preface
The text and pictures of this article are from the Internet, only for learning and communication, not for any commercial purpose. The copyright belongs to the original author. If you have any questions, please contact us in time for handling.
Recently, there is a very popular suspense and reasoning play: the secret corner. Douban scored 9.0. We had nothing to do at weekends. We crawled down the first episode of the play while chasing the play. We analyzed the play and made a word cloud to see how the audience evaluated the play.
The whole article is divided into two parts: 1. Crawling out the first episode of the play in iqiyi 2. Dealing with the crawling out of the screen and making word cloud.
1. Climb the iqiyi screen
Compared with other video websites, iqiyi's bullet screen is a little harder to climb. Why? Because the file you climb out is scrambled (with a map on the bottom), you need to binary code the file before using it. The specific steps are as follows:
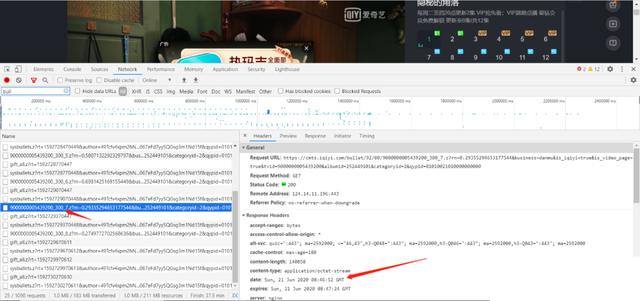
First, open the browser, enter the iqiyi page, click the play, and the pop-up screen will open. Then, F12, some interfaces will pop up under or on the right side of the browser. Select Network, and enter "bullet" in the box marked on my figure to search the files related to the pop-up screen. Why do you enter this search? Because the meaning of this word is pop-up screen, programmers usually name things regularly Yes, and most of the related documents of video websites are named ha ha. If you have no content after F12 search, just click the browser refresh button. The arrows in the figure below refer to Network, search box, screen file name and screen content (as you can see, bullet screen content is a mess). It's also important to note that there are more than one set of pop-up files. Iqiyi will load one pop-up file in 5 minutes (why 5 minutes, explained below).

Next, observe the law of the emergence of the bullet screen file and the law of the bullet screen file address, summarized as follows:
The link rule of bullet screen documents is
https://cmts.iqiyi.com/bullet/tvid First two bits of last four bits / TVID last two bits / tvid_300_x.z;
x is calculated by dividing the total duration of the film by 300 seconds and rounding it up, i.e. one packet per 5 minutes.
What's the tvid? It's the one in your URL navigation bar. Why x press 5 minutes for a package? It's because I check two adjacent pop-up packages after F12. It's 5 minutes to load one.

