick success + learning won't come to me! 🍻🍻🍻
There are also self-made confession artifacts, which need to be taken by yourself:
Python confession artifact, source code + analysis + various perfect configurations + romantic and novel 🍻🍻🍻

🌲🌲🌲 Well, that's all I want to share with you today
❤️❤️❤️ If you like, don't save your one button three connections~

