As mentioned in the previous article, Python is simple and efficient because it has rich functions that can be used immediately. Recently, I read some technical articles of Github and found some interesting and practical Python libraries. It's a feeling that I'm too late to meet each other. Today, I will sort out these libraries and share them with you.
pandas_profiling
Before data analysis, you need to take a look at the general situation of the data, pandas_ The profiling tool can quickly preview data, provide a clear understanding of the overall data overview and data quality, and is very helpful for data production. A detailed data report can save us a lot of time (less code typing) and not use it quickly.
1. Installation
pip install pandas-profiling
2. Overall data preview
import pandas as pd
import pandas_profiling
data = pd.read_csv('https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv')
data.describe()
pandas_profiling.ProfileReport(data)
3. Data analysis report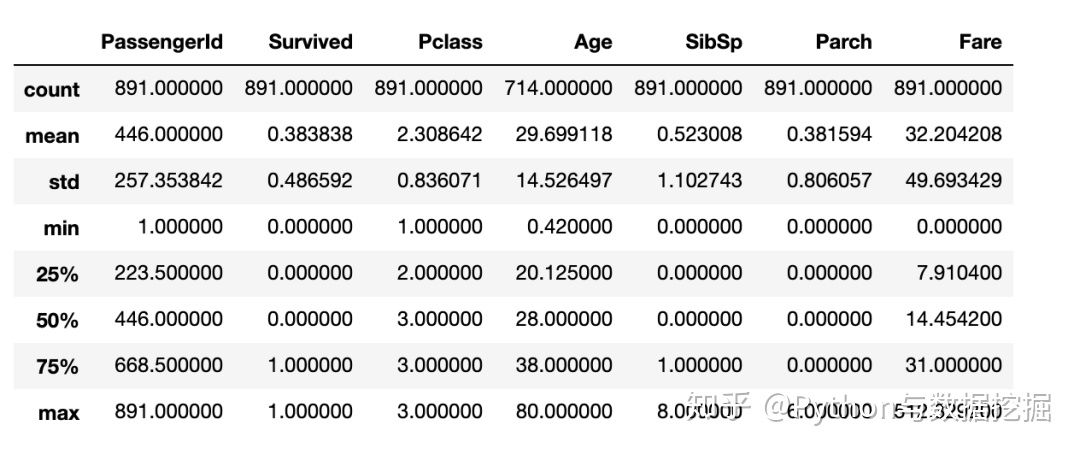
PyOD
There is no shortcut to data exploration. If you skip the data science stage and go directly to the model building stage, after a period of time, you will find that the accuracy will reach the upper limit, that is, the performance of the model will not improve. This is because outliers (also known as "discrete values") are often overlooked.
In the previous article Dry goods sharing small partners in the data field, exception detection is enough In, we have shared some algorithms for anomaly detection. Recently, we found the PyOD library. PyOD is a library for detecting outliers in data. It can access more than 20 different algorithms to detect outliers, and it is compatible with Python 2 and 3. It is easy to use.
1. Installation
pip install pyod # normal install pip install --upgrade pyod # or update if needed pip install --pre pyod # or include pre-release version for new features
2. Examples
from __future__ import division
from __future__ import print_function
import os
import sys
# temporary solution for relative imports in case pyod is not installed
# if pyod is installed, no need to use the following line
sys.path.append(
os.path.abspath(os.path.join(os.path.dirname("__file__"), '..')))
from pyod.models.lof import LOF
from pyod.utils.data import generate_data
from pyod.utils.data import evaluate_print
from pyod.utils.example import visualize
if __name__ == "__main__":
contamination = 0.1 # percentage of outliers
n_train = 200 # number of training points
n_test = 100 # number of testing points
# Generate sample data
X_train, y_train, X_test, y_test = \
generate_data(n_train=n_train,
n_test=n_test,
n_features=2,
contamination=contamination,
random_state=42)
# train LOF detector
clf_name = 'LOF'
clf = LOF()
clf.fit(X_train)
# get the prediction labels and outlier scores of the training data
y_train_pred = clf.labels_ # binary labels (0: inliers, 1: outliers)
y_train_scores = clf.decision_scores_ # raw outlier scores
# get the prediction on the test data
y_test_pred = clf.predict(X_test) # outlier labels (0 or 1)
y_test_scores = clf.decision_function(X_test) # outlier scores
# evaluate and print the results
print("\nOn Training Data:")
evaluate_print(clf_name, y_train, y_train_scores)
print("\nOn Test Data:")
evaluate_print(clf_name, y_test, y_test_scores)
# visualize the results
visualize(clf_name, X_train, y_train, X_test, y_test, y_train_pred,
y_test_pred, show_figure=True, save_figure=False)
tushare
Tushare is a free and open source python financial data interface package. It mainly realizes the process from data collection, cleaning and processing to data storage for financial data such as stocks. It can provide financial analysts with fast, clean and diverse data that is easy to analyze, greatly reduce their workload in data acquisition, and make them pay more attention to the research and implementation of strategies and models. Considering the advantages of Python pandas package in financial quantitative analysis, most of the data formats returned by tushare are of pandas DataFrame type, which is very convenient for data analysis and visualization with pandas/NumPy/Matplotlib.
For those who are learning to use python for data analysis, they can provide a public data set, in addition, the database provides instant news and real-time box office data, which is a good place to practice data.
