The previous article explained in detail how to use kibana RestFul style to operate es, followed by ES cluster, native API and SpringDataElasticsearch
https://blog.csdn.net/qq_45441466/article/details/120110968
1.Elasticsearch cluster
What are the possible problems with single point elastic search?
- The storage capacity of a single machine is limited, and high storage cannot be realized
- Single server is prone to single point of failure and cannot achieve high availability
- The concurrent processing capability of a single service is limited, and high concurrency cannot be achieved
Therefore, in order to solve these problems, we need to build a cluster for elasticsearch
1.2. Cluster structure
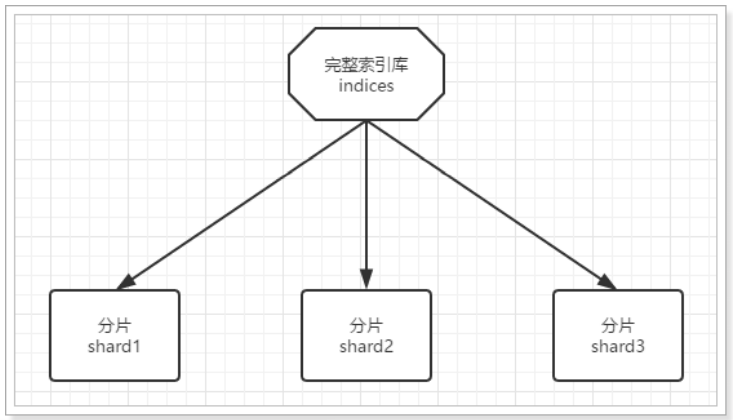
1.2.1. Data slicing
First of all, the first problem we face is that the amount of data is too large and the amount of single point storage is limited.
What do you think should be done?
Yes, we can split the data into multiple copies, each of which is stored in different machine nodes, so as to reduce the amount of data in each node. This is the distributed storage of data, also known as data Shard.
1.2.2. Data backup
Data fragmentation solves the problem of massive data storage, but if there is a single point of failure, the fragmented data is no longer complete. How to solve this?
Yes, just like everyone will store an additional copy to the mobile hard disk in order to back up the mobile phone data. We can back up each piece of data and store it in other nodes to prevent data loss. This is data backup, also known as data replica.
Data backup can ensure high availability, but the number of nodes required will be doubled by one backup per slice, and the cost is too high!
To strike a balance between high availability and cost, we can do this:
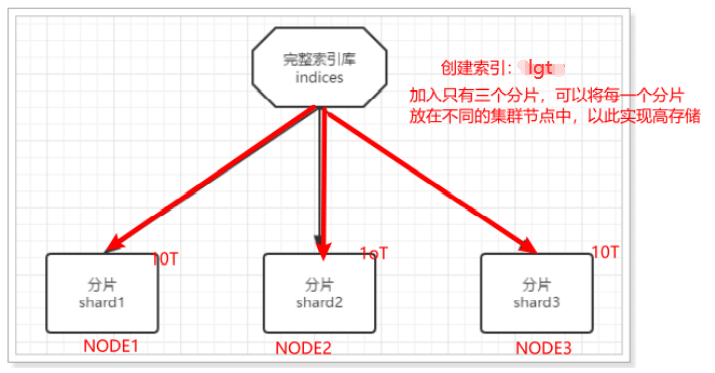
- Firstly, the data is partitioned and stored in different nodes
- Then back up each partition and put it on the other node to complete mutual backup
In this way, the number of service nodes required can be greatly reduced. As shown in the figure, we take three slices and one backup for each slice as an example:
In this cluster, if a single node fails, it will not lead to data loss, so it ensures the high availability of the cluster and reduces the amount of data storage in the node. Moreover, because multiple nodes store data, user requests will also be distributed to different servers, and the concurrency ability has been improved to a certain extent.
1.3. Building clusters
The cluster requires multiple machines. We use one machine to simulate it. Therefore, we need to deploy multiple elasticsearch nodes in one virtual machine, and the ports of each elasticsearch must be different.
One machine for simulation: copy three copies of our ES installation package, modify the port number and the different storage locations of data and log.
In actual development, each ES node is placed on a different server.
