Summary
This is about hadoop Installation tests for. stay server110 Install the configuration on and synchronize to server111,server112
Environmental Science
Centos 7
jdk 1.8
hadoop-3.2.1
server110 192.168.1.110
server111 192.168.1.111
server112 192.168.1.112
install
#decompression [root@server110 software]# tar -xzvf hadoop-3.2.1.tar.gz -C /opt/modules/ #environment variable [root@server110 hadoop-3.2.1]# vim /etc/profile #java JAVA_HOME=/opt/modules/jdk1.8.0_181 PATH=$PATH:$JAVA_HOME/bin #hadoop HADOOP_HOME=/opt/modules/hadoop-3.2.1 PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export JAVA_HOME HADOOP_HOME PATH :wq #Save Exit #Make environment variables valid [root@server110 hadoop-3.2.1]# source /etc/profile #test [root@server110 hadoop-3.2.1]# hadoop Usage: hadoop [OPTIONS] SUBCOMMAND [SUBCOMMAND OPTIONS] or hadoop [OPTIONS] CLASSNAME [CLASSNAME OPTIONS] ..
Local mode wordcount test
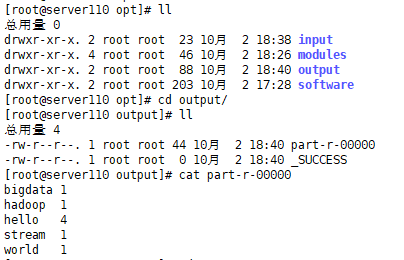
#Create Test File [root@server110 opt]# mkdir input [root@server110 opt]# cd input/ [root@server110 input]# vim input.txt hello world hello bigdata hello stream hello hadoop #Execute hadoop with sample jar [root@server110 opt]# hadoop jar /opt/modules/hadoop-3.2.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount /opt/input/ /opt/output #View Output Results [root@server110 opt]# cat output/part-r-00000 bigdata 1 hadoop 1 hello 4 stream 1 world 1
Output directory structure
Pseudo Distributed Configuration
configuration file
Default profile, not sure what format to write, can refer to the default profile
core-default.xml
hdfs-default.xml
mapred-default.xml
yarn-default.xml
- hadoop-3.2.1\share\hadoop\common\hadoop-common-3.2.1.jar\core-default.xml
- hadoop-3.2.1\share\hadoop\hdfs\hadoop-hdfs-3.2.1.jar\hdfs-default.xml
- hadoop-3.2.1\share\hadoop\mapreduce\hadoop-mapreduce-client-core-3.2.1.jar\mapred-default.xml
- hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-common-3.2.1.jar\yarn-default.xml
Configure JAVA_HOME whenever an env file is encountered
#Profile directory [root@server110 hadoop]# pwd /opt/modules/hadoop-3.2.1/etc/hadoop [root@server110 hadoop]# vim hadoop-env.sh #shift+g jumps to the last line export JAVA_HOME=/opt/modules/jdk1.8.0_181
#core-site.xml configuration [root@server110 hadoop]# vim core-site.xml <!--To configure namenode address --> <property> <name>fs.defaultFS</name> <value>hdfs://server110:9000</value> </property> <!--hadoop Storage directory for temporary files generated at runtime --> <property> <name>hadoop.tmp.dir</name> <value>/opt/modules/hadoop-3.2.1/data/tmp</value> </property> #hdfs-site.xml configuration [root@server110 hadoop]# vim hdfs-site.xml <!-- Number of copies default 3--> <property> <name>dfs.replication</name> <value>3</value> </property>
Format NameNode
[root@server110 hadoop-3.2.1]# bin/hdfs namenode -format 2021-10-02 19:37:23,307 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = server110/192.168.1.110 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 3.2.1 .. `021-10-02 19:37:24,414 INFO common.Storage: Storage directory /opt/modules/hadoop-3.2.1/data/tmp/dfs/name has been successfully formatted.` .. /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at server110/192.168.1.110 ************************************************************/
Start hdfs
Startup error, prompting to start using root,
HDFS_NAMENODE_USER, HDFS_DATANODE_USER, HDFS_SECONDARYNAMENODE_USER need to be configured
