1, Principle and construction process
1. Principle
Previously, we learned the text compressor based on LZW algorithm, which is based on the repetition of substrings in the text. Huffman coding is another text compression algorithm, which is based on the relative frequency of different symbols in a text. Suppose a text is a string composed of characters a, u, x and z, its length is 1000, each character is stored in 1 byte, and a total of 1000 bytes (i.e. 8000 bits) are required. If each character is represented by 2-bit binary, 1000 characters can be represented by 2000 bit space. In addition, we also need a certain space to store the code table, which can adopt the following storage format:
Number of symbols, code 1, symbol 1, code 2, symbol 2···The number of symbols and each symbol occupy 8 bits respectively, and each code occupies ⌈ log 2 ( symbol number individual number ) ⌉ \lceil \log_2 {(number of symbols)} \ rceil ⌈ log2 (number of symbols) ⌉ bits. Therefore, the encoding table needs 48 bits in total and the compression ratio is 8000 2048 = 3.9 \frac{8000}{2048}=3.9 20488000=3.9
Using the above encoding method, the encoding of the string aaxuaxz is 0000011000111. Because the code of each character occupies 2 bits. Therefore, from left to right, 2 digits are extracted from the code each time, and the original string can be obtained by compiling the code table.
In the string aaxuaxz, a appears three times. The number of times a symbol appears is called frequency. The frequency of symbols a, u, X and Z in this string is 3, 2, 1 and 1 respectively. When the frequency of different characters is very different, we can shorten the length of the coding string by variable length coding. If coding is used. If the code (0=a, 10=x, 110=u, 111=z) is used, the code of the symbol string is 00101100111, and the length of the code string is 13 bits, which is slightly shorter than the original 14 bits. When the occurrence frequency of different characters is more different, the length difference of coding string will be more obvious.
So how to decode it? The encoding of the string aaxuaxz is 00101100111. When decoding from left to right, we need to know whether the code of the first character is 0, 00 or 001. Because no code of a character starts with 00, the code of the first character must be 0. According to the encoding table, the character is a. The next code is 0, 01 or 010. Similarly, because there is no code starting with 01, the code must be 0. Continue to use this method to decode. This decoding can be realized because no code is the prefix of another code.
2. Extended binary tree and Huffman coding
We can use the extended binary tree to derive a special class to realize variable length coding for the code with the above prefix properties. In an extended binary tree, the path from the root to the external node can be encoded by using 0 to represent the path to the left subtree and 1 to represent the path to the right subtree.
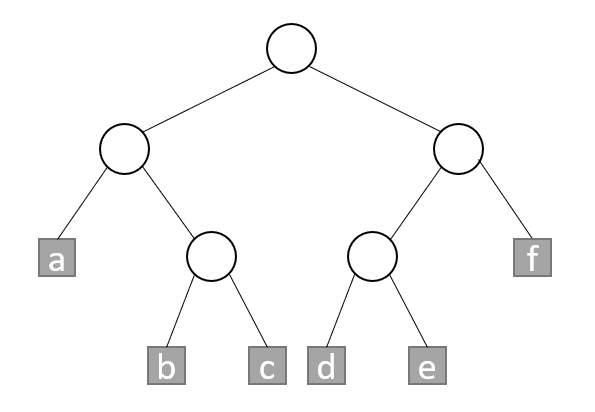
As shown in the figure, the paths from the root to the nodes (a, b, c, d, e, f) are (00010011100101, 11) respectively. Because each path corresponds to an external node, and the external nodes are independent of each other, no path code is the prefix of another. Therefore, these codes can be used to encode characters a~f respectively. Let S be a string of these characters,
F
(
x
)
F(x)
F(x) is the frequency at which the character x appears. If S is encoded with these codes, the length of the encoded bit string:
2
∗
F
(
a
)
+
3
∗
F
(
b
)
+
3
∗
F
(
c
)
+
3
∗
F
(
d
)
+
3
∗
F
(
e
)
+
2
∗
F
(
f
)
2*F(a)+3*F(b)+3*F(c)+3*F(d)+3*F(e)+2*F(f)
2∗F(a)+3∗F(b)+3∗F(c)+3∗F(d)+3∗F(e)+2∗F(f)
For an extended binary tree with n external nodes, and the external nodes are marked as 1, ···, N, the length of the corresponding coding bit string is:
W
E
P
=
∑
1
n
L
(
i
)
∗
F
(
i
)
WEP=\sum_1^nL(i)*F(i)
WEP=1∑nL(i)∗F(i)
among
L
(
i
)
L(i)
L(i) represents the path length from the root to the external node i; WEP is the weighted external path length of the binary tree. In order to shorten the length of the string, binary tree code must be used. The external node of the binary tree should correspond to the characters of the encoded string, and the WEP is the smallest. A binary tree is called Huffman tree if its WEP is the smallest for a given set of frequencies.
