Requirements: use postgresql13 to test the Chinese full-text retrieval function
Install postgresql13 database
I use the docker container to install and test
1. Create a centos7 image container
docker run -di --name postgres13 --privileged=true -p 5432:5432 centos:7 /usr/sbin/init
docker exec -it postgres13 bash
2. Install yum source
yum install https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm
3. Start installation
yum install -y gcc gcc-c++ epel-release llvm5.0 llvm5.0-devel clang libicu-devel perl-ExtUtils-Embed readline readline-devel zlib zlib-devel openssl openssl-devel pam-devel libxml2-devel libxslt-devel openldap-devel systemd-devel tcl-devel python-devel centos-release-scl-rh
yum makecache yum -y install postgresql13-server.x86_64 postgresql13-devel.x86_64
5. Initialize database
/usr/pgsql-13/bin/postgresql-13-setup initdb systemctl enable postgresql-13 systemctl start postgresql-13
6. Configure account information
su -postgres psql
Create user
create user test with password '123.com';
Create database
create database test_db owner test;
sign out
\q
7. Set remote configuration
Modify the configuration file postgresql.conf – allow remote
Location: / var/lib/pgsql/10/data/postgresql.conf
Modify: listen_addresses = '*'
Modify profile pg_hba.conf – access rules
Location: / var/lib/pgsql/10/data/pg_hba.conf
Modify: add host all 0.0.0.0/0 MD5 access rule under Ipv4 at the bottom
Restart service
systemctl restart postgresql-13.service
Full text retrieval
A data type tsvector is provided to store the preprocessed documents, and a type tsquery is provided to represent the processed documents query . There are many functions and operators available for these data type , the most important of which is the matching operator @@ . Full text search can Use indexes to speed up.
Full text search in PostgreSQL is based on the matching operator @ @, which returns true when a tsvector (document) matches a tsquery (query)
e.g
Search for the existence of cat and rat in a fat cat sat on a mat and ate a fat rat
SELECT 'a fat cat sat on a mat and ate a fat rat'::tsvector @@ 'cat & rat'::tsquery; ?column? ---------- t
As suggested in the above example, a tsquery is NOT just an unprocessed text, at most a tsvector. A tsquery contains search terms. They must be normalized word bits, AND and, OR, NOT, AND FOLLOWED BY can be used Operators combine multiple terms . There are several functions to_tsquery,plainto_tsquery and phraseto_tsquery can be used to convert the text written by users into correct tsquery. They mainly use the method of regularizing the words appearing in the text. Similarly, to_tsvector is used to parse and normalize a document string. So in practice, a text search match may look more like:
SELECT to_tsvector('fat cats ate fat rats') @@ to_tsquery('fat & rat');
?column?
----------
t
In tsquery, the & (AND) operator specifies that both of its parameters must appear in the document to indicate a match. Similarly, the | (OR) operator specifies that at least one parameter must appear, AND! The (NOT) operator specifies that its parameters cannot be matched until they appear. For ex amp le, query fat &! Rat matches documents that contain fat but NOT rat.
e.g
Search fat cats ate fat rats for ate and no ca
SELECT to_tsvector('fat cats ate fat rats') @@ to_tsquery('ate & ! ca');
?column?
----------
t
Judge whether two words are adjacent
SELECT to_tsvector('fatal error not fatal') @@ to_tsquery('fatal <-> error');
?column?
----------
t
SELECT to_tsvector('fatal error not fatal') @@ to_tsquery('fatal <-> fatal');
?column?
----------
f
Query fields from tables
First create a test table
CREATE TABLE test(id int,info TEXT,crt_time TIMESTAMP); INSERT INTO test SELECT generate_series(1,10000),md5(random()::TEXT),clock_timestamp();
You can do a full-text search without an index.
