I. Introduction to Redia data persistence
1 background description
Redis is an in memory database, and data may be lost in case of power failure. For example, if you hang up the whole redis, then redis is unavailable. If there is no persistence, redis will lose all data. If you make a piece of data to disk through persistence, and then synchronize it to some cloud storage services regularly, you can ensure that some data is not lost and ensure the reliability of data.
2 persistence mode
In Redis, in order to ensure faster fault recovery in case of system downtime (similar processes are killed), two data persistence schemes are designed, namely rdb and aof.
two Rdb mode persistence
one summary
Rdb mode is a mechanism to save the key/value in redis manually (save blocking, bgsave asynchronous) or periodically. Rdb mode is generally the default data persistence mode of redis. The persistence mechanism of this mode will be turned on automatically when the system is started.
two RDB mode configuration
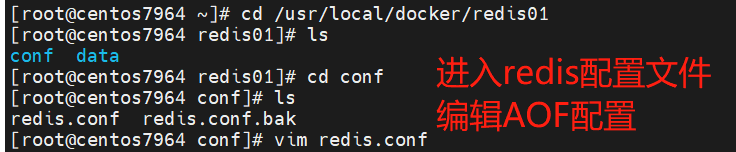
RDB persistence is enabled by default, and can also be configured according to the rules. For example, open the redis.conf file, such as
# This means that if more than 1000 key s are changed every 60s, a new dump.rdb file is generated, which is the complete data snapshot in the current redis memory. This operation is also called snapshot.
save 60 1000
# When the persistent rdb file encounters a problem, whether the main process accepts writing. yes means to stop writing. If no means that redis continues to provide services.
stop-writes-on-bgsave-error yes
# Whether to perform compression when performing snapshot mirroring. yes: compression, but it requires some cpu consumption. No: no compression, more disk space is required.
rdbcompression yes
# A CRC64 check is placed at the end of the file. When storing or loading rbd files, there will be a performance degradation of about 10%. In order to maximize performance, you can turn off this configuration item.
rdbchecksum yes
# The file name of the snapshot
dbfilename dump.rdb
# Directory where snapshots are stored
dir /var/lib/redis
three Rdb mode persistence practice
Experiment 1
Save several pieces of data in redis, then execute shutdown to shut down redis, and then restart redis to see if the data just inserted is still there? If the data is still there, why?
Because stopping redis through redis cli shutdown is actually a safe exit mode. When redis exits, it will immediately generate a complete rdb snapshot of the data in memory, such as
127.0.0.1:6379> set phone 11111111 OK 127.0.0.1:6379> shutdown #Persistence also occurs by default [root@centos7964 ~]# docker start redis01 [root@centos7964 ~]# docker exec -it redis01 redis-cli 127.0.0.1:6379> keys * 1) "pone"
Experiment II
Save several new pieces of data in redis, kill the redis process with kill -9, and simulate the scenario of abnormal exit due to redis failure, resulting in memory data loss?
This time, it was found that the redis process was killed abnormally, and several latest data were lost. For example:
First, open the first client and clear the data corresponding to the redis memory and disk
[root@centos7964 data]# docker exec -it redis01 redis-cli 127.0.0.1:6379> flushall OK 127.0.0.1:6379> exit [root@centos7964 data]# ls dump.rdb [root@centos7964 data]# rm –f dump.rdb [root@centos7964 data]# ls
Then, open and log in to the second client and store some data to redis, such as
[root@centos7964 ~]# docker exec -it redis01 redis-cli 127.0.0.1:6379> set one mybatis OK 127.0.0.1:6379> set two spring OK 127.0.0.1:6379> keys * 1) "one" 2) "two"
Next, go back to the first client again and kill the redis process, for example
[root@centos7964 data]# ps -ef | grep redis polkitd 6995 6974 0 14:44 ? 00:00:00 redis-server *:6379 root 7064 6974 0 14:44 pts/0 00:00:00 redis-cli root 7111 6467 0 14:47 pts/1 00:00:00 docker exec -it redis01 redis-cli root 7130 6974 0 14:47 pts/1 00:00:00 redis-cli root 7278 7180 0 14:51 pts/0 00:00:00 grep --color=auto redis [root@centos7964 data]# kill -9 6995 [root@centos7964 data]# docker start redis01
Finally, open the first client, log in to redis and check whether the key still exists
[root@centos7964 ~]# docker exec -it redis01 redis-cli 127.0.0.1:6379> keys * (empty array) 127.0.0.1:6379> [root@centos7964 ~]#
Experiment III
Manually call save (synchronous save) or bgsave (asynchronous save) to execute rdb snapshot generation. Then kill the redis process and restart to detect whether there is any data just saved
127.0.0.1:6379> set id 100 OK 127.0.0.1:6379> set name jack OK 127.0.0.1:6379> save #Blocking persistence OK 127.0.0.1:6379> set address beijing OK 127.0.0.1:6379> bgsave #Asynchronous persistence Background saving started
four Rdb persistent interview analysis
four point one What is the difference between save and bgsave in Redis?