3. Construction steps
To encode a string with Huffman encoding, you need to do the following:
① Determines the symbols of strings and how often they appear
② A Huffman tree is established, in which the external node is represented by the symbol in the string, and the weight of the external node is represented by the frequency of the corresponding symbol.
③ Traverse the path from the root to the external node to get the code of each symbol.
④ Replace symbols in strings with code.
In order to facilitate decoding, it is necessary to save the mapping table from symbol to code or the frequency table of each symbol. If the frequency table of symbols is saved, the Huffman tree can be reconstructed by using ②.
The process of constructing Hoffman input is: first, a set of binary trees is established. Each binary tree contains only one external node. Each external node represents a symbol of the string, and its weight is equal to the frequency of the symbol. Then, continuously select two binary trees with the least weight from the set, merge them into a new binary tree, add a root node in the merging method, and take the two binary trees as the left and right subtrees respectively. The weight of the new binary tree is the sum of the weights of the two subtrees. This process continues until there is only one binary tree left.

2, Realize
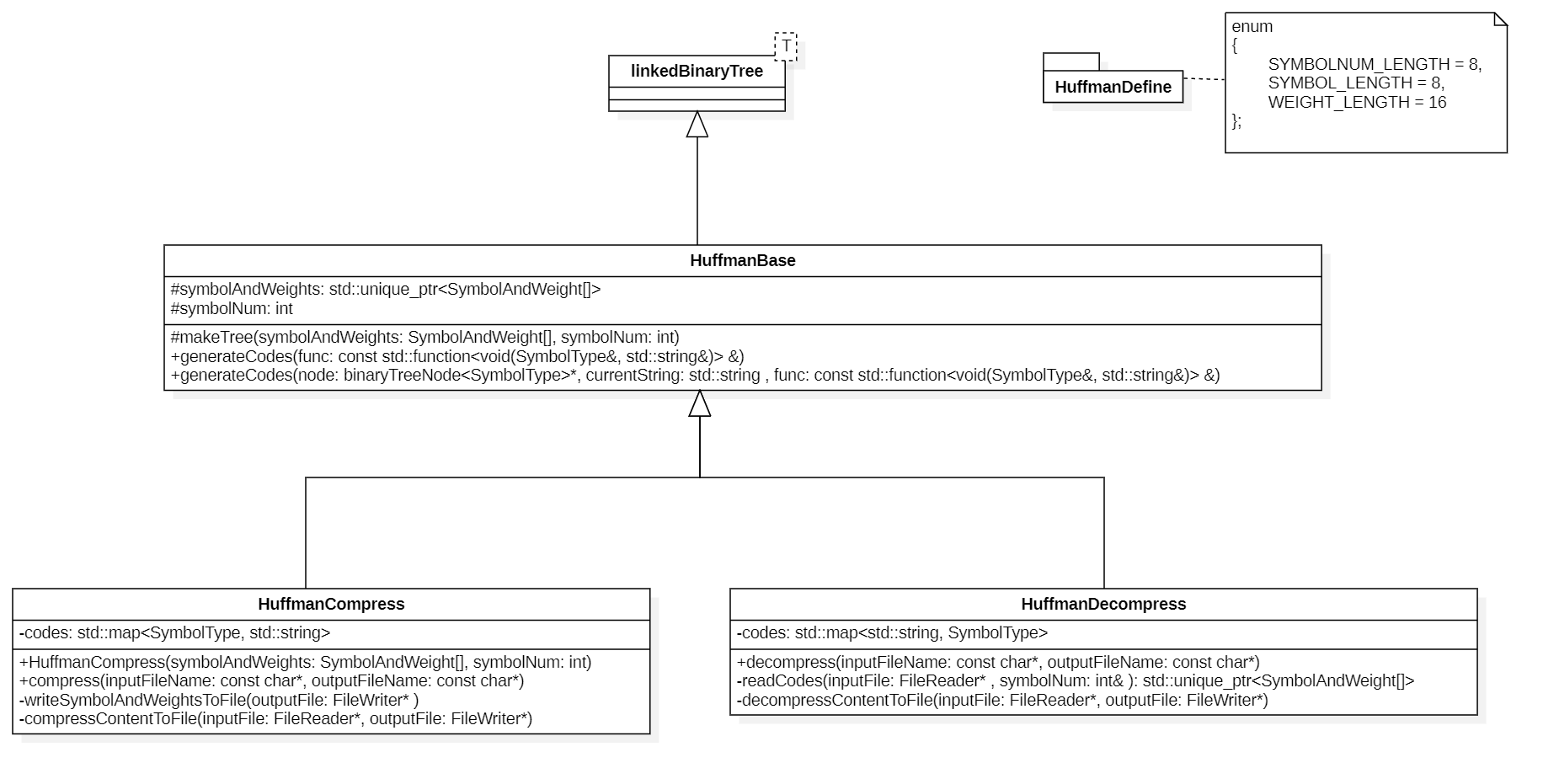
1. Class diagram
After careful analysis, it is not difficult to analyze. Whether it is compression or decompression, the construction process of the tree is exactly the same. The process of generating code mapping relationship between them is also recursive, but the mapping relationship is relative (from character to coding and from coding to character). Therefore, we provide base classes to handle these same operations.
In addition, we choose to use the FileReader and FileWriter previously implemented to handle file reading and writing.
2. Common constants and structures
// HuffmanDefine.h
#pragma once
using SymbolType = unsigned char;
using WeightType = int;
struct SymbolAndWeight
{
SymbolType symbol;
WeightType weight;
};
enum
{
SYMBOLNUM_LENGTH = 8,
SYMBOL_LENGTH = 8,
WEIGHT_LENGTH = 16
};
3. Base class definition
// HuffmanBase.h
#pragma once
#include "HuffmanDefine.h"
#include "../../binaryTree/linkedBinaryTree.h"
#include <map>
#include <memory>
#include <functional>
#include "HuffmanDefine.h"
class HuffmanBase : public linkedBinaryTree<SymbolType>
{
protected:
std::unique_ptr<SymbolAndWeight[]> symbolAndWeights;
int symbolNum;
void makeTree(SymbolAndWeight symbolAndWeights[], int symbolNum);
void generateCodes(const std::function<void(SymbolType&, std::string&)> &func);
