@
preface
Spring boot is the packaging of spring. Through automatic configuration, spring boot can be used out of the box with very low starting cost. However, the cost of learning its implementation principle is greatly increased. You need to first understand and be familiar with spring principle. If you don't know the principle of spring, you can check the previous articles of the blogger. This article mainly analyzes the principle of spring boot startup, automatic configuration, Condition and event driven.
text
Starting principle
Spring boot is very simple to start. Because Tomcat is built in, you only need to start it in the following ways:
@SpringBootApplication(scanBasePackages = {"cn.dark"})
public class SpringbootDemo {
public static void main(String[] args) {
// The first
SpringApplication.run(SpringbootDemo .class, args);
// The second
new SpringApplicationBuilder(SpringbootDemo .class)).run(args);
// The third
SpringApplication springApplication = new SpringApplication(SpringbootDemo.class);
springApplication.run();
}
}
You can see that the first is the simplest and most commonly used way. Note that @ SpringBootApplication annotation needs to be marked on the class. This is the core implementation of automatic configuration. Later, we will analyze what spring boot does first?
Before moving on, let's guess what needs to be done in the run method? Compared with spring source code, we know that when spring is started, an application context object of ApplicationContext will be created and its refresh method will be called to start the container. Spring boot is just a shell of spring, and such an operation will certainly not be avoided. On the other hand, previous projects built through spring need to be published to Tomcat as War package, but now spring boot has built-in tomcat, which only needs to be started as Jar package, so corresponding Tomcat objects will be created and started in the run method. The above is just our conjecture. Let's verify it and enter the run method:
public ConfigurableApplicationContext run(String... args) {
// Tool class for time statistics
StopWatch stopWatch = new StopWatch();
stopWatch.start();
ConfigurableApplicationContext context = null;
Collection<SpringBootExceptionReporter> exceptionReporters = new ArrayList<>();
configureHeadlessProperty();
// Obtain the implementation class that implements the SpringApplicationRunListener interface, and load it through the SPI mechanism
// META-INF/spring.factories Classes under files
SpringApplicationRunListeners listeners = getRunListeners(args);
// First call the starting method of SpringApplicationRunListener
listeners.starting();
try {
ApplicationArguments applicationArguments = new DefaultApplicationArguments(args);
// Processing configuration data
ConfigurableEnvironment environment = prepareEnvironment(listeners, applicationArguments);
configureIgnoreBeanInfo(environment);
// Print banner on startup
Banner printedBanner = printBanner(environment);
// Create context object
context = createApplicationContext();
// Get the class of SpringBootExceptionReporter interface, exception report
exceptionReporters = getSpringFactoriesInstances(SpringBootExceptionReporter.class,
new Class[] { ConfigurableApplicationContext.class }, context);
prepareContext(context, environment, listeners, applicationArguments, printedBanner);
// Core method, start spring container
refreshContext(context);
afterRefresh(context, applicationArguments);
// End of Statistics
stopWatch.stop();
if (this.logStartupInfo) {
new StartupInfoLogger(this.mainApplicationClass).logStarted(getApplicationLog(), stopWatch);
}
// Call started
listeners.started(context);
// ApplicationRunner
// CommandLineRunner
// Get the implementation classes of these two interfaces and call their run methods
callRunners(context, applicationArguments);
}
catch (Throwable ex) {
handleRunFailure(context, ex, exceptionReporters, listeners);
throw new IllegalStateException(ex);
}
try {
// Finally, call the running method.
listeners.running(context);
}
catch (Throwable ex) {
handleRunFailure(context, ex, exceptionReporters, null);
throw new IllegalStateException(ex);
}
return context;
}
The starting process of spring boot is this method. First, look at the getRunListeners method. This method is to get all the spring applicationrunlistener implementation classes. These classes are used for spring boot event publishing. Later, we will analyze the event driver. Here we mainly see the implementation principle of this method:
private SpringApplicationRunListeners getRunListeners(String[] args) {
Class<?>[] types = new Class<?>[] { SpringApplication.class, String[].class };
return new SpringApplicationRunListeners(logger,
getSpringFactoriesInstances(SpringApplicationRunListener.class, types, this, args));
}
private <T> Collection<T> getSpringFactoriesInstances(Class<T> type, Class<?>[] parameterTypes, Object... args) {
ClassLoader classLoader = getClassLoader();
// Use names and ensure unique to protect against duplicates
Set<String> names = new LinkedHashSet<>(SpringFactoriesLoader.loadFactoryNames(type, classLoader));
// Reflection instantiation after loading
List<T> instances = createSpringFactoriesInstances(type, parameterTypes, classLoader, args, names);
AnnotationAwareOrderComparator.sort(instances);
return instances;
}
public static List<String> loadFactoryNames(Class<?> factoryType, @Nullable ClassLoader classLoader) {
String factoryTypeName = factoryType.getName();
return loadSpringFactories(classLoader).getOrDefault(factoryTypeName, Collections.emptyList());
}
public static final String FACTORIES_RESOURCE_LOCATION = "META-INF/spring.factories";
private static Map<String, List<String>> loadSpringFactories(@Nullable ClassLoader classLoader) {
MultiValueMap<String, String> result = cache.get(classLoader);
if (result != null) {
return result;
}
try {
Enumeration<URL> urls = (classLoader != null ?
