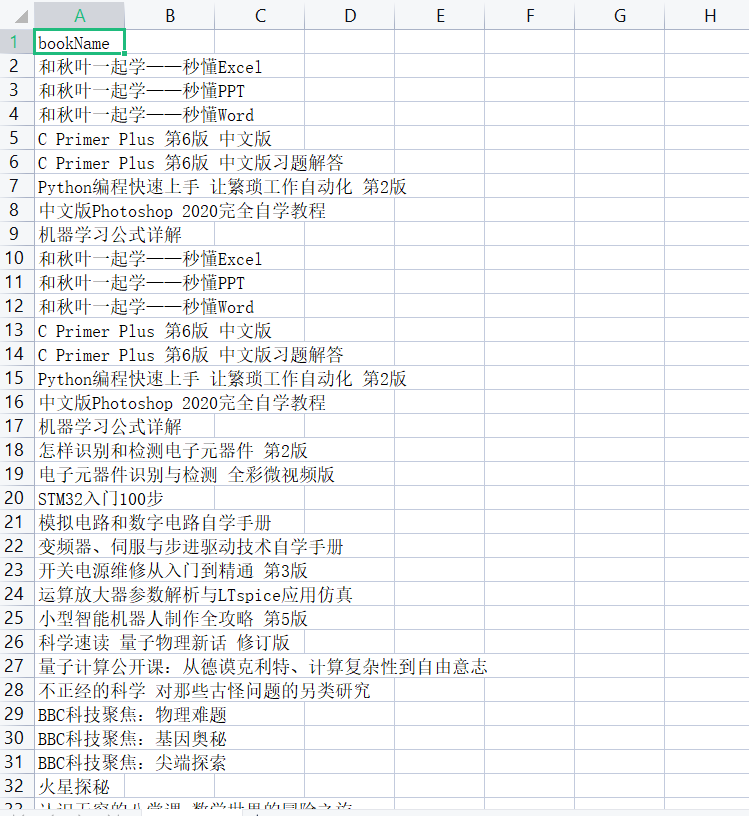
Title: use the crawler to get all the book names recommended by the new book under this website
This is the homework assigned by my teacher after I went online for the reptile course last Thursday. When I did it, I didn't know how to use the cycle. After consulting the students next to me, I probably understood the method used for this problem. In fact, I always have some ideas. I think I'm not sensitive to the code, which can easily lead to problems. My head is blank and I don't know how to start. I look here and there vaguely and still can't think of a way to solve the problem. This is a very fatal problem. I am running away from everything I fear and all unsolvable problems. No, you can't do this. If you keep running away, you will achieve nothing. In the end, you still can't learn to cycle and judge. Wake up, boy, you are still young. You have many things I dream of. I believe you can do it.
As shown in the figure:

Website of the people's Posts and Telecommunications Publishing House: https://www.ptpress.com.cn/
Now I am still a program ape on the road. I don't understand many things, but I will share what I have learned in my own way and use my own words to clarify what the program has done. Maybe there are deficiencies in my language, expression ability and code understanding. You are welcome to criticize and correct.
1, First, import the library required by the code
bs4's full name is beautiful soup. It is one of the commonly used libraries for writing python crawlers. It is mainly used to parse html tags.
WebDriverWait -- displays the wait time
Import the By package from selenium.webdriver.common.by to locate elements
Various judgments are generally used in conjunction with waiting events, such as waiting for an element to load
Import time module and pandas Library
To use Selenium library to crawl dynamic web pages, you need to download selenium webdriver plug-in (chromedriver)
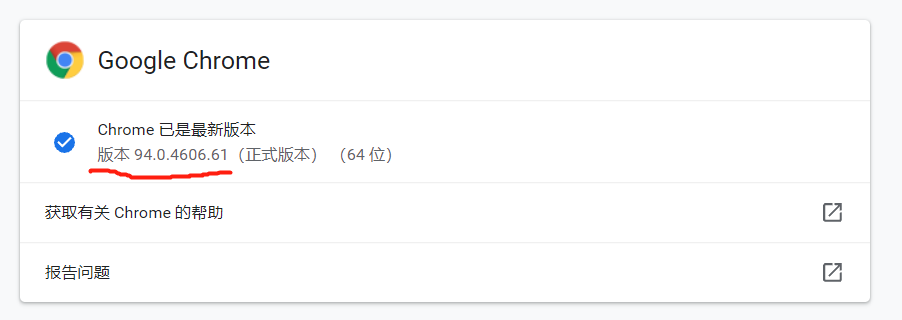
Compare your Google browser version and select the corresponding plug-in version to download
1, (1) click the three dots in the upper right corner of Google browser (2) click Help (3) Click about Google Chrome
Log in to the chromedriver installation website http://npm.taobao.org/mirrors/chromedriver/