- The Redis Save command performs a synchronous save operation to save all data snapshots of the current Redis instance to the hard disk in the form of RDB files.
- The BGSAVE command returns OK immediately after execution, and then Redis fork sends out a new child process. The original Redis process (parent process) continues to process client requests, while the child process is responsible for saving data to disk and then exiting.
four point two What are the advantages of RDB persistence mechanism?
First, RDB will generate multiple data files, each of which represents the data of redis at a certain time. This method of multiple data files is very suitable for cold standby. This complete data file can be sent to some remote cloud services. In China, it can be Alibaba cloud's ODPS distributed storage, Regularly back up the data in redis with a predetermined backup strategy
Second: RDB has very little impact on the external read-write services provided by redis, which can enable redis to maintain high performance. Because the main process of redis only needs to fork a child process and let the child process perform disk IO operations for RDB persistence.
Third: compared with the AOF persistence mechanism, it is faster to restart and recover the redis process directly based on the RDB data file.
four point three What are the disadvantages of RDB persistence mechanism?
If you want to lose as little data as possible when redis fails, RDB is not very good. It takes snapshots every 5 minutes or more. At this time, once the redis process goes down, you will lose data in the last few minutes.
three Aof mode data persistence
Aof mode is a persistence mechanism for recording redis data by recording write operation logs. This mechanism is turned off by default.
one AOF mode configuration
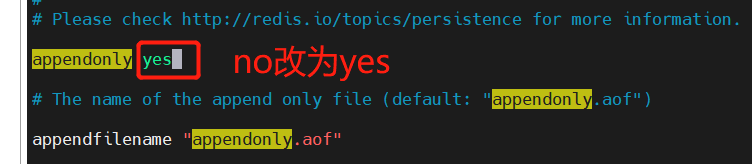
# Whether to enable AOF. It is off by default
appendonly yes
# Specify AOF file name
appendfilename appendonly.aof
# Redis supports three brushing modes:
# appendfsync always #Every time a write command is received, it is forced to write to the disk, similar to MySQL sync_binlog=1 is the safest. However, the speed is also the slowest in this mode, which is generally not recommended.
appendfsync everysec #Forced write to disk once per second to balance performance and persistence. This method is recommended.
# appendfsync no #It is completely dependent on the OS. Generally, it is written once every 30 seconds. The performance is the best, but persistence is not guaranteed. It is not recommended.
#During log rewriting, the command is not appended, but only placed in the buffer to avoid conflicts on DISK IO caused by the addition of the command.
#Set to yes to indicate that new write operations are not fsync during rewriting and are temporarily stored in memory. Write after rewriting is completed. The default value is no. yes is recommended
no-appendfsync-on-rewrite yes
#When the current AOF file size is twice the size of the AOF file obtained by the last log rewrite, a new log rewrite process is automatically started.
auto-aof-rewrite-percentage 100
#The minimum value for the current AOF file to start a new log rewriting process to avoid frequent rewriting due to the small file size when IDS is just started.
auto-aof-rewrite-min-size 64mb
two AOF mode persistence practice
First: turn on the AOF switch and enable AOF persistence
Second: write some data and observe the log contents in the AOF file (appendonly.aof)
Third: kill -9, kill the redis process, restart the redis process, and find that the data has been recovered from the AOF file. When the redis process is started, it will directly load all logs from appendonly.aof to recover the data in memory.
three AOF interview analysis
three point one How to understand the rewrite operation in AOF mode?
The data in redis is actually limited. Many data may automatically expire, may be deleted by users, and may be cleared by redis using the cache clearing algorithm. In other words, the old data in redis will continue to be eliminated, and only a part of the commonly used data will be automatically retained in redis memory. Therefore, there may be a lot of data that has been cleaned up before, and the corresponding write log still stays in AOF. There is only one AOF log file, which will continue to expand to a large extent.
