In any Automatic speech recognition system, the first step is to extract the features. In other words, we need to extract the identifiable components of the audio signal and throw away other messy information, such as background noise, mood, etc.
Understanding how speech is produced is very helpful for us to understand speech. People produce sound through the vocal channels, and the shape of the channels.The shape of the vocal channel includes the tongue, teeth, etc. If we know this shape accurately, then we can accurately describe the phoneme produced. The shape of the vocal channel is shown in the envelope of the short-term power spectrum of the speech. MFCCs are a feature that accurately describes this envelope.
MFCCs (Mel Frequency Cepstral Coefficents) are a feature that is widely used in automatic speech and speaker recognition. It was invented by Davis and Memelstein in 1980. Since then, MFCCs have stood out from the crowd in terms of artificial features in speech recognition. They have never been surpassed.(As for Deep Learning's feature learning, that's later).
Well, here we have mentioned a very important keyword: the shape of the channel, and then know that it is important, and that it can be displayed in the envelope of the short-term power spectrum of speech. Alas, what is the power spectrum? What is the envelope? What is MFCCs? Why is it effective? How? Let's move on.
1. Spectrogram
We process voice signals, so how to describe them is important. Because different descriptions show different information. What descriptions are useful for our observation and understanding? Let's first learn about what is called a spectrogram.
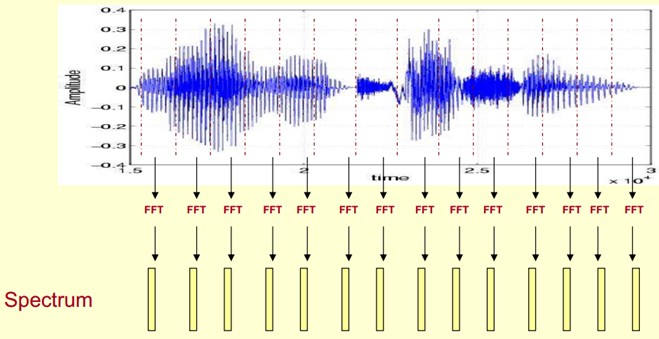
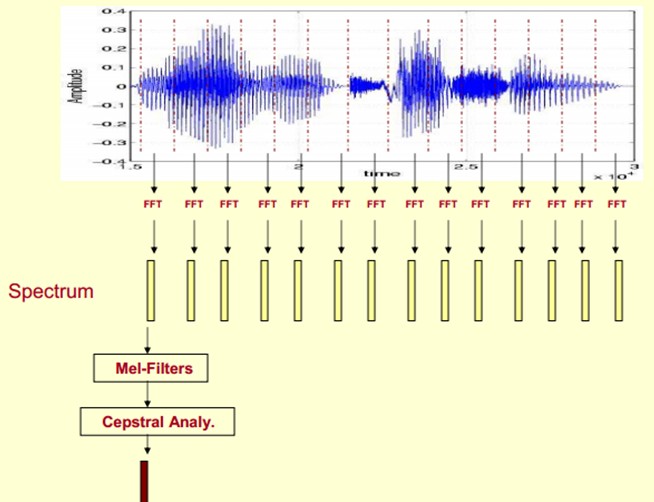
Here, the voice is divided into many frames, each corresponding to a spectrum (calculated by short-term FFT), which represents the relationship between frequency and energy. In practice, there are three kinds of spectrum graphs: linear, logarithmic and self-power (the amplitudes of each line in the logarithmic spectrum are logarithmically calculated, so the units of their vertical coordinates are dB.(dB). The purpose of this transformation is to make those components with lower amplitudes higher than those with higher amplitudes so as to observe the periodic signal masked by low amplitude noise.