[root@server110 hadoop-3.2.1]# sbin/start-dfs.sh Starting namenodes on [server110] ERROR: Attempting to operate on hdfs namenode as root ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation. Starting datanodes ERROR: Attempting to operate on hdfs datanode as root ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation. Starting secondary namenodes [server110] ERROR: Attempting to operate on hdfs secondarynamenode as root ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
Configure the following at the top of start-dfs.sh and stop-dfs.sh
(If stop-dfs.sh is not configured, it will start up and stop)
[root@server110 hadoop-3.2.1]# vim sbin/start-dfs.sh HDFS_NAMENODE_USER=root HDFS_DATANODE_USER=root HDFS_SECONDARYNAMENODE_USER=root [root@server110 hadoop-3.2.1]# vim sbin/stop-dfs.sh HDFS_NAMENODE_USER=root HDFS_DATANODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
Configuration complete, restart
[root@server110 hadoop-3.2.1]# sbin/start-dfs.sh Starting namenodes on [server110] Last logon: June, October, 2, 19:28:08 CST 2021 From 192.168.1.107pts/0 upper Starting datanodes Last logon: June, October, 2, 19:52:03 CST 2021pts/1 upper localhost: Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts. Starting secondary namenodes [server110] Last logon: June, October, 2, 19:52:06 CST 2021pts/1 upper [root@server110 hadoop-3.2.1]# jps 22962 SecondaryNameNode 23109 Jps 22539 NameNode 22699 DataNode
Close Firewall
web port 9870 was found to be blocked, closing three machine firewalls
[root@server110 hadoop-3.2.1]# systemctl stop firewalld.service
[root@server110 hadoop-3.2.1]# systemctl disable firewalld.service
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
[root@server110 hadoop-3.2.1]# systemctl status firewalld.service
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Docs: man:firewalld(1)
10 Month 02 17:45:14 server111 systemd[1]: Starting firewalld - dynamic firewall daemon...
10 Month 02 17:45:15 server111 systemd[1]: Started firewalld - dynamic firewall daemon.
10 Month 02 19:58:36 server110 systemd[1]: Stopping firewalld - dynamic firewall daemon...
10 Month 02 19:58:37 server110 systemd[1]: Stopped firewalld - dynamic firewall daemon.
View the web interface
View web page, hadoop3.x version, web port changed to 9870
http://192.168.1.110:9870/
Can be accessed normally and configured successfully
Turn off hdfs
[root@server110 hadoop-3.2.1]# sbin/stop-dfs.sh Stopping namenodes on [server110] Last logon: June 20:03:58 CST 2021pts/1 upper Stopping datanodes Last logon: June 20:12:06 CST 2021pts/1 upper Stopping secondary namenodes [server110] Last logon: June 20:12:08 CST 2021pts/1 upper
Cluster Configuration
Cluster Planning
NameNode, SecondaryNameNode, ResourceManager are resource intensive, so they are distributed across different machines
| server110 | server111 | server112 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
workers
[root@server110 hadoop]# vim workers server110 server111 server112
hdfs-site.xml
Add secondaryNameNode configuration information
[root@server110 hadoop]# vim hdfs-site.xml <!--secondary NameNode To configure --> <property> <name>dfs.namenode.secondary.http-address</name> <value>server112:9868</value> </property>
yarn-env.xml
[root@server110 hadoop]# vim yarn-env.sh #shift+g jumps to the last line export JAVA_HOME=/opt/modules/jdk1.8.0_181
yarn-site.xml
Specify ResourceManager address
How reducer gets data mapreduce_shuffle
[root@server110 hadoop]# vim yarn-site.xml
<!--Appoint resourcemanager -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>server111</value>
</property>
<!--reducer How to get data-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
start-yarn.sh & stop-yarn.sh
To start yarn with root, you need to add the following variables at the top of the start-yarn.sh & stop-yarn.sh files. This is configured in advance, so you won't have to report any errors later.
