Today is the second day of the National Day holiday. I've been playing for a day. Today, I'll sort out the ideas of data analysis homework written in the previous two days and type the manuscript for the experimental report. It is a reference for the little partners who are interested in reptiles, and also hopes to provide a little help to the students who have not completed the experiment.
- Mission requirements.
1) Analyze the page structure and determine the data items to be captured. At least the article title, publication time, body content, article URL, etc. can be captured. Additional data items can be added according to the content characteristics of the selected capture target. (for example, when capturing Sina blog, you can capture additional data items such as labels, categories, reading numbers, comments, etc.), and news can capture additional data items such as authors and news sources.
Note: labels and classifications are arrays, and data should be stored in the form of array / list.
Scoring standard: Full Score: 35; 5 points for each data item, 30 points for 4 main data items, and full score for more than 2 additional data items;
2) Correctly handle directory pages and body pages, and be able to automatically capture at least 100 Web pages.
Scoring standard: Full Score: 25; Score 5 points for every 20 pieces of data, and score more than 100 according to the number of crawls, full score; 3) Data persistence. Save data to disk file.
Scoring standard: full score 20 points; Determine the score according to no writing, writing text or Excel, and writing to the database; No writing 0 points, writing text or Excel 10 points; Write to database 20 points;
data processing
Scoring standard: Full Score: 15 points; 5 points for data processing; 5 points for each data processing problem and 15 points for solving more than two data processing problems;
Report the overall situation:
Scoring criteria: 5 points for the cleanliness of the report format;
Extra points: for new problems not required in the experimental report but found during the experiment, 5 points will be added for each, no more than 10 points.
2. The experiment needs to understand the requests and re library, which are used to crawl the data text and extract the specified information. It also needs to know a little about create in sqlalchemy_ The engine () method is used to store the data in the database. Static web page information is relatively easy to crawl, but Ajax is used in blog web pages. Its full name is Asynchronous Javascript and XML, that is, Asynchronous Javascript and XML. It can use JavaScript to exchange data with the server and update some web pages under the condition of ensuring that the page is not refreshed and the page link remains unchanged. In this case, there are two ideas to obtain the corresponding data, one is to crawl the data before the page is rendered, and the other is to crawl the data after the page is rendered. This article first introduces crawling the json file before the page is rendered.
3. The following is the implementation code:
'''
coding:requests.apparent_encoding
@author: Li Sentan
@time:2021.9.30
@file:infoblog_requests1.py
'''
import requests
import re
from bs4 import BeautifulSoup
import pandas as pd
import time
from sqlalchemy import create_engine
#Get the content of the captured web page information and return the text format of the web page source code
def getHTMLText(url):
try:
kv = {'user-agent':'Mozilla/5,0'}
r = requests.get(url,headers = kv,timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "Page request failed!"
#Get the link of each blog and coexist in the array
def gethref(depth):
scale = 80
start = time.perf_counter()
hrefall = []
start_url = 'http://blog.sina.com.cn/s/articlelist_1197161814_0_'
print("Grabbing href,please wait a moment".center(scale // 2, '-'))
for i in range(1, depth + 1):
try:
url = start_url + str(i) + ".html"
html = getHTMLText(url)
soup = BeautifulSoup(html, "html5lib")
for link in soup.find_all("a", title="", target="_blank"):
href = link.get("href")
href2 = href.split("/")[-1].split("_")[0]
if href2 == "blog":
# print(href)
hrefall.append(href)
# print(count)
# print(link.get_text())
# textall.append(link.get_text())
except:
continue
print("Grab href Time use:{}".format(time.perf_counter()-start))
return hrefall
#Get the article name and content of each blog and store them in array form.
def gettext(hrefall):
scale = 80
start = time.perf_counter()
# chinesetextall = []
# englishtextall = []
aidsall = []
textnameall = []
textall= []
count = 1
total = len(hrefall)
print("Grabbing text and textname,please wait a moment".center(scale // 2, '-'))
for i in hrefall:
aa = '*' * (count // 5)
bb = '-' * ((total - count) // 5)
c = (count / total) * 100
aid = i.split("/")[-1].split("_")[1]
b = ""
for j in range(10,16):
b+=aid[j]
aids = b
aidsall.append(aids)
soup = BeautifulSoup(getHTMLText(i),"html5lib")
for link in soup.find_all("title"):
textname = link.get_text().split("_")[0]
if textname != "":
textnameall.append(textname)
else:
textnameall.append("NaN")
print('\n'+'Grab Textname If the information is missing, please run it under the condition of good network.'.center(scale // 2, '-'))
for link in soup.find_all("div", id="sina_keyword_ad_area2"):
text = link.get_text()
text = re.sub("[\n\t\u200b\xa0\u3000]", " ", text)
# chinese = text.split("English full text:") [0]
# english = text.split("full text in English:") [1]
# print(chinese, "\n", " ", english)
if text != []:
textall.append(text)
else:
textall.append("NaN")
print('Grab Text If the information is missing, please run it under the condition of good network.'.center(scale // 2, '-'))
dur = time.perf_counter() - start
print("\r{:^3.0f}%[{}->{}]{:.2f}s".format(c, aa, bb, dur), end='')
count = count + 1
print("\n"+"Grab text and textname Time use:{}".format(time.perf_counter() - start))
return textnameall,textall,aidsall
#Get the number of collections, likes, reads, reprints and comments of each blog, which are also stored in the form of array.
