I don't know when I began to enjoy crawling thousands of data!![]()
This article will use Python anti crawl technology to explain how to obtain tens of thousands of public commercial data of a certain Baocheng.
catalog
1 preliminary preparation
Python environment: Python 3.8.2
Python compiler: JetBrains pycharm2018.1.2 x64
Third party libraries and modules: selenium, time, csv, re
In addition, you need a browser driver: webDriver
selenium is a third-party library, which needs to be installed separately. Enter the following command line at the terminal
pip install selenium
input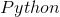 And
And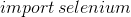 If no error is reported, the installation of the third-party library is successful.
If no error is reported, the installation of the third-party library is successful.

Let's talk about how to install the browser driver (take Google browser as an example):
First, download the browser drive WebDriver
Download address of Chrome browser drive: http://npm.taobao.org/mirrors/chromedriver/
firefox's drive download address: https://github.com/mozilla/geckodriver/releases
Drive download address of Edge browser: https://developer.microsoft.com/en-us/micrsosft-edage/tools/webdriver
Safari browser's drive download address: https://webkit.org/blog/6900/webdriver-support-in-safari-10/
Take Google browser for example. You need to know the version number of the browser first
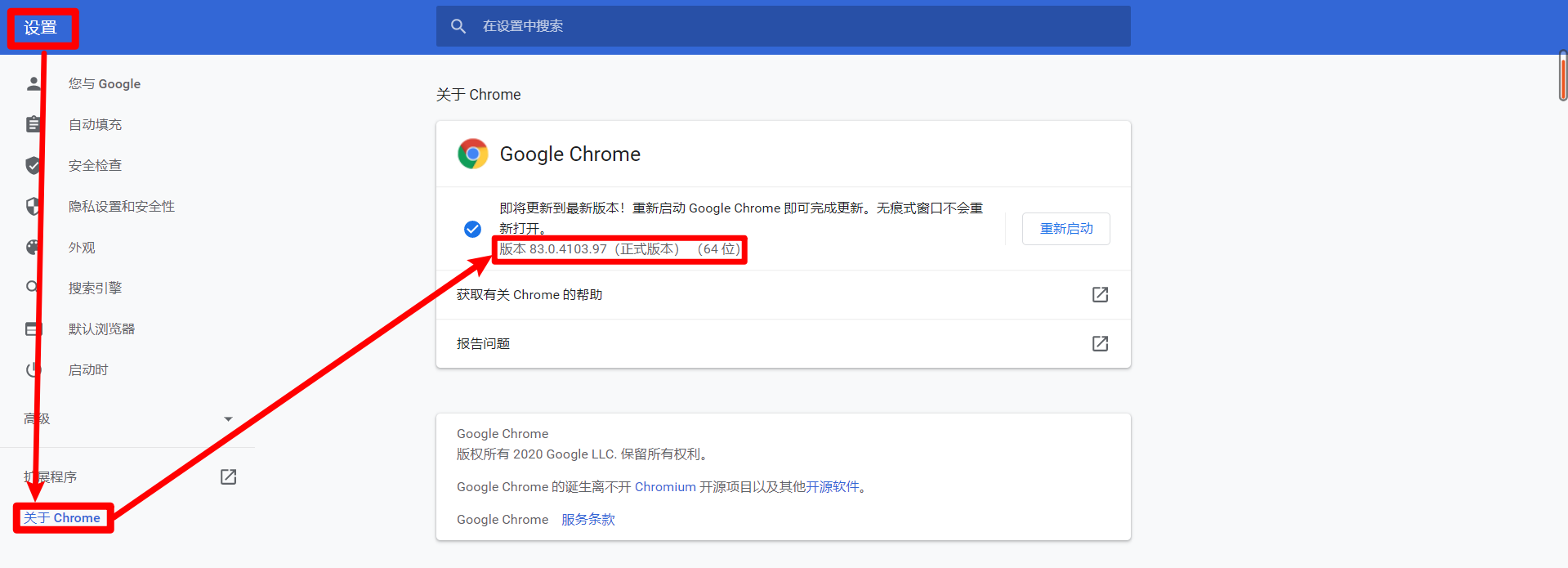
Just the front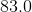 It's OK if it's well matched, and it's OK if it's in a big direction. Then find a matching version and download it
It's OK if it's well matched, and it's OK if it's in a big direction. Then find a matching version and download it
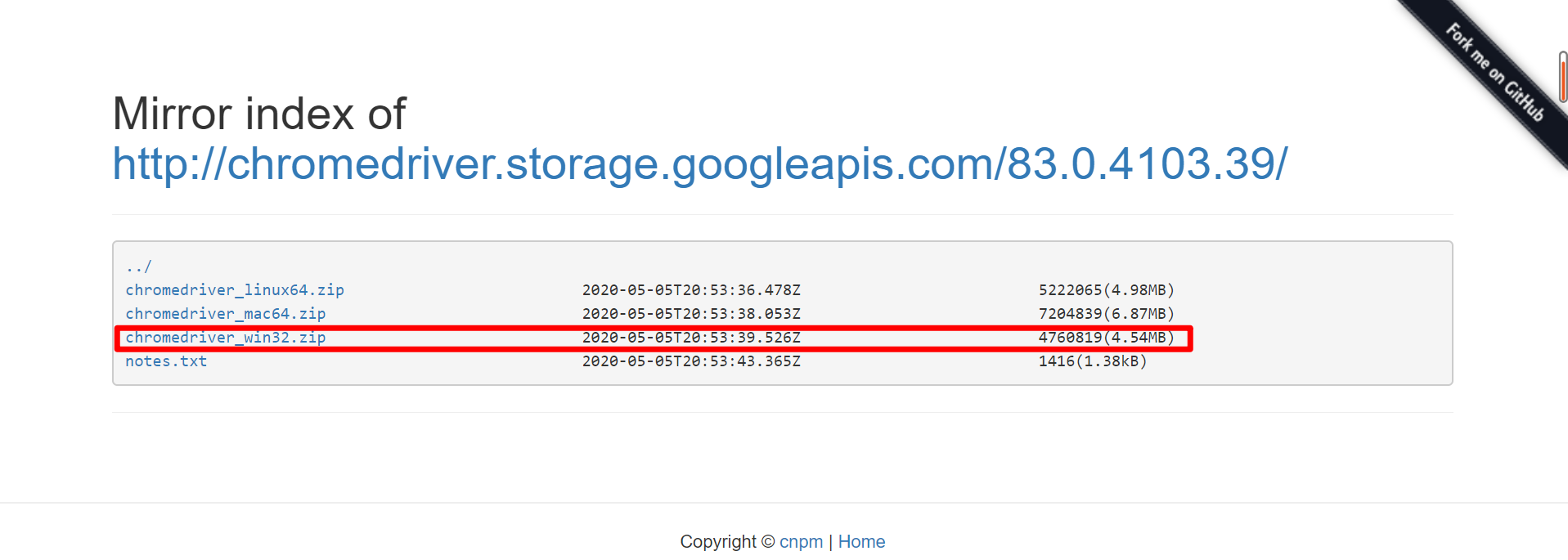
Download it and test it later
# Import webdriver from selenium
from selenium import webdriver
# Specify the chrom e driver (download to the local browser drive and locate the address to it)
driver = webdriver.Chrome('E:/software/chromedriver_win32/chromedriver.exe')
# get method to open the specified URL
driver.get('http://www.baidu.com')
At this point, the preparation is ready. Next, enter the reptile case explanation
2 case details
2.1 import module
Import the third-party library and related modules mentioned above
from selenium.webdriver import ActionChains # Import action chain from selenium import webdriver import time import csv import re
2.2 core code
Determine target page: Taobao.com (official website)
Write code to automatically open target web page
# Incoming browser driver local address
driver = webdriver.Chrome('E:/software/chromedriver_win32/chromedriver.exe')
# Incoming destination page address
driver.get('https://www.taobao.com/')Maximize browser
driver.maximize_window() # Maximize browser
Pass in keywords and search products automatically