classLoader.getResources(FACTORIES_RESOURCE_LOCATION) :
ClassLoader.getSystemResources(FACTORIES_RESOURCE_LOCATION));
result = new LinkedMultiValueMap<>();
while (urls.hasMoreElements()) {
URL url = urls.nextElement();
UrlResource resource = new UrlResource(url);
Properties properties = PropertiesLoaderUtils.loadProperties(resource);
for (Map.Entry<?, ?> entry : properties.entrySet()) {
String factoryTypeName = ((String) entry.getKey()).trim();
for (String factoryImplementationName : StringUtils.commaDelimitedListToStringArray((String) entry.getValue())) {
result.add(factoryTypeName, factoryImplementationName.trim());
}
}
}
cache.put(classLoader, result);
return result;
}
}
Step by step, you can see that the final step is to use SPI mechanism to select meta-inf according to the interface type/ spring.factories The corresponding implementation class is loaded in the file and instantiated, as is the automatic configuration of SpringBoot. Why is it implemented like this? Can't you scan through comments? Of course, these classes are all in the third-party jar package, and annotation scanning is very troublesome. Of course, you can Import them through @ Import annotation, but this method is not suitable for the case where there are many extension classes, so the advantages of using SPI here are obvious.
Back in the run method, you can see that the createApplicationContext method is called, as the name implies. This is to create an application context object:
public static final String DEFAULT_SERVLET_WEB_CONTEXT_CLASS = "org.springframework.boot."
+ "web.servlet.context.AnnotationConfigServletWebServerApplicationContext";
protected ConfigurableApplicationContext createApplicationContext() {
Class<?> contextClass = this.applicationContextClass;
if (contextClass == null) {
try {
switch (this.webApplicationType) {
case SERVLET:
contextClass = Class.forName(DEFAULT_SERVLET_WEB_CONTEXT_CLASS);
break;
case REACTIVE:
contextClass = Class.forName(DEFAULT_REACTIVE_WEB_CONTEXT_CLASS);
break;
default:
contextClass = Class.forName(DEFAULT_CONTEXT_CLASS);
}
}
catch (ClassNotFoundException ex) {
throw new IllegalStateException(
"Unable create a default ApplicationContext, please specify an ApplicationContextClass", ex);
}
}
return (ConfigurableApplicationContext) BeanUtils.instantiateClass(contextClass);
}
Note that a new context object annotation configservletwebserver ApplicationContext is instantiated by reflection here. This is an extension of SpringBoot. See its construction method:
public AnnotationConfigServletWebServerApplicationContext() {
this.reader = new AnnotatedBeanDefinitionReader(this);
this.scanner = new ClassPathBeanDefinitionScanner(this);
}
If you have seen the implementation principle of Spring annotation driven, these two objects will certainly be familiar. One supports annotation parsing, and the other is scan package.
After the context is created, the next step is to call the refresh method to start the container:
private void refreshContext(ConfigurableApplicationContext context) {
refresh(context);
if (this.registerShutdownHook) {
try {
context.registerShutdownHook();
}
catch (AccessControlException ex) {
// Not allowed in some environments.
}
}
}
protected void refresh(ApplicationContext applicationContext) {
Assert.isInstanceOf(AbstractApplicationContext.class, applicationContext);
((AbstractApplicationContext) applicationContext).refresh();
}
First, call ServletWebServerApplicationContext in its parent class:
public final void refresh() throws BeansException, IllegalStateException {
try {
super.refresh();
}
catch (RuntimeException ex) {
stopAndReleaseWebServer();
throw ex;
}
}
You can see that it is directly delegated to the parent class:
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
// Prepare this context for refreshing.
prepareRefresh();
// Tell the subclass to refresh the internal bean factory.
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// Prepare the bean factory for use in this context.
prepareBeanFactory(beanFactory);
try {
// Allows post-processing of the bean factory in context subclasses.
postProcessBeanFactory(beanFactory);
// Invoke factory processors registered as beans in the context.
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
registerBeanPostProcessors(beanFactory);
// Initialize message source for this context.
initMessageSource();
// Initialize event multicaster for this context.
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
onRefresh();
// Check for listener beans and register them.
registerListeners();
// Instantiate all remaining (non-lazy-init) singletons.
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
finishRefresh();
}
catch (BeansException ex) {
if (logger.isWarnEnabled()) {
logger.warn("Exception encountered during context initialization - " +
"cancelling refresh attempt: " + ex);
}
// Destroy already created singletons to avoid dangling resources.
destroyBeans();
// Reset 'active' flag.
cancelRefresh(ex);
// Propagate exception to caller.
throw ex;
}
finally {
// Reset common introspection caches in Spring's core, since we
// might not ever need metadata for singleton beans anymore...