View the row of fcd801772aa08e53eb52fefc0504467d in the id column in the info column
SELECT id
FROM test
WHERE to_tsvector('english', info) @@ to_tsquery('english', 'fcd801772aa08e53eb52fefc0504467d');

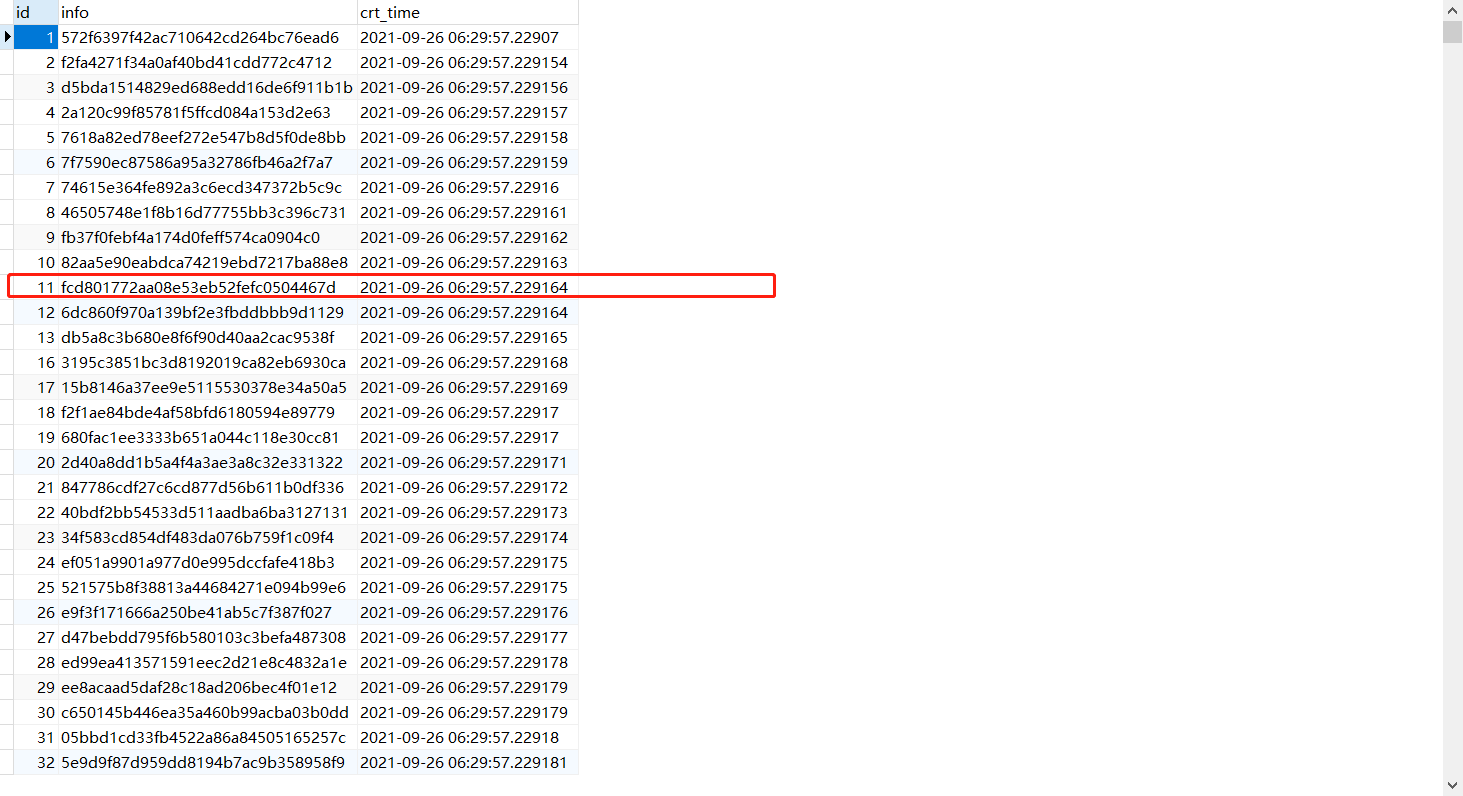
The above query specifies that you want to use the english configuration to parse and normalize strings. We can also ignore the configuration parameters:
SELECT id
FROM test
WHERE to_tsvector(info) @@ to_tsquery('fcd801772aa08e53eb52fefc0504467d');
View the full-text retrieval configuration that is already installed in the database
\dF *
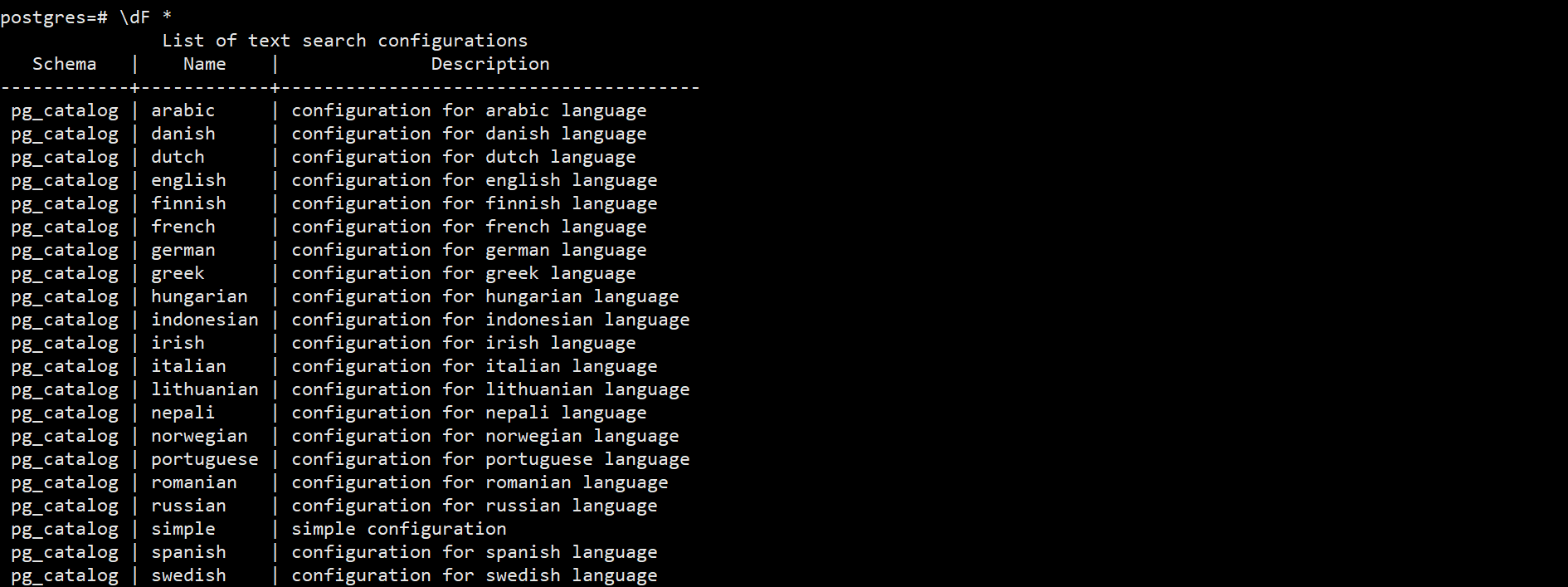
At present, full-text retrieval does not support Chinese, and additional plug-ins need to be installed
Extended file installation directory: / usr/pgsql-13/share/extension
Install Chinese search component
install zhparser
scws needs to be installed before installing zhparser
Install compiler tools
yum install gcc make wget git -y
wget http://www.xunsearch.com/scws/down/scws-1.2.3.tar.bz2
./configure && make && make install
git clone https://github.com/amutu/zhparser.git
export PATH=/usr/pgsql-13/bin:$PATH make && make install
Login database
[root@229372496fad zhparser-master]# su - postgres
-bash-4.2$ psql
psql (13.4)
Type "help" for help.
postgres=# create extension zhparser;
CREATE EXTENSION
postgres=# \dFp
List of text search parsers
Schema | Name | Description
------------+----------+---------------------
pg_catalog | default | default word parser
public | zhparser |
(2 rows)
Problem summary
Question 1: make: pg_config: Command not found make: *** No targets. Stop.
solve:
export PATH=/usr/pgsql-13/bin:$PATH
Recompile and install again
make & make install