It's 11/11 again. I don't know when it started. 11/11 changed from "Singles Day" to "11/11 Shopping Carnival". The last single dog festival was also successfully conquered and became a holiday for couples to give gifts and love.
Turning over the quiet to silent chat list, I suddenly woke up. No, we can't go on like this. What's the use of envying others? We need to take action to find our own happiness!!!
I also want to "talk about love without breaking up"!!!Tearful!!!
Register for landing at once~
Screening criteria, Hmm... Sex female, age... 18 to 24 years old, height, it doesn't matter, just press the default 155-170, region... Hmm Beijing is good, Beijing is closer, photos?That must be, must be!!!
Sisters, I'm here~
Wow, many ladies and sisters, which one to pick up after all....

It's time for our crawlers to show up
Reptilian section
The crawler section is also our previous four steps: analyzing the target page, getting the content of the page, extracting key information, and saving the output
1. First analyze the target page
Press F12 to invoke the Developer Tools page, switch to the Network option, and then grab the package while paging to successfully intercept the request URL.
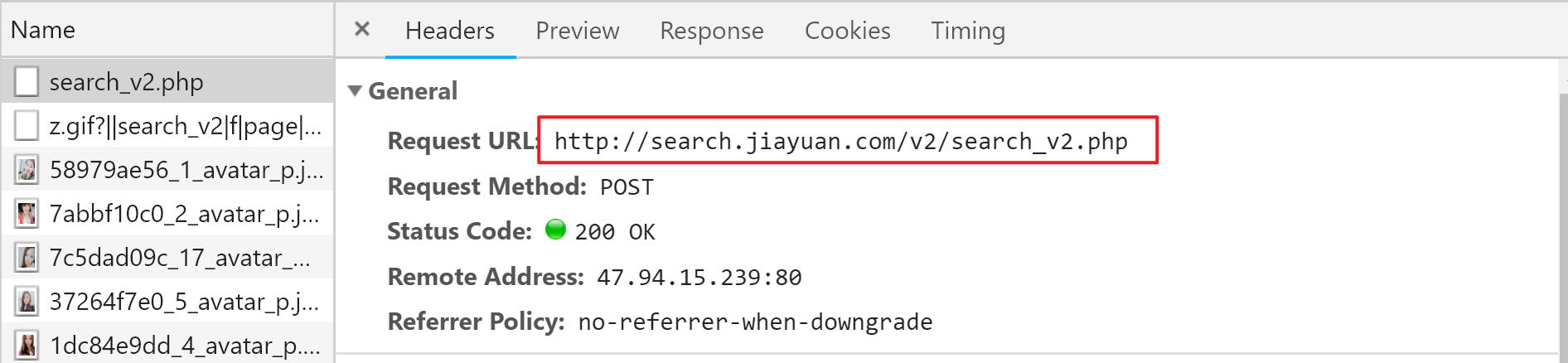
However, this request is a POST method, which is slightly different from the GET method we saw earlier.Where's the difference... It's a little short?
Yes, it is too short, there is a lot of information missing, such as the conditions we search for, even the information of page number, how can it be used to find Miss Sister correctly?
Don't worry, flip down. In fact, the parameters requested by the POST method are placed in the Form Data (why not, maybe)

PS: In addition to these, there are more detailed filter criteria
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| region | Age | height | Education | A monthly salary | Marriage History | Home Purchase | Car Buying | Origin | Registered residence |
| 11 | 12 | 12 | 14 | 15 | 16 | 17 | 18 | 22 | 23 |
| Nation | Religious belief | With or without children | Occupation | Company type | The Chinese Zodiac | constellation | Blood type | Integrity Level | Photo |
Construct a complete request URL,
Access, no problem, change the value of p, access, no problem, OK completed this stage.
