Naive Bayesian algorithm is simple and efficient.Next, we will describe how it can be used to identify the authors of A Dream of Red Mansions.
The first step, of course, is to have text data first. I downloaded a txt freely on the Internet (I was in a hurry to hand in the draft at that time.)Classification is definitely a round-by-turn score, so when we get the text data, we divide the rounds first.Then, punctuation and word segmentation are removed to make word frequency statistics.
1 # -*- coding: utf-8 -*- 2 import re 3 import jieba 4 import string 5 import collections as coll 6 jieba.load_userdict('E:\\forpython\\Red Chamber Dream Vocabulary Complete.txt') # Import Red Chamber Dream Thesaurus of Sogou 7 8 9 class textprocesser: 10 def __init__(self): 11 pass 12 13 # Divide the novel into 120 chapters and save it separately in a txt file 14 def divide_into_chapter(self): 15 red=open('E:\\forpython\\The Dream of Red Mansion.txt',encoding='utf-8') 16 each_line = red.readline() 17 chapter_count = 0 18 chapter_text = '' 19 complied_rule = re.compile('No.[123,345,667,890]+return ') 20 21 while each_line: 22 if re.findall(complied_rule,each_line): 23 file_name = 'chap'+str(chapter_count) 24 file_out = open('E:\\forpython\\chapters\\'+file_name+'.txt','a',encoding = 'utf-8') 25 file_out.write(chapter_text) 26 chapter_count += 1 27 file_out.close() 28 chapter_text = each_line 29 else: 30 chapter_text += each_line 31 32 each_line = red.readline() 33 34 red.close() 35 36 37 # Word breaks for individual chapters 38 def segmentation(self,text,text_count): 39 file_name = 'chap'+str(text_count)+'-words.txt' 40 file_out = open('E:\\forpython\\chapter2words\\'+file_name,'a',encoding='utf-8') 41 delset = string.punctuation 42 43 line=text.readline() 44 45 while line: 46 seg_list = jieba.cut(line,cut_all = False) 47 words = " ".join(seg_list) 48 words = words.translate(delset) # Remove English Punctuation 49 words = "".join(words.split('\n')) # Remove carriage return 50 words = self.delCNf(words) # Remove Chinese Punctuation 51 words = re.sub('[ \u3000]+',' ',words) # Remove extra spaces 52 file_out.write(words) 53 line = text.readline() 54 55 file_out.close() 56 text.close() 57 58 59 # Participle for all chapters 60 def do_segmentation(self): 61 for loop in range(1,121): 62 file_name = 'chap'+str(loop)+'.txt' 63 file_in = open('E:\\forpython\\chapters\\'+file_name,'r',encoding = 'utf-8') 64 65 self.segmentation(file_in,loop) 66 67 file_in.close() 68 69 # Remove Chinese Character Function 70 def delCNf(self,line): 71 regex = re.compile('[^\u4e00-\u9fa5a-zA-Z0-9\s]') 72 return regex.sub('', line) 73 74 75 # Word frequency statistics after punctuation removal 76 def count_words(self,text,textID): 77 line = str(text) 78 words = line.split() 79 words_dict = coll.Counter(words) # Generate word frequency dictionary 80 81 file_name = 'chap'+str(textID)+'-wordcount.txt' 82 file_out = open('E:\\forpython\\chapter-wordcount\\'+file_name,'a',encoding = 'utf-8') 83 84 # Write text after sorting 85 sorted_result = sorted(words_dict.items(),key = lambda d:d[1],reverse = True) 86 for one in sorted_result: 87 line = "".join(one[0] + '\t' + str(one[1]) + '\n') 88 file_out.write(line) 89 90 file_out.close() 91 92 93 94 def do_wordcount(self): 95 for loop in range(1,121): 96 file_name = 'chap'+str(loop)+'-words.txt' 97 file_in = open('E:\\forpython\\chapter2words\\'+file_name,'r',encoding = 'utf-8') 98 line = file_in.readline() 99 100 text = '' 101 while line: 102 text += line 103 line = file_in.readline() 104 self.count_words(text,loop) 105 file_in.close() 106 107 108 if __name__ == '__main__': 109 processer = textprocesser() 110 processer.divide_into_chapter() 111 processer.do_segmentation() 112 processer.do_wordcount()