1. Access to data
import tushare as ts #Get the trading data of all stocks on the latest trading day at one time ts.get_today_all() #News data ts.get_notices()
2. Data display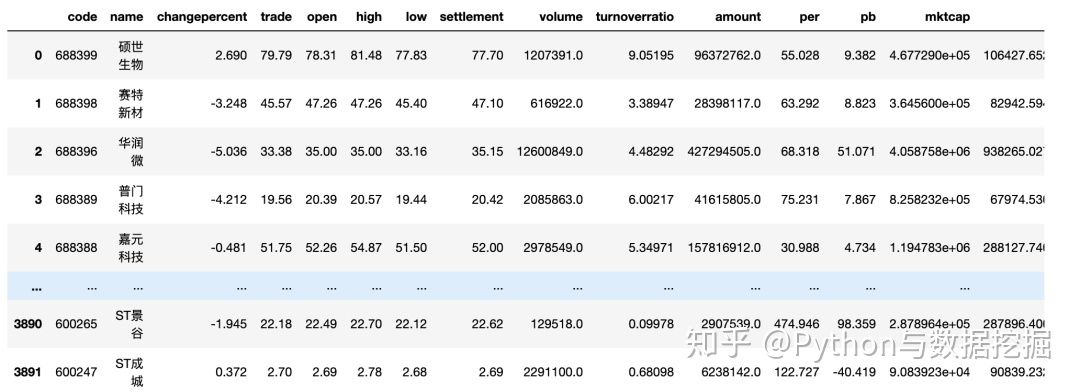
Wget
Extracting data from the Internet is one of the most important tasks for data scientists. WGet is a free utility that can be used to download non interactive files from the network. It supports HTTP, HTTPS and FTP protocols, as well as file retrieval through HTTP's proxy. Because it is non interactive, it can work in the background even if the user is not logged in. So next time you want to download a website or all the pictures on a page, WGet can help you.
1. Installation
pip install wget
2. Examples
import wget url = 'http://www.futurecrew.com/skaven/song_files/mp3/razorback.mp3' filename = wget.download(url) 100% [................................................] 3841532 / 3841532 filename razorback.mp3
imbalanced-learn
In the model training, how to deal with the data imbalance has been bothering the data mining engineers, and the imbalanced learn has solved it for you. Imblearn provides SMOTEENN method to solve data balance processing. Therefore, you need to download the corresponding package imblearn.
1. Installation
pip install imblearn
2. usage
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.decomposition import PCA
import numpy as np
import pandas as pd
from imblearn.combine import SMOTEENN
# Generate the dataset
X, y = make_classification(n_classes=2, class_sep=2, weights=[0.1, 0.9],
n_informative=3, n_redundant=1, flip_y=0,
n_features=20, n_clusters_per_class=1,
n_samples=100, random_state=10)
sm = SMOTEENN()
X_resampled, y_resampled = sm.fit_sample(X, y)
print(y_resampled)
print(y_resampled.shape)
smtplib
SMTP(Simple Mail Transfer Protocol) is a simple mail transfer protocol. It is a set of rules used to transfer mail from the source address to the destination address. It controls the transfer mode of mail. python's smtplib provides a convenient way to send email. It simply encapsulates the protocol of smtp.
Python's SMTP library, front-end technology and database are combined. Some routine data analysis reports are sent by automated mail every week, saving time and effort, and improving work efficiency.
The syntax for creating SMTP objects in Python is as follows:
import smtplib smtpObj = smtplib.SMTP( [host [, port [, local_hostname]]] )
Example
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import smtplib
from email.mime.text import MIMEText
from email.header import Header
sender = '********'
receivers = ['********'] # Receive email
message = MIMEText('Python Mail sending test...', 'plain', 'utf-8')
message['From'] = Header("Python Learning and data mining", 'utf-8') # sender
message['To'] = Header("test", 'utf-8') # recipient
subject = 'Python SMTP Mail test'
message['Subject'] = Header(subject, 'utf-8')
try:
smtpObj = smtplib.SMTP('localhost')
smtpObj.sendmail(sender, receivers, message.as_string())
print "Mail sent successfully"
except smtplib.SMTPException:
print "Error: Unable to send message"
youtube-dl
Are you still bothered that you can't download the website video? Try youtube DL to help you get it all done. Today, share and introduce this powerful command-line download artifact to see if the name thinks it's a tool specifically for downloading videos from youtube websites. In fact, it supports video downloads from hundreds of websites around the world. Maybe it's because there's a wall in China. youtube DL supports those websites that don't exist outside the wall better Some.
1. Installation
pip install youtube-dl #install pip install --upgrade youtube-dl #upgrade
2. Usage
[root@bear ~]# youtube-dl --max-quality url http://www.youtube.com/watch?v=XXXXXX [root@bear ~]# youtube-dl --max-quality url http://v.youku.com/v_show/id_XXXXXX.html [root@bear ~]# youtube-dl --list-extractors #View list of support websites [root@bear ~]# youtube-dl -U #Program upgrade
More interesting content, focus on WeChat official account "Python learning and data mining".
In order to facilitate the technical exchange, this number has opened the technical exchange group, and WeChat: connect_we, remarks: CSDN, welcome to reprint, collection, code word is not easy, like small edit point like!