2. Parse Web Content
From the url above, we can get user information in json format returned by the server.The code is as follows:
import requestsdef fetchURL(url):
'''
//Function: Visit url's web page, get web content and return
//Parameters:
url : Target Page's url
//Return: html content of the target page
'''
headers = { 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36', 'Cookie': 'guider_quick_search=on; SESSION_HASH=f09e081981a0b33c26d705c2f3f82e8f495a7b56; PHPSESSID=e29e59d3eacad9c6d809b9536181b5b4; is_searchv2=1; save_jy_login_name=18511431317; _gscu_1380850711=416803627ubhq917; stadate1=183524746; myloc=11%7C1101; myage=23; mysex=m; myuid=183524746; myincome=30; COMMON_HASH=4eb61151a289c408a92ea8f4c6fabea6; sl_jumper=%26cou%3D17%26omsg%3D0%26dia%3D0%26lst%3D2018-11-07; last_login_time=1541680402; upt=4mGnV9e6yqDoj%2AYFb0HCpSHd%2AYI3QGoganAnz59E44s4XkzQZ%2AWDMsf5rroYqRjaqWTemZZim0CfY82DFak-; user_attr=000000; main_search:184524746=%7C%7C%7C00; user_access=1; PROFILE=184524746%3ASmartHe%3Am%3Aimages1.jyimg.com%2Fw4%2Fglobal%2Fi%3A0%3A%3A1%3Azwzp_m.jpg%3A1%3A1%3A50%3A10; pop_avatar=1; RAW_HASH=n%2AazUTWUS0GYo8ZctR5CKRgVKDnhyNymEBbT2OXyl07tRdZ9PAsEOtWx3s8I5YIF5MWb0z30oe-qBeUo6svsjhlzdf-n8coBNKnSzhxLugttBIs.; pop_time=1541680493356'
} try:
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = 'unicode_escape'
print(r.url) return r.text except requests.HTTPError as e:
print(e)
print("HTTPError") except requests.RequestException as e:
print(e) except:
print("Unknown Error !")if __name__ == '__main__':
url = 'http://search.jiayuan.com/v2/search_v2.php?key=&sex=f&stc=2:18.24,3:155.170,23:1&sn=default&sv=1&p=1&f=select'
html = fetchURL(url)
print(html)Here are a few points to note:
(1) The search function of the website needs to be logged on, otherwise it will always be prompted to log on by a pop-up box, so I have to register an account and put the cookie in the crawler's request header after logging on, so that I can access the data correctly (but during crawling, I find that I don't need to log on to get it, am I losing?!)
(2) The result returned by the direct open request can not be "read". There is not a single Chinese character in the whole passage, it is all kind of things like garbled code. This is a kind of unicode encoding, which converts Chinese characters into a string of characters beginning with \.

It is also easy to decode Chinese characters by setting the encoding of response to unicode_escape is fine.
r = requests.get(url, headers=headers) r.raise_for_status() r.encoding = 'unicode_escape'print(r.text)
(3) In order to find as many sisters as possible, I decided to remove the restriction of "region" and visit again. Sure enough, the number of sisters I found rose from 3229 to 59146 in an instant, so I can climb happily now.

3. Extract key information
By analyzing the josn file we can see that there is a lot of information about the user, including user ID, nickname, gender, age, height, photo, education, city, criteria for spouse selection, personality declaration, etc. (But some information is not available here, you need to go to your home page to view it, such as income, etc.).
import jsondef parserHtml(html):
'''
//Function: Try to parse the structure of a memory HTML file given the parameter HTML to get what you want
//Parameters:
html: Memory for similar files HTML Text object
'''
s = json.loads(html)
usrinfo = []
for key in s['userInfo']:
blist = []
uid = key['uid']
nickname = key['nickname']
sex = key['sex']
age = key['age']
work_location = key['work_location']
height = key['height']
education = key['education']
matchCondition = key['matchCondition']
marriage = key['marriage']
income = key['income']
shortnote = key['shortnote']
image = key['image']
blist.append(uid)
blist.append(nickname)
blist.append(sex)
blist.append(age)
blist.append(work_location)
blist.append(height)
blist.append(education)
blist.append(matchCondition)
blist.append(marriage)
blist.append(income)
blist.append(shortnote)
blist.append(image)
usrinfo.append(blist)
print(nickname,age,work_location) #writePage(usrinfo)
