Deep learning image classification (XVIII) detailed explanation of Vision Transformer(ViT) network
In the previous section, we talked about the self attention structure in Transformer. In this section, learn the detailed explanation of Vision Transformer(vit). Learning video from Bilibili , refer to blog Detailed explanation of Vision Transformer.

1. Preface
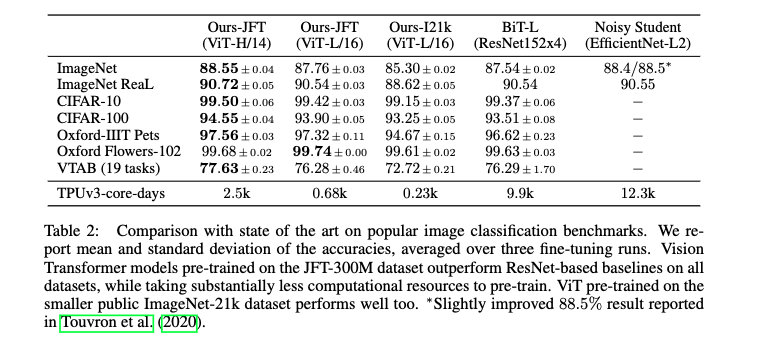
ViT's original paper is An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale . First, let's take a look at the effect of the ViT model. The highest accuracy of 88.55 can be achieved on ImageNet 1k. The key is that we have conducted pre training on our own data set, with a volume of 300 million data.
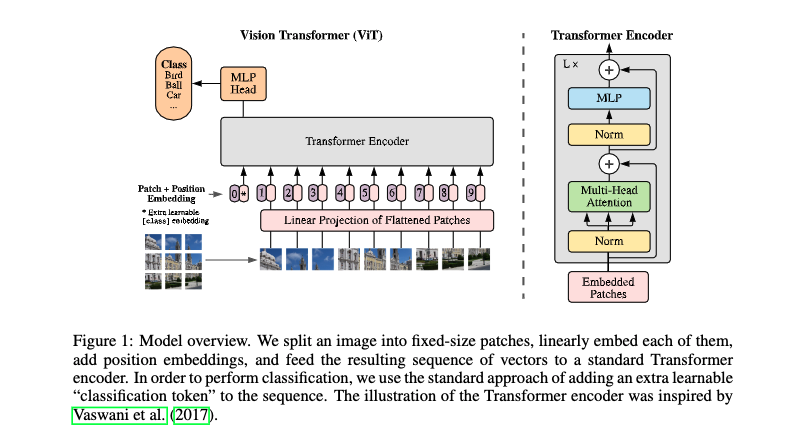
2. ViT model architecture
The original architecture is shown as follows. First, the input image is divided into many patches, 16 in the paper. Input the patch into the Embedding layer of Linear Projection of Flattened Patches, and you will get vectors, usually called tokens. Next, a new token is added in front of a series of tokens (the category token is a bit like the START input to the Transformer Decoder, which corresponds to the * position). In addition, the location information needs to be added, corresponding to 0 ~ 9. Then input it into Transformer Encoder, and stack the block s L times corresponding to the figure on the right. Transformer Encoder has as many outputs as there are inputs. Finally, only classification is performed, so the output corresponding to the class position is input into MLP Head for prediction and classification output.
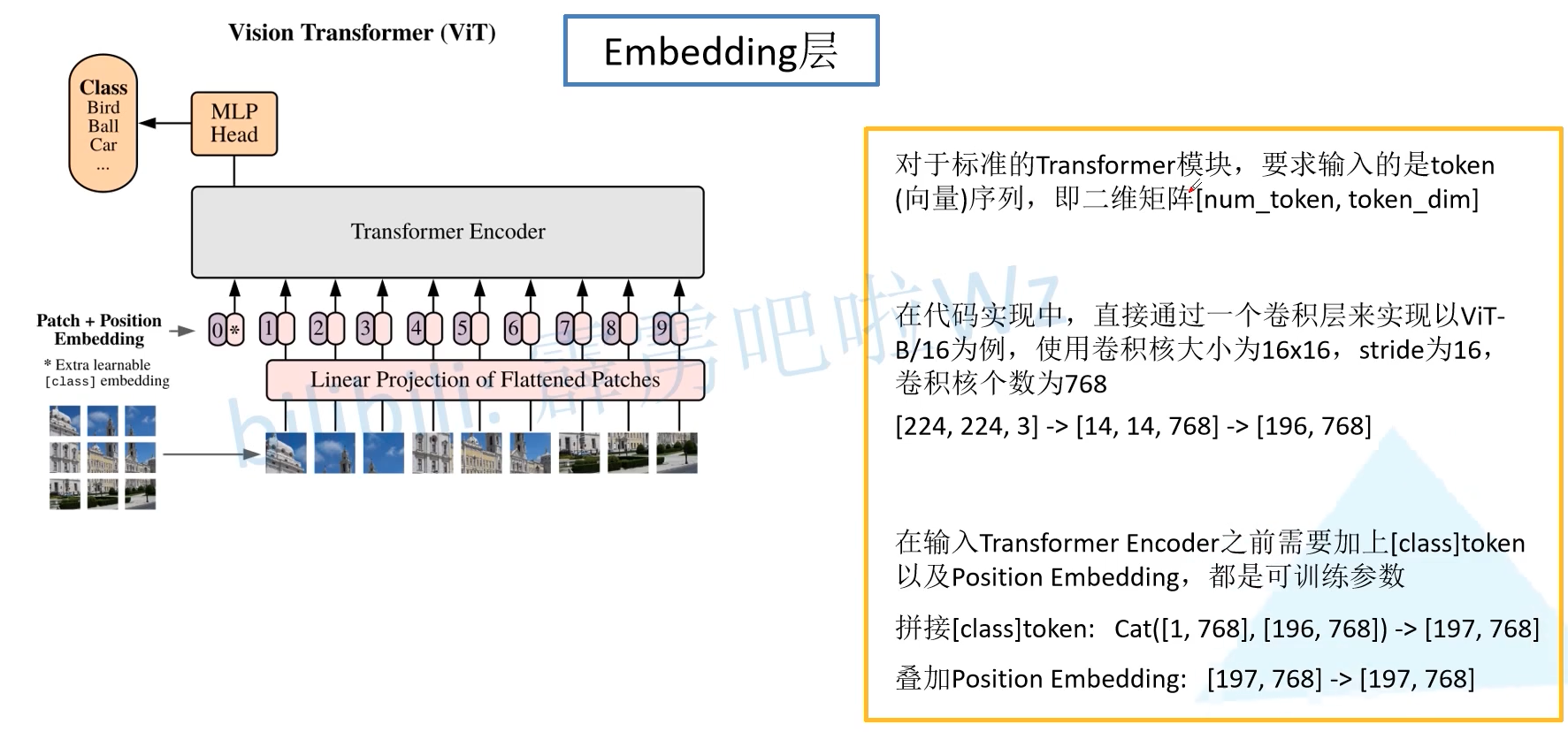
2.1 Embedding layer
Next, let's talk about each module in detail. The first is the Embedding layer. For the standard Transformer module, the required input is the sequence of token vectors, that is, two-dimensional matrix [num_token, token_dim]. In the specific code implementation process, we actually implement it through a convolution layer. Taking