resetCommonCaches();
}
}
}
This method is not strange. It has been analyzed before. I won't repeat it here. Now the container of spring boot is started. But where is Tomcat started? You don't see it in the run method either. In fact, the start of Tomcat is also in the refresh process. One step of this method is to call the onRefresh method. In spring, this is an unimplemented template method. Spring boot uses this method to start Tomcat:
protected void onRefresh() {
super.onRefresh();
try {
createWebServer();
}
catch (Throwable ex) {
throw new ApplicationContextException("Unable to start web server", ex);
}
}
private void createWebServer() {
WebServer webServer = this.webServer;
ServletContext servletContext = getServletContext();
if (webServer == null && servletContext == null) {
ServletWebServerFactory factory = getWebServerFactory();
// Mainly look at this method
this.webServer = factory.getWebServer(getSelfInitializer());
}
else if (servletContext != null) {
try {
getSelfInitializer().onStartup(servletContext);
}
catch (ServletException ex) {
throw new ApplicationContextException("Cannot initialize servlet context", ex);
}
}
initPropertySources();
}
First, get the TomcatServletWebServerFactory object, and then create and start Tomcat:
public WebServer getWebServer(ServletContextInitializer... initializers) {
if (this.disableMBeanRegistry) {
Registry.disableRegistry();
}
Tomcat tomcat = new Tomcat();
File baseDir = (this.baseDirectory != null) ? this.baseDirectory : createTempDir("tomcat");
tomcat.setBaseDir(baseDir.getAbsolutePath());
Connector connector = new Connector(this.protocol);
connector.setThrowOnFailure(true);
tomcat.getService().addConnector(connector);
customizeConnector(connector);
tomcat.setConnector(connector);
tomcat.getHost().setAutoDeploy(false);
configureEngine(tomcat.getEngine());
for (Connector additionalConnector : this.additionalTomcatConnectors) {
tomcat.getService().addConnector(additionalConnector);
}
prepareContext(tomcat.getHost(), initializers);
return getTomcatWebServer(tomcat);
}
Each step above can be compared with Tomcat's configuration file. Note that only http protocol is supported by default:
Connector connector = new Connector(this.protocol); private String protocol = DEFAULT_PROTOCOL; public static final String DEFAULT_PROTOCOL = "org.apache.coyote.http11.Http11NioProtocol";
If you want to extend it, you can set the value of additionalTomcatConnectors property. Note that this property has no corresponding setter method, only additionalTomcatConnectors method. That is to say, we can only implement the postProcessBeanFactory method of BeanFactoryPostProcessor interface, not the postprocessbeandef of BeanDefinitionRegistryPostProcessor The initionregistry method, because the former can obtain the TomcatServletWebServerFactory object through the incoming BeanFactory object in advance and call additionalmtomcatconnectors; the latter can only get the BeanDefinition object, which can only set the value through the setter method.
event driven
Spring originally provides event mechanism, but it is extended in spring boot. Through publishing and subscribing events, different operations are carried out in different stages of the container's life cycle. Let's take a look at the events that will be published by default during the startup and shutdown of spring boot. Use the following code:
@SpringBootApplication
public class SpringEventDemo {
public static void main(String[] args) {
new SpringApplicationBuilder(SpringEventDemo.class)
.listeners(event -> {
System.err.println("Event received:" + event.getClass().getSimpleName());
})
.run()
.close();
}
}
This code will print all event names on the console in the following order:
- ApplicationStartingEvent: container start
- Application environment preparedevent: environment ready
- ApplicationContextInitializedEvent: context initialization completed
- Application preparedevent: context ready
- ContextRefreshedEvent: context refresh completed
- ServletWebServerInitializedEvent: webServer initialization complete
- Application started event: container start completed
- ApplicationReadyEvent: container ready
- ContextClosedEvent: container closed
The above is the normal startup and shutdown. If there is an exception, the ApplicationFailedEvent event will be published. Event publishing spreads throughout the start-up and shutdown cycle of the container. Just now, we saw that the event publishing object is a spring applicationrunlistener loaded by SPI to implement the eventpublishing runlistener class. Similarly, the event listener is also in the spring.factories As configured in the file, the following listeners are implemented by default:
org.springframework.context.ApplicationListener=\ org.springframework.boot.ClearCachesApplicationListener,\ org.springframework.boot.builder.ParentContextCloserApplicationListener,\ org.springframework.boot.cloud.CloudFoundryVcapEnvironmentPostProcessor,\ org.springframework.boot.context.FileEncodingApplicationListener,\ org.springframework.boot.context.config.AnsiOutputApplicationListener,\ org.springframework.boot.context.config.ConfigFileApplicationListener,\ org.springframework.boot.context.config.DelegatingApplicationListener,\ org.springframework.boot.context.logging.ClasspathLoggingApplicationListener,\ org.springframework.boot.context.logging.LoggingApplicationListener,\ org.springframework.boot.liquibase.LiquibaseServiceLocatorApplicationListener
You can see that there are a series of listeners for file encoding, logging application listener, ConfigFileApplicationListener, etc. SpringBoot uses these listeners to load necessary configurations and components into the container. We will not analyze them in detail here, and are interested in them Through the onApplicationEvent method, readers can see which event each listener listens to. Of course, event publishing and listening can also be extended.
Auto configuration principle
The core of SpringBoot is automatic configuration. Why can it be used out of the box? We don't need to manually use @ EnableXXX and other annotations to open it? The answer to all this is in the @ SpringBootApplication annotation:
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@SpringBootConfiguration
@EnableAutoConfiguration
@ComponentScan(excludeFilters = { @Filter(type = FilterType.CUSTOM, classes = TypeExcludeFilter.class),
@Filter(type = FilterType.CUSTOM, classes = AutoConfigurationExcludeFilter.class) })
public @interface SpringBootApplication {}
There are three important notes here: @ SpringBootConfiguration, @ EnableAutoConfiguration, @ ComponentScan. @ComponentScan doesn't need to mention that @ SpringBootConfiguration is equivalent to @ Configuration, and @ EnableAutoConfiguration is to enable automatic Configuration:
@AutoConfigurationPackage
@Import(AutoConfigurationImportSelector.class)
public @interface EnableAutoConfiguration {
}
@Import(AutoConfigurationPackages.Registrar.class)
public @interface AutoConfigurationPackage {
}
@The function of AutoConfigurationPackage annotation is to take the package marked by this annotation as the package of automatic configuration. Just look at it briefly, mainly look at AutoConfigurationImportSelector, which is the core class of automatic configuration. Note that this class is the interface of DeferredImportSelector.