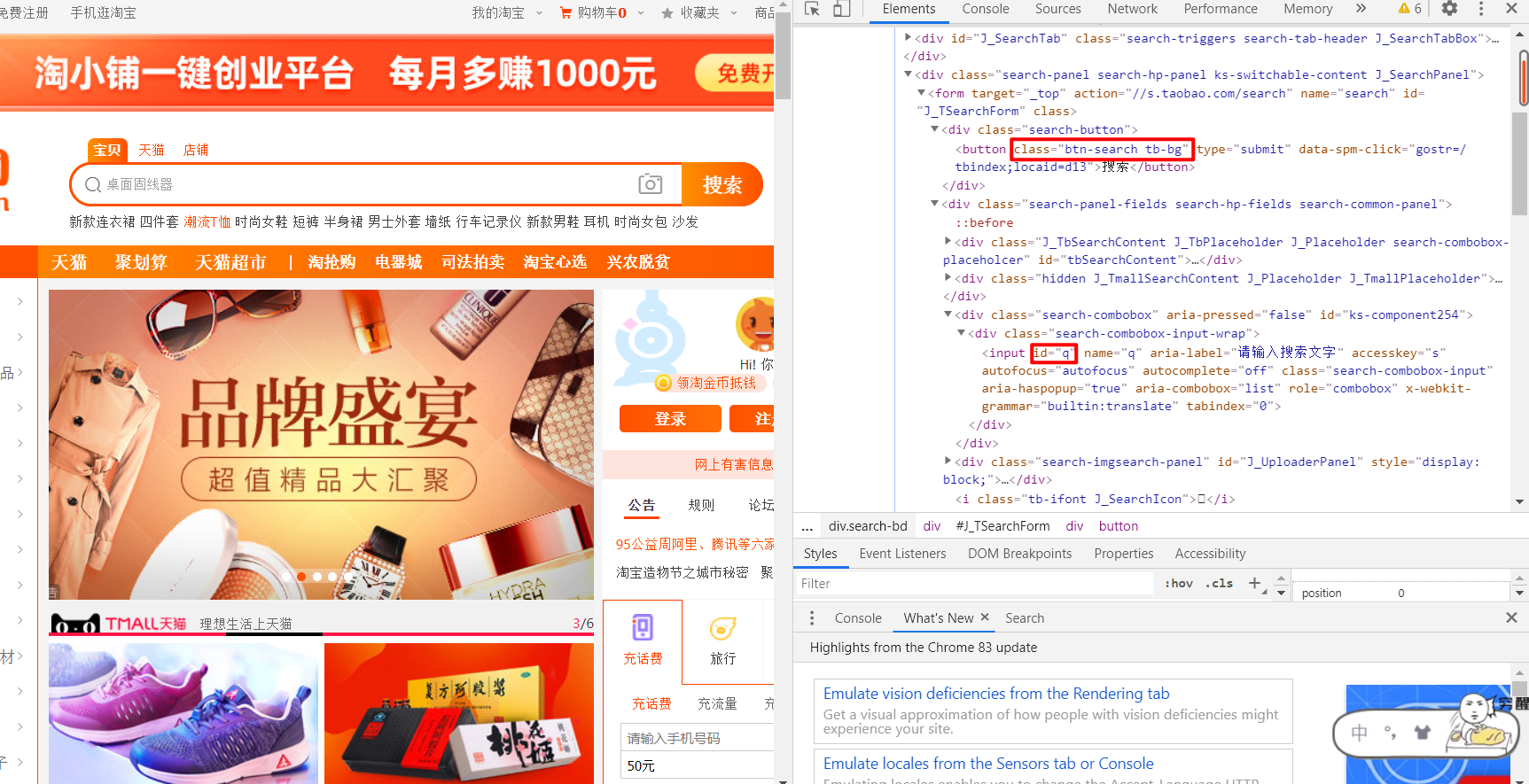
keyword = input('Please enter the product name you want to search:')
driver.find_element_by_id('q').send_keys(keyword) # Accurately locate the search box of Taobao according to the id value of "check" and pass in the keyword
driver.find_element_by_class_name('btn-search').click() # Locate the search button according to the class label 'BTN search' and clickAt this time, we found that we need to log in to view the search content. Then we need to solve the problem of logging in
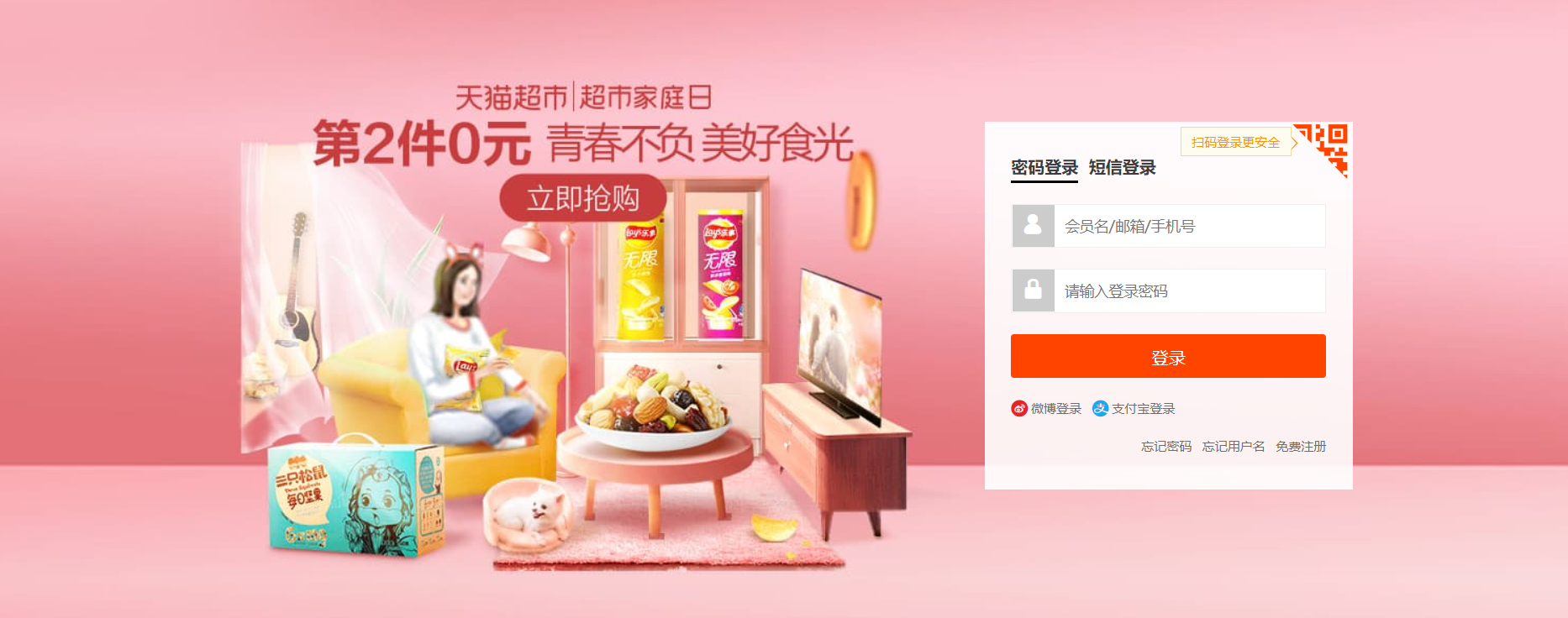
Pass in the account password (here, use F12 to locate its xpath value)
driver.find_element_by_xpath('//*[@id="fm-login-id"]').send_keys('account ')
driver.find_element_by_xpath('//*[@id="fm-login-password"]').send_keys('password ')Solve the problem of man-machine verification (anti climbing, sliding the slider to the right)
login = driver.find_element_by_xpath('//*[@id="nc_1_n1z "] ') ා find the slider through xpath
action = ActionChains(driver) # Create an action chain
action.click_and_hold(on_element=login) # Click not to release
action.move_by_offset(xoffset=300-42, yoffset=0) # Slide by axis
action.pause(0.5).release().perform() # Set the chain call time (slider time) and release the mouse perform() to execute the action chainGet the target data value of the entire page (for loop)
divs = driver.find_elements_by_xpath('//div[@class="items"]/div[@class="item J_MouserOnverReq "]')
for div in divs:
info = div.find_element_by_xpath('.//div[@class="row row-2 title"]/a').text
price = div.find_element_by_xpath('.//strong').text
deal = div.find_element_by_xpath('.//div[@class="deal-cnt"]').text
shop = div.find_element_by_xpath('.//div[@class="shop"]/a').textSave file (stored in csv format)
with open('data.csv', mode='a', newline="") as csvfile:
csvWriter = csv.writer(csvfile, delimiter=',')
csvWriter.writerow([info, price, deal, shop])The above is to crawl one page of data, so how to crawl multiple pages of data
 Get total pages
Get total pages
page = driver.find_element_by_xpath('//*[@ id = "mainsrp pager"] / div / div / div / div [1] '). Text ා get the total page number label
page_list = re.findall('(\d+)', page) # Regular expression gets multiple exact numeric data [list returned]
page_num = page_list[0] # String type datafor loops through all pages to get all the data of the product
driver.get('https://s.taobao.com/search?q={}&s={}'.format(keyword, page_num*44))
page_num += 1It is worth noting that the page address of the above code is summarized according to the rule of viewing the multi page address data

Obviously, from the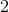 Page data address start, which
Page data address start, which Value from
Value from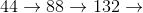 , which is generated by the superposition law of the number 44.