Text categorization I personally feel the most important thing is to select the eigenvector. I consulted the relevant literature and decided to select more than 50 classical function words and more than 20 words that have appeared in 120 rounds (the use of classical function words is not affected by the plot, only related to the author's writing habits).Here is the generation
Code for eigenvectors
1 # -*- coding: utf-8 -*- 2 import jieba 3 import re 4 import string 5 import collections as coll 6 jieba.load_userdict('E:\\forpython\\Red Chamber Dream Vocabulary Complete.txt') # Import Red Chamber Dream Thesaurus of Sogou 7 8 class featureVector: 9 def __init__(self): 10 pass 11 12 # Remove Chinese Character Function 13 def delCNf(self,line): 14 regex = re.compile('[^\u4e00-\u9fa5a-zA-Z0-9\s]') 15 return regex.sub('', line) 16 17 18 # Partition the whole article 19 def cut_words(self): 20 red = open('E:\\forpython\\The Dream of Red Mansion.txt','r',encoding = 'utf-8') 21 file_out = open('E:\\forpython\\The Dream of Red Mansion-Words.txt','a',encoding = 'utf-8') 22 delset = string.punctuation 23 24 line = red.readline() 25 26 while line: 27 seg_list = jieba.cut(line,cut_all = False) 28 words = ' '.join(seg_list) 29 words = words.translate(delset) # Remove English Punctuation 30 words = "".join(words.split('\n')) # Remove carriage return 31 words = self.delCNf(words) # Remove Chinese Punctuation 32 words = re.sub('[ \u3000]+',' ',words) # Remove extra spaces 33 file_out.write(words) 34 line = red.readline() 35 36 file_out.close() 37 red.close() 38 39 # Statistics word frequency 40 def count_words(self): 41 data = open('E:\\forpython\\The Dream of Red Mansion-Words.txt','r',encoding = 'utf-8') 42 line = data.read() 43 data.close() 44 words = line.split() 45 words_dict = coll.Counter(words) # Generate word frequency dictionary 46 47 file_out = open('E:\\forpython\\The Dream of Red Mansion-word frequency.txt','a',encoding = 'utf-8') 48 49 # Write text after sorting 50 sorted_result = sorted(words_dict.items(),key = lambda d:d[1],reverse = True) 51 for one in sorted_result: 52 line = "".join(one[0] + '\t' + str(one[1]) + '\n') 53 file_out.write(line) 54 55 file_out.close() 56 57 58 59 def get_featureVector(self): 60 # Put 120 chapters of text after word breaking into a list 61 everychapter = [] 62 for loop in range(1,121): 63 data = open('E:\\forpython\\chapter2words\\chap'+str(loop)+'-words.txt','r',encoding = 'utf-8') 64 each_chapter = data.read() 65 everychapter.append(each_chapter) 66 data.close() 67 68 temp = open('E:\\forpython\\The Dream of Red Mansion-Words.txt','r',encoding = 'utf-8') 69 word_beg = temp.read() 70 word_beg = word_beg.split(' ') 71 temp.close() 72 73 # Find words that appear in every turn 74 cleanwords = [] 75 for loop in range(1,121): 76 data = open('E:\\forpython\\chapter2words\\chap'+str(loop)+'-words.txt','r',encoding = 'utf-8') 77 words_list = list(set(data.read().split())) 78 data.close() 79 cleanwords.extend(words_list) 80 81 cleanwords_dict = coll.Counter(cleanwords) 82 83 cleanwords_dict = {k:v for k, v in cleanwords_dict.items() if v >= 120} 84 85 