print('---' * 20)Some of the results are as follows: http://search.jiayuan.com/v2/search_v2.php?key=&sex=f&stc=2:18.24,3:155.170,23:1&sn=default&sv=1&p=1&f=select Xiaowen 23 Xi'an Also single sugar bean 18 Jinan White Rabbit Small 24 Huaihua Xiao Ya xy 24 Shenzhen Regret Dream Margin 23 Hangzhou Winter 24 Nanjing Qian 141 21 Shijiazhuang Ranger Heart Injury 24 Minhang Tall lemon 24 Changsha Sweet 23 Zhengzhou ------------------------------------------------------------ http://search.jiayuan.com/v2/search_v2.php?key=&sex=f&stc=2:18.24,3:155.170,23:1&sn=default&sv=1&p=2&f=select Mushroom 24 Wuhan Low-key Residence Women 24 Nanjing Ms. 21 Nanjing A glimmer in the distance 23 Nanjing Nana 24 Hebei I like you most 24 Luoyang Smiley Mushroom 24 Guangzhou LLS 24 Huizhou Worth 24 Wuxi Suyuan 23 Jiangbei ------------------------------------------------------------
4. Save the output file
Finally, you only need to write the extracted information to the csv file to complete the crawl.Here is the complete code:
import requestsimport jsonimport timedef fetchURL(url):
'''
//Function: Visit url's web page, get web content and return
//Parameters:
url : Target Page's url
//Return: html content of the target page
'''
headers = { 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36', 'Cookie': 'guider_quick_search=on; SESSION_HASH=f09e081981a0b33c26d705c2f3f82e8f495a7b56; PHPSESSID=e29e59d3eacad9c6d809b9536181b5b4; is_searchv2=1; save_jy_login_name=18511431317; _gscu_1380850711=416803627ubhq917; stadate1=183524746; myloc=11%7C1101; myage=23; mysex=m; myuid=183524746; myincome=30; COMMON_HASH=4eb61151a289c408a92ea8f4c6fabea6; sl_jumper=%26cou%3D17%26omsg%3D0%26dia%3D0%26lst%3D2018-11-07; last_login_time=1541680402; upt=4mGnV9e6yqDoj%2AYFb0HCpSHd%2AYI3QGoganAnz59E44s4XkzQZ%2AWDMsf5rroYqRjaqWTemZZim0CfY82DFak-; user_attr=000000; main_search:184524746=%7C%7C%7C00; user_access=1; PROFILE=184524746%3ASmartHe%3Am%3Aimages1.jyimg.com%2Fw4%2Fglobal%2Fi%3A0%3A%3A1%3Azwzp_m.jpg%3A1%3A1%3A50%3A10; pop_avatar=1; RAW_HASH=n%2AazUTWUS0GYo8ZctR5CKRgVKDnhyNymEBbT2OXyl07tRdZ9PAsEOtWx3s8I5YIF5MWb0z30oe-qBeUo6svsjhlzdf-n8coBNKnSzhxLugttBIs.; pop_time=1541680493356'
} try:
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = 'unicode_escape'
print(r.url) return r.text except requests.HTTPError as e:
print(e)
print("HTTPError") except requests.RequestException as e:
print(e) except:
print("Unknown Error !")def parserHtml(html):
'''
//Function: Try to parse the structure of a memory HTML file given the parameter HTML to get what you want
//Parameters:
html: Memory for similar files HTML Text object
'''
s = json.loads(html)
usrinfo = []
for key in s['userInfo']:
blist = []
uid = key['uid']
nickname = key['nickname']
sex = key['sex']
age = key['age']
work_location = key['work_location']
height = key['height']
education = key['education']
matchCondition = key['matchCondition']
marriage = key['marriage']
income = key['income']
shortnote = key['shortnote']
image = key['image']
blist.append(uid)
blist.append(nickname)
blist.append(sex)
blist.append(age)
blist.append(work_location)
blist.append(height)
blist.append(education)
blist.append(matchCondition)
blist.append(marriage)
blist.append(income)
blist.append(shortnote)
blist.append(image)
usrinfo.append(blist)
print(nickname,age,work_location)
writePage(usrinfo)
print('---' * 20)def writePage(urating):
'''
Function : To write the content of html into a local file
html : The response content
filename : the local filename to be used stored the response
'''
import pandas as pd
dataframe = pd.DataFrame(urating)
dataframe.to_csv('Jiayuan_UserInfo.csv', mode='a', index=False, sep=',', header=False)if __name__ == '__main__': for page in range(1, 5916):
url = 'http://search.jiayuan.com/v2/search_v2.php?key=&sex=f&stc=2:18.24,3:155.170,23:1&sn=default&sv=1&p=%s&f=select' % str(page)
html = fetchURL(url)
parserHtml(html) #To reduce the risk of blocked ip s, there is a 5-second pause for every 100 pages crawled.
if page%100==99:
time.sleep(5)follow-up work
1. Document Reduplication
It took me more than two hours to crawl over 5,000 pages and nearly 60,000 data, which was originally a very happy thing, but when I opened the file and sorted it by user ID, I found it!!!!