We plan to deploy three elasticsearch nodes with the cluster name of Lagou elastic:

http: indicates the port used when accessing using the http protocol. Elasticsearch head, kibana and postman. The default port number is 9200.
tcp: the communication port of each node in the cluster. It is 9300 by default
Step 1: copy and paste the es software 3 times, and rename them respectively

Step 2: modify the elasticsearch.yml under the configuration file config of each node. The first configuration file is taken as an example below
node-01:
#Must be the ip address of this machine
network.host: 127.0.0.1
#Allow cross domain access
http.cors.enabled: true
#When cross domain is allowed, the default value is *, which means that all domain names are supported
http.cors.allow-origin: "*"
#Allow all nodes to access
#network.host: 0.0.0.0
#The name of the cluster. The cluster names of all nodes in the same cluster should be the same
cluster.name: lagou-elastic
#The current node name is different for each node
node.name: node-01
#The storage path of data is different for each node, and the storage paths of data and log corresponding to different es servers cannot be the same
path.data: D:\class\es-9201\data
#The storage path of logs is different for each node
path.logs: D:\class\es-9201\logs
#The external port of http protocol is different for each node. The default is 9200
http.port: 9201
#Each node of TCP protocol external port is different. The default value is 9300
transport.tcp.port: 9301
#The three nodes discover each other, including their own port numbers using the tcp protocol
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
#Declare that more than a few voting master nodes are valid. Please set it to (nodes / 2) + 1
#discovery.zen.minimum_master_nodes: 2
#Master node
#node.master: true
Step 3: start the cluster and start the three nodes separately. Don't be in a hurry. Start them one by one
Use the head plug-in to view:
1.4. Create index library in test cluster
Configure kibana and restart

After building a cluster, we need to create an index library. The problem is, when we create an index library, which service node will the data be saved to? If we slice the index library, which node will each slice be on?
You have to try it yourself.
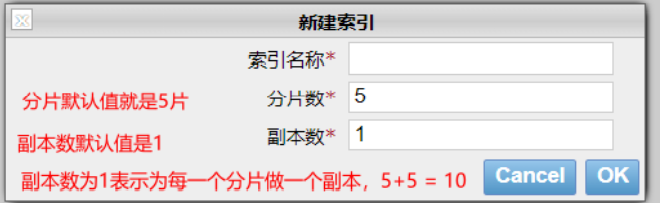
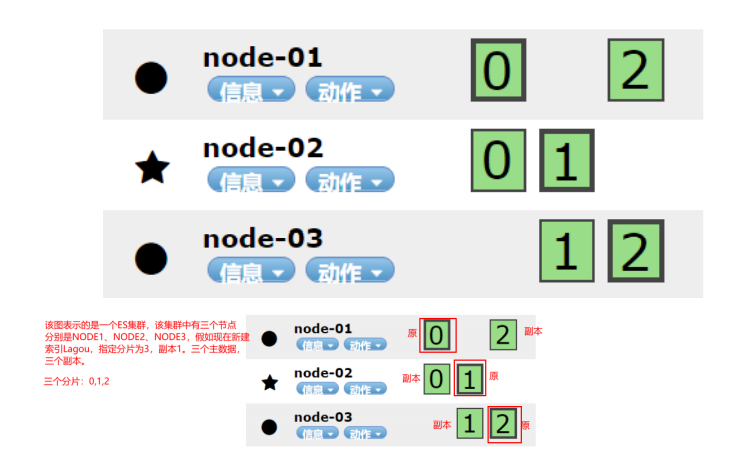
Here, let's take a look at the settings of fragmentation and backup in the cluster, for example:
PUT /lagou { "settings": { "number_of_shards": 3, "number_of_replicas": 1 } }
There are two configurations:
- number_of_shards: the number of slices, which is set to 3 here
- number_of_replicas: the number of replicas is set to 1 here. Each fragment has one backup and one original data. There are 2 copies in total.
Through the head view of chrome browser, we can view the storage structure of slices:
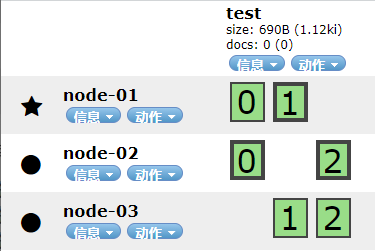
It can be seen that the test index library has three partitions, namely 0, 1 and 2. Each partition has 1 copy, a total of 6 copies.