ViT-B/16 as an example, the convolution kernel size is 16 × 16 16 \times 16 sixteen × 16. The stripe is 16 and the number of convolution cores is 768, that is [224,3] -- > [14,14768] -- > [196,768]. That is, there are 196 tokens in total, and the length of each token vector is 768. In addition, we also need to add a category of token. Therefore, we actually initialize a trainable parameter [1, 768] and splice it with the token sequence to obtain cat ([1, 768], [196768]) -- > [197, 768]. Then superimpose the position code position embedding: [197768] -- > [197, 768].
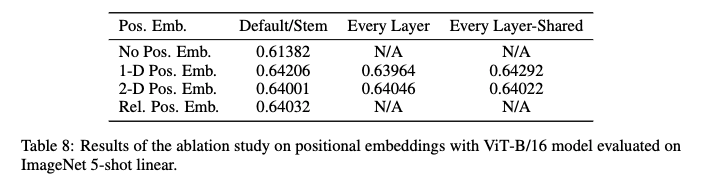
Let's consider Position Embedding in detail. If Position Embedding is not used, the result is 0.61382, and the result using one-dimensional position coding is 0.64206, which is obviously three percentage points higher than that without position coding. Using 2D and relative position coding is actually similar to 1D. It is also mentioned in the paper that the difference in how to encoder spatial information is less important, that is, the difference in location coding is not particularly important. 1D is simple, effective and has few parameters, so 1D position coding is used by default.
In this paper, we give such a graph, and the cosine similarity between the position codes we train and other position codes. The size of the patches here is 32 × 32 32 \times 32 thirty-two × 32, 224 / 32 = 7 224/32=7 224 / 32 = 7, so the size here is 7 × 7 7 \times 7 seven × 7. How do you understand this picture? We will superimpose a location code on each token. Of the 49 small graphs in the middle, each small graph is actually the same 7 × 7 7 \times 7 seven × 7. The position code of the first patch on the first line in the upper left corner is the same as its own position code, so the cosine similarity is 1, so the upper left corner is yellow. Then it is calculated with other location codes. You get the small picture in the upper left corner. Others are similar laws. Note that this is learned.