There is a selectImports method in this class. This method is in my previous article Understand Spring transaction annotation analysis this time It has also been analyzed, but the implementation class is different. It will also be called by the ConfigurationClassPostProcessor class. First, let's see what this method does:
public String[] selectImports(AnnotationMetadata annotationMetadata) {
if (!isEnabled(annotationMetadata)) {
return NO_IMPORTS;
}
AutoConfigurationMetadata autoConfigurationMetadata = AutoConfigurationMetadataLoader
.loadMetadata(this.beanClassLoader);
// Get all auto configuration classes
AutoConfigurationEntry autoConfigurationEntry = getAutoConfigurationEntry(autoConfigurationMetadata,
annotationMetadata);
return StringUtils.toStringArray(autoConfigurationEntry.getConfigurations());
}
protected AutoConfigurationEntry getAutoConfigurationEntry(AutoConfigurationMetadata autoConfigurationMetadata,
AnnotationMetadata annotationMetadata) {
if (!isEnabled(annotationMetadata)) {
return EMPTY_ENTRY;
}
AnnotationAttributes attributes = getAttributes(annotationMetadata);
// SPI gets all implementation classes with EnableAutoConfiguration as key
List<String> configurations = getCandidateConfigurations(annotationMetadata, attributes);
configurations = removeDuplicates(configurations);
Set<String> exclusions = getExclusions(annotationMetadata, attributes);
checkExcludedClasses(configurations, exclusions);
configurations.removeAll(exclusions);
// Filter out some auto configuration classes
configurations = filter(configurations, autoConfigurationMetadata);
fireAutoConfigurationImportEvents(configurations, exclusions);
// Package as auto configuration entity class
return new AutoConfigurationEntry(configurations, exclusions);
}
protected List<String> getCandidateConfigurations(AnnotationMetadata metadata, AnnotationAttributes attributes) {
// SPI gets all implementation classes with EnableAutoConfiguration as key
List<String> configurations = SpringFactoriesLoader.loadFactoryNames(getSpringFactoriesLoaderFactoryClass(),
getBeanClassLoader());
Assert.notEmpty(configurations, "No auto configuration classes found in META-INF/spring.factories. If you "
+ "are using a custom packaging, make sure that file is correct.");
return configurations;
}
Tracing the source code can be seen from META-INF/spring.factories All the values corresponding to EnableAutoConfiguration (in spring boot autoconfigure) are obtained in the file and instantiated through reflection. After filtering, they are packaged as AutoConfigurationEntry objects and returned.
You should think that the implementation of automatic configuration is through this selectImports method, but in fact, this method is not usually called, but will call the process and selectImports methods of the internal class AutoConfigurationGroup of this class, the former is also through getAutoConfigurationEntry to get all automatic configuration classes, the latter is filter, sort and package Return after installation.
Next, we will analyze how the ConfigurationClassPostProcessor is called here, and directly enter the processConfigBeanDefinitions method:
public void processConfigBeanDefinitions(BeanDefinitionRegistry registry) {
List<BeanDefinitionHolder> configCandidates = new ArrayList<>();
String[] candidateNames = registry.getBeanDefinitionNames();
for (String beanName : candidateNames) {
BeanDefinition beanDef = registry.getBeanDefinition(beanName);
if (beanDef.getAttribute(ConfigurationClassUtils.CONFIGURATION_CLASS_ATTRIBUTE) != null) {
if (logger.isDebugEnabled()) {
logger.debug("Bean definition has already been processed as a configuration class: " + beanDef);
}
}
else if (ConfigurationClassUtils.checkConfigurationClassCandidate(beanDef, this.metadataReaderFactory)) {
configCandidates.add(new BeanDefinitionHolder(beanDef, beanName));
}
}
// Return immediately if no @Configuration classes were found
if (configCandidates.isEmpty()) {
return;
}
// Sort by previously determined @Order value, if applicable
configCandidates.sort((bd1, bd2) -> {
int i1 = ConfigurationClassUtils.getOrder(bd1.getBeanDefinition());
int i2 = ConfigurationClassUtils.getOrder(bd2.getBeanDefinition());
return Integer.compare(i1, i2);
});
// Detect any custom bean name generation strategy supplied through the enclosing application context
SingletonBeanRegistry sbr = null;
if (registry instanceof SingletonBeanRegistry) {
sbr = (SingletonBeanRegistry) registry;
if (!this.localBeanNameGeneratorSet) {
BeanNameGenerator generator = (BeanNameGenerator) sbr.getSingleton(
AnnotationConfigUtils.CONFIGURATION_BEAN_NAME_GENERATOR);
if (generator != null) {
this.componentScanBeanNameGenerator = generator;
this.importBeanNameGenerator = generator;
}
}
}
if (this.environment == null) {
this.environment = new StandardEnvironment();
}
// Parse each @Configuration class
ConfigurationClassParser parser = new ConfigurationClassParser(
this.metadataReaderFactory, this.problemReporter, this.environment,
this.resourceLoader, this.componentScanBeanNameGenerator, registry);
Set<BeanDefinitionHolder> candidates = new LinkedHashSet<>(configCandidates);
Set<ConfigurationClass> alreadyParsed = new HashSet<>(configCandidates.size());
do {
parser.parse(candidates);
parser.validate();
Set<ConfigurationClass> configClasses = new LinkedHashSet<>(parser.getConfigurationClasses());
configClasses.removeAll(alreadyParsed);
// Read the model and create bean definitions based on its content
if (this.reader == null) {
this.reader = new ConfigurationClassBeanDefinitionReader(
registry, this.sourceExtractor, this.resourceLoader, this.environment,
this.importBeanNameGenerator, parser.getImportRegistry());
}
this.reader.loadBeanDefinitions(configClasses);
alreadyParsed.addAll(configClasses);
// Omit....