, which is generated by the superposition law of the number 44.
2.3 general code
from selenium.webdriver import ActionChains # Import action chain
from selenium import webdriver
import time
import csv
import re
# Search for keywords and log in to Taobao
def search_product(key):
driver.get('https://www.taobao.com/')
driver.find_element_by_id('q').send_keys(key) # Accurately locate the search box of Taobao according to the id value of "check" and pass in the keyword
driver.find_element_by_class_name('btn-search').click() # Locate the search button according to the class label 'BTN search' and click
driver.implicitly_wait(10) # Implicitly wait (in seconds) until the page is rendered, and then no longer wait
driver.maximize_window() # Maximize browser
# Solve login (login anti climbing: e.g. with slider)
driver.find_element_by_xpath('//*[@id="fm-login-id"]').send_keys('fill in account name / mobile number here ')
time.sleep(1)
driver.find_element_by_xpath('//*[@id="fm-login-password"]').send_keys('fill in account password here ')
time.sleep(2)
# Solve slider
login = driver.find_element_by_xpath('//*[@id="nc_1_n1z "] ') ා find the slider through xpath
action = ActionChains(driver) # Create an action chain
action.click_and_hold(on_element=login) # Click not to release
action.move_by_offset(xoffset=300-42, yoffset=0) # Slide by axis
action.pause(0.5).release().perform() # Set the chain call time (slider time) and release the mouse perform() to execute the action chain
driver.find_element_by_xpath('//*[@ id = "login form"] / div [4] / button '). Click() (click to log in and redirect to the previous keyword)
driver.implicitly_wait(10) # Implicit wait
page = driver.find_element_by_xpath('//*[@ id = "mainsrp pager"] / div / div / div / div [1] '). Text ා get the total page number label
page_list = re.findall('(\d+)', page) # Regular expression gets multiple exact numeric data [list returned]
page_num = page_list[0] # String type data
return int(page_num)
# Crawling data and saving
def get_data():
divs = driver.find_elements_by_xpath('//div[@class="items"]/div[@class="item J_MouserOnverReq "]')
for div in divs:
info = div.find_element_by_xpath('.//div[@class="row row-2 title"]/a').text
price = div.find_element_by_xpath('.//strong').text
deal = div.find_element_by_xpath('.//div[@class="deal-cnt"]').text
shop = div.find_element_by_xpath('.//div[@class="shop"]/a').text
print(info, price, deal, shop, sep='|')
# preservation
with open('data.csv', mode='a', newline="") as csvfile:
csvWriter = csv.writer(csvfile, delimiter=',')
csvWriter.writerow([info, price, deal, shop])
def main():
print('Crawling page 1 data...')