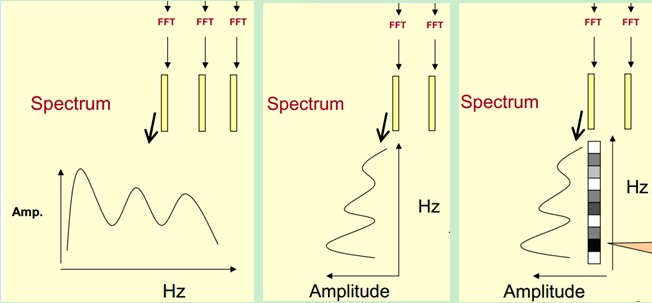
First, we show the spectrum of one of the frames by coordinates, such as the left of the picture above. Now we rotate the spectrum on the left by 90 degrees. We get the middle picture. Then we map these ranges to a gray level representation (which can also be interpreted as quantifying 256 consecutive ranges?)0 is black, 255 is white. The larger the amplitude value, the darker the corresponding area. This gives you the right-most picture. Why? To increase the dimension of time, so that you can display the frequency of a voice instead of a frame, and you can visually see the static and dynamic information. The advantages will be shown later.
This gives us a spectrogram of the voice signal that changes over time.
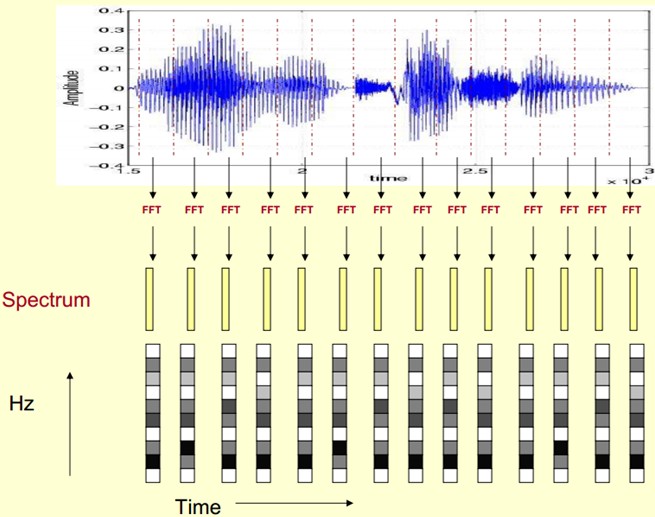
The picture below is a spectrogram of a speech. The dark part is the peak (formants) in the spectrogram.
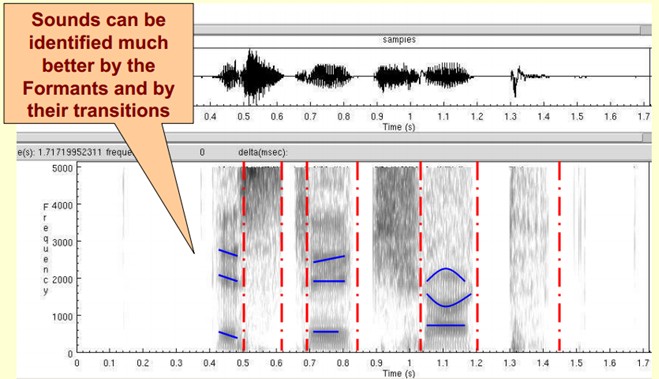
Why do we need to represent speech in spectrograms?
First, the properties of phonemes can be better observed here. In addition, sound can be better recognized by observing the resonance peaks and their transitions. Hidden Markov Models implicitly model the sound spectrum to achieve good recognition performance. Another effect is that it can visually evaluate TTS systems.text to speech can be directly compared with the matching degree of the synthesized speech and the natural speech spectrogram.
| By subframe time-frequency transformation of the voice, the FFT spectrum of each frame is obtained, and then the FFT spectrum of each frame is arranged in time order to get the time-frequency-energy distribution map. It is very intuitive to show the change of the voice signal frequency center over time. |
2. Cepstrum Analysis
Below is a spectrum of the voice. Peaks represent the main frequency components of the voice. We call these peaks formants, which carry the identification attributes of the voice (just like a personal identification card). So it is particularly important. Use it to recognize different sounds.
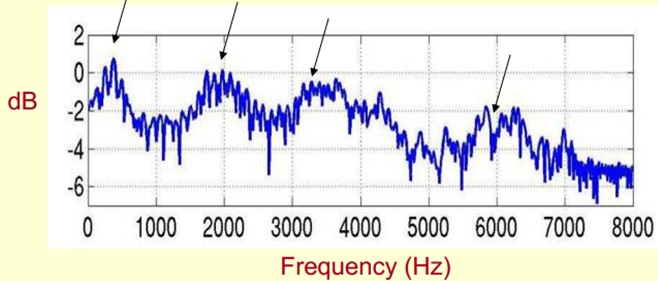
Since it's so important, we need to extract it! We need to extract not only the location of the resonance peaks, but also the process of their transformation. So we extract the envelope of the spectrum (Spectral Envelope). This envelope is a smooth curve connecting these resonance peaks.