Devil!!!There is a large amount of duplicate data. Just this user named "Name Fang", there are more than 2,000, which is great?!!
To verify if something went wrong with my program, I checked and debugged repeatedly for a long time.
I find that if you only crawl the first 100 pages of data, the repetition rate is low, and after 100 pages, a large number of repetitive users begin to appear; and the repetitive data does not appear continuously on the same page, but from different pages.
Best of all, he asks the big man for help. After he listens to my description, he says, is it the data of the website itself that is problematic?
To solve this puzzle, I decided to go to the website and find out manually what happened after 100 pages.
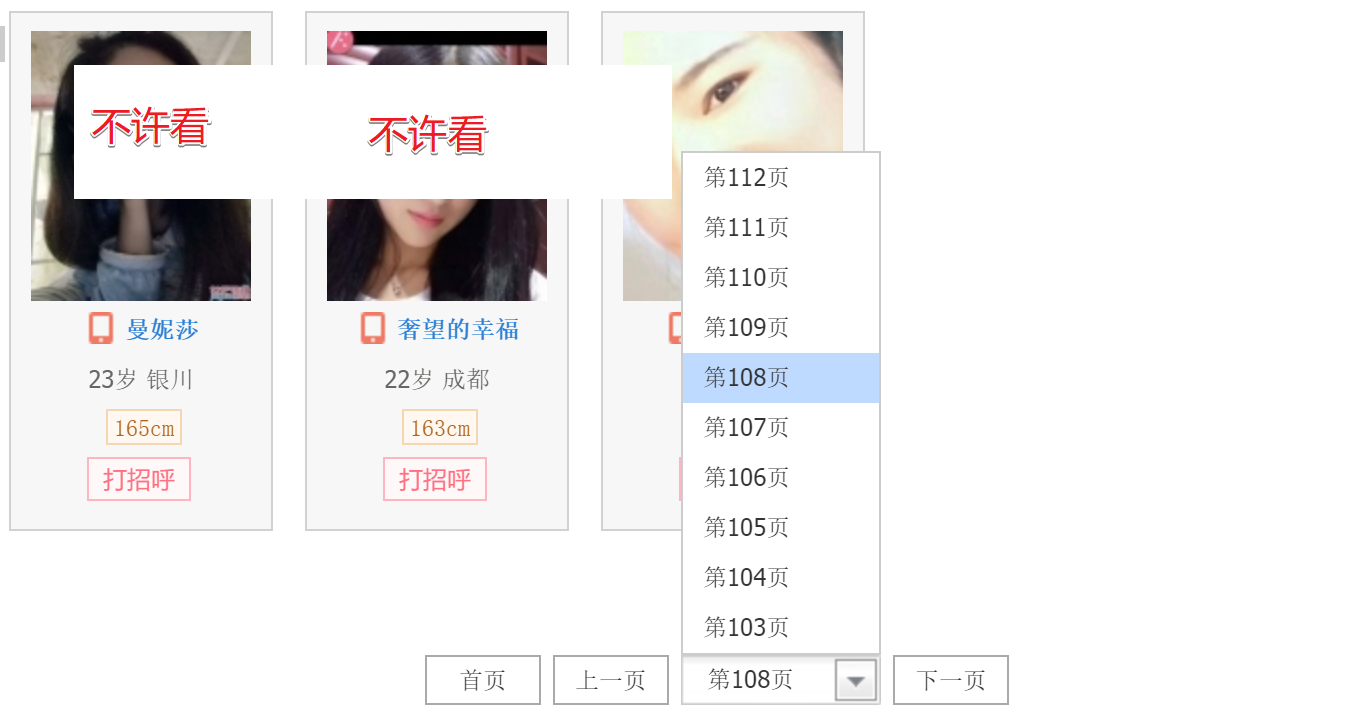
The page turning function of this site is rather poor, with only the first page, the previous page and the next page, and page number jumps of only five pages at a time.After clicking for a long time and reaching more than one hundred pages, I found a shocking thing.