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
mapred-env.sh
Configure JAVA_HOME whenever an env file is encountered
[root@server110 hadoop]# vim mapred-env.sh #shift+g jumps to the last line export JAVA_HOME=/opt/modules/jdk1.8.0_181
mapred-site.xml
1. Configure MapReduce to run on yarn
2. Configure the classpath, otherwise execute mr and report no class error
[root@server110 hadoop]# vim mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>The runtime framework for executing MapReduce jobs.
Can be one of local, classic or yarn.
</description>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
${HADOOP_HOME}/etc/hadoop,
${HADOOP_HOME}/share/hadoop/common/*,
${HADOOP_HOME}/share/hadoop/common/lib/*,
${HADOOP_HOME}/share/hadoop/hdfs/*,
${HADOOP_HOME}/share/hadoop/hdfs/lib/*,
${HADOOP_HOME}/share/hadoop/mapreduce/*,
${HADOOP_HOME}/share/hadoop/mapreduce/lib/*,
${HADOOP_HOME}/share/hadoop/yarn/*,
${HADOOP_HOME}/share/hadoop/yarn/lib/*
</value>
</property>
Delete format data
Delete formatted namenode information and log information in pseudo-distributed
[root@server110 hadoop-3.2.1]# rm -rf data/ logs/
synchronize files
[root@server110 modules]# scp -r hadoop-3.2.1/ server111:/opt/modules/ [root@server110 modules]# scp -r hadoop-3.2.1/ server112:/opt/modules/
environment variable