page = search_product(keyword)
get_data()
# Data acquisition after page 2
page_num = 1 # page_num * 44
while page_num != page:
print('*' * 100)
print('Climbing to the top{}Page data'.format(page_num+1))
print('*' * 100)
driver.get('https://s.taobao.com/search?q={}&s={}'.format(keyword, page_num*44))
driver.implicitly_wait(10) # Implicit wait
get_data()
page_num += 1
driver.quit()
if __name__ == '__main__':
driver = webdriver.Chrome('E:/software/chromedriver_win32/chromedriver.exe')
# keyword = 'computer'
keyword = input('Please enter the product name you want to search:')
main()
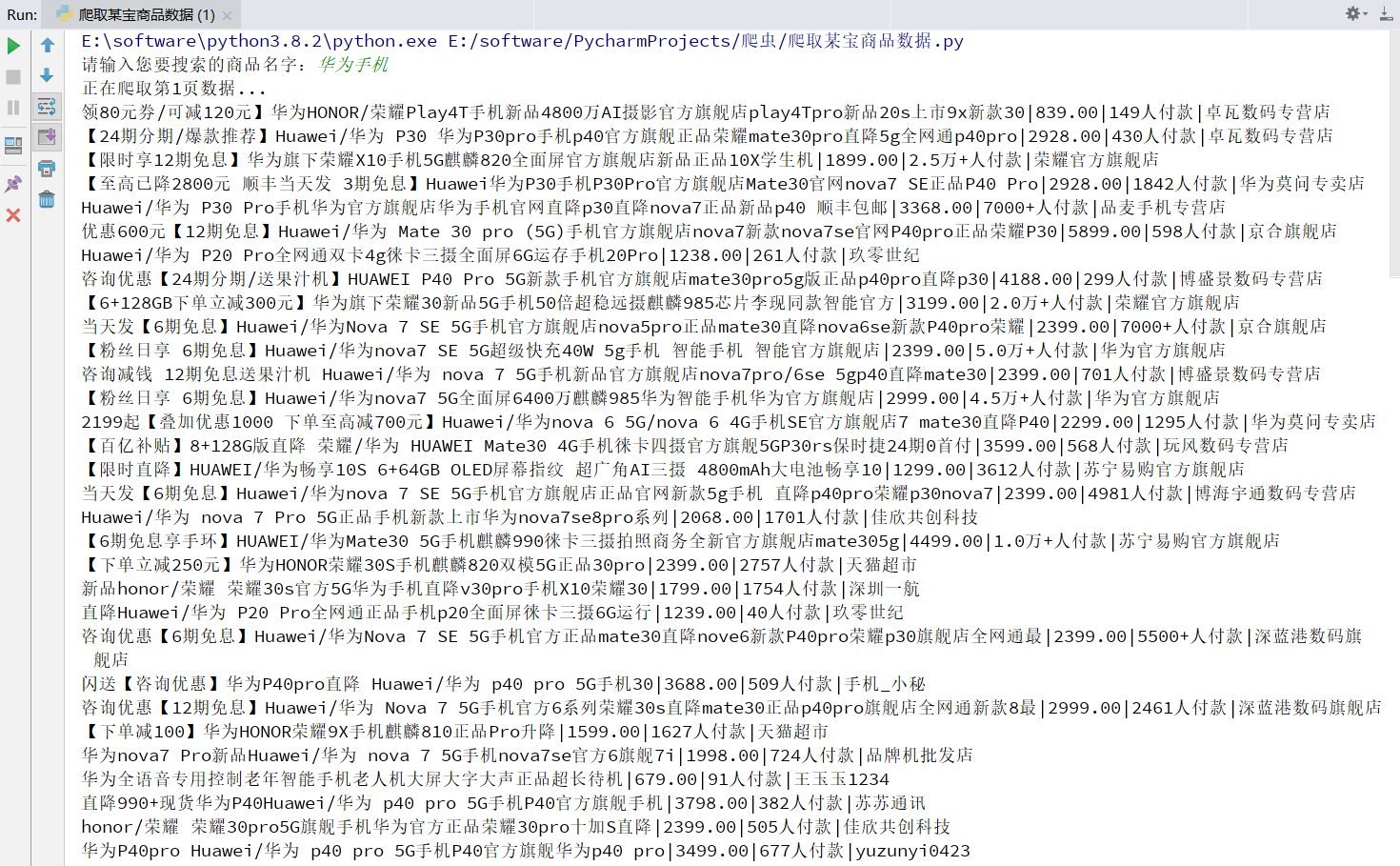
Screenshot display of total operation effect
This is the screenshot of PyCharm operation effect