}
The previous section is to get the qualified Configuration configuration class, and the main logic is in conf igurationClassParser.parse In the method, the method completes the parsing of @ Component, @ Bean, @ Import, @ ComponentScans and other annotations. Here we mainly look at the parsing of @ Import. Other readers can analyze by themselves. Step by step tracking will eventually enter the processConfigurationClass method:
protected void processConfigurationClass(ConfigurationClass configClass) throws IOException {
if (this.conditionEvaluator.shouldSkip(configClass.getMetadata(), ConfigurationPhase.PARSE_CONFIGURATION)) {
return;
}
ConfigurationClass existingClass = this.configurationClasses.get(configClass);
if (existingClass != null) {
if (configClass.isImported()) {
if (existingClass.isImported()) {
existingClass.mergeImportedBy(configClass);
}
// Otherwise ignore new imported config class; existing non-imported class overrides it.
return;
}
else {
// Explicit bean definition found, probably replacing an import.
// Let's remove the old one and go with the new one.
this.configurationClasses.remove(configClass);
this.knownSuperclasses.values().removeIf(configClass::equals);
}
}
// Recursively process the configuration class and its superclass hierarchy.
SourceClass sourceClass = asSourceClass(configClass);
do {
sourceClass = doProcessConfigurationClass(configClass, sourceClass);
}
while (sourceClass != null);
this.configurationClasses.put(configClass, configClass);
}
Attention is needed here this.conditionEvaluator.shouldSkip This method is used to load and filter the Bean, that is, to determine whether to load the Bean according to the matching value of @ Condition annotation. The specific implementation will be analyzed later, and continue to track the main process doProcessConfigurationClass:
protected final SourceClass doProcessConfigurationClass(ConfigurationClass configClass, SourceClass sourceClass)
throws IOException {
//Omit
// Process any @Import annotations
processImports(configClass, sourceClass, getImports(sourceClass), true);
//Omit
return null;
}
Here is the support for completing a series of annotations. I omitted it. I mainly look at the processImports method, which deals with @ Import annotations:
private void processImports(ConfigurationClass configClass, SourceClass currentSourceClass,
Collection<SourceClass> importCandidates, boolean checkForCircularImports) {
if (importCandidates.isEmpty()) {
return;
}
if (checkForCircularImports && isChainedImportOnStack(configClass)) {
this.problemReporter.error(new CircularImportProblem(configClass, this.importStack));
}
else {
this.importStack.push(configClass);
try {
for (SourceClass candidate : importCandidates) {
if (candidate.isAssignable(ImportSelector.class)) {
// Candidate class is an ImportSelector -> delegate to it to determine imports
Class<?> candidateClass = candidate.loadClass();
ImportSelector selector = ParserStrategyUtils.instantiateClass(candidateClass, ImportSelector.class,
this.environment, this.resourceLoader, this.registry);
if (selector instanceof DeferredImportSelector) {
this.deferredImportSelectorHandler.handle(configClass, (DeferredImportSelector) selector);
}
else {
String[] importClassNames = selector.selectImports(currentSourceClass.getMetadata());
Collection<SourceClass> importSourceClasses = asSourceClasses(importClassNames);
processImports(configClass, currentSourceClass, importSourceClasses, false);
}
}
else if (candidate.isAssignable(ImportBeanDefinitionRegistrar.class)) {
Class<?> candidateClass = candidate.loadClass();
ImportBeanDefinitionRegistrar registrar =
ParserStrategyUtils.instantiateClass(candidateClass, ImportBeanDefinitionRegistrar.class,
this.environment, this.resourceLoader, this.registry);
configClass.addImportBeanDefinitionRegistrar(registrar, currentSourceClass.getMetadata());
}
else {
this.importStack.registerImport(
currentSourceClass.getMetadata(), candidate.getMetadata().getClassName());
processConfigurationClass(candidate.asConfigClass(configClass));
}
}
}
}
}
Just now I reminded AutoConfigurationImportSelector implements the DeferredImportSelector interface. If it is not the implementation class of the interface, it directly calls the selectImports method, otherwise it calls deferredi mportSelectorHandler.handle method:
private List<DeferredImportSelectorHolder> deferredImportSelectors = new ArrayList<>();