[root@server111 modules]# vim /etc/profile HADOOP_HOME=/opt/modules/hadoop-3.2.1 PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export JAVA_HOME HADOOP_HOME PATH
[root@server112 modules]# vim /etc/profile HADOOP_HOME=/opt/modules/hadoop-3.2.1 PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export JAVA_HOME HADOOP_HOME PATH
Reformat namenode
[root@server110 hadoop-3.2.1]# bin/hadoop namenode -format
Start dfs
[root@server110 hadoop-3.2.1]# sbin/start-dfs.sh Starting namenodes on [server110] Last logon: June 21:49:16 CST 2021pts/1 upper Starting datanodes Last logon: June 21:50:08 CST 2021pts/1 upper Starting secondary namenodes [server112] Last logon: June 21:50:10 CST 2021pts/1 upper
Start yarn
Since the configured resourceManager is on server 111, yarn can only be started on server 111, and other nodes will fail to start
[root@server111 hadoop-3.2.1]# sbin/start-yarn.sh Starting resourcemanager Last logon: June 18:13:38 CST 2021 from server112pts/1 upper Starting nodemanagers Last logon: June 22:07:15 CST 2021pts/0 upper
jps
There are NameNode, DataNode, NodeManager on server 110
[root@server110 opt]# jps 29718 Jps 29607 NodeManager 28907 DataNode 28734 NameNode
There are DataNode, ResourceManager, NodeManager on server 111
[root@server111 hadoop-3.2.1]# jps 22609 DataNode 23025 ResourceManager 23189 NodeManager 23542 Jps
There are DataNode, SecondaryNameNode, NodeManager on server112