This is a three-page screenshot I took at hand, 108 pages, 109 pages, and 110 pages. There are screenshots below the picture as proof, to feel, and to follow.
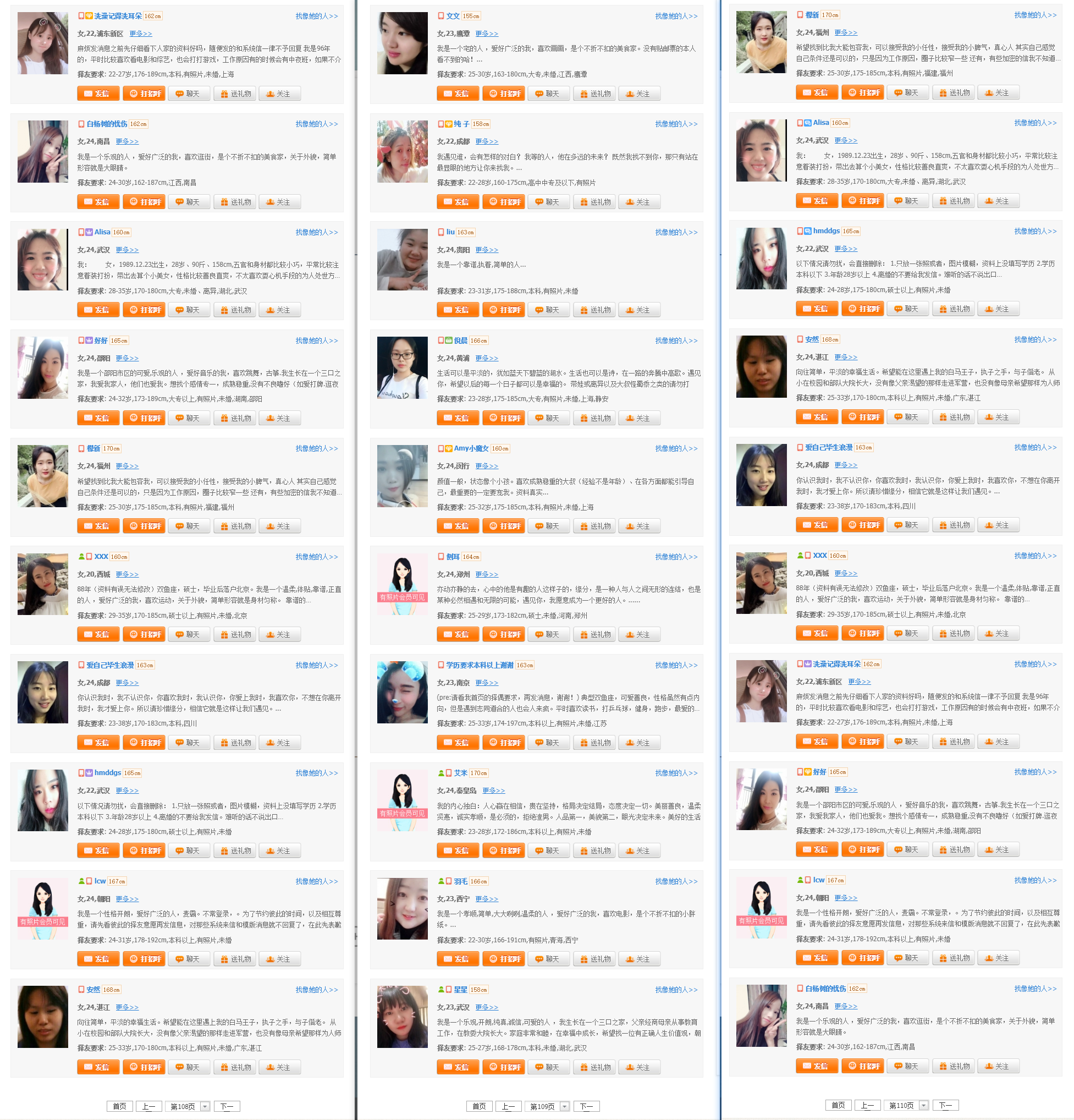
Okay, the same users change the order to make up the pages, right? Now I want to see how many pages are left after weighting.