def getnumber(aidsall):
scale = 80
fall = []
dall = []
rall = []
zall = []
call = []
print("Grabbing number,please wait a moment".center(scale // 2, '-'))
start = time.perf_counter()
for i in range(len(aidsall)):
aa = '*' * (i//5)
b = '-' * ((len(aidsall) - i)//5)
c = (i / len(aidsall)) * 100
urlbase = "http://comet.blog.sina.com.cn/api?maintype=num&uid=475b3d56&aids="
a = getHTMLText(urlbase+aidsall[i])
b1 = re.findall(r'"f":(\d+)', a)#Collection
b2 = re.findall(r'"d":(\d+)', a)#like
b3 = re.findall(r'"r":(\d+)', a)#read
b4 = re.findall(r'"z":(\d+)', a)#Reprint
b5 = re.findall(r'"c":(\d+)', a)#comment
if b1!= []:
fall.append(int(''.join(b1)))
else:
fall.append('NaN')
print('Grab number If the information is missing, please run it under the condition of good network.'.center(scale // 2, '-'))
if b2!=[]:
dall.append(int(''.join(b2)))
else:
dall.append('NaN')
# print('There are omissions in fetching information, please run it when the network is good. '. center(scale // 2,' - ')
if b3!=[]:
rall.append(int(''.join(b3)))
else:
rall.append('NaN')
# print('There are omissions in fetching information, please run it when the network is good. '. center(scale // 2,' - ')
if b4!=[]:
zall.append(int(''.join(b4)))
else:
zall.append('NaN')
# print('There are omissions in fetching information, please run it when the network is good. '. center(scale // 2,' - ')
if b5!=[]:
call.append(int(''.join(b5)))
else:
call.append('NaN')
# print('There are omissions in fetching information, please run it when the network is good. '. center(scale // 2,' - ')
# fall.append(int(float(b1[0])))
# dall.append(int(float(b2[0])))
# rall.append(int(float(b3[0])))
# zall.append(int(float(b4[0])))
# call.append(int(float(b5[0])))
dur = time.perf_counter() - start
print("\r{:^3.0f}%[{}->{}]{:.2f}s".format(c, aa, b, dur), end='')
# print(fall,"\n",dall,"\n",rall,"\n",zall,"\n",call)
return fall,dall,rall,zall,call
#Call the function to realize the corresponding function. Store the crawling data into csv files and databases.
def main():
scale = 80
start = time.perf_counter()
depth =6
hrefall = gethref(depth)
textnameall, textall, aidsall = gettext(hrefall)
fall, dall, rall, zall, call = getnumber(aidsall)
try:
print('\n'+"Building DataFrame format,please wait a moment".center(scale // 2, '-'))
pf = pd.DataFrame({"Textname":textnameall,"Text":textall,"href":hrefall,"Number of collections":fall,"Like counting":dall,"Reading number":rall,"Number of reprints":zall,"Number of comments":call})
pf.index = pf.index + 1
print("Storing csv file,please wait a moment".center(scale // 2, '-'))
pf.to_csv("blog_info2.csv",encoding="utf-8")
print("Total time:{}".format(time.perf_counter()-start))
print("Saving data to database,please wait a moment".center(scale // 2, '-'))
connect = create_engine("mysql+pymysql://root:lst0916@localhost:3306/infoblog")
pd.io.sql.to_sql(pf,'infoblog',connect,schema = "infoblog",if_exists = 'replace',index = False)
print('Data crawling completed!'.center(scale // 2, '-'))
except:
print('There are omissions in the captured information. Please run under the condition of good network.'.center(scale // 2, '-'))
if __name__ == '__main__':
main()
The code is a little long. In fact, it is relatively simple to look at it separately. The overall part of the article defines four function methods, and then adds a main (). Before writing the code, we still make it clear that several functions are required to crawl information, and then define functions respectively to realize the functions. This way of thinking will be clearer. In addition, because the author's programming ability is not strong enough, I will create a lianxi.py to practice unfamiliar function methods, and then save it to the general file after writing.