void generateCodes(binaryTreeNode<SymbolType>* node, std::string currentString, const std::function<void(SymbolType&, std::string&)> &func);
};
4. Construction of Huffman tree
The Hoffman tree itself is not necessarily a left tall tree or a heap, but we can use the heap to construct the Hoffman tree:
#include "HuffmanBase.h"
#include "../heap.h"
using namespace std;
using TreeType = linkedBinaryTree<SymbolType>;
struct HuffmanNode
{
TreeType* tree;
WeightType weight;
};
void HuffmanBase::makeTree(SymbolAndWeight symbolAndWeights[], int symbolNum)
{
auto pred = [](HuffmanNode& left, HuffmanNode& right) {return left.weight < right.weight; };
heap<HuffmanNode, decltype(pred)> huffmanHeap(symbolNum, pred);
TreeType emptyTree;
for (int i = 0; i < symbolNum; ++i)
{
auto newTree = new TreeType;
newTree->makeTree(symbolAndWeights[i].symbol, emptyTree, emptyTree);
huffmanHeap.push(HuffmanNode{ newTree, symbolAndWeights[i].weight });
}
while (huffmanHeap.size() > 1)
{
auto left = huffmanHeap.top();
huffmanHeap.pop();
auto right = huffmanHeap.top();
huffmanHeap.pop();
auto newTree = new TreeType;
newTree->makeTree(0, *left.tree, *right.tree);
huffmanHeap.push(HuffmanNode{ newTree, left.weight + right.weight });
delete left.tree;
delete right.tree;
}
this->swap(*huffmanHeap.top().tree);
this->symbolAndWeights.reset(new SymbolAndWeight[symbolNum]);
this->symbolNum = symbolNum;
copy(symbolAndWeights, symbolAndWeights + symbolNum, this->symbolAndWeights.get());
}
5. Generate mapping relationship
After generating Huffman tree, we need to generate the mapping relationship between coding and characters. When encoding, we need to map characters into codes; In decoding, we need to map the encoding to characters. Therefore, we give the actual mapping relationship data and its processing function to subclasses (here we can consider using the template method):
void HuffmanBase::generateCodes(const function<void(SymbolType&, string&)>& func)
{
generateCodes(root, "", func);
}
void HuffmanBase::generateCodes(binaryTreeNode<SymbolType>* node, string currentString, const function<void(SymbolType&, string&)> &func)
{
if (node->leftChild == nullptr && node->rightChild == nullptr)
{
func(node->element, currentString);
return;
}
if (node->leftChild != nullptr)
{
generateCodes(node->leftChild, currentString + "0", func);
}
if (node->rightChild != nullptr)
{
generateCodes(node->rightChild, currentString + "1", func);
}
}
6. Compressed class definition
Here, the frequency of each code needs to be provided externally. We save the code and frequency in the file header to reconstruct the Huffman tree.