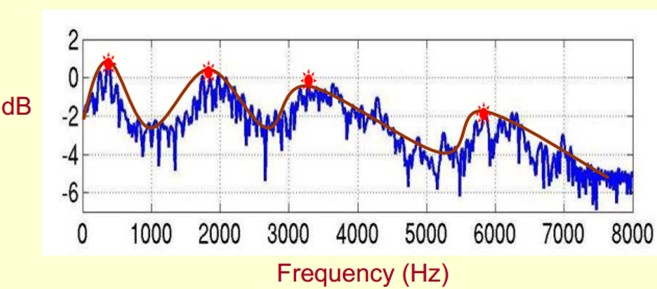
You can understand that the original spectrum consists of two parts: the envelope and the details of the spectrum. The logarithmic spectrum is used here, so the unit is dB. Now we need to separate the two parts so that we can get the envelope.
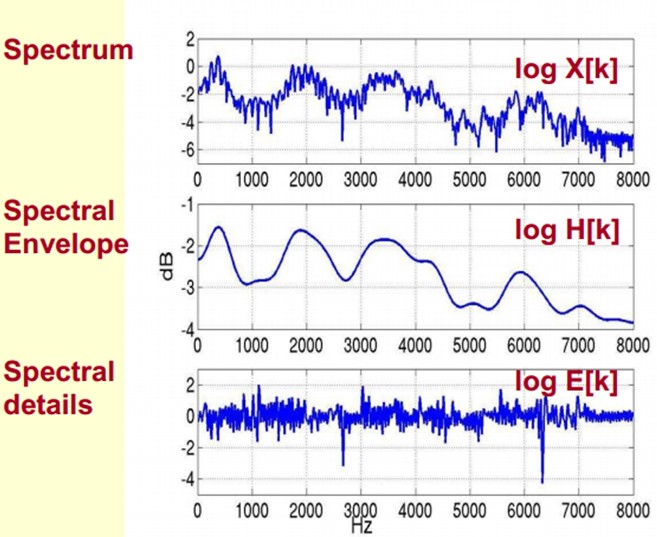
How do you separate them? That is, how do you get log H[k] and log E[k] on the basis of a given log X[k] to satisfy log X[k] = log H[k] + log E[k]?
To achieve this goal, we need a Play a Mathematical Trick. What is this Trick? It is to do FFT on the spectrum. Making a Fourier transform on the spectrum is equivalent to Inverse FFT (IFFT) In this case, IFFT on the logarithmic spectrum is equivalent to describing the signal on a pseudo-frequency axis.
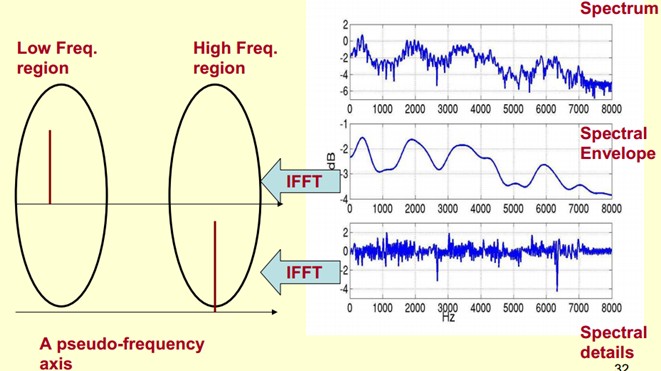
As we can see from the graph above, envelopes are mainly low frequency components (at this time, thinking needs to be changed, then the horizontal axis should not be considered frequency, let's see time)We think of it as a sinusoidal signal with four cycles per second. So we give it a peak at 4Hz above the pseudo-axis. The details of the spectrum are mainly high frequencies. We think of it as a sinusoidal signal with 100 cycles per second. So we give it a peak at 100Hz above the pseudo-axis.