A copy of slice 1 and slice 2 is saved on node-01
A copy of slice 0 and slice 2 is saved on node-02
Copies of partition 0 and partition 1 are saved on node-03
1.5. Working principle of cluster
1.5.1.shad and replica mechanism
(1) An index contains multiple shard s, that is, an index exists on multiple servers
(2) Each shard is a minimum unit of work and carries some data. For example, there are three servers. Now there are three pieces of data, one of which is on each of the three servers(
3) When increasing or decreasing nodes, shard will automatically load balance in nodes
(4) Primary shards and replica Shards. Each document must exist only in one primary shard and its corresponding replica shard, and cannot exist in multiple primary Shards
(5) replica shard is a replica of the primary shard. It is responsible for fault tolerance and load of read requests
(6) The number of primary shard s is fixed when the index is created, and the number of replica shard s can be modified at any time
(7) The default number of primary shards is 5, and the default number of replicas is 1 (one replica for each primary shard). By default, there are 10 shards, 5 primary shards and 5 replica Shards
(8) The primary shard cannot be placed on the same node as its own replica shard (otherwise, if the node goes down, both the primary shard and the replica will be lost, which will not play the role of fault tolerance), but it can be placed on the same node as the replica shards of other primary Shards
1.5.2. Cluster write data
1. The client selects a node to send the request. This node is the coordinating node
2. coordinating node: route the document and forward the request to the corresponding node( Select the corresponding node for storage according to a certain algorithm)
3. The primary shard on the actual node processes the request, saves the data locally, and then synchronizes the data to the replica node
4. coordinating node. If it is found that the primary node and all replica node s are completed, the request will be returned to the client
This route is simply a modular algorithm. For example, there are three servers. At this time, the id transmitted is 5, so 5% 3 = 2 is placed on the second server
1.5.3.ES query data
Inverse sorting algorithm
There is an algorithm called reverse sorting: in short, record the id of the word through word segmentation, find out which id contains the data, and then find the data according to the id
Query process
1. The client sends a request to coordinate node
2. The coordination node forwards the search request to the primary shard or replica shard corresponding to all Shards
3. query phase: each shard returns its search results (in fact, some unique identifiers) to the coordination node. The coordination node performs data consolidation, sorting, paging and other operations to produce the final results
4. fetch phase, and then the coordination node pulls data from each node according to the unique ID, and finally returns it to the client
2.Elasticsearch client
2.1. Client introduction
Clients in various languages are available on the elasticsearch official website: https://www.elastic.co/guide/en/elasticsearch/clie nt/index.html
Note: after clicking enter, select version to 6.2.4, because we used to follow version 6.2.4:
2.2. Create Demo project
2.2.1. Initialization item
Create a springboot project.
2.2.2.pom file
Note that here we directly import the SpringBoot launcher for subsequent explanation. However, it is also necessary to manually introduce the dependency of elasticsearch's high-level rest client:
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.8.5</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.8.1</version>
</dependency>
<!--Apache Provided by open source organizations for operation JAVA BEAN Toolkit for-->
<dependency>
<groupId>commons-beanutils</groupId>
<artifactId>commons-beanutils</artifactId>
<version>1.9.1</version>
</dependency>
<!--ES senior Rest Client-->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>6.4.3</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>6.4.3</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>6.4.3</version>
</dependency>
<!-- <dependency>-->
<!-- <groupId>org.springframework.boot</groupId>-->
<!-- <artifactId>spring-boot-starter-data-elasticsearch</artifactId>-->
<!-- </dependency>-->
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>2.2.3. Configuration file
We create application.yml under resource
2.3. Index library and mapping
While creating the index library, we will also create the type and its mapping relationship. However, it is not recommended to use the java client for these operations. The reasons are as follows:
- The index library and mapping are usually completed during initialization and do not require frequent operations. It is better to configure them in advance
- The official API for creating index libraries and mapping is very cumbersome, and the json structure needs to be spliced through strings:
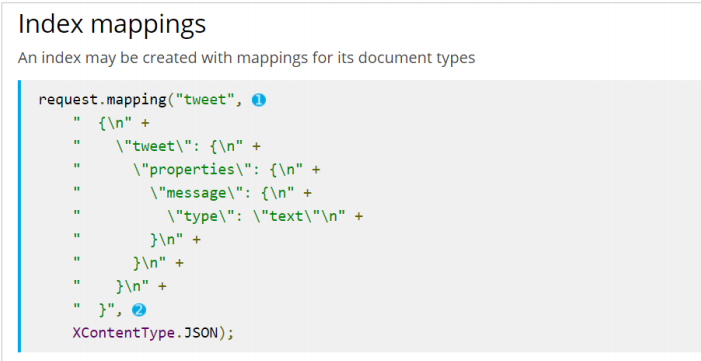
Therefore, it is recommended to implement these operations using the Rest style API we learned yesterday.
Let's take such a commodity data as an example to create an index library:
public class Product {
private Long id;
private String title; //title
private String category;// classification
private String brand; // brand
private Double price; // Price
private String images; // Picture address
}
Analyze the data structure:
- id: it can be considered as a primary key. It is an indicator to judge whether the data is repeated in the future. It is not word segmentation. keyword type can be used
- title: search field. Word segmentation is required. text type can be used
- category: commodity classification. This is a whole without word segmentation. keyword type can be used. Brand: brand is similar to classification. keyword type can be used without word segmentation
- Price: price. This is a double type
- images: pictures, fields for display, no search, index is false, no word segmentation, and keyword type can be used
We can write such a mapping configuration:
PUT /lgt
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
},
"mappings": {
"item": {
"properties": {
"id": {
"type": "keyword"
},
"title": {
"type": "text","analyzer": "ik_max_word"
},
"category": {
"type": "keyword"
},
"brand": {
"type": "keyword"
},
"images": {
"type": "keyword",
"index": false
},
"price": {
"type": "double"
}
}
}
}
}2.4. Index data operation
With the index library, let's take a look at how to add index data
Operating MYSQL database:
1. Get database connection
2. Complete data addition, deletion, modification and query
3. Release resources
2.4.1. Initialize client
To complete any operation, you need to go through the HighLevelRestClient client. Let's see how to create it.