Therefore, AOF will automatically rewrite every certain time in the background. For example, the write log for 100w data has been stored in the log; There is only 100000 redis memory left; Build a set of latest logs based on the current 100000 data in memory and send them to AOF; Overwrite previous old logs; Ensure that the AOF log file is not too large, and keep consistent with the amount of redis memory data
three point two What are the advantages of AOF persistence mechanism?
First: AOF can better protect data from loss. Generally, AOF will execute fsync operation through a background thread every 1 second, and the data will be lost for 1 second at most
Second: the AOF log file is written in append only mode, so there is no overhead of disk addressing. The writing performance is very high, and the file is not easy to be damaged. Even if the end of the file is damaged, it is easy to repair.
Third: even if the AOF log file is too large, the background rewriting operation will not affect the reading and writing of the client. When rewriting the log, the instructions will be compressed to create a minimum log that needs to recover data. When creating a new log file, the old log file is written as usual. When the log file after the new merge is ready, you can exchange the new and old log files.
Fourth: the commands of AOF log files are recorded in an easy to read way. This feature is very suitable for emergency recovery of catastrophic accidental deletion. For example, someone accidentally empties all data with the flush command. As long as the background rewrite has not occurred at this time, the AOF file can be copied immediately, the last flush command can be deleted, and then the AOF file can be put back. All data can be recovered automatically through the recovery mechanism
three point three What are the disadvantages of AOF persistence mechanism?
First: for the same data, the AOF log file is usually larger than the RDB data snapshot file.
Second: after AOF is enabled, the supported write QPS will be lower than that supported by RDB, because AOF is generally configured to fsync log files every second. Of course, fsync every second still has high performance.
Third: AOF, which is based on the command log, is more fragile and prone to bugs than the RDB based method of persisting a complete data snapshot file each time. However, in order to avoid the bugs caused by the rewrite process, AOF does not merge based on the old instruction log, but rebuilds the instructions based on the data in memory at that time, which will be much more robust.
three point four How to select the persistence mode of redis?
First: don't just use RDB, because that will cause you to lose a lot of data.
Second: don't just use AOF, because AOF is not as fast as RDB for data recovery, and RDB's simple and rough data snapshot method is more robust.
Thirdly, AOF and RDB persistence mechanisms are comprehensively used to ensure that data is not lost, which is the first choice for data recovery; RDB is used for different degrees of cold standby.
four Redis transaction processing practice
This section focuses on the transactions in redis, as well as the transaction control instructions, control mechanism and optimistic lock implementation.
one Redis transaction introduction
Redis adopts an optimistic approach to transaction control. It uses the watch command to monitor a given key. When exec (commit a transaction), if the monitored key changes after calling watch, the whole transaction will fail. You can also call watch to monitor multiple keys multiple times. Note that the key of watch is valid for the whole connection. If the connection is disconnected, monitoring and transactions will be automatically cleared. Of course, the exec, discard and unwatch commands will clear all monitoring in the connection.
two Basic instruction
When redis performs transaction control, it is usually implemented based on the following instructions, for example:
- multi open transaction
- exec commit transaction
- discard cancel transaction
- watch monitoring. If the monitored value changes, the transaction submission will fail
- unwatch remove monitoring
Redis ensures that all commands in a transaction are executed or not executed (atomicity). If the client is disconnected before sending the EXEC command, redis will empty the transaction queue and all commands in the transaction will not be executed. Once the client sends the EXEC command, all commands will be executed. Even if the client is disconnected, it doesn't matter, because all commands to be executed have been recorded in redis.
three Redis transaction control practice
three point one exec commit transaction
For example: analog transfer, tony 500, jack 200, tony to Jack 100. The process is as follows:
127.0.0.1:6379> set tony 500 OK 127.0.0.1:6379> set jack 200 OK 127.0.0.1:6379> mget tony jack 1) "500" 2) "200" 127.0.0.1:6379> multi #Open transaction OK 127.0.0.1:6379(TX)> decrby tony 100 #All instruction operations are queued QUEUED 127.0.0.1:6379(TX)> incrby jack 100 QUEUED 127.0.0.1:6379(TX)> mget tony jack QUEUED 127.0.0.1:6379(TX)> exec #Commit transaction 1) (integer) 400 2) (integer) 300 3) 1) "400" 2) "300" 127.0.0.1:6379> mget tony jack 1) "400" 2) "300" 127.0.0.1:6379>
three point two discard cancel transaction
Note that the redis transaction is too simple. Instead of rolling back, it has to be cancelled.