[root@server112 hadoop-3.2.1]# jps 23472 Jps 23347 NodeManager 22974 SecondaryNameNode 22879 DataNode
View the web
http://192.168.1.110:9870
http://192.168.1.111:8088
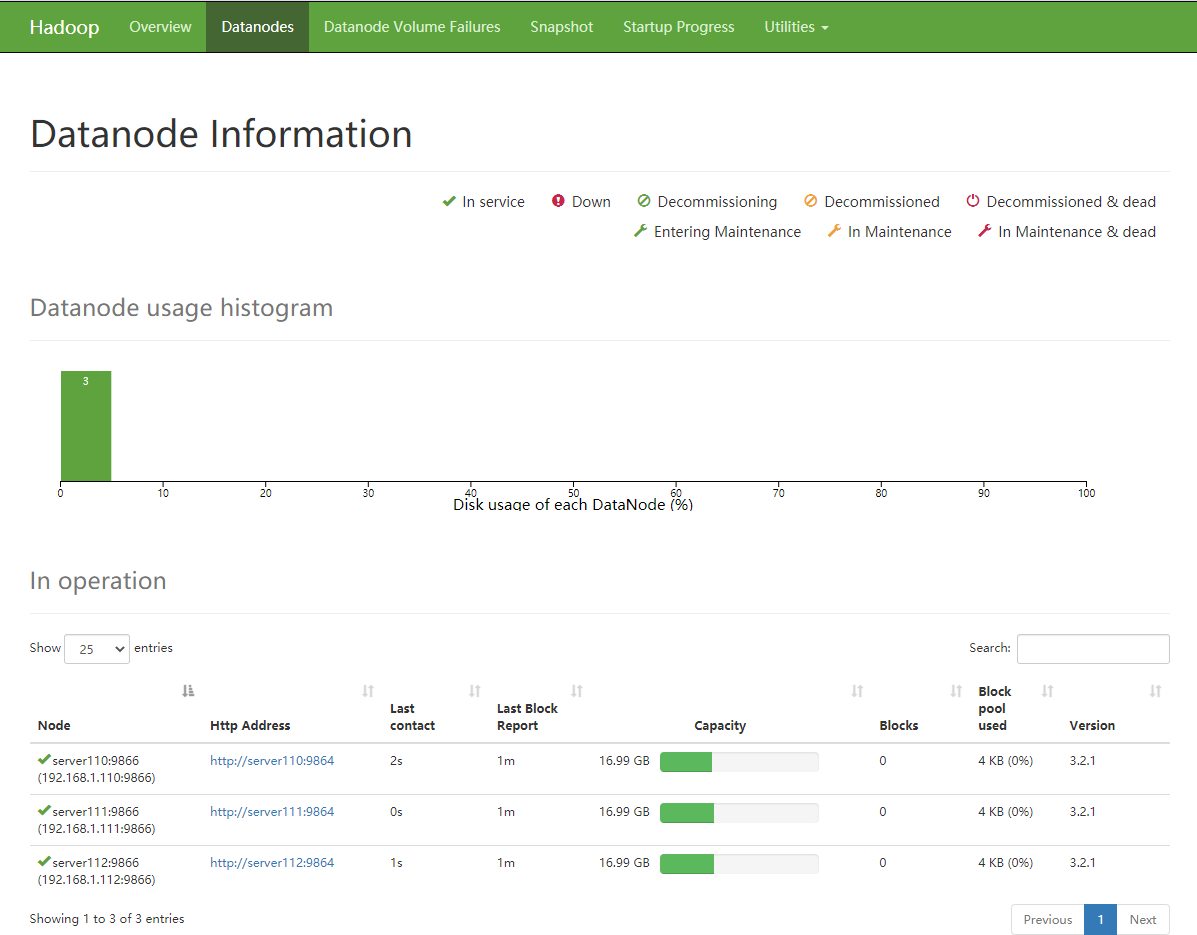
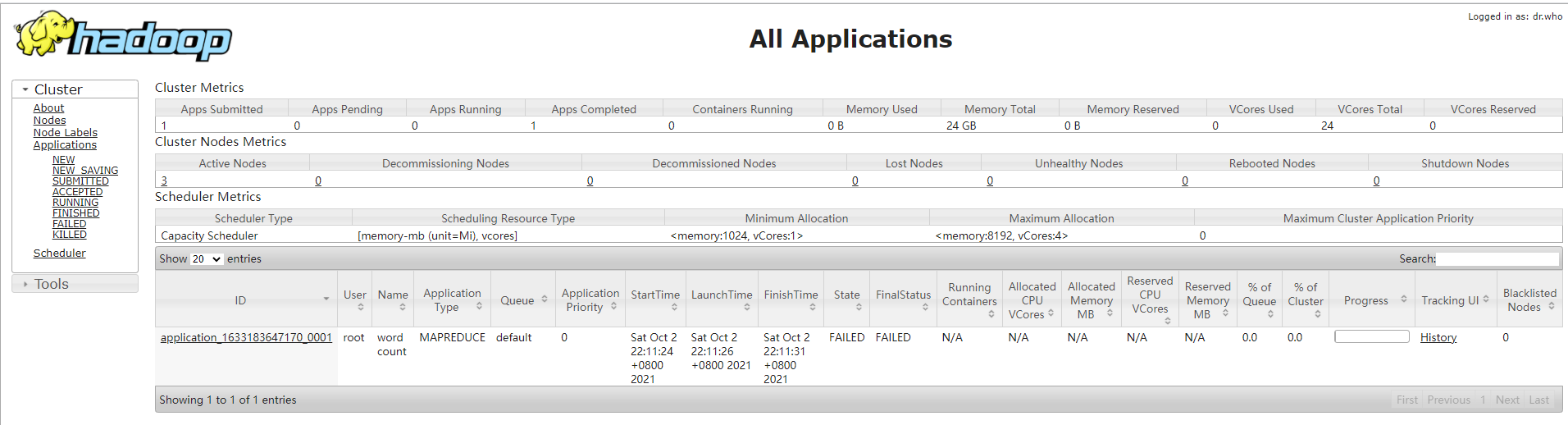
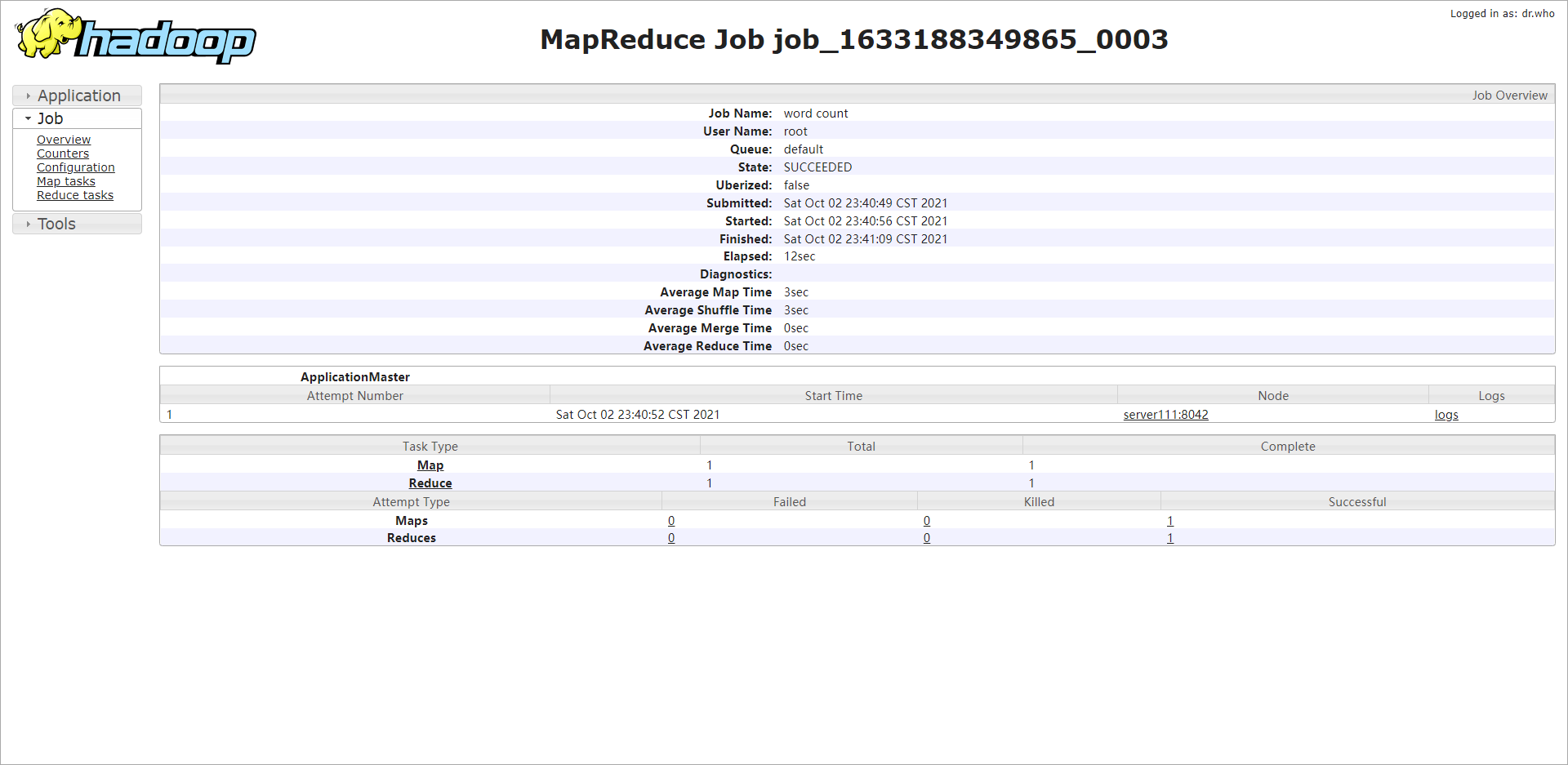
test
HDFS
#Upload the input folder under opt to the root directory of hdfs [root@server110 opt]# hdfs dfs -put input /
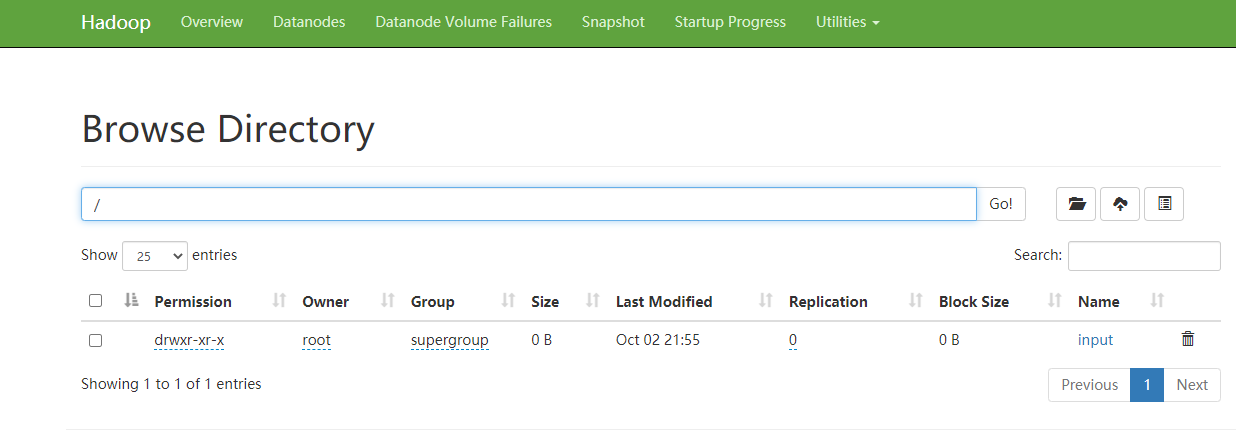
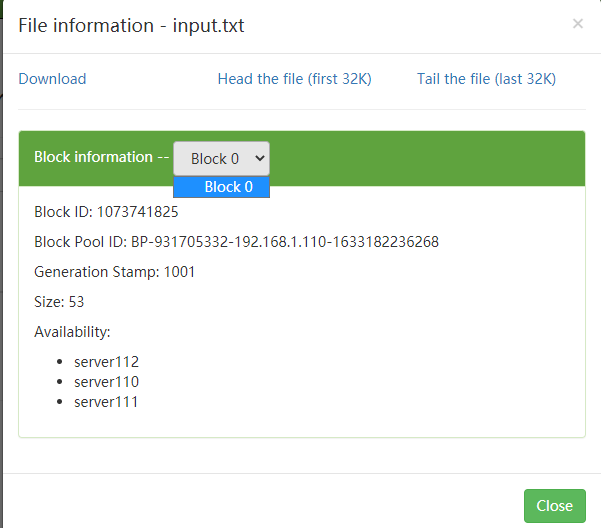
View file information
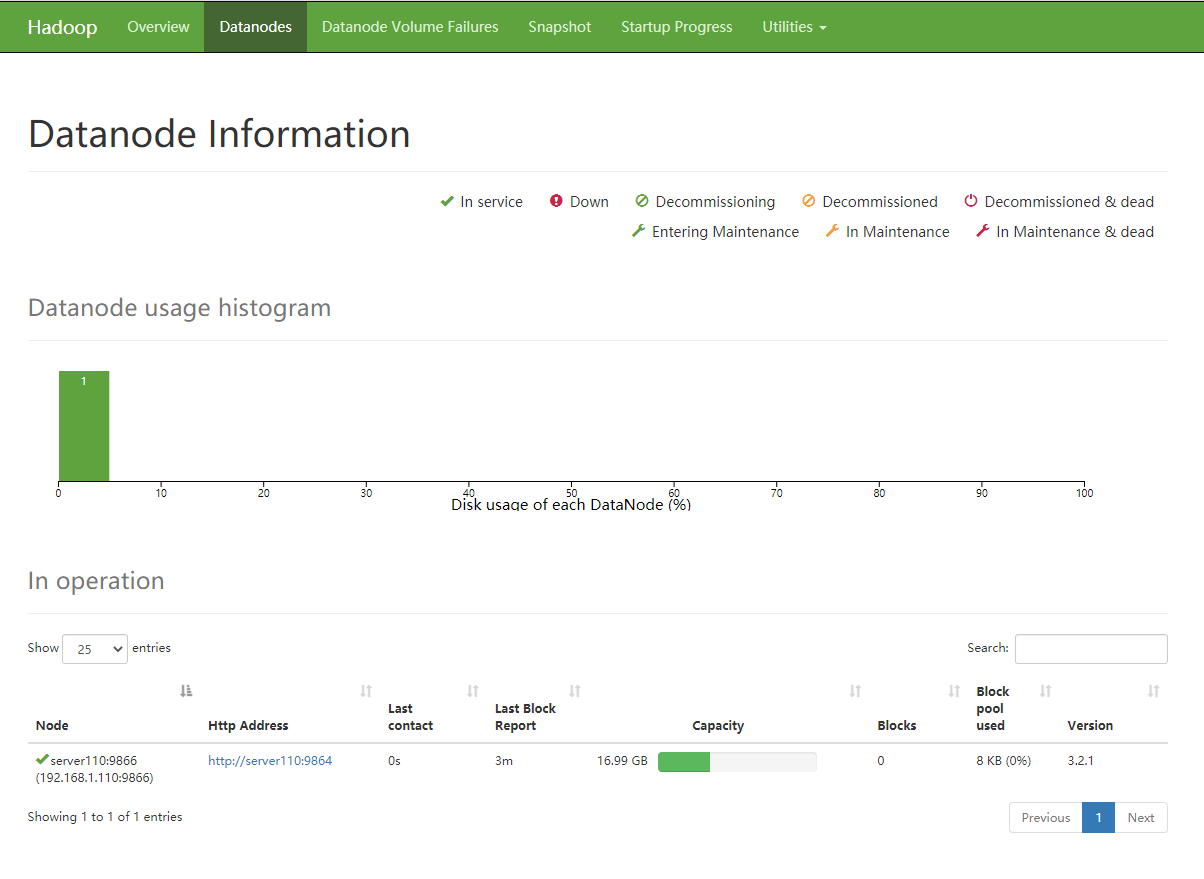
The file is small and only one block is allocated
The number of copies configured above is 3, and the node where the available copies are displayed below in Availability.