Add them together and they will be the original spectrum signal.
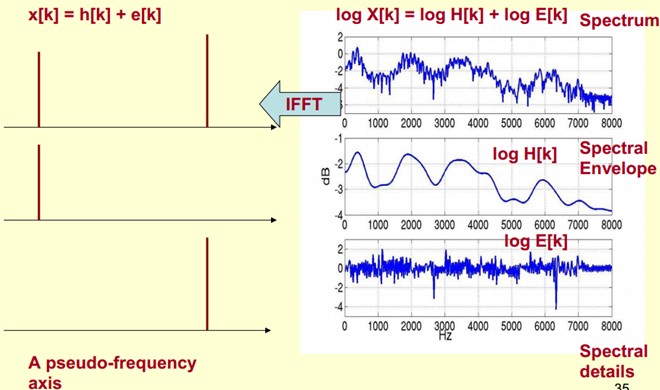
In practice, we already know log X[k], so we can get x[k]. So as the graph shows, h[k] is the low frequency part of x[k], so we can get h[k] by using a low-pass filter. Yes, here we can separate them and get the envelope of the spectrum we want, h[k].
x[k] is essentially a Cepstrum (a newly coined word that inverts the first four letters of the spectrum word spectrum to the reverse). What we care about is h[k], which is the low-frequency part of the spectrum. h[k] describes the envelope of the spectrum and is widely used to describe features in speech recognition.
Now summarizing the cepstrum analysis, it is actually a process:
1) The original speech signal is transformed by Fourier transform to get the spectrum: X[k]=H[k]E[k];
Consider only the extent: |X[k] |=|H[k]||E[k] |;
2) We take logarithms on both sides: log||X[k] |= log ||H[k] |+ log |||E[k] ||.
3) The inverse Fourier transform is obtained on both sides: x[k]=h[k]+e[k].
In fact, there is a professional name called homologous signal processing. Its purpose is to transform the non-linear problem into a linear problem solving method. Correspondingly, the original voice signal is actually a convoluted signal (the channel is equivalent to a linear time-invariant system, and the sound generation can be understood as an excitation passing through the system).The first step converts the multiplicative signal into a multiplicative signal by convolution (the convolution of time domain equals the product of frequency domain). The second step converts the multiplicative signal into an additive signal by logarithm, and the third step performs an inverse transformation to restore it to a convolutional signal. At this time, although the front and back are time domain sequences, they are in distinct discrete time domains, so the latter is called the inverse frequency domain.
In summary, cepstrum is the spectrum of a signal after its Fourier transformation has been logarithmically computed and then its inverse Fourier transformation is computed as follows:

The following sections have not been sorted out yet
3. Mel Frequency Analysis
Well, here, let's first see what we've just done? Give us a piece of speech and we can get its spectral envelope (a smooth curve connecting all the resonance peaks). But experiments on human auditory perception show that human auditory perception focuses only on certain areas, not on the entire spectral envelope.
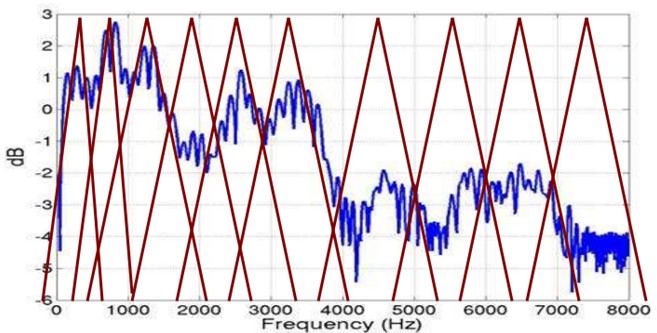
Mel frequency analysis is based on human auditory perception experiments. Experimental observations show that the human ear acts like a filter bank, focusing only on certain frequency components (human hearing is selective for frequency).In other words, it only passes signals of certain frequencies, which it does not want to perceive at all. However, these filters are not uniformly distributed on the frequency axis. There are many filters in the low frequency area, which are more densely distributed, but in the high frequency area, the number of filters becomes less and the distribution is sparse.