private static RestHighLevelClient restHighLevelClient;
private Gson gson = new Gson();
/**
* Initialize client
*/
@BeforeAll
static void init() {
System.out.println("Yes");
RestClientBuilder clientBuilder = RestClient.builder(
new HttpHost("127.0.0.1", 9201, "http"),
new HttpHost("127.0.0.1", 9202, "http"),
new HttpHost("127.0.0.1", 9203, "http")
);
restHighLevelClient = new RestHighLevelClient(clientBuilder);
}
/**
* Close client
*/
@AfterAll
static void close() throws IOException {
restHighLevelClient.close();
}2.4.2. Add a document
/**
* New document
* @throws IOException
*/
@Test
void addDoc() throws IOException {
//1. Create a document
Product product = new Product();
product.setBrand("Huawei");
product.setCategory("mobile phone");
product.setId(1L);
product.setImages("http://image.huawei.com/1.jpg");
product.setTitle("Huawei P50 It's great");
product.setPrice(88.88d);
//2. Convert document data to json format
String source = gson.toJson(product);
//3. Create index request object
// public IndexRequest(String index, String type, String id)
IndexRequest request = new IndexRequest("lagou","item",product.getId().toString());
//4. Make a request
request.source(source, XContentType.JSON);
IndexResponse response = restHighLevelClient.index(request, RequestOptions.DEFAULT);
System.out.println(response);
}2.4.3. Viewing documents
/**
* View document
* @throws IOException
*/
@Test
void queryDoc() throws IOException {
//Create the request object GetRequest and specify the id
GetRequest request = new GetRequest("lagou","item","1");
//Execute query
GetResponse response = restHighLevelClient.get(request, RequestOptions.DEFAULT);
System.out.println(response);
String source = response.getSourceAsString();
Product product = gson.fromJson(source, Product.class);
System.out.println(product);
}2.4.4. Modify document
/**
* Modify document
* @throws IOException
*/
@Test
void updateDoc() throws IOException {
Product product = new Product();
product.setBrand("Huawei");
product.setCategory("mobile phone");
product.setId(1L);
product.setImages("http://image.huawei.com/1.jpg");
product.setTitle("Huawei P50 It's great");
product.setPrice(88.99d);
//Create the request object GetRequest and specify the id
IndexRequest request = new IndexRequest("lagou","item",product.getId().toString());
String source = gson.toJson(product);
request.source(source,XContentType.JSON);
//Execute query
IndexResponse response = restHighLevelClient.index(request, RequestOptions.DEFAULT);
System.out.println(response);
}2.4.5. Delete document
/**
* remove document
* @throws IOException
*/
@Test
void deleteDoc() throws IOException {
//Create the request object GetRequest and specify the id
DeleteRequest request = new DeleteRequest("lagou","item","1");
//Execute query
DeleteResponse response = restHighLevelClient.delete(request, RequestOptions.DEFAULT);
System.out.println(response);
}2.5. Search data
2.5.1. Query all matches_ all
/**
* Match all
* @throws IOException
*/
@Test
void matchAll() throws IOException {
//Create search object
SearchRequest request = new SearchRequest();
//Query build tool
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//Add query criteria and obtain various queries through QueryBuilders
sourceBuilder.query(QueryBuilders.matchAllQuery());
request.source(sourceBuilder);
//Execute query
SearchResponse search = restHighLevelClient.search(request, RequestOptions.DEFAULT);
//Get query results
SearchHits hits = search.getHits();
//Get file array
SearchHit[] searchHits = hits.getHits();
List<Product> productList = new ArrayList<>();
for (SearchHit searchHit : searchHits) {
String source = searchHit.getSourceAsString();
Product product = gson.fromJson(source, Product.class);
productList.add(product);
}
System.out.println(productList);
}Note that in the above code, the search criteria are added through sourceBuilder.query(QueryBuilders.matchAllQuery()). The parameters accepted by this query() method are: QueryBuilder interface type.