2.2 Transformer Encoder layer
Transformer Encoder is to stack encoder blocks L times repeatedly. Let's look at a single Encoder Block. First, input a normal layer, where normal refers to the Layer Normalization layer (some papers have compared why BN is not good in the transformer, not as good as ln | here, normal and then Multihead Attention are also studied in some papers. The original transformer first Attention and then normal. In addition, this normal before operation is the same as DenseNet's BN before Conv). After LN, it passes through multi head Attention, and then the source code passes through the Dropout layer. Some reappearance gods use the DropPath method. According to previous experience, it may be better to use the latter. Then, the residual can pass through LN, MLP Block, Dropout/DropPath.
MLP Block is also very simple. It is a full connection, GELU activation function, Dropout, full connection, Dropout. Note that the number of nodes in the first fully connected layer is 4 times the length of the input vector, and the second fully connected layer will restore its original size.
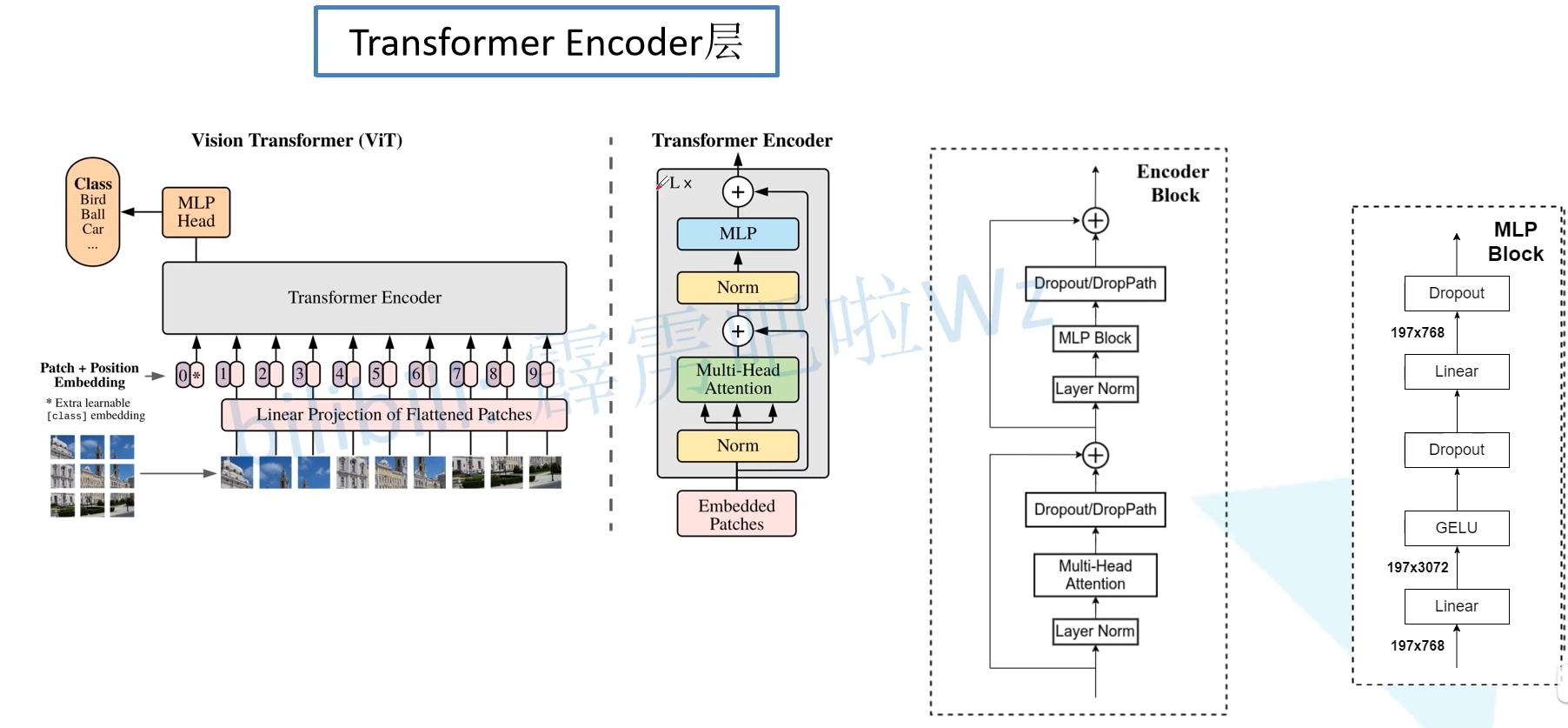
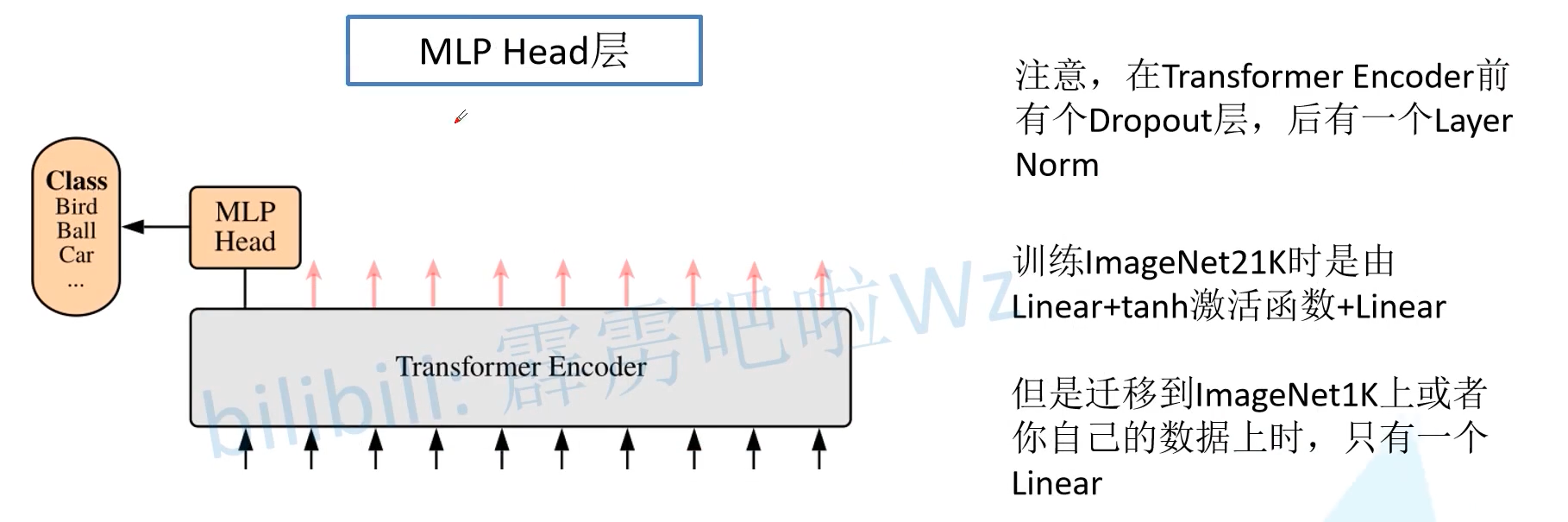