The human auditory system is a special non-linear system, which responds to different frequency signals with different sensitivity. The human auditory system does a good job in extracting speech features. It can not only extract semantic information.Moreover, it can extract the speaker's personal characteristics, which are beyond the expectations of existing speech recognition systems. If speech recognition systems can simulate human auditory perception processing features, it is possible to improve speech recognition rate.
The Mel Frequency Cepstrum Coefficient (MFCC) takes into account human auditory characteristics by mapping the linear spectrum to the non-linear spectrum of Mel based on auditory perception and then converting it to the cepstrum.
The formula for converting normal frequencies to Mel frequencies is:
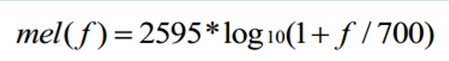
As you can see from the figure below, it can convert non-uniform frequencies into uniform frequencies, that is, uniform filter banks.
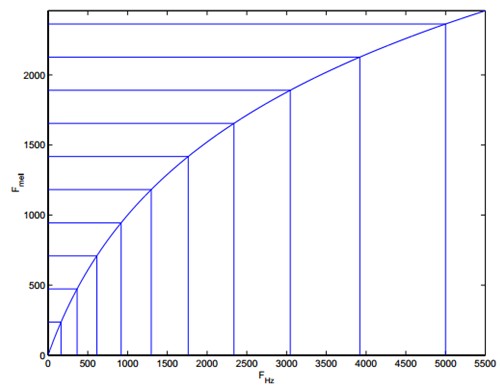
Within the Mel frequency domain, there is a linear relationship between people's perception of tones. For example, if the Mel frequencies of two voices differ by two times, the human ear sounds twice as different as the tones of the two voices.
4. Mel Frequency Cepstral Coefficients
The Mel spectrum is obtained by passing the spectrum through a set of Mel filters. The formula is: log X[k] = log (Mel-Spectrum). At this time we perform a cepstrum analysis on log X[k]:
1) Logarithm: log X[k] = log H[k] + log E[k].
2) Inverse transformation: x[k] = h[k] + e[k].
The cepstrum coefficient h[k] obtained on the Mel spectrum is called the Mel frequency cepstrum coefficient, or MFCC for short.
Now let's summarize the process of extracting MFCC features: (There are too many specific mathematical processes online, so don't want to post them here)
1) Pre-emphasis, framing and windowing of the voice first; (Enhance some pre-processing of voice signal performance (signal-to-noise ratio, processing accuracy, etc.)
2) For each short analysis window, the corresponding frequency spectrum is obtained by FFT; (The frequency spectrum distributed in different time windows on the time axis is obtained)
3) Mel spectrum is obtained from the above spectrum through a Mel filter bank; (Mel spectrum is used to convert the linear natural spectrum into the Mel spectrum which reflects human auditory characteristics)
4) Perform cepstrum analysis on the Mel spectrum (take logarithm, do inverse transformation, the actual inverse transformation is generally achieved by DCT discrete cosine transformation, take the second to 13th coefficients after DCT as MFCC coefficients), and obtain Mel frequency cepstrum coefficient MFCC, which is the feature of this frame of speech; (cepstrum analysis, get MFCC as speech feature)
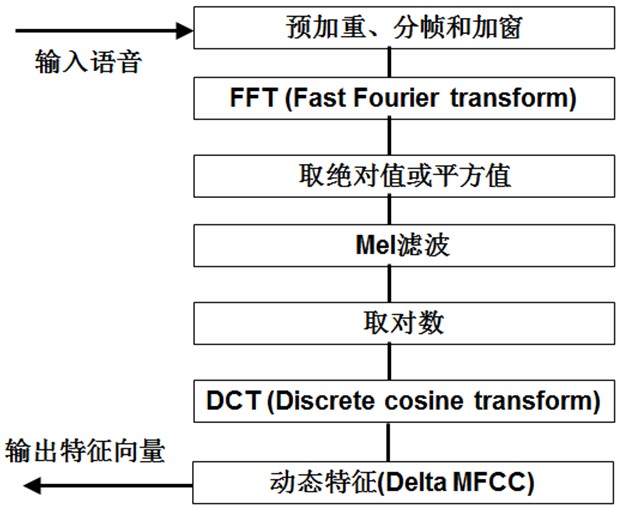
At this point, the voice can be described by a series of cepstrum vectors, each of which is the MFCC eigenvector of each frame.