import pandas as pd
inputfile = "Jiayuan_UserInfo.csv"outputfile = "Jiayuan_UserInfo_output.csv"df = pd.read_csv(inputfile,encoding='utf-8',names=['uid','nickname','sex','age','work_location','height','education','matchCondition','marriage','income','shortnote','image'])
datalist = df.drop_duplicates()
datalist.to_csv(outputfile,encoding='utf-8',index=False, header=False)
print("Done!")Here are the results:
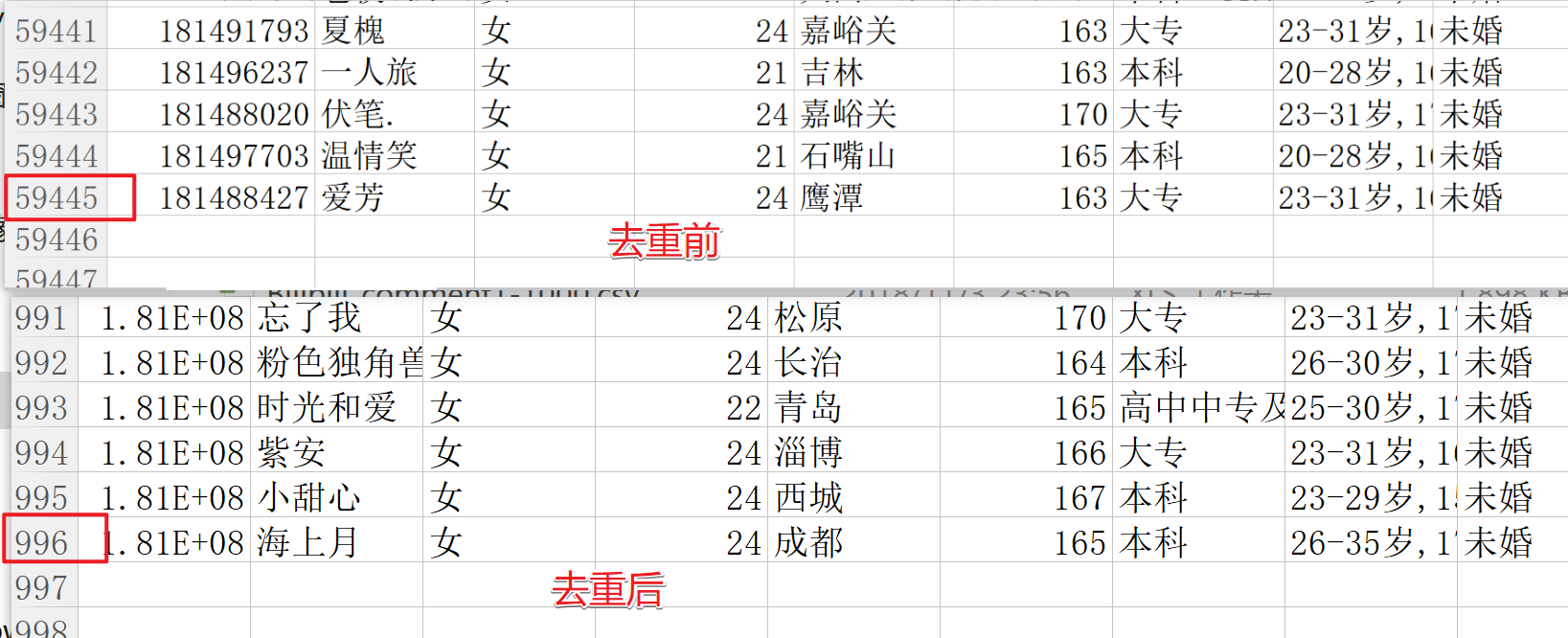
In search results of nearly 60,000 people, there are actually less than 1,000 people left after weight removal. Look back and see if there are 592 people who meet the criteria on the website. Does that make you feel smacked?Use this method to create the illusion of a large number of users, smart.