This interface provides many implementation classes corresponding to different types of queries we learned earlier, such as term query, match query, range query, boolean query, etc., as shown in the figure:
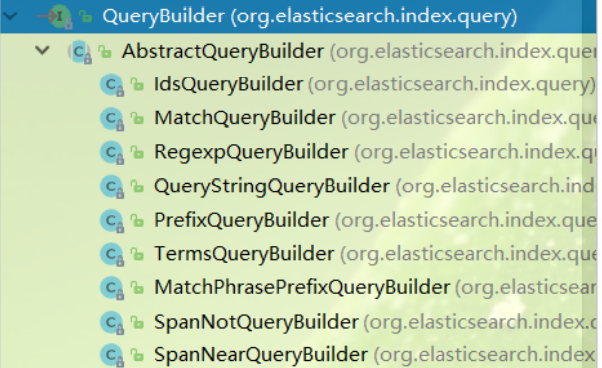
Therefore, if we want to use different queries, it is just the different parameters passed to the sourceBuilder.query() method. These implementation classes don't need us to go to new. QueryBuilders factory is officially provided to help us build various implementation classes:
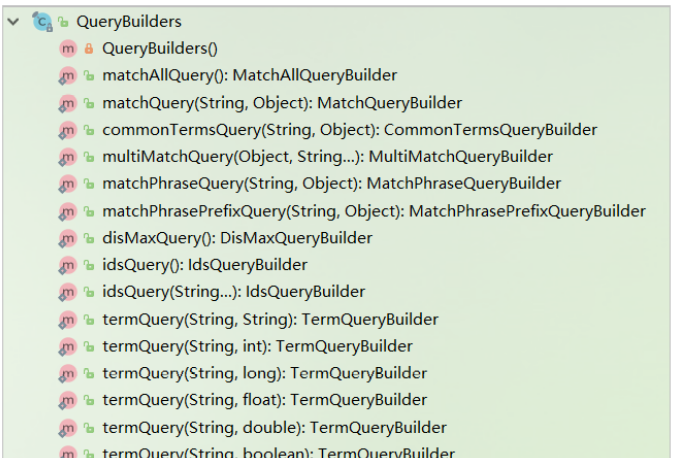
2.5.2. Keyword search match
Encapsulation basic query method:
/**
* Basic query method
* //Query build tool
* SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
* //Add query criteria and obtain various queries through QueryBuilders
* sourceBuilder.query(QueryBuilders.matchAllQuery());
*/
void basicQuery(SearchSourceBuilder sourceBuilder) throws IOException {
//Create search object
SearchRequest request = new SearchRequest();
request.source(sourceBuilder);
//Execute query
SearchResponse search = restHighLevelClient.search(request, RequestOptions.DEFAULT);
//Get query results
SearchHits hits = search.getHits();
//Get file array
SearchHit[] searchHits = hits.getHits();
List<Product> productList = new ArrayList<>();
for (SearchHit searchHit : searchHits) {
String source = searchHit.getSourceAsString();
Product product = gson.fromJson(source, Product.class);
productList.add(product);
}
System.out.println(productList);
} /**
* Keyword query
* @throws IOException
*/
@Test
void match() throws IOException {
SearchSourceBuilder builder = new SearchSourceBuilder();
//Set query criteria of query type
builder.query(QueryBuilders.matchQuery("title","P50"));
//Call basic query method
basicQuery(builder);
}2.5.3. range query
RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("price");
| method | explain |
| gt(Object from) | greater than |
| gte(Object from) | Greater than or equal to |
| lt(Object from) | less than |
| lte(Object from) | Less than or equal to |
Example:
/**
* Range query 30-100
* @throws IOException
*/
@Test
void range() throws IOException {
SearchSourceBuilder builder = new SearchSourceBuilder();
//Set query criteria of query type
builder.query(QueryBuilders.matchQuery("title","P50"));
builder.query(QueryBuilders.rangeQuery("price").gt(30).lt(100));
//Call basic query method
basicQuery(builder);
}
2.5.4.source filtering
_ source: store original document
By default, all data in the index library will be returned. If we want to return only some fields, we can control it through the source filter.
/**
* _source filter
* @throws IOException
*/
@Test
void sourceFilter() throws IOException {
SearchSourceBuilder builder = new SearchSourceBuilder();
//Set query criteria of query type
builder.query(QueryBuilders.matchQuery("title","P50"));
builder.query(QueryBuilders.rangeQuery("price").gt(30).lt(100));
builder.fetchSource(new String[]{"id","price","title"},new String[0]);
//Call basic query method
basicQuery(builder);
}2.6. Sorting
It is still configured through sourceBuilder:
/**
* sort
* @throws IOException
*/
@Test
void sort() throws IOException {
SearchSourceBuilder builder = new SearchSourceBuilder();
//Set query criteria of query type
builder.query(QueryBuilders.matchQuery("title","P50"));
builder.query(QueryBuilders.rangeQuery("price").gt(30).lt(100));
builder.fetchSource(new String[]{"id","price","title"},new String[0]);
builder.sort("price", SortOrder.DESC);
//Call basic query method
basicQuery(builder);
}2.7. Paging

/**
* paging
* @throws IOException
*/
@Test
void page() throws IOException {
SearchSourceBuilder builder = new SearchSourceBuilder();
//Set query criteria of query type
builder.query(QueryBuilders.matchAllQuery());
//Add paging
int page = 1;
int size =3;
int start = (page-1)*size;
//Configure paging
builder.from(start);
builder.size(size);
//Call basic query method
basicQuery(builder);
}3.Spring Data Elasticsearch
Next, let's learn the elasticsearch component provided by spring: Spring Data Elasticsearch
3.1. What is spring data elastic search
Spring Data Elasticsearch (hereinafter referred to as SDE) is a sub module under the Spring Data project.