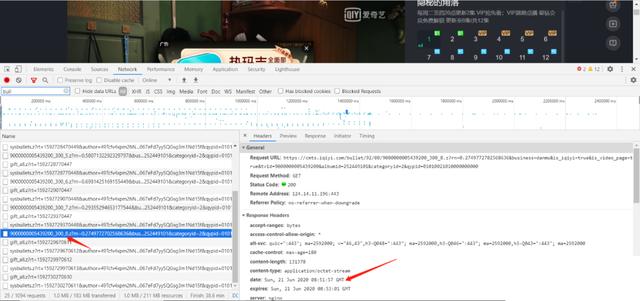
The first episode is 77 minutes in total. If you load a barrage file in 5 minutes, round it up. We need to grab 16 (77 / 5 + 1) barrage files in total.
The grab code is:
import zlib import requests for x in range(16): x+=1 #x It's from 1 to 16, 16. The first episode is 77 minutes in total. Iqiyi will load new screens every 5 minutes #77 Divide by 5 and round up url='https://cmts.iqiyi.com/bullet/92/00/9000000005439200_300_'+str(x)+'.z' bulletold=requests.get(url).content #The documents taken out in this step are disorderly bulletnew = bytearray(bulletold)#Use binary to recode the previous disorderly code file xml=zlib.decompress(bulletnew, 15+32).decode('utf-8') #Write 16 encoded files respectively xml In file (similar to txt File) for data retrieval with open('./iqiyi'+str(x)+'.xml','a+',encoding='utf-8') as f: f.write(xml) f.close()
The captured xml file is shown in the following figure. It can be seen that the content field is the bullet screen:
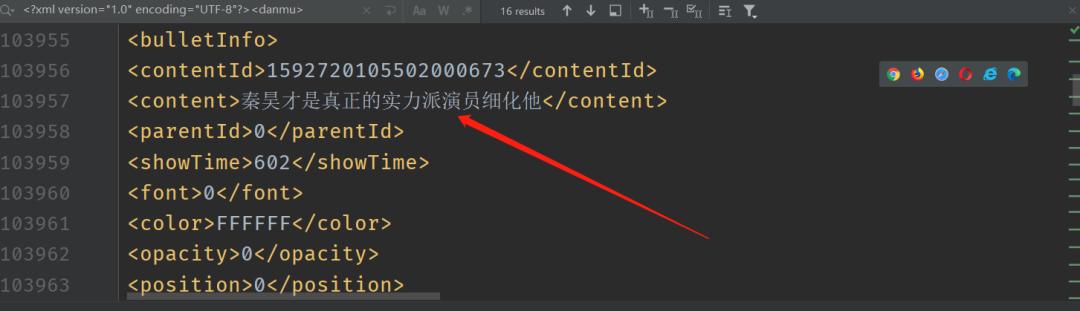
Take out the content field in the xml file and save it as dan_mu.txt File, convenient for us to do word cloud later:
from xml.dom.minidom import parse import xml.dom.minidom for x in range(16): x+=1 DOMTree = xml.dom.minidom.parse(r"C:\Users\dmj\PycharmProjects\test\iqiyi"+str(x)+".xml") collection = DOMTree.documentElement # Get all in collection entry data entrys = collection.getElementsByTagName("entry") print(entrys) for entry in entrys: content = entry.getElementsByTagName('content')[0] print(content.childNodes[0].data) i = content.childNodes[0].data with open("dan_mu.txt", mode="a+", encoding="utf-8") as f: f.write(i) f.write("\n")
dan_mu.txt The file is about this length:
2. Making word cloud
The wordcloud library and jieba Library of python are used for word cloud creation. The code is as follows:
from wordcloud import WordCloud import jieba import matplotlib.pyplot as plt #Read the barrage txt file with open('./dan_mu.txt',encoding = 'utf-8', mode = 'r')as f: myText = f.read() myText = " ".join(jieba.cut(myText)) list = myText.split(" ") #Cleaning useless data for i in range(len(list)-1,-1,-1): if len(list[i])==1 or list[i]=="this" or \ list[i]=="no" or list[i]=="such" \ or list[i]=="Yes?" or list[i]=="This is"\ or list[i]=="still": list.remove(list[i]) #print(list) myText= " ".join(list) print(myText) # Making word cloud wordcloud = WordCloud(background_color="white", font_path="simsun.ttf", height=300, width = 400).generate(myText) # Picture display plt.imshow(wordcloud) plt.axis("off") plt.show() # Export word cloud pictures to the current folder wordcloud.to_file("wordCloudMo.png")
The problem you may encounter here is that when downloading wordcloud, an external library, you may encounter various kinds of fancy error reports. How to solve this problem? Please refer to this elder brother's method below:
https://blog.csdn.net/qq_42813128/article/details/82020510The results of cloud map are as follows:

We can see from the cloud chart that the words "real", "children", "Yan Liang", "Pu", "acting" and other words appear frequently. "Real", "acting", "fierce" and other words are everyone's affirmation of the play; "child" refers to the three starring children; "Pu Pu" is really good at acting, and everyone guesses whether she will become the next Zhang Zifeng.
Generally speaking, everyone in the curtain of the play is highly praised, so it's worth watching.
Your favorite friends are welcome to pay attention to the editor. In addition to sharing technical articles, there are many benefits. Personal "information" can be obtained, including but not limited to Python practice, PDF electronic documents, interview brochures, learning materials, etc.