One thing to note is that only by looking at the source code can we know that there is a Dropout layer in front of the Transformer Encoder and a Layer Norm layer after it. These have not been drawn in the figure. There is a Dropout layer in front of the Transformer Encoder. My understanding is to randomly Mask the original image, and then still classify it.
2.3 MLP Head layer
When training ImageNet21K, it is composed of Linear + tanh activation function + Linear. However, after migrating to ImageNet1k or during migration learning, only one Linear is enough. (a softmax is required to obtain the category probability)
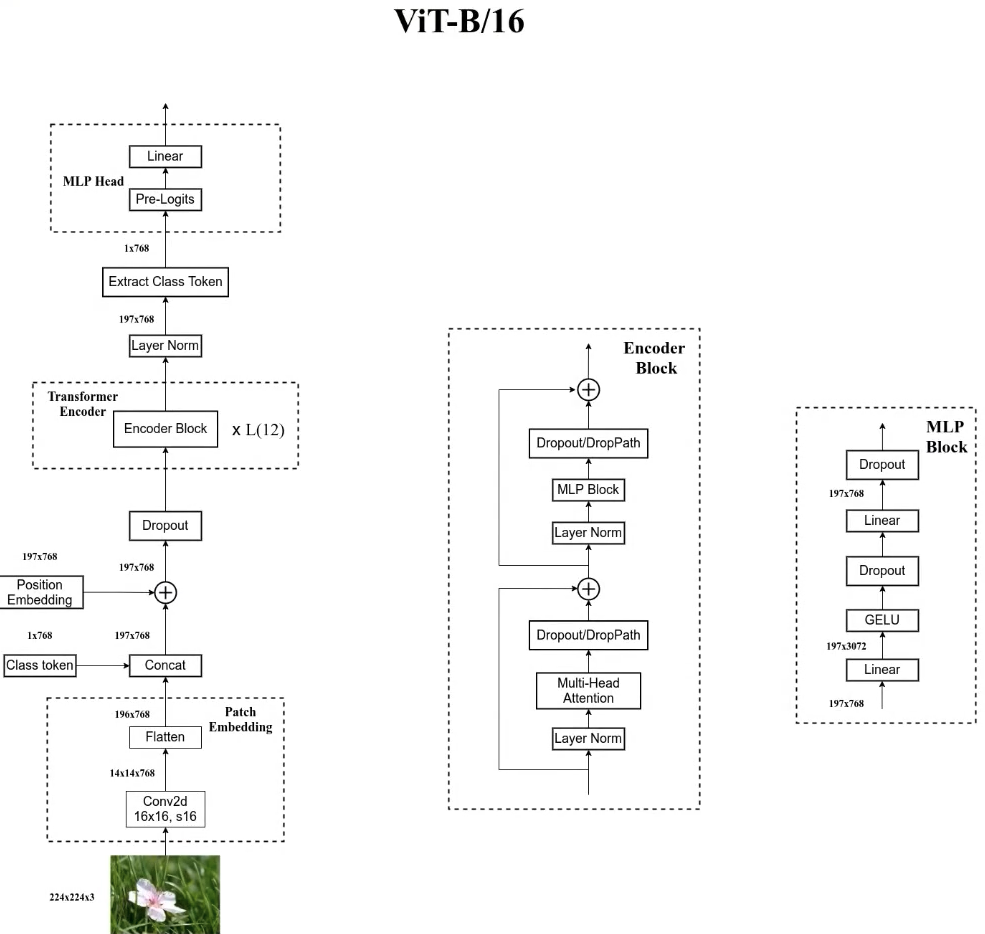
2.4 ViT B/16
Let's comb the structure of ViT B/16 from the beginning, assuming that the input diagram is 224 × 224 × 3 224 \times 224 \times 3 two hundred and twenty-four × two hundred and twenty-four × 3. First pass through a convolution layer, and then flatten in the height and width directions. Then concat a class token, plus the addition operation of Position Embedding, where Position Embedding is also a trainable parameter. After Dropout, enter 12 stacked Encoder blocks. The output of Encoder through LN is 197 × 768 197 \times 768 one hundred and ninety-seven × 768, which is unchanged. Then we extract the output corresponding to the first class token. After slicing, it becomes 1 × 768 1 \times 768 one × 768, enter it into MLP Head. During the pre training of ImageNet21K, pre Logits is a full connection layer and tanh activation function. If you are training on ImageNet1k or your own data set, you can not use this pre Logits.
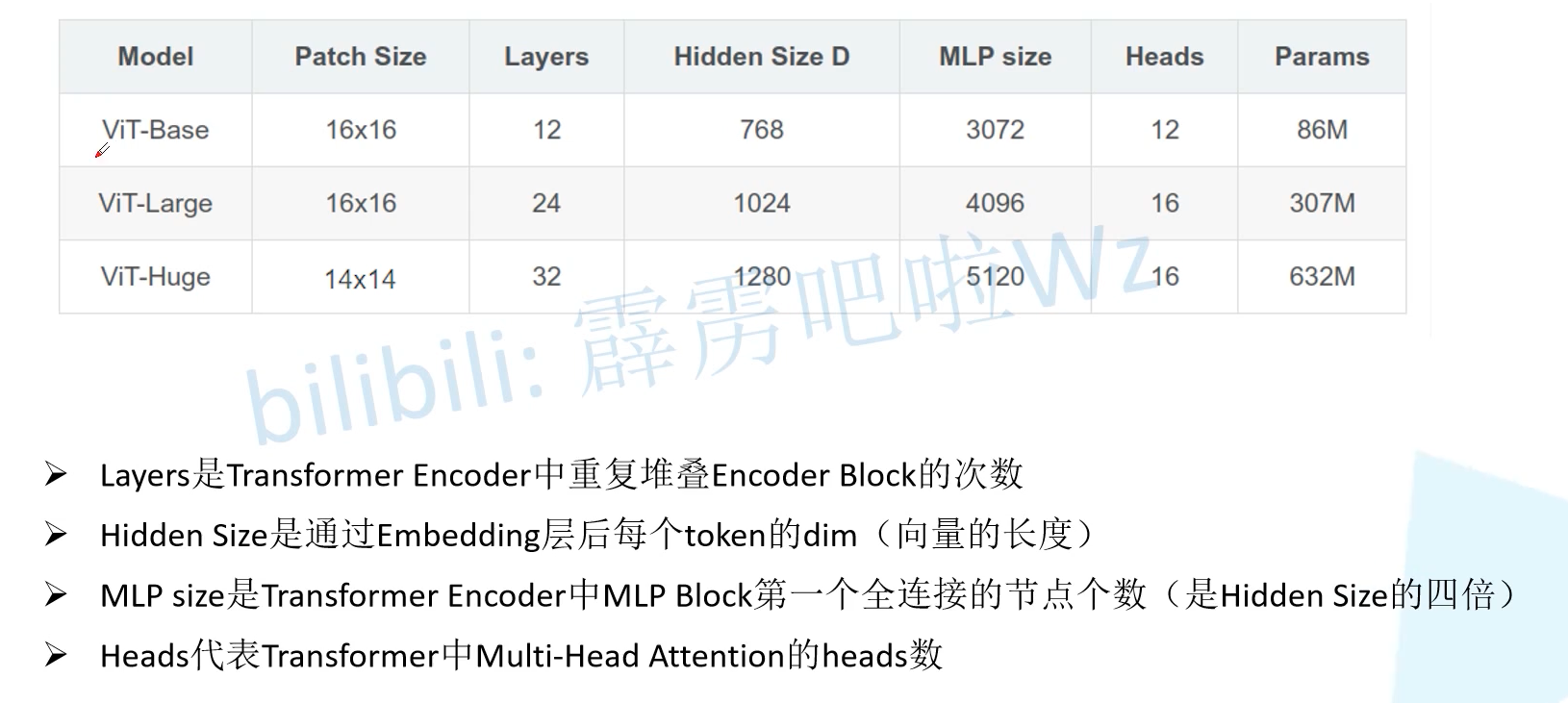
2.5 ViT model parameters
Let's look at the parameters of the ViT model given in the paper. ViT B corresponds to ViT base, ViT L corresponds to ViT large, and ViT H corresponds to ViT huge. patch size is the size of the image slice (there are also in the source code) 32 × 32 32 \times 32 thirty-two × 32); layers is the number of times the encoder block is stacked; Hidden size is the length of the token vector; The MLP size is four times the hidden size, that is, the number of nodes in the first full connection layer of the MLP block in the encoder block; Heads is the number of heads in multi head attention.
3. Hybrid hybrid model
Let's take a look at the hybrid model of CNN and Transformer. Firstly, the traditional neural network backbone is used to extract features, and then the final results are obtained through ViT model. The feature extraction part here adopts ResNet59 network, but it is different from the original one. The first point is to use stdConv2d, the second point is to use GN instead of