The mission of Spring Data is to provide a unified programming interface for various data access, whether it is a relational database (such as MySQL), a non relational database (such as Redis), or an index database such as Elasticsearch. So as to simplify the developer's code and improve the development efficiency.
Page of Spring Data Elasticsearch: https://projects.spring.io/spring-data-elasticsearch/
features:
- Support Spring's @ Configuration based java Configuration mode or XML Configuration mode
- It provides a convenient tool class ElasticsearchTemplate for operating ES. This includes implementing automatic intelligent mapping between documents and POJO s.
- Use Spring's data transformation service to realize the function rich object mapping
- Annotation based metadata mapping, which can be extended to support more different data formats, can define JavaBean s: class names and attributes
- The corresponding implementation method is automatically generated according to the persistence layer interface without manual writing of basic operation code (similar to mybatis, it is automatically implemented according to the interface). Of course, manual customization query is also supported
3.2. Configure SpringDataElasticsearch
In the pom file, we introduce the initiator of SpringDataElasticsearch:
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-elasticsearch</artifactId> </dependency>
Then, just create a new application.yml file under resources and introduce the host and port of elasticsearch:
spring:
data:
elasticsearch:
cluster-name: lagou-elastic
cluster-nodes: 127.0.0.1:9301,127.0.0.1:9302,127.0.0.1:9303It should be noted that the bottom layer of SpringDataElasticsearch does not use RestHighLevelClient provided by elasticsearch, but TransportClient. It does not use Http protocol for communication, but accesses the tcp port opened by elasticsearch. In our previous cluster configuration, we set 930193029303 respectively
3.3. Index library operation
Prepare a pojo object, and then prepare a new entity class as the following document corresponding to the index library:
@Data
@Document(indexName = "lat",type = "product",shards = 3,replicas = 1)
@AllArgsConstructor
@NoArgsConstructor
public class Product {
@Id
private Long id;
@Field(value = "title",type = FieldType.Text,analyzer = "ik_max_word")
private String title; //title
@Field(value = "category",type = FieldType.Keyword)
private String category;// classification
@Field(value = "brand",type = FieldType.Keyword)
private String brand; // brand
@Field(value = "price",type = FieldType.Double)
private Double price; // Price
@Field(value = "images",type = FieldType.Keyword,index = false)
private String images; // Picture address
}- @Document: declare index library configuration
- indexName: index library name
- Type: type name. The default is "docs"
- shards: the number of shards. The default value is 5
- Replicas: number of replicas. The default is 1
- @id: the id of the declared entity class
- @Field: declare field properties
- Type: the data type of the field
- analyzer: Specifies the word breaker type
- Index: create index
We first create a test class, and then inject ElasticsearchTemplate:
@Autowired
private ElasticsearchTemplate template;
The following is an API example for creating an index library:
@Test
public void createIndex() {
//Method of creating index
template.createIndex(Product.class);