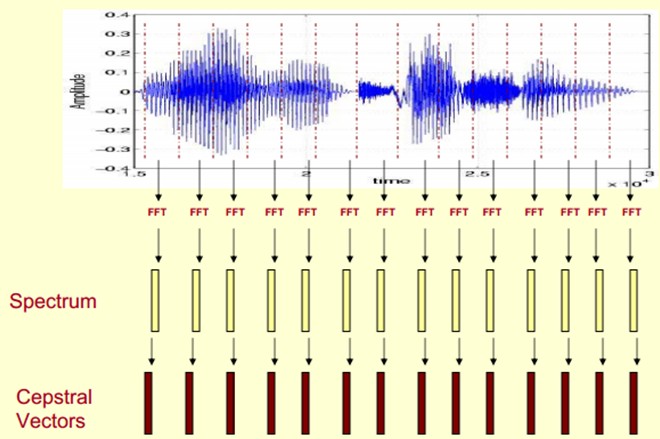
This allows the speech classifier to be trained and recognized using these cepstrum vectors.
5. References
[1] There is also a good tutorial here:
[2] This paper mainly refers to: cmu's tutorial:
http://www.speech.cs.cmu.edu/15-492/slides/03_mfcc.pdf
[3] C library for computing Mel Frequency Cepstral Coefficients (MFCC)
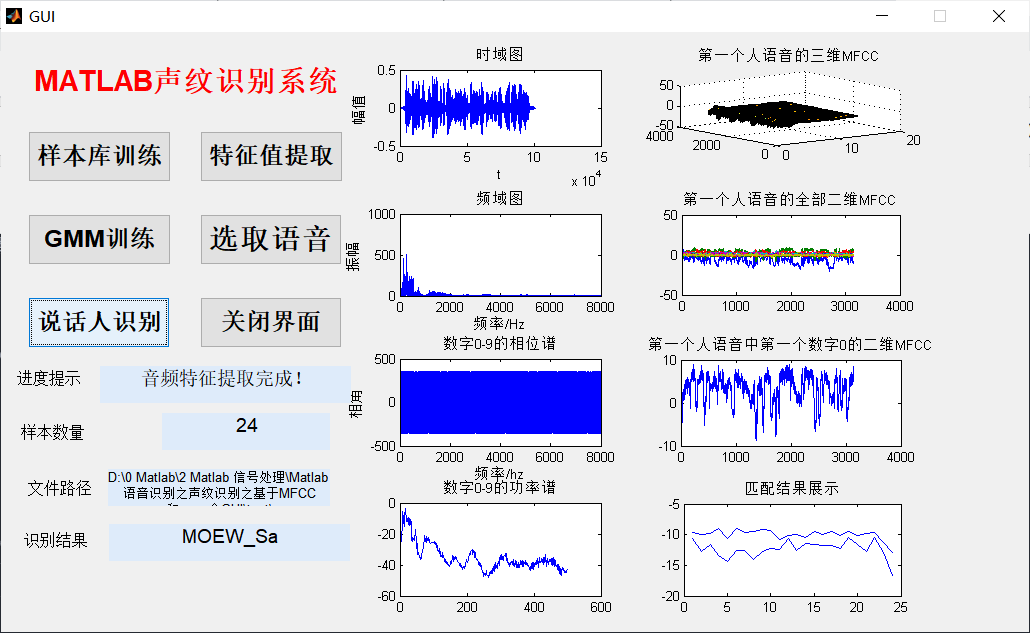
function varargout = GUI(varargin)
% GUI MATLAB code for GUI.fig
% GUI, by itself, creates a new GUI or raises the existing
% singleton*.
%
% H = GUI returns the handle to a new GUI or the handle to
% the existing singleton*.
%
% GUI('CALLBACK',hObject,eventData,handles,...) calls the local
% function named CALLBACK in GUI.M with the given input arguments.
%
% GUI('Property','Value',...) creates a new GUI or raises the
% existing singleton*. Starting from the left, property value pairs are
% applied to the GUI before GUI_OpeningFcn gets called. An
% unrecognized property name or invalid value makes property application
% stop. All inputs are passed to GUI_OpeningFcn via varargin.