cleanwords_f = list(cleanwords_dict.keys()) 86 87 xuci = open('E:\\forpython\\Classical Functional Words.txt','r',encoding = 'utf-8') 88 xuci_list = xuci.read().split() 89 xuci.close() 90 featureVector = list(set(xuci_list + cleanwords_f)) 91 featureVector.remove('\ufeff') 92 93 # Write text 94 file_out = open('E:\\forpython\\The Dream of Red Mansion-feature vector.txt','a',encoding = 'utf-8') 95 for one in featureVector: 96 line = "".join(one+ '\n') 97 file_out.write(line) 98 99 file_out.close() 100 return(featureVector) 101 102 if __name__ == '__main__': 103 vectorbuilter = featureVector() 104 vectorbuilter.cut_words() 105 vectorbuilter.count_words() 106 vectorbuilter.get_featureVector()
Naive Bayesian text classification uses the word frequency of the eigenvector as the representative of each turn (lazy, direct screenshot ppt)
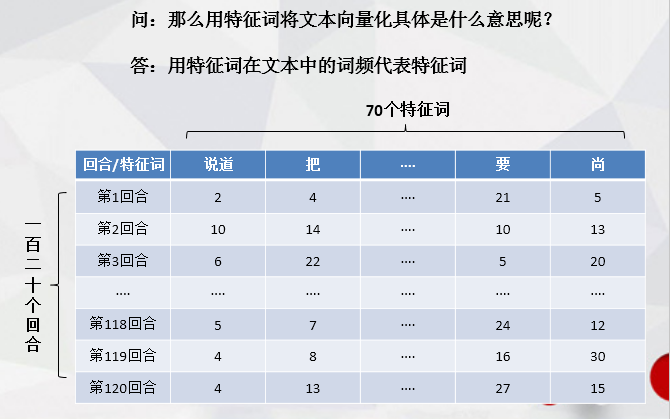
After vectorizing all 120 rounds with eigenvectors, you get an array of 120 by 70.Now it's easy.Directly select the training set, in which I marked 20 to 29 of the first 80 rounds as the first (represented by number 1) training set and used them as the first; in the latter 80 rounds, 110 to 119 rounds were selected as the second (represented by number 2) training set.
1 # -*- coding: utf-8 -*- 2 3 import numpy as np 4 from sklearn.naive_bayes import MultinomialNB 5 import get_trainset as ts 6 x_train = ts.get_train_set().get_all_vector() 7 8 9 10 class result: 11 def __inti__(self): 12 pass 13 14 def have_Xtrainset(self): 15 Xtrainset = x_train 16 Xtrainset = np.vstack((Xtrainset[19:29],Xtrainset[109:119])) 17 return(Xtrainset) 18 19 def as_num(self,x): 20 y='{:.10f}'.format(x) 21 return(y) 22 23 def built_model(self): 24 x_trainset = self.have_Xtrainset() 25 y_classset = np.repeat(np.array([1,2]),[10,10]) 26 27 NBclf = MultinomialNB() 28 NBclf.fit(x_trainset,y_classset) # Modeling 29 30 all_vector = x_train 31 32 result = NBclf.predict(all_vector) 33 print('Front'+str(len(result[0:80]))+'The result of reclassification is:') 34 print(result[0:80]) 35 print('after'+str(len(result[80:121]))+'The result of reclassification is:') 36 print(result[80:121]) 37 38 diff_chapter = [80,81,83,84,87,88,90,100] 39 for i in diff_chapter: 40 tempr = NBclf.predict_proba(all_vector[i]) 41 print('No.'+str(i+1)+'The classification probability returned is: ') 42 print(str(self.as_num(tempr[0][0]))+' '+str(self.as_num(tempr[0][1]))) 43 44 45 if __name__ == '__main__': 46 res = result() 47 res.built_model()
The skit-learn s MultiminomialNB function is called directly above, as I explained in the previous article.
The classification results are:
From the final classification results, there is a clear dividing point around Round 82, so it seems that there is still a significant difference in writing style between Round 80 and Round 40. This result is consistent with the year inference of the Red Chamber Dream academia.
As for why eight of the last 40 rounds were grouped into categories, there were 81 rounds, 82 rounds, 84 rounds, 85 rounds, 88 rounds, 89 rounds, 91 rounds and 101 rounds, all around Round 80. This difference may be caused by the convergence of contexts. Because the text of Dream of Red Chamber used in this article was downloaded from the Internet, the version is unknown, so it can also be used.Can be caused by the version of Dream of Red Mansions.
There must be a lot more to optimize in the code, so make a fool of it here...