}The information that needs to be specified to create an index library, such as index library name, type name, fragmentation, number of copies, and mapping information, have been filled in
3.3.2. Create mapping
@Test
public void putMapping() {
//Create type mapping
template.putMapping(Product.class);
}3.4. Index data CRUD
The index data CRUD of SDE is not encapsulated in ElasticsearchTemplate, but has an interface called ElasticsearchRepository:
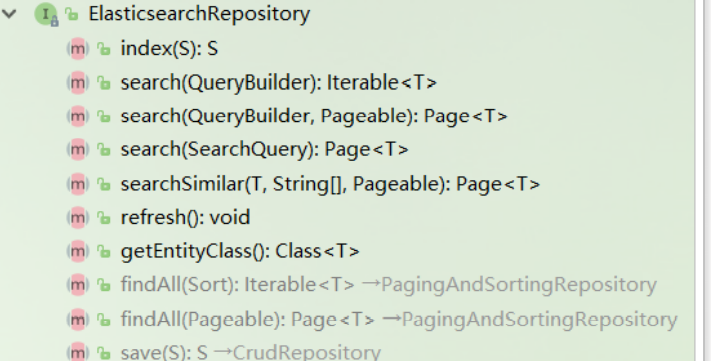
We need to customize the interface and inherit elasticsearchrepository:
/**
* @Author panghl
* @Date 2021/9/5 0:17
* @Description
* When SDE accesses the index library, it needs to define an interface of persistence layer to inherit ElasticsearchRepository without implementation
**/
public interface ProductRepository extends ElasticsearchRepository<Product, Long> {
/**
* Query by price range
* @param from Start price
* @param to End price
* @return Eligible goods
*/
List<Product> findByPriceBetween(Double from, Double to);
}3.4.1. Create index data
@Autowired
private ProductRepository productRepository;
@Test
public void addDoc() {
Product product1 = new Product(1L, "Smartisan Mobilephone", "mobile phone", "hammer", 3288.88d, "http://image.huawei.com/1.jpg");
Product product2 = new Product(2L, "Huawei mobile phone", "mobile phone", "Huawei", 3288.88d, "http://image.huawei.com/1.jpg");
Product product3 = new Product(3L, "Mi phones", "mobile phone", "millet", 3288.88d, "http://image.huawei.com/1.jpg");
Product product4 = new Product(4L, "iPhone", "mobile phone", "Apple", 3288.88d, "http://image.huawei.com/1.jpg");
Product product5 = new Product(5L, "OPPO mobile phone", "mobile phone", "OPPO", 3288.88d, "http://image.huawei.com/1.jpg");
List<Product> productList = new ArrayList<>();
productList.add(product1);
productList.add(product2);
productList.add(product3);
productList.add(product4);
productList.add(product5);
productRepository.saveAll(productList);
System.out.println("save success");
}3.4.2. Query index data
By default, you can query all two functions by id:
@Test
public void queryIndexData() {
Product product = productRepository.findById(1L).orElse(new Product());
//Fetch data
//Role of orElse method: if the entity object encapsulated in optional is empty, that is, no matching document is found from the index library, return the orElse parameter
System.out.println("product=>" + product);
}3.4.3. User defined method query
The query methods provided by the product repository are limited, but it provides a very powerful custom query function:
As long as we follow the syntax provided by spring data, we can define method declarations arbitrarily:
/**
* Query by price range
* @param from Start price
* @param to End price
* @return Eligible goods
*/
List<Product> findByPriceBetween(Double from, Double to);There is no need to write an implementation. SDE will automatically help us implement this method. We just need to use:
@Test
public void querySelfIndexData() {
List<Product> byPriceBetween = productRepository.findByPriceBetween(1000d, 4000d);
System.out.println(byPriceBetween);
}Some syntax examples supported:
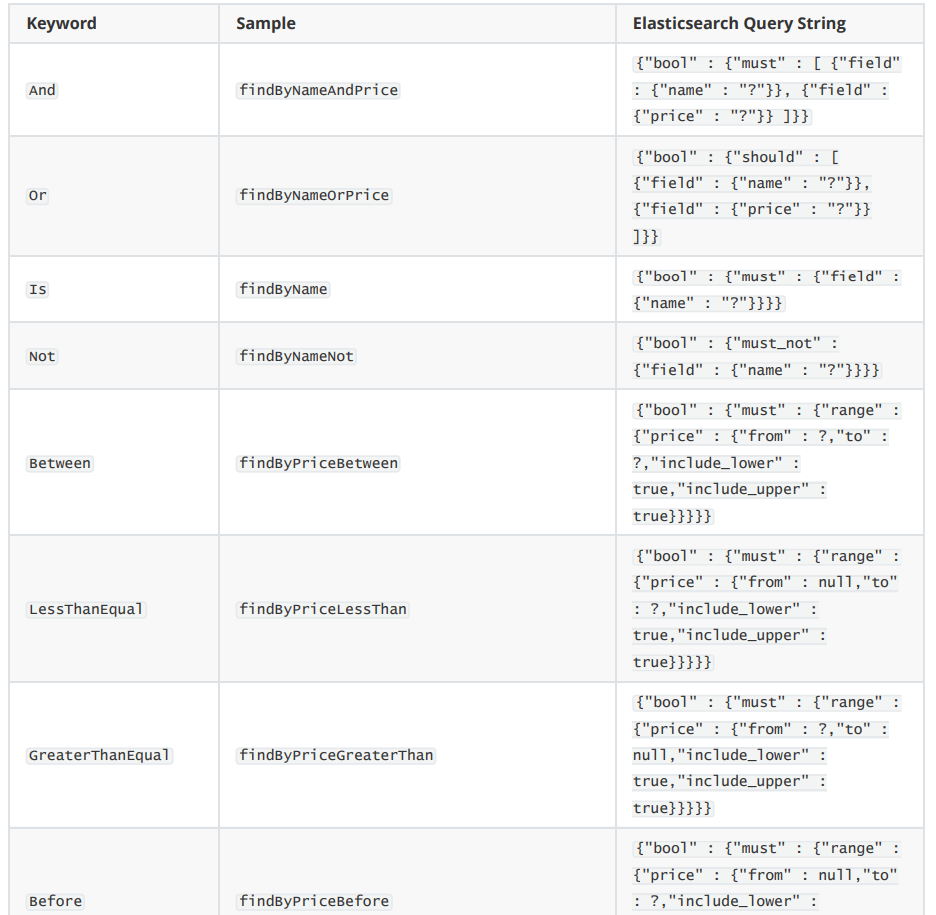


3.5. Native Query
If you think the above interface still doesn't meet your needs, SDE also supports native queries. At this time, you still use ElasticsearchTemplate
The construction of query conditions is completed through a class called NativeSearchQueryBuilder, but the bottom layer of this class still uses QueryBuilders, AggregationBuilders, HighlightBuilders and other tools in the native API.