BN, and the third point is to move the three block s in stage4 to stage3. The output of R50 backbone is 14 × 14 × 1024 14 \times 14 \times 1024 fourteen × fourteen × 1024, and then through 1 × 1 1 \times 1 one × 1 convolution becomes 14 × 14 × 768 14 \times 14 \times 768 fourteen × fourteen × 768, and then flatten to get the token. Then it was the same as ViT.

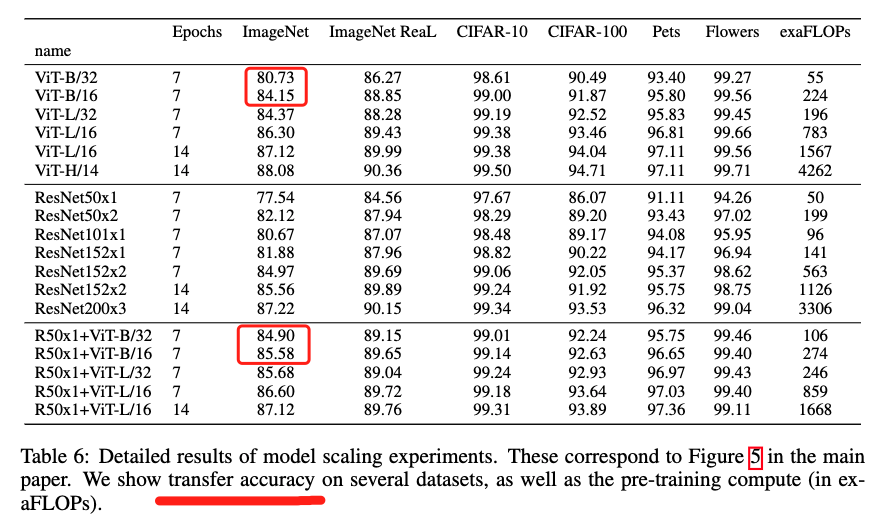
The results show that the hybrid model is better than the pure transformer model, which is also the result of transfer learning. In a small amount of fine-tuning, the mixed model takes up a large proportion, but with the increase of the number of iterations, the pure transformer can also achieve the effect of the mixed model. For example, when there are 14 epoches, ViT-L/16 and Res50x1+ViT-L/16 are basically the same.
4. Code
See the source of the code here.
"""
original code from rwightman:
https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
"""
from functools import partial
from collections import OrderedDict
import torch
import torch.nn as nn
def drop_path(x, drop_prob: float = 0., training: bool = False):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for
changing the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use
'survival rate' as the argument.