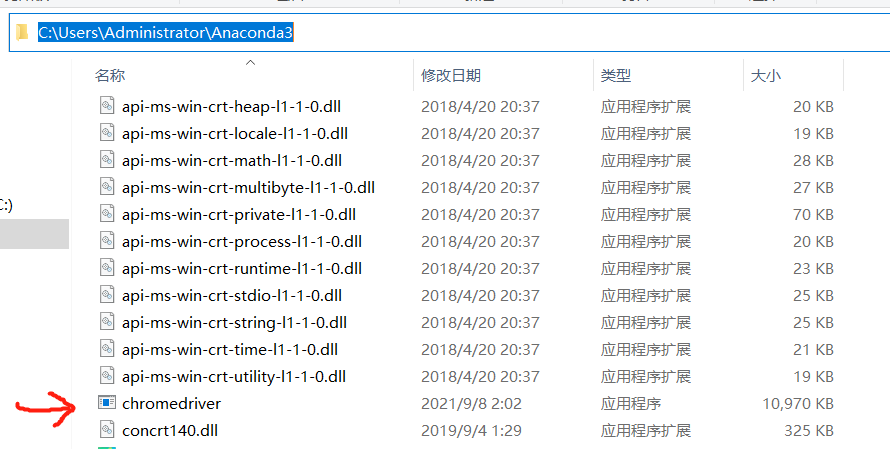
Download this plug-in and save it to the path of Anaconda3 on your computer
My Anaconda3 path is: C:\Users\Administrator\Anaconda3
Next, PyCharm runs the code and starts
from bs4 import BeautifulSoup from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC import time import pandas as pd  ##### Enter the URL, start the browser and visit the specified website. After running, a Google browsing page will open, showing a waiting time of 10s. Assign a list to allbookName ```python url = 'https://www.ptpress.com.cn/' driver = webdriver.Chrome() #Launch browser driver.get(url) #Visit the specified website print(driver.page_source) wait = WebDriverWait(driver, 10) # Set waiting time allbookName=[]

There are 17 kinds of books recommended in the new book, including computer, electronics, popular science, communication, photography, economy, management, finance and investment, success / motivation, psychology, design, music, film, beauty, life, industry and painting. There are 8 books under each book type, so you need to cycle 17 times. Locate the button position, right-click the electronic button, click Check, view the code corresponding to this button, write down its path, and then cycle 17 times, so that the crawler can automatically turn the page and crawl to all books.
When you locate the button of each book type, execute the click operation, use the lxml interpreter to parse, and then use the select method to obtain the target path (book name) to be extracted in the soup object, so as to obtain the book name and put it into allbookName. After each book type obtains 8 books, sleep for 2 seconds and then cycle.
#Get the names of all books recommended by the new book
for i in range(1,18):
confirm_btn = wait.until(
EC.element_to_be_clickable(
(By.CSS_SELECTOR, '#newBook > div.main > div.tabs > span:nth-child({})'.format(i)) # Positioning button position
)
)
confirm_btn.click() # Execute click operation
soup = BeautifulSoup(driver.page_source, 'lxml') # Parsing web pages
souped = soup.select('div.new-book div.box > a > p') # Define target native
bookName = [i.text for i in souped] # Get book title
allbookName.extend(bookName)
print(allbookName)
print(len(allbookName))
time.sleep(2)




##### In this way, all book titles are run. There are 17 book categories and 8 books under each category. The total number is 17x8=136, and the result is correct
##### The last step: create a DataFrame and save it as a csv file
```python
#Save as csv file
data = pd.DataFrame({ #Convert data to data frame
'bookName':allbookName
})
data.to_csv('all_book.csv',index=None,encoding='utf-8') #Save data