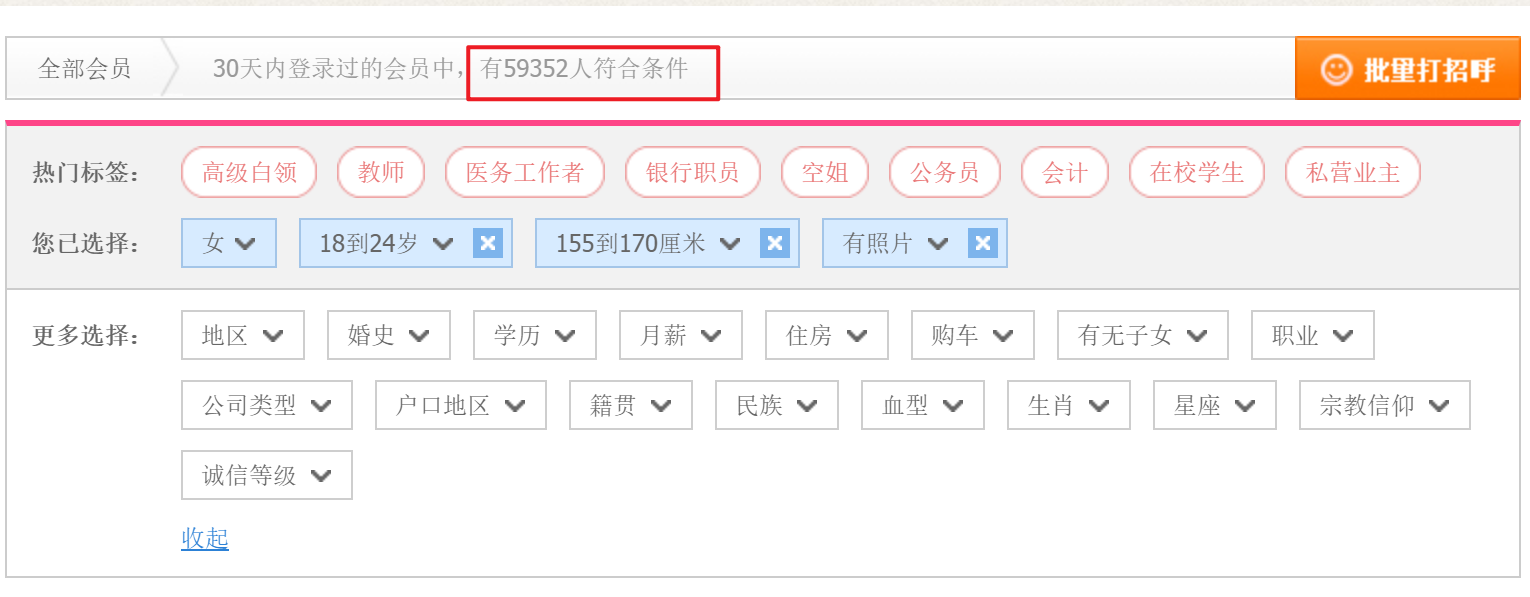
2. Photo Download
Put aside the data and tell the truth, the purpose of our trip is to see your sister come!
To get it right, let's download the photos of the ladies and sisters. The link to the photos is in the csv file we saved before.
import requestsimport pandas as pd#Read CSV file userData =Pd.read_CSV ("Jiayuan_UserInfo_Output.csv', names=['uid','nickname','sex','age','work_Location','height','education','matchCondition','marriage','income','shortnote','image']) for line in range (len (userData):
url = userData['image'][line]
img = requests.get(url).content
nickname = re.sub("[\s+\.\!\/_,$%^*(+\"\'?|]+|[+-!,. ?,~@#¥%......&*()▌]+", "",userData['nickname'][line])
filename = str(line) + '-' + nickname + '-' + str(userData['height'][line]) + '-' + str(userData['age'][line]) + '.jpg'
try: with open('images_output/' + filename, 'wb') as f:
f.write(img) except:
print(filename)
print("Finished!")For ease of identification, I use serial number + user nickname + height + age as the filename of the picture
One thing to note here is that user nicknames may contain strange characters. If they are used as file names, there will be exceptions when saving files. So here we first do some processing on user names, exclude punctuation and other characters, and do an exception handling, that is, if there is an exception, output the file name and continueSave the next one.
So I got 996 pictures of Miss and Sister.
But these are not important anymore.
This time, I not only successfully crawled all the data of my sister, but also found a little "secret" of the website.
At this time, I'm expanding so much that I think I'm terrific
I don't think they're up to me.
If there is something in the article that you don't understand or explain incorrectly, you are welcome to criticize and correct it in the commentary area, or scan the QR code below, add me WeChat, and learn to communicate and make progress together.