public void handle(ConfigurationClass configClass, DeferredImportSelector importSelector) {
DeferredImportSelectorHolder holder = new DeferredImportSelectorHolder(
configClass, importSelector);
if (this.deferredImportSelectors == null) {
DeferredImportSelectorGroupingHandler handler = new DeferredImportSelectorGroupingHandler();
handler.register(holder);
handler.processGroupImports();
}
else {
this.deferredImportSelectors.add(holder);
}
}
First, a DeferredImportSelectorHolder object is created. If it is executed for the first time, it is added to the deferredImportSelectors property. Wait until conf igurationClassParser.parse The last call to process method:
public void parse(Set<BeanDefinitionHolder> configCandidates) {
//Omit
this.deferredImportSelectorHandler.process();
}
public void process() {
List<DeferredImportSelectorHolder> deferredImports = this.deferredImportSelectors;
this.deferredImportSelectors = null;
try {
if (deferredImports != null) {
DeferredImportSelectorGroupingHandler handler = new DeferredImportSelectorGroupingHandler();
deferredImports.sort(DEFERRED_IMPORT_COMPARATOR);
deferredImports.forEach(handler::register);
handler.processGroupImports();
}
}
finally {
this.deferredImportSelectors = new ArrayList<>();
}
}
On the contrary, it is directly executed. First, get the AutoConfigurationGroup object through register:
public void register(DeferredImportSelectorHolder deferredImport) {
Class<? extends Group> group = deferredImport.getImportSelector()
.getImportGroup();
DeferredImportSelectorGrouping grouping = this.groupings.computeIfAbsent(
(group != null ? group : deferredImport),
key -> new DeferredImportSelectorGrouping(createGroup(group)));
grouping.add(deferredImport);
this.configurationClasses.put(deferredImport.getConfigurationClass().getMetadata(),
deferredImport.getConfigurationClass());
}
public Class<? extends Group> getImportGroup() {
return AutoConfigurationGroup.class;
}
Then do the real processing in the processGroupImports method:
public void processGroupImports() {
for (DeferredImportSelectorGrouping grouping : this.groupings.values()) {
grouping.getImports().forEach(entry -> {
ConfigurationClass configurationClass = this.configurationClasses.get(
entry.getMetadata());
try {
processImports(configurationClass, asSourceClass(configurationClass),
asSourceClasses(entry.getImportClassName()), false);
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to process import candidates for configuration class [" +
configurationClass.getMetadata().getClassName() + "]", ex);
}
});
}
}
public Iterable<Group.Entry> getImports() {
for (DeferredImportSelectorHolder deferredImport : this.deferredImports) {
this.group.process(deferredImport.getConfigurationClass().getMetadata(),
deferredImport.getImportSelector());
}
return this.group.selectImports();
}
In the getImports method, the process and selectImports methods are called. After getting the automatic configuration class, the processImports method is called recursively to load the automatic configuration class. At this point, the loading process of automatic configuration is analyzed. The following is the sequence diagram: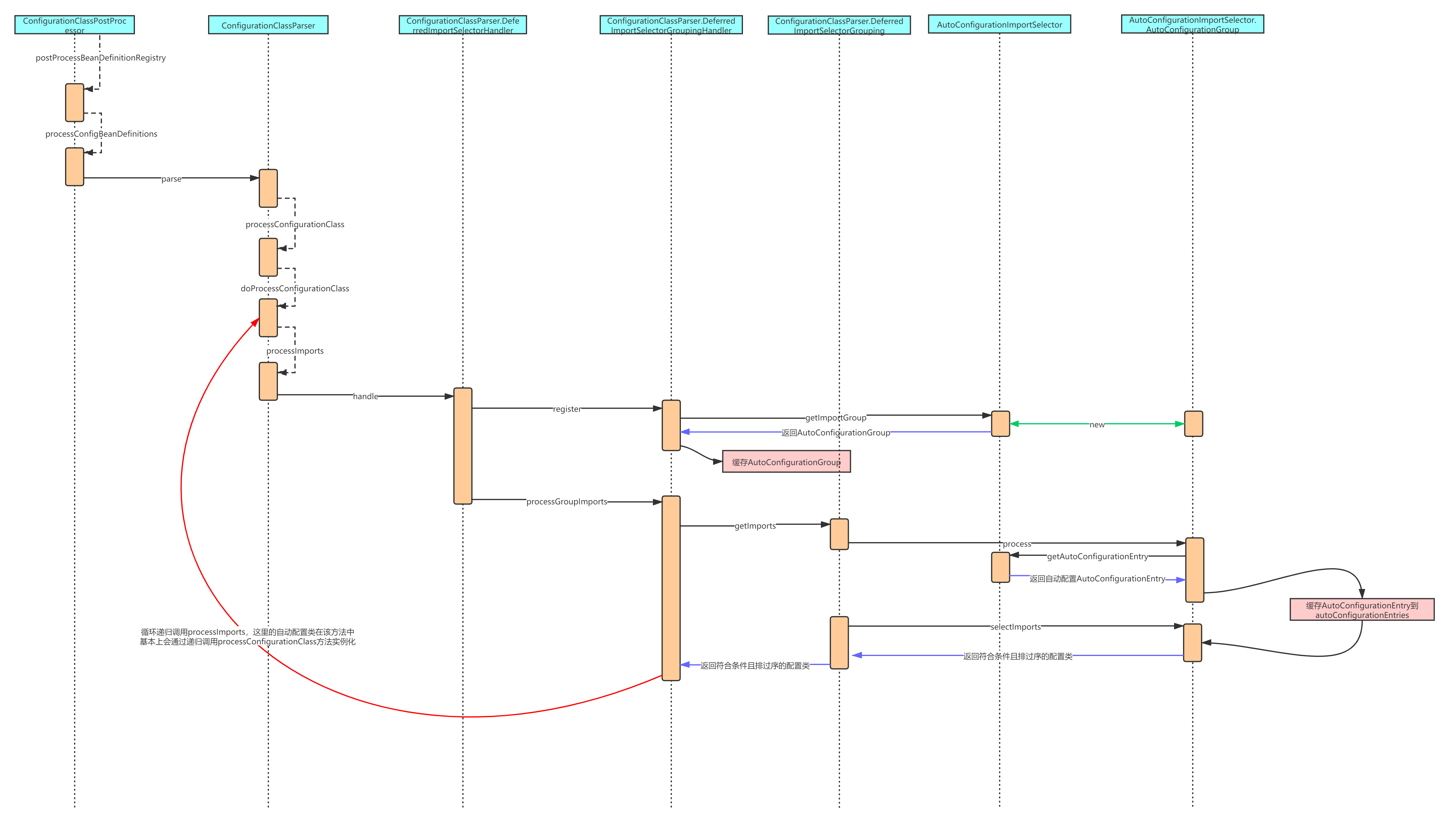
Condition annotation principle
There are many Condition related annotations in the auto configuration class. Take AOP as an example:
Configuration(proxyBeanMethods = false)
@ConditionalOnProperty(prefix = "spring.aop", name = "auto", havingValue = "true", matchIfMissing = true)
public class AopAutoConfiguration {
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass(Advice.class)
static class AspectJAutoProxyingConfiguration {
@Configuration(proxyBeanMethods = false)
@EnableAspectJAutoProxy(proxyTargetClass = false)
@ConditionalOnProperty(prefix = "spring.aop", name = "proxy-target-class", havingValue = "false",
matchIfMissing = false)
static class JdkDynamicAutoProxyConfiguration {
}
@Configuration(proxyBeanMethods = false)
@EnableAspectJAutoProxy(proxyTargetClass = true)
@ConditionalOnProperty(prefix = "spring.aop", name = "proxy-target-class", havingValue = "true",
matchIfMissing = true)
static class CglibAutoProxyConfiguration {
}
}
@Configuration(proxyBeanMethods = false)
@ConditionalOnMissingClass("org.aspectj.weaver.Advice")
@ConditionalOnProperty(prefix = "spring.aop", name = "proxy-target-class", havingValue = "true",
matchIfMissing = true)
static class ClassProxyingConfiguration {
ClassProxyingConfiguration(BeanFactory beanFactory) {
if (beanFactory instanceof BeanDefinitionRegistry) {