127.0.0.1:6379> mget tony jack 1) "400" 2) "300" 127.0.0.1:6379> multi OK 127.0.0.1:6379> incrby jack 100 QUEUED 127.0.0.1:6379> discard OK 127.0.0.1:6379> get jack "300" 127.0.0.1:6379> exec (error) ERR EXEC without MULTI
When an incorrect instruction occurs, the transaction will also be cancelled automatically.
127.0.0.1:6379> mget tony jack 1) "400" 2) "300" 127.0.0.1:6379> multi OK 127.0.0.1:6379(TX)> incrby jack 100 QUEUED 127.0.0.1:6379(TX)> abcd (error) ERR unknown command `abcd`, with args beginning with: 127.0.0.1:6379(TX)> get jack QUEUED 127.0.0.1:6379(TX)> exec (error) EXECABORT Transaction discarded because of previous errors. 127.0.0.1:6379> get jack "300" 127.0.0.1:6379>
three point three Second kill ticket grabbing transaction
Based on a second kill and rush purchase case, demonstrate the optimistic lock mode of redis, for example
Step 1: open client 1 and perform the following operations
127.0.0.1:6379> set ticket 1 OK 127.0.0.1:6379> set money 0 OK 127.0.0.1:6379> watch ticket #Optimistic lock. Observe the value. If the value changes, the transaction fails OK 127.0.0.1:6379> multi #Open transaction OK 127.0.0.1:6379> decr ticket QUEUED 127.0.0.1:6379> incrby money 100 QUEUED
Step 2: open client 2 and perform the following operations. Before client 1 submits the transaction, client 2 buys the ticket.
127.0.0.1:6379> get ticket "1" 127.0.0.1:6379> decr ticket (integer) 0
Step 3: return to client 1: commit the transaction and check the value of ticket
127.0.0.1:6379> exec (nil) #Execute transaction, failed 127.0.0.1:6379> get ticket "0" 127.0.0.1:6379> unwatch #Cancel monitoring
three point four Jedis client transaction operations
Conduct transaction test based on Jedis, and the code is as follows:
package com.jt;
import org.junit.Test;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Transaction;
public class JedisTransactionTests {
@Test
public void testTransaction(){
Jedis jedis=new Jedis("192.168.126.130",6379);
jedis.auth("123456");
jedis.set("tony","300");
jedis.set("jack","500");
//To implement the operation, tony transfers 100 to jack
//Open transaction
Transaction multi = jedis.multi();
//Perform business operations
try {
multi.decrBy("tony", 100);
multi.incrBy("jack", 100);
int n=100/0;//Simulation anomaly
//Commit transaction
multi.exec();
}catch(Exception e) {
//An exception occurred to cancel the transaction
multi.discard();
}
String tonyMoney=jedis.get("tony");
String jackMoney=jedis.get("jack");
System.out.println("tonyMoney="+tonyMoney);
System.out.println("jackMoney="+jackMoney);
jedis.close();
}
}
three point five Jedis client second kill operation practice
package com.jt.demos;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Response;
import redis.clients.jedis.Transaction;
import java.util.List;
/**
* redis Second kill exercise:
* Simulate that both threads rush to buy the same ticket (consider music lock)
*/
public class SecondKillDemo02 {
public static void secKill(){
Jedis jedis=new Jedis("192.168.126.130",6379);
jedis.auth("123456");
jedis.watch("ticket","money");
String ticket = jedis.get("ticket");
if(ticket==null||Integer.valueOf(ticket)==0)
throw new RuntimeException("No inventory");
Transaction multi = jedis.multi();
try {
multi.decr("ticket");
multi.incrBy("money", 100);
List<Object> exec = multi.exec();
System.out.println(exec);
}catch (Exception e){
e.printStackTrace();
multi.discard();
}finally {
jedis.unwatch();
jedis.close();
}
}
public static void main(String[] args) {
Jedis jedis=new Jedis("192.168.126.130",6379);
jedis.auth("123456");
jedis.set("ticket","1");
jedis.set("money","0");
Thread t1=new Thread(()->{
secKill();
});
Thread t2=new Thread(()->{
secKill();
});
t1.start();
t2.start();
}
}