"""
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob) * random_tensor
return output
class DropPath(nn.Module):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
class PatchEmbed(nn.Module):
"""
2D Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_c=3, embed_dim=768, norm_layer=None):
super().__init__()
img_size = (img_size, img_size)
patch_size = (patch_size, patch_size)
self.img_size = img_size
self.patch_size = patch_size
self.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])
self.num_patches = self.grid_size[0] * self.grid_size[1]
self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
B, C, H, W = x.shape
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
# flatten: [B, C, H, W] -> [B, C, HW]
# transpose: [B, C, HW] -> [B, HW, C]
x = self.proj(x).flatten(2).transpose(1, 2)
x = self.norm(x)
return x
class Attention(nn.Module):
def __init__(self,
dim, # Enter the dim of the token
num_heads=8,
qkv_bias=False,
qk_scale=None,
attn_drop_ratio=0.,
proj_drop_ratio=0.):
super(Attention, self).__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop_ratio)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop_ratio)
def forward(self, x):
# [batch_size, num_patches + 1, total_embed_dim]
B, N, C = x.shape
# qkv(): -> [batch_size, num_patches + 1, 3 * total_embed_dim]
# reshape: -> [batch_size, num_patches + 1, 3, num_heads, embed_dim_per_head]
# permute: -> [3, batch_size, num_heads, num_patches + 1, embed_dim_per_head]
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
# [batch_size, num_heads, num_patches + 1, embed_dim_per_head]
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
# transpose: -> [batch_size, num_heads, embed_dim_per_head, num_patches + 1]
# @: multiply -> [batch_size, num_heads, num_patches + 1, num_patches + 1]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
# @: multiply -> [batch_size, num_heads, num_patches + 1, embed_dim_per_head]
# transpose: -> [batch_size, num_patches + 1, num_heads, embed_dim_per_head]
# reshape: -> [batch_size, num_patches + 1, total_embed_dim]
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Mlp(nn.Module):
"""
MLP as used in Vision Transformer, MLP-Mixer and related networks
"""
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Block(nn.Module):
def __init__(self,
dim,
num_heads,
mlp_ratio=4.,
qkv_bias=False,
qk_scale=None,
drop_ratio=0.,
attn_drop_ratio=0.,
drop_path_ratio=0.,
act_layer=nn.GELU,
norm_layer=nn.LayerNorm):
super(Block, self).__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop_ratio=attn_drop_ratio, proj_drop_ratio=drop_ratio)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path_ratio) if drop_path_ratio > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop_ratio)
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class VisionTransformer(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_c=3, num_classes=1000,
embed_dim=768, depth=12, num_heads=12, mlp_ratio=4.0, qkv_bias=True,
qk_scale=None, representation_size=None, distilled=False, drop_ratio=0.,
attn_drop_ratio=0., drop_path_ratio=0., embed_layer=PatchEmbed, norm_layer=None,
act_layer=None):
"""
Args:
img_size (int, tuple): input image size
patch_size (int, tuple): patch size
in_c (int): number of input channels
num_classes (int): number of classes for classification head
embed_dim (int): embedding dimension
depth (int): depth of transformer
num_heads (int): number of attention heads
mlp_ratio (int): ratio of mlp hidden dim to embedding dim
qkv_bias (bool): enable bias for qkv if True
qk_scale (float): override default qk scale of head_dim ** -0.5 if set
representation_size (Optional[int]): enable and set representation layer (pre-logits) to this value if set
distilled (bool): model includes a distillation token and head as in DeiT models
drop_ratio (float): dropout rate
attn_drop_ratio (float): attention dropout rate
drop_path_ratio (float): stochastic depth rate
embed_layer (nn.Module): patch embedding layer
norm_layer: (nn.Module): normalization layer
"""
super(VisionTransformer, self).__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
self.num_tokens = 2 if distilled else 1
norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6)
act_layer = act_layer or nn.GELU
self.patch_embed = embed_layer(img_size=img_size, patch_size=patch_size, in_c=in_c, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.dist_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) if distilled else None
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, embed_dim))
self.pos_drop = nn.Dropout(p=drop_ratio)
dpr = [x.item() for x in torch.linspace(0, drop_path_ratio, depth)] # stochastic depth decay rule
self.blocks = nn.Sequential(*[
Block(dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop_ratio=drop_ratio, attn_drop_ratio=attn_drop_ratio, drop_path_ratio=dpr[i],