#pragma once
#include "HuffmanBase.h"
class FileReader;
class FileWriter;
class HuffmanCompress : public HuffmanBase
{
public:
HuffmanCompress(SymbolAndWeight symbolAndWeights[], int symbolNum);
void compress(const char* inputFileName, const char* outputFileName);
private:
std::map<SymbolType, std::string> codes;
void writeSymbolAndWeightsToFile(FileWriter* outputFile);
void compressContentToFile(FileReader* inputFile, FileWriter* outputFile);
};
7. Compression class implementation
#include "HuffmanCompress.h"
#include "../../public/FileHelper/FileReader.h"
#include "../../public/FileHelper/FileWriter.h"
using namespace std;
HuffmanCompress::HuffmanCompress(SymbolAndWeight symbolAndWeights[], int symbolNum)
{
makeTree(symbolAndWeights, symbolNum);
generateCodes([this](SymbolType& symbol, string& code) {this->codes.insert(make_pair(symbol, code));});
}
void HuffmanCompress::compress(const char* inputFileName, const char* outputFileName)
{
FileReader inputFile(inputFileName);
FileWriter outputFile(outputFileName);
writeSymbolAndWeightsToFile(&outputFile);
compressContentToFile(&inputFile, &outputFile);
}
void HuffmanCompress::writeSymbolAndWeightsToFile(FileWriter* outputFile)
{
outputFile->write(symbolNum, SYMBOLNUM_LENGTH);
for (int i = 0; i < symbolNum; ++i) {
outputFile->write(symbolAndWeights[i].symbol, SYMBOL_LENGTH);
outputFile->write(symbolAndWeights[i].weight, WEIGHT_LENGTH);
}
}
void HuffmanCompress::compressContentToFile(FileReader* inputFile, FileWriter* outputFile)
{
int currentChar = 0;
while ((currentChar = inputFile->readChar()) != EOF)
{
auto iter = codes.find(currentChar);
if (iter != codes.end())
{
for (auto& ch : iter->second)
{
outputFile->write(ch - 48, 1);
}
}
}
}
8. Decompress class definition
#pragma once
#include "HuffmanBase.h"
class FileReader;
class FileWriter;
class HuffmanDecompress : public HuffmanBase
{
public:
void decompress(const char* inputFileName, const char* outputFileName);
private:
std::map<std::string, SymbolType> codes;
std::unique_ptr<SymbolAndWeight[]> readCodes(FileReader* inputFile, int& symbolNum);
void decompressContentToFile(FileReader* inputFile, FileWriter* outputFile);
};
9. Decompression class implementation
You should pay attention to the judgment method of reading the last character. Because we only read one bit at a time, we can't pass= EOF judgment. Fortunately, we provided the operator bool earlier to get the flow state.