This is the screenshot after opening the csv file
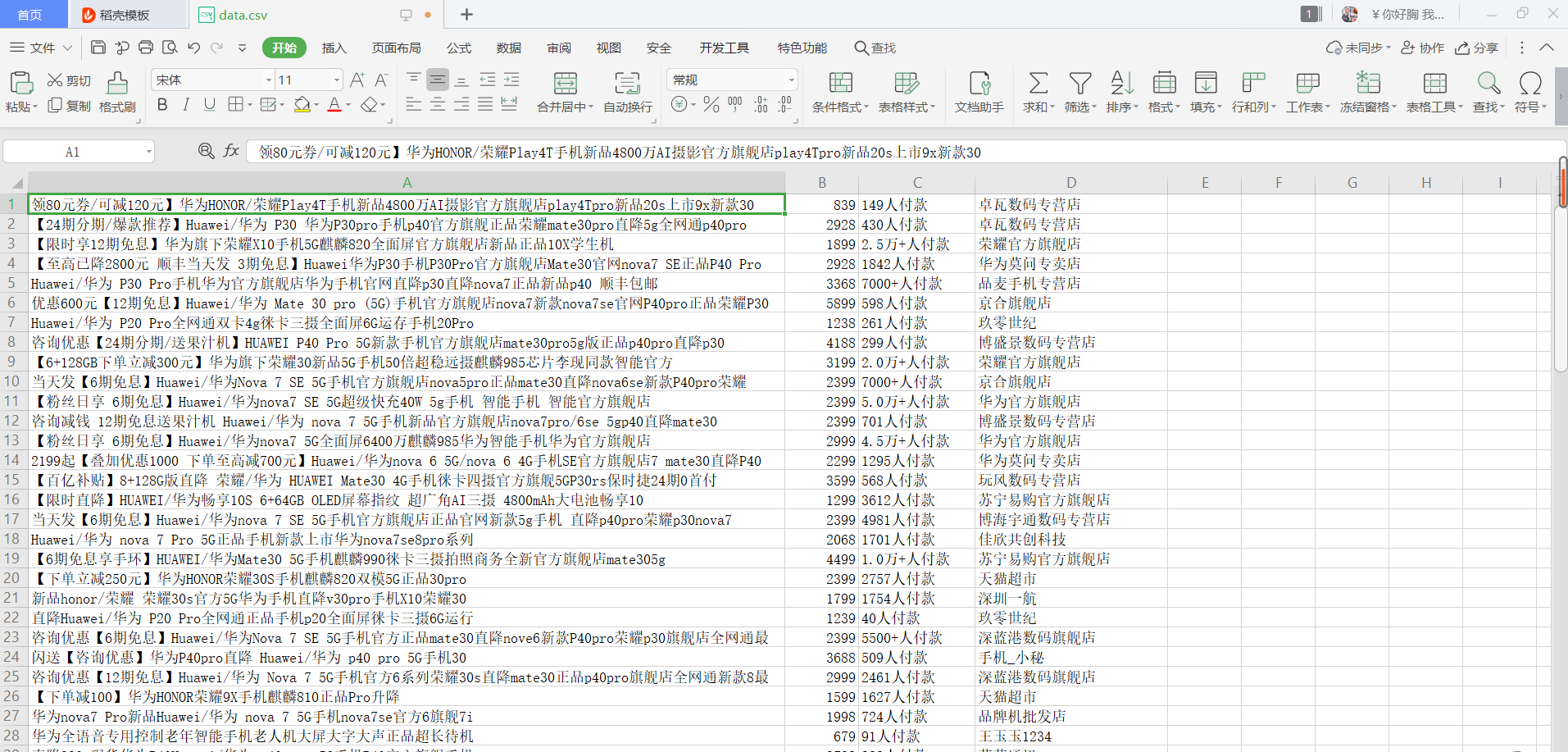
3 summary statement
Recently, I was preparing for the final exam. After July, I will write a crawler column: Python Network Data crawling and analysis "from beginner to proficient"
Interested friends can first pay attention to a wave!
For more original articles and classified columns, please click here → My home page.
★ copyright notice: This is CSDN blogger "Rongzai! The most beautiful boy! The copyright agreement of CC 4.0 BY-SA.
For reprint, please attach the original source link and this statement.
Welcome to leave a message, learn and communicate together~~~
Thank you for reading