norm_layer=norm_layer, act_layer=act_layer)
for i in range(depth)
])
self.norm = norm_layer(embed_dim)
# Representation layer
if representation_size and not distilled:
self.has_logits = True
self.num_features = representation_size
self.pre_logits = nn.Sequential(OrderedDict([
("fc", nn.Linear(embed_dim, representation_size)),
("act", nn.Tanh())
]))
else:
self.has_logits = False
self.pre_logits = nn.Identity()
# Classifier head(s)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
self.head_dist = None
if distilled:
self.head_dist = nn.Linear(self.embed_dim, self.num_classes) if num_classes > 0 else nn.Identity()
# Weight init
nn.init.trunc_normal_(self.pos_embed, std=0.02)
if self.dist_token is not None:
nn.init.trunc_normal_(self.dist_token, std=0.02)
nn.init.trunc_normal_(self.cls_token, std=0.02)
self.apply(_init_vit_weights)
def forward_features(self, x):
# [B, C, H, W] -> [B, num_patches, embed_dim]
x = self.patch_embed(x) # [B, 196, 768]
# [1, 1, 768] -> [B, 1, 768]
cls_token = self.cls_token.expand(x.shape[0], -1, -1)
if self.dist_token is None:
x = torch.cat((cls_token, x), dim=1) # [B, 197, 768]
else:
x = torch.cat((cls_token, self.dist_token.expand(x.shape[0], -1, -1), x), dim=1)
x = self.pos_drop(x + self.pos_embed)
x = self.blocks(x)
x = self.norm(x)
if self.dist_token is None:
return self.pre_logits(x[:, 0])
else:
return x[:, 0], x[:, 1]
def forward(self, x):
x = self.forward_features(x)
if self.head_dist is not None:
x, x_dist = self.head(x[0]), self.head_dist(x[1])
if self.training and not torch.jit.is_scripting():
# during inference, return the average of both classifier predictions
return x, x_dist
else:
return (x + x_dist) / 2
else:
x = self.head(x)
return x
def _init_vit_weights(m):
"""
ViT weight initialization
:param m: module
"""
if isinstance(m, nn.Linear):
nn.init.trunc_normal_(m.weight, std=.01)
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out")
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.LayerNorm):
nn.init.zeros_(m.bias)
nn.init.ones_(m.weight)
def vit_base_patch16_224_in21k(num_classes: int = 21843, has_logits: bool = True):
"""
ViT-Base model (ViT-B/16) from original paper (https://arxiv.org/abs/2010.11929).
ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer.
weights ported from official Google JAX impl:
https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_base_patch16_224_in21k-e5005f0a.pth
"""
model = VisionTransformer(img_size=224,
patch_size=16,
embed_dim=768,
depth=12,
num_heads=12,
representation_size=768 if has_logits else None,
num_classes=num_classes)
return model
def vit_base_patch32_224_in21k(num_classes: int = 21843, has_logits: bool = True):
"""
ViT-Base model (ViT-B/32) from original paper (https://arxiv.org/abs/2010.11929).
ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer.
weights ported from official Google JAX impl:
https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_base_patch32_224_in21k-8db57226.pth
"""
model = VisionTransformer(img_size=224,
patch_size=32,
embed_dim=768,
depth=12,
num_heads=12,
representation_size=768 if has_logits else None,
num_classes=num_classes)
return model
def vit_large_patch16_224_in21k(num_classes: int = 21843, has_logits: bool = True):
"""
ViT-Large model (ViT-L/16) from original paper (https://arxiv.org/abs/2010.11929).
ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer.
weights ported from official Google JAX impl:
https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_large_patch16_224_in21k-606da67d.pth
"""
model = VisionTransformer(img_size=224,
patch_size=16,
embed_dim=1024,
depth=24,
num_heads=16,
representation_size=1024 if has_logits else None,
num_classes=num_classes)
return model
def vit_large_patch32_224_in21k(num_classes: int = 21843, has_logits: bool = True):
"""
ViT-Large model (ViT-L/32) from original paper (https://arxiv.org/abs/2010.11929).
ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer.
weights ported from official Google JAX impl:
https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_large_patch32_224_in21k-9046d2e7.pth
"""
model = VisionTransformer(img_size=224,
patch_size=32,
embed_dim=1024,
depth=24,
num_heads=16,
representation_size=1024 if has_logits else None,
num_classes=num_classes)
return model
def vit_huge_patch14_224_in21k(num_classes: int = 21843, has_logits: bool = True):
"""
ViT-Huge model (ViT-H/14) from original paper (https://arxiv.org/abs/2010.11929).
ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer.
NOTE: converted weights not currently available, too large for github release hosting.
"""
model = VisionTransformer(img_size=224,
patch_size=14,
embed_dim=1280,
depth=32,
num_heads=16,
representation_size=1280 if has_logits else None,
num_classes=num_classes)
return model