#include "HuffmanDecompress.h"
#include "../../public/FileHelper/FileReader.h"
#include "../../public/FileHelper/FileWriter.h"
using namespace std;
void HuffmanDecompress::decompress(const char* inputFileName, const char* outputFileName)
{
FileReader inputFile(inputFileName);
FileWriter outputFile(outputFileName);
int symbolNum = 0;
auto symbolAndWeights = readCodes(&inputFile, symbolNum);
makeTree(symbolAndWeights.get(), symbolNum);
generateCodes([this](SymbolType& symbol, string& code) {this->codes.insert(make_pair(code, symbol)); });
decompressContentToFile(&inputFile, &outputFile);
}
unique_ptr<SymbolAndWeight[]> HuffmanDecompress::readCodes(FileReader* inputFile, int &symbolNum)
{
symbolNum = inputFile->read(SYMBOLNUM_LENGTH);
unique_ptr<SymbolAndWeight[]> symbolAndWeights(new SymbolAndWeight[symbolNum]);
for (int i = 0; i < symbolNum; ++i) {
symbolAndWeights[i].symbol = inputFile->read(SYMBOL_LENGTH);
symbolAndWeights[i].weight = inputFile->read(WEIGHT_LENGTH);
}
return symbolAndWeights;
}
void HuffmanDecompress::decompressContentToFile(FileReader* inputFile, FileWriter* outputFile)
{
auto currentNode = this->root;
int currentBit = 0;
string currentCode = "";
while (1)
{
currentBit = inputFile->read(1);
if (!*inputFile)
{
break;
}
if (currentBit == 0)
{
currentNode = currentNode->leftChild;
currentCode += "0";
}
else
{
currentNode = currentNode->rightChild;
currentCode += "1";
}
if (currentNode->leftChild == nullptr && currentNode->rightChild == nullptr)
{
currentNode = root;
outputFile->write(codes.find(currentCode)->second, sizeof(SymbolType) * CHAR_BIT);
currentCode = "";
}
}
}
10. Modification of FileReader
FileReader has a small problem. When reading data from a file to fill the buffer and output, it uses the wrong length. Since the previous LZW code unfilledLength is 4 bits, that is, unfilledLength = fileBuffer.getMaxBufferSize() - unfilledLength, this problem does not occur.
void FileReader::readDataAndFillBuffer(long& data, int unfilledLength)
{
if (unfilledLength > 0)
{
unsigned char ch = inputFileStream.get();
// wrong
// data += (ch >> unfilledLength);
// right
data += (ch >> (fileBuffer.getMaxBufferSize() - unfilledLength));
auto restLength = fileBuffer.getMaxBufferSize() - unfilledLength;
fileBuffer.AppendDataToBuffer(getLowBitsOfData(ch, restLength), restLength);
}
}
11. Test code
#pragma once
#include "HuffmanCompress.h"
#include "HuffmanDecompress.h"
#include <iostream>
#include <map>
#include <fstream>
#include <memory>
#include <tuple>
using namespace std;
unique_ptr<SymbolAndWeight[]> getSymbolFreq(const char* fileName, int &codesNum)
{
ifstream ifs(fileName);
if (!ifs.is_open())
{
cerr << "file " << fileName << " cann't open" << endl;
exit(0);
}
int allChars[256] = { 0 };
int currentChar = 0;
while ((currentChar = ifs.get()) != EOF)
{
allChars[currentChar]++;
}
ifs.close();
unique_ptr<SymbolAndWeight[]> codes(new SymbolAndWeight[256]);
int indexOfCode = 0;
codesNum = 0;
for (int i = 0; i < 256; ++i)
{
if (allChars[i] != 0)
{
codesNum++;
codes[indexOfCode++] = { (SymbolType)i, allChars[i] };
}
}
return codes;
}
void test()
{
int codesNum;
auto codes = getSymbolFreq("input.txt", codesNum);
HuffmanCompress compress(codes.get(), codesNum);
compress.compress("input.txt", "input.huffman");
HuffmanDecompress decompress;
decompress.decompress("input.huffman", "output.txt");
}

12. Summary
Compared with Huffman coding and LZW coding, it is not difficult to find that they will be better if combined. Huffman coding pays more attention to the occurrence frequency of a single character, but ignores the repetition frequency of words (continuous characters); LZW encoding considers the occurrence of continuous characters and uses the same encoding method for them, but its encoding length completely depends on the order of string occurrence rather than frequency.
In addition, Hoffman coding has another problem: the implementation of the above compression rate comes from two scans of the file, which will lead to too long compression time.