MR
Test wordcount using the existing input directory on hdfs
[root@server110 opt]# hadoop jar /opt/modules/hadoop-3.2.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount /input /output [root@server110 opt]# hdfs dfs -ls / Found 3 items drwxr-xr-x - root supergroup 0 2021-10-02 21:55 /input drwxr-xr-x - root supergroup 0 2021-10-02 22:35 /output drwx------ - root supergroup 0 2021-10-02 22:05 /tmp [root@server110 opt]# hdfs dfs -ls /output Found 2 items -rw-r--r-- 3 root supergroup 0 2021-10-02 22:35 /output/_SUCCESS -rw-r--r-- 3 root supergroup 44 2021-10-02 22:35 /output/part-r-00000 [root@server110 opt]# hdfs dfs -cat /output/part-r-00000 2021-10-02 22:36:23,310 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false bigdata 1 hadoop 1 hello 4 stream 1 world 1
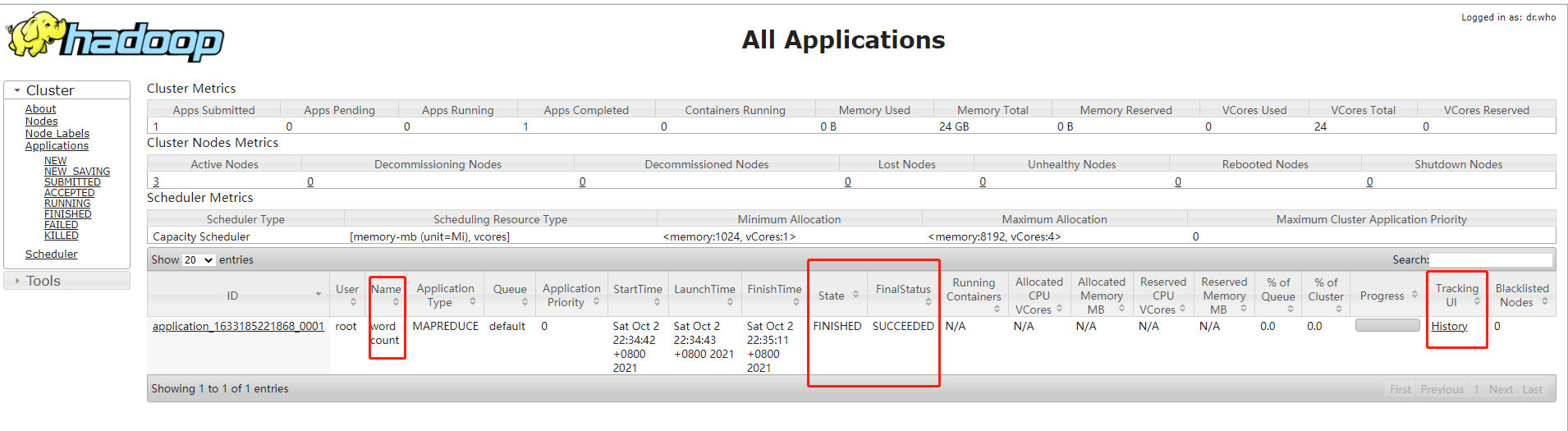
History Server & Log Aggregation
When testing mr, we found that the history server has forgotten to configure. Configure it here.
Configured on server111 node, can only be started on server111 node
[root@server110 opt]# vim /opt/modules/hadoop-3.2.1/etc/hadoop/mapred-site.xml <!--Configure History Server --> <property> <name>mapreduce.jobhistory.address</name> <value>server111:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>server111:19888</value> </property>
[root@server110 opt]# vim /opt/modules/hadoop-3.2.1/etc/hadoop/yarn-site.xml
<!--Log Aggregation-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>-1</value>
</property>
Start History Server
[root@server111 hadoop-3.2.1]# mapred --daemon start historyserver [root@server111 hadoop-3.2.1]# jps 27446 ResourceManager 27319 DataNode 28316 Jps 27597 NodeManager 28254 JobHistoryServer
Test log
#Delete output folder on original dfs [root@server110 hadoop-3.2.1]# hdfs dfs -rm -r /output #Re-execute wordcount program [root@server110 hadoop-3.2.1]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount /input /output #View output directory [root@server110 hadoop-3.2.1]# hdfs dfs -ls /output Found 2 items -rw-r--r-- 3 root supergroup 0 2021-10-02 23:10 /output/_SUCCESS -rw-r--r-- 3 root supergroup 44 2021-10-02 23:10 /output/part-r-00000 #View Output Results [root@server110 hadoop-3.2.1]# hdfs dfs -cat /output/part-r-00000 2021-10-02 23:10:44,393 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false bigdata 1 hadoop 1 hello 4 stream 1 world 1
view log
1. Unable to access log server
- Because the configuration file configures the event hostname, server111, but the local window system is inaccessible.
Required to be added at C:\Windows\System32\driversetc\hosts
192.168.1.110 server110 192.168.1.111 server111 192.168.1.112 server112
2. Error checking log, history server starts normally, web can't see log. After checking the permissions of / tmp directory, yarn automatically created / tmp/logs directory is root:root, and the default administrator group is root:supergroup.
[root@server110 hadoop-3.2.1]# hdfs dfs -chmod 777 /tmp
Log Normal