BeanDefinitionRegistry registry = (BeanDefinitionRegistry) beanFactory;
AopConfigUtils.registerAutoProxyCreatorIfNecessary(registry);
AopConfigUtils.forceAutoProxyCreatorToUseClassProxying(registry);
}
}
}
}
Here you can see @ ConditionalOnProperty, @ ConditionalOnClass, @ ConditionalOnMissingClass, in addition to @ ConditionalOnBean, @ ConditionalOnMissingBean and many other condition matching annotations. These annotations indicate that the Bean will be loaded only when the condition is matched. For example, @ ConditionalOnProperty indicates that the corresponding Bean will be loaded only when the condition is met in the configuration file. Prefix indicates the prefix in the configuration file. Name indicates the name of the configuration. Havengvalue indicates that the Bean will be loaded only when the configuration is this value. matchIfMissing indicates whether the corresponding Bean will be loaded by default without the configuration. Other annotations can be analogically understood and memorized. The following is mainly to analyze the implementation principle of this annotation.
If you click in the annotation here, you will find that each annotation is marked with @ Conditional annotation, and the value value value corresponds to a class, such as OnBeanCondition. These classes implement the Condition interface. See their inheritance system: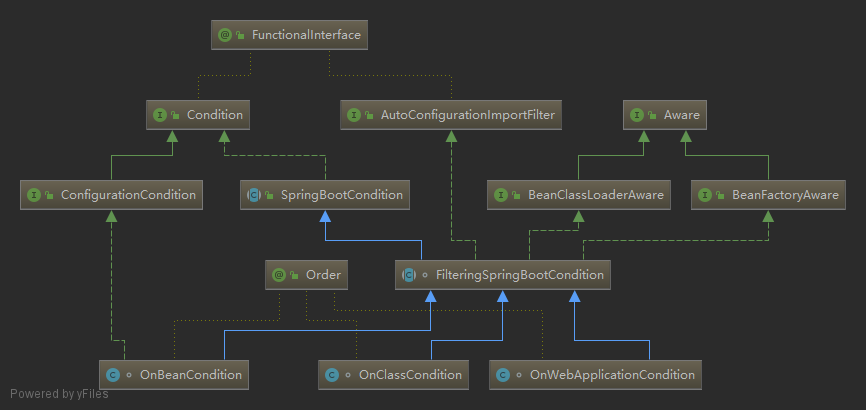
Only a few implementation classes are shown above, but in fact, there are many implementation classes of Condition. We can also implement the interface ourselves to extend @ Condition annotation.
There is a matches method in the Condition interface, which returns true to indicate a match. This method is called in many places in the ConfigurationClassParser, that is, the shouldSkip method I just reminded. The specific implementation is in the ConditionEvaluator class:
public boolean shouldSkip(@Nullable AnnotatedTypeMetadata metadata, @Nullable ConfigurationPhase phase) {
if (metadata == null || !metadata.isAnnotated(Conditional.class.getName())) {
return false;
}
if (phase == null) {
if (metadata instanceof AnnotationMetadata &&
ConfigurationClassUtils.isConfigurationCandidate((AnnotationMetadata) metadata)) {
return shouldSkip(metadata, ConfigurationPhase.PARSE_CONFIGURATION);
}
return shouldSkip(metadata, ConfigurationPhase.REGISTER_BEAN);
}
List<Condition> conditions = new ArrayList<>();
for (String[] conditionClasses : getConditionClasses(metadata)) {
for (String conditionClass : conditionClasses) {
Condition condition = getCondition(conditionClass, this.context.getClassLoader());
conditions.add(condition);
}
}
AnnotationAwareOrderComparator.sort(conditions);
for (Condition condition : conditions) {
ConfigurationPhase requiredPhase = null;
if (condition instanceof ConfigurationCondition) {
requiredPhase = ((ConfigurationCondition) condition).getConfigurationPhase();
}
if ((requiredPhase == null || requiredPhase == phase) && !condition.matches(this.context, metadata)) {
return true;
}
}
return false;
}
Take a look at the implementation of matches, but the method is not implemented in the OnBeanCondition class, but in its parent class SpringBootCondition:
public final boolean matches(ConditionContext context, AnnotatedTypeMetadata metadata) {
String classOrMethodName = getClassOrMethodName(metadata);
try {
ConditionOutcome outcome = getMatchOutcome(context, metadata);
logOutcome(classOrMethodName, outcome);
recordEvaluation(context, classOrMethodName, outcome);
return outcome.isMatch();
}
getMatchOutcome method is also a template method. The specific matching logic is implemented in this method. The ConditionOutcome object returned by this method contains two fields: match and log message. Enter the OnBeanCondition class:
public ConditionOutcome getMatchOutcome(ConditionContext context, AnnotatedTypeMetadata metadata) {
ConditionMessage matchMessage = ConditionMessage.empty();
MergedAnnotations annotations = metadata.getAnnotations();
if (annotations.isPresent(ConditionalOnBean.class)) {
Spec<ConditionalOnBean> spec = new Spec<>(context, metadata, annotations, ConditionalOnBean.class);
MatchResult matchResult = getMatchingBeans(context, spec);
if (!matchResult.isAllMatched()) {
String reason = createOnBeanNoMatchReason(matchResult);
return ConditionOutcome.noMatch(spec.message().because(reason));
}
matchMessage = spec.message(matchMessage).found("bean", "beans").items(Style.QUOTE,