%
% *See GUI Options on GUIDE's Tools menu. Choose "GUI allows only one
% instance to run (singleton)".
%
% See also: GUIDE, GUIDATA, GUIHANDLES
% Edit the above text to modify the response to help GUI
% Last Modified by GUIDE v2.5 15-Mar-2020 17:37:45
% Begin initialization code - DO NOT EDIT
gui_Singleton = 1;
gui_State = struct('gui_Name', mfilename, ...
'gui_Singleton', gui_Singleton, ...
'gui_OpeningFcn', @GUI_OpeningFcn, ...
'gui_OutputFcn', @GUI_OutputFcn, ...
'gui_LayoutFcn', [] , ...
'gui_Callback', []);
if nargin && ischar(varargin{1})
gui_State.gui_Callback = str2func(varargin{1});
end
if nargout
[varargout{1:nargout}] = gui_mainfcn(gui_State, varargin{:});
else
gui_mainfcn(gui_State, varargin{:});
end
% End initialization code - DO NOT EDIT
% --- Executes just before GUI is made visible.
function GUI_OpeningFcn(hObject, eventdata, handles, varargin)
% This function has no output args, see OutputFcn.
% hObject handle to figure
% eventdata reserved - to be defined in a future version of MATLAB
% handles structure with handles and user data (see GUIDATA)
% varargin command line arguments to GUI (see VARARGIN)
% Choose default command line output for GUI
handles.output = hObject;
% Update handles structure
guidata(hObject, handles);
% UIWAIT makes GUI wait for user response (see UIRESUME)
% uiwait(handles.figure1);
% --- Outputs from this function are returned to the command line.
function varargout = GUI_OutputFcn(hObject, eventdata, handles)
% varargout cell array for returning output args (see VARARGOUT);
% hObject handle to figure
% eventdata reserved - to be defined in a future version of MATLAB
% handles structure with handles and user data (see GUIDATA)
% Get default command line output from handles structure
varargout{1} = handles.output;
% --- Executes on button press in pushbutton1.
function pushbutton1_Callback(hObject, eventdata, handles)
fprintf('\n Identifying...\n\n');
%Load trained GMM Model
load speakerData;
load speakerGmm;
waveDir='trainning\'; %Import Test Set
Test_speakerData = dir(waveDir); %Get the structure data in the test set, which is char Structures of type
Test_speakerData(1:2) = [];
Test_speakerNum=length(Test_speakerData);
Test_speakerNum
count=0;
%%%%%%%%%%%%%%%%for i=1:Test_speakerNum
%%%Read Voice
[filename,filepath]=uigetfile('*.wav','Select Audio File');
set(handles.text1,'string',filepath)
filep=strcat(filepath,filename);
[testing_data, fs]=wavread(filep);
sound(testing_data, fs);
save testing_data
load testing_data
y=testing_data
axes(handles.axes1)
plot(y);
xlabel('t');ylabel('amplitude');
title('Time Domain Diagram');
%frequency domain
%Amplitude-frequency map
N=length(y);
fs1=100; %sampling frequency
n=0:N-1;
t=n/fs; %time series
yfft =fft(y,N);
mag=abs(yfft); %Absolute value of amplitude
f=n*fs/N; %Frequency Sequence
axes(handles.axes2)
plot(f(1:N/2),mag(1:N/2)); %draw Nyquist Amplitude varying with frequency before frequency
xlabel('frequency/Hz');
ylabel('amplitude');title('Frequency domain diagram');
%Phase spectrum
A=abs(yfft);
ph=2*angle(yfft(1:N/2));
ph=ph*180/pi;
axes(handles.axes3);
plot(f(1:N/2),ph(1:N/2));
xlabel('frequency/hz'),ylabel('phase angle'),title('Number 0-9 Phase spectrum');
% Draw power spectrum
Fs=1000;
n=0:1/Fs:1;
xn=y;
nfft=1024;
window=boxcar(length(n)); %Rectangular window
noverlap=0; %No data overlap
p=0.9; %Confidence probability
[Pxx,Pxxc]=psd(xn,nfft,Fs,window,noverlap,p);
index=0:round(nfft/2-1);
k=index*Fs/nfft;
plot_Pxx=10*log10(Pxx(index+1));
plot_Pxxc=10*log10(Pxxc(index+1));
axes(handles.axes4)
plot(k,plot_Pxx);
title('Number 0-9 The power spectrum of');
axes(handles.axes5)
surf( speakerData(1).mfcc); %Draw MFCC 3-D Graph
title('The three-dimensional representation of the first person's voice MFCC'); %What the first person said mfcc Features mfcc Refers to the Meier cepstrum coefficient
%Draw the first person's MFCC All 2-D Charts
axes(handles.axes6)
plot(speakerData(1).mfcc);
title('All two dimensions of the first person's voice MFCC');
%Draw a feature to see the effect
axes(handles.axes7)
plot(speakerData(1).mfcc(:,2));
title('Two-dimensional of the first digit 0 in the first person's voice MFCC');
% hObject handle to pushbutton1 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles structure with handles and user data (see GUIDATA)
% --- Executes on button press in pushbutton2.