Result screenshot:
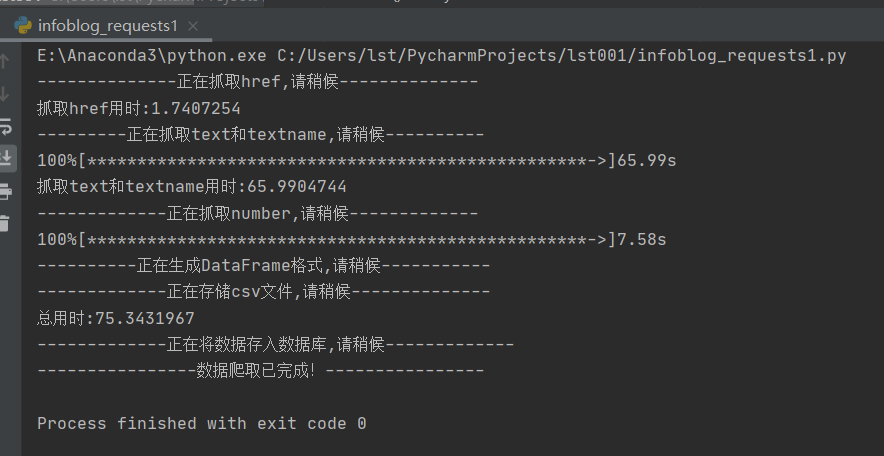 This is when the campus network is better. It took more than 70 seconds.
This is when the campus network is better. It took more than 70 seconds.
The defined functions can be easily understood. The following points should be explained:
1. Timer (this method is learned in teacher Songtian's class): the author adds a timer in gettext(),getnumber() method, which is equivalent to a progress bar. In this way, when crawling information, we can intuitively see the progress of crawling. Of course, we can also see the speed of the network (students using the campus network pay attention, cough cough cough). In addition, Network problems will also lead to the loss of information crawled among you. I am very painful when generating dataframe format, because if there is little data, the generation will fail.
2. Looking at the code, you will find that I use try and except more to solve the problem of data loss during intermediate crawling. The lost data is "NaN" "Said that in this way, the datafame data format can be generated whether it is lost or not, which makes the code more robust. Although this adds additional judgment and prolongs the crawling time, it is still necessary. After all, when I use the campus network without try and except, I don't succeed in crawling several times.
3. Store the data in the database. To be honest, the author vaguely understood this method before: create_engine(), but I don't know much about the database, because I didn't learn the database well last semester. I only read the book at the end of the semester, and sql sever hasn't been used for several times. Although the command of the database is relatively simple, I still forget it. Hahahaha, the author, a little garbage, later searched the data and read the book of the database. It should be another preview, hahahaha, Then uninstall the sql server, next mysql, and finally create_ The engine () method is clear. After importing the data into the database and viewing the data, select * from infolog is ok. Here is create_engine():
from sqlalchemy import create_engine
import pymysql
connect = create_engine("mysql+pymysql://root:lst0916@localhost:3306/infoblog")
pd.io.sql.to_sql(pf,'infoblog',connect,schema = "infoblog",if_exists = 'replace')
#con = pymysql.connect(host=localhost, user=username, password=password, database=dbname, #charset='utf8',use_unicode=True)
# dbinfo = {
# 'uesr':'root',
# 'host':'@localhost:3306',
# 'password':'lst0916',
# 'database':'infoblog',
# 'charset':'utf8',
# 'use_unicode':True
# }Where pf is the dataframe structure of the data, and create_ The parameters in engine () are consistent with those in pymysql.connect(). The author's database dbinfo information is shown in the table above. You can view the information in your own database and write it in the order of parameters.
4. Main problems and optimization points:
(1) Crawling the article name and content of each blog is relatively slow. Regardless of the network problem, from the code point of view, the author first created the beautifulsup object, then searched it twice (once to find the article name and once to crawl the article content), and finally put them in the array corresponding to append. Therefore, a search can be synthesized during optimization.
(2) If you do not add try expect during crawling, it is particularly easy to miss information when crawling javascript rendered pages, so you may report an error in the '. Join() method. This is because if the crawling information is missing, the parameters in join() are empty, so you report an error. However, the silly author sometimes reports an error and sometimes does not report an error when running before, I thought the ". Join () side was unstable, so I used the int() method again. Unexpectedly, I still made mistakes from time to time. I directly doubt life. So many methods of tmd are unstable. What does pycharm do? Ha ha ha ha. As a result, when dataframe reported an error, I suddenly realized that the original culprit is the campus network! Good guy, it suddenly became clear that it took two days to write code and calculate the class. It took a day and a half to light up the bug. Finally, I would like to thank the campus network for giving me more experience in crawlers and increasing the robustness of my code.
(3) Finding json files and crawling javascript content as a difficulty, we really need to understand this well. First, find the developer tool - > Network - > js, find the corresponding js file, and then crawl the data in it. The other way is to crawl the rendered page without looking for the json file. In fact, it is to use the browser kernel to make a virtual browser. The specific method is to use the selenium library. The author will try to write out the process of crawling data from scratch + selenium later.
Xiaobai's growth story......
Together we face the challenges of the future!
Smile happily every day!