matchResult.getNamesOfAllMatches());
}
if (metadata.isAnnotated(ConditionalOnSingleCandidate.class.getName())) {
Spec<ConditionalOnSingleCandidate> spec = new SingleCandidateSpec(context, metadata, annotations);
MatchResult matchResult = getMatchingBeans(context, spec);
if (!matchResult.isAllMatched()) {
return ConditionOutcome.noMatch(spec.message().didNotFind("any beans").atAll());
}
else if (!hasSingleAutowireCandidate(context.getBeanFactory(), matchResult.getNamesOfAllMatches(),
spec.getStrategy() == SearchStrategy.ALL)) {
return ConditionOutcome.noMatch(spec.message().didNotFind("a primary bean from beans")
.items(Style.QUOTE, matchResult.getNamesOfAllMatches()));
}
matchMessage = spec.message(matchMessage).found("a primary bean from beans").items(Style.QUOTE,
matchResult.getNamesOfAllMatches());
}
if (metadata.isAnnotated(ConditionalOnMissingBean.class.getName())) {
Spec<ConditionalOnMissingBean> spec = new Spec<>(context, metadata, annotations,
ConditionalOnMissingBean.class);
MatchResult matchResult = getMatchingBeans(context, spec);
if (matchResult.isAnyMatched()) {
String reason = createOnMissingBeanNoMatchReason(matchResult);
return ConditionOutcome.noMatch(spec.message().because(reason));
}
matchMessage = spec.message(matchMessage).didNotFind("any beans").atAll();
}
return ConditionOutcome.match(matchMessage);
}
You can see that this class supports @ ConditionalOnBean, @ ConditionalOnSingleCandidate, @ ConditionalOnMissingBean annotations. The main matching logic is in the getMatchingBeans method:
protected final MatchResult getMatchingBeans(ConditionContext context, Spec<?> spec) {
ClassLoader classLoader = context.getClassLoader();
ConfigurableListableBeanFactory beanFactory = context.getBeanFactory();
boolean considerHierarchy = spec.getStrategy() != SearchStrategy.CURRENT;
Set<Class<?>> parameterizedContainers = spec.getParameterizedContainers();
if (spec.getStrategy() == SearchStrategy.ANCESTORS) {
BeanFactory parent = beanFactory.getParentBeanFactory();
Assert.isInstanceOf(ConfigurableListableBeanFactory.class, parent,
"Unable to use SearchStrategy.ANCESTORS");
beanFactory = (ConfigurableListableBeanFactory) parent;
}
MatchResult result = new MatchResult();
Set<String> beansIgnoredByType = getNamesOfBeansIgnoredByType(classLoader, beanFactory, considerHierarchy,
spec.getIgnoredTypes(), parameterizedContainers);
for (String type : spec.getTypes()) {
Collection<String> typeMatches = getBeanNamesForType(classLoader, considerHierarchy, beanFactory, type,
parameterizedContainers);
typeMatches.removeAll(beansIgnoredByType);
if (typeMatches.isEmpty()) {
result.recordUnmatchedType(type);
}
else {
result.recordMatchedType(type, typeMatches);
}
}
for (String annotation : spec.getAnnotations()) {
Set<String> annotationMatches = getBeanNamesForAnnotation(classLoader, beanFactory, annotation,
considerHierarchy);
annotationMatches.removeAll(beansIgnoredByType);
if (annotationMatches.isEmpty()) {
result.recordUnmatchedAnnotation(annotation);
}
else {
result.recordMatchedAnnotation(annotation, annotationMatches);
}
}
for (String beanName : spec.getNames()) {
if (!beansIgnoredByType.contains(beanName) && containsBean(beanFactory, beanName, considerHierarchy)) {
result.recordMatchedName(beanName);
}
else {
result.recordUnmatchedName(beanName);
}
}
return result;
}
The logic here seems more complicated, but in fact, two things are done. First, call through getNamesOfBeansIgnoredByType method beanFactory.getBeanNamesForType Get the corresponding Bean instance in the container, then judge which Bean exists or does not exist according to the returned result (multiple values can be configured in the Condition annotation), and return the MatchResult object, while the matchr As long as a Bean in esult does not match, it returns false, which determines whether the current Bean needs to be instantiated.
summary
This paper analyzes the implementation of the core principles of Spring boot, and believes that readers will be able to use and extend Spring boot more skillfully. In addition, there are some common components that I haven't analyzed, such as transaction, MVC, and automatic configuration of listener. If we have the Spring source code foundation, we will see them later. I won't go into details here. Finally, readers can think about how we should customize the starter starter. I believe it will be difficult for you after reading this article.