function pushbutton2_Callback(hObject, eventdata, handles)
load testing_data
load speakerGmm
match= MFCC_feature_compare(testing_data,speakerGmm);
axes(handles.axes8)
plot(match);
hold on
title('Match Result Display');
[max_1 index]=max(match);
fprintf('\n %s',match);
fprintf('\n\n\n The speaker is%s. ',speakerData(index).name(1:end-4))
set(handles.text3,'string',speakerData(index).name(1:end-4))
if index==i
count=count+1;
end
% hObject handle to pushbutton2 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles structure with handles and user data (see GUIDATA)
% --- Executes on button press in pushbutton3.
function pushbutton3_Callback(hObject, eventdata, handles)
waveDir = uigetdir(strcat(matlabroot,'\work'), 'Select Training Audio Library' );
set(handles.text8,'string','Sample library selection complete!')
speakerData = dir(waveDir); % Get the structure data in the test set, which is char Structures of type
speakerData(1:2) = [];
speakerNum=length(speakerData);%Number of people tested;
set(handles.text6,'string',speakerNum)
save speakerNum
% hObject handle to pushbutton3 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles structure with handles and user data (see GUIDATA)
% --- Executes on button press in pushbutton4.
function pushbutton4_Callback(hObject, eventdata, handles)
load speakerNum
set(handles.text8,'string','Audio file feature extraction is in progress.')
pause(1) %Stay for one second
for i=1:speakerNum
fprintf('\n Extracting #%d personal%s Features', i, speakerData(i,1).name(1:end-4));
[y, fs]=wavread(['trainning\' speakerData(i,1).name]); %Read sample audio data
y=double(y); %Type Conversion
y=y/max(y);
epInSampleIndex = epdByVol(y, fs); % Endpoint Detection
y=y(epInSampleIndex(1):epInSampleIndex(2)); % Eliminate noise
speakerData(i).mfcc=melcepst(y,8000);
end
set(handles.text8,'string','Audio feature extraction complete!')
save speakerData speakerData % Save data
% hObject handle to pushbutton4 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles structure with handles and user data (see GUIDATA)
% --- Executes on button press in pushbutton5.
function pushbutton5_Callback(hObject, eventdata, handles)
%GMM train
fprintf('\n A Gaussian mixture model for training each speaker...\n\n');
load speakerData.mat
gaussianNum=12;
speakerNum=length(speakerData); %Get Number of Samples
for i=1:speakerNum
fprintf('\n For%d Individual speaker%s train GMM......', i,speakerData(i).name(1:end-4));
[speakerGmm(i).mu, speakerGmm(i).sigm,speakerGmm(i).c] = gmm_estimate(speakerData(i).mfcc(:,5:12)',gaussianNum,20); %Correct transposition
end
fprintf('\n');
save speakerGmm speakerGmm; %Save Samples GMM
% hObject handle to pushbutton5 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles structure with handles and user data (see GUIDATA)
% --- Executes on button press in pushbutton6.
function pushbutton6_Callback(hObject, eventdata, handles)
clc
close all
% hObject handle to pushbutton6 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles structure with handles and user data (see GUIDATA)