Demand: query the goods of Xiaomi mobile phone contained in the title, sort them in ascending order of price, page by page query: display 2 items per page, query page 1. Aggregate and analyze query results: obtain brands and numbers
Example
/**
* Query the goods of Xiaomi mobile phone contained in the title, sorted in ascending order of price, and paged query: 2 items are displayed on each page, and page 1 is queried.
* Aggregate and analyze query results: obtain brands and numbers
*/
@Test
public void nativeQuery() {
//1. Build a Native Query
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
//2.source come here
//2.1 parameter: public FetchSourceFilter(String[] includes, String[] excludes)
queryBuilder.withSourceFilter(new FetchSourceFilter(new String[0], new String[0]));
//3. Query criteria
queryBuilder.withQuery(QueryBuilders.matchQuery("title","Mi phones"));
//4. Set paging and sort
queryBuilder.withPageable(PageRequest.of(0,10, Sort.by(Sort.Direction.ASC,"price")));
//Highlight
// HighlightBuilder.Field field = new HighlightBuilder.Field("title");
HighlightBuilder builder = new HighlightBuilder();
builder.field("title");
builder.preTags("<font style='color:red'>");
builder.postTags("</font>");
//Set to 0 to return full content instead of fragments
builder.numOfFragments(0);
queryBuilder.withHighlightBuilder(builder);
//5. Aggregate and analyze query results: obtain brands and numbers
queryBuilder.addAggregation(AggregationBuilders.terms("brandAgg").field("brand").missing("title"));
//6. Query
AggregatedPage<Product> result = template.queryForPage(queryBuilder.build(), Product.class,new ESSearchResultMapper());
System.out.println(result);
//7. Get results
//total
long total = result.getTotalElements();
//Page number
int totalPage = result.getTotalPages();
//Get the data set of the industry
List<Product> content = result.getContent();
content.stream().forEach(System.out::print);
//Get aggregate results
Aggregations aggregations = result.getAggregations();
Terms terms = aggregations.get("brandAgg");
//Get the bucket and traverse the contents of the bucket
terms.getBuckets().forEach(b->{
System.out.println("brand->"+b.getKey());
System.out.println("Number of documents->"+b.getDocCount());
});
}Note: the above query does not support highlighted results.
Highlight:
1. Custom search result mapping
/**
* @Author panghl
* @Date 2021/9/5 1:09
* @Description Custom result mapping, handling highlighting
**/
public class ESSearchResultMapper implements SearchResultMapper {
/**
* Complete result mapping
* The operation should focus on the original results:_ Take out the source and put it into the highlighted data
*
* @param searchResponse
* @param aClass
* @param pageable
* @param <T>
* @return AggregatedPage Three parameters are required for construction: pageable, list < Product >, and total records
*/
@Override
public <T> AggregatedPage<T> mapResults(SearchResponse searchResponse, Class<T> aClass, Pageable pageable) {
//Get total records
SearchHits hits = searchResponse.getHits();
long totalHits = hits.getTotalHits();
System.out.println("Total records->" + totalHits);
Gson gson = new Gson();
//Record list
List<T> productList = new ArrayList<>();
for (SearchHit hit : hits) {
if (hits.getHits().length <= 0) {
return null;
}
//Get_ All data in the source attribute
Map<String, Object> map = hit.getSourceAsMap();
//Gets the highlighted field
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
//Each highlighted field needs to be set
for (Map.Entry<String, HighlightField> highlightField : highlightFields.entrySet()) {
//Get highlighted key: highlighted field
String key = highlightField.getKey();
//Get value: the effect after highlighting
HighlightField value = highlightField.getValue();
//Place highlighted fields and text effects in the map
map.put(key, value.getFragments()[0].toString());
}
//Convert map to object
T T = gson.fromJson(gson.toJson(map), aClass);
productList.add(T);
}
//The fourth parameter, response.getAggregations(), adds the aggregation result
return new AggregatedPageImpl<>(productList,pageable,totalHits,searchResponse.getAggregations(),searchResponse.getScrollId());
}
@Override
public <T> T mapSearchHit(SearchHit searchHit, Class<T> aClass) {
return null;
}
}2. Highlight implementation:
