Small T guide: the monitoring platform of electric power dynamometer system is designed and developed based on the equipment data acquisition and equipment Bank V2.0 application of China Telecom Shanghai ideal information industry (Group) Co., Ltd. The real-time data of the collected devices are stored in TDengine.
Application background
The power dynamometer system monitoring platform is developed and designed based on the equipment data collection and equipment Bank V2.0 application of China Telecom Shanghai ideal information industry (Group) Co., Ltd. the software is the core of the power dynamometer system monitoring platform and an important part of realizing data aggregation, data processing, visual display and dynamometer test. According to the power dynamometer system collection According to the functional requirements of the control interface, the monitoring platform architecture of the whole power measurement system can be divided into four parts: equipment layer, network layer, platform layer and display layer. The overall structure is as follows: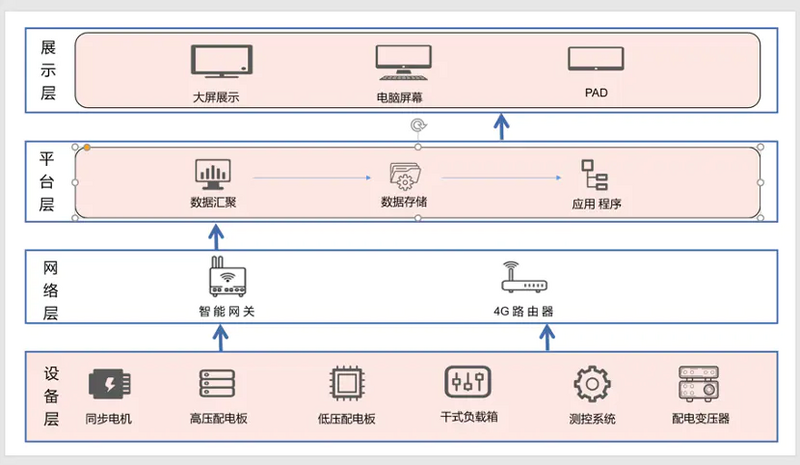
Real time data is stored in TDengine database and communicates with equipment bank. The data flow is as follows: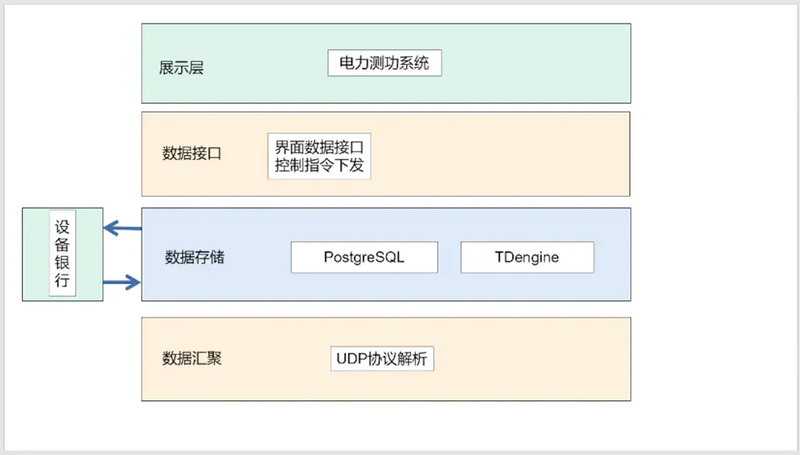
The equipment bank is mainly responsible for the management of template, equipment and alarm information. Its visual interface is as follows: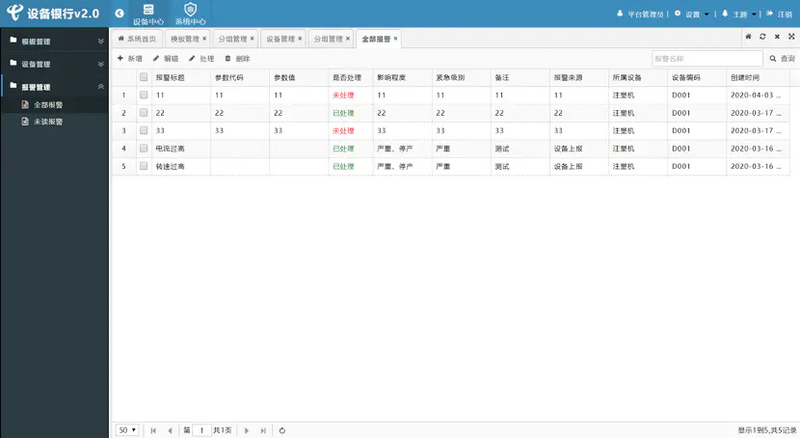
Spark+TDengine usage process
1. Installation of tdengine
Please refer to official documents: www.taosdata.com/cn/document...
2. Build test database and test table in TDengine
taos> create database test; taos>use test; #Here, we create a table with the same structure as the log table in the tdengine's own library log. Later, we will refer to log.log Read data stored in test.log_cp taos> create table log_cp( -> ts TIMESTAMP, -> level TINYINT, -> content BINARY(80), -> ipaddr BINARY(15) -> )
3. Spark reads TDengine
TDengine does not provide a DataSource called by Spark, but TDengine itself supports JDBC. Therefore, here use Spark JDBC to read TDengine. The latest version can be downloaded on the official website. I use the following version:
<dependency> <groupId>com.taosdata.jdbc</groupId> <artifactId>taos-jdbcdriver</artifactId> <version>1.0.3</version> </dependency>
For the use of JDBC, the official website has the following tips:
Because TDengine is developed in C language, it depends on the local function library of the system when using the Taos jdbc driver driver package.
One libtaos.so After TDengine is successfully installed in Linux system, the dependent local function library libtaos.so Files are automatically copied to / usr/lib/libtaos.so , which is included in the Linux Autoscan path and does not need to be specified separately.
Two taos.dll After installing the client in windows system, the driver package depends on the taos.dll The file will be automatically copied to the system default search path C:/Windows/System32, which also does not need to be specified separately.
For the first time, in order to ensure that there is libtaos.so or taos.dll You need to install the TDengine client locally (for the client, please download it on the TDengine website). The read code of Spark is as follows:
val jdbccdf = spark .read .format("jdbc") .option("url", "jdbc:TAOS://192.168.1.151:6030/log") .option("driver", "com.taosdata.jdbc.TSDBDriver") .option("dbtable", "log") .option("user", "root") .option("password", "taosdata") .option("fetchsize", "1000") .load()
4. Spark TDengine
Because when reading TDengine, the first field ts will be converted to decimal, but it is not recognized to directly store the decimal tdengine in storage, so it is necessary to convert ts into type
jdbccdf.select(($"ts" / 1000000).cast(TimestampType).as("ts"), $"level", $"content", $"ipaddr") .write.format("jdbc") .option("url", "jdbc:TAOS://192.168.1.151:6030/test?charset=UTF-8&locale=en_US.UTF-8") .option("driver", "com.taosdata.jdbc.TSDBDriver") .option("dbtable", "log2") .option("user", "root") .option("password", "taosdata") .mode(SaveMode.Append) .save()
5. Run TDengine in spark yarn mode
The above tests are all based on the local test of the master. If they are run in the yarn mode, it is unrealistic to install the TDengine client on each node. Check the code of the taos jdbc driver and find out that the driver will execute System.load("taos"), that is, as long as java.library.path Exists in libtaos.so The program can run normally without installing the client of TDengine because java.library.path It is set when the jvm starts. To change its value, dynamic loading can be used. The following methods are used to solve the loading problem libtaos.so Questions:
(1) Driving end libtaos.so Send to each executor
spark.sparkContext.addFile("/path/to/libtaos.so")
(2) Override the createConnectionFactory method in the JdbcUtils class in Spark, and add
loadLibrary(new File(SparkFiles.get("libtaos.so")).getParent)
conduct java.library.path Dynamic loading of
def createConnectionFactory(options: JDBCOptions): () => Connection = { val driverClass: String = options.driverClass () => { loadLibrary(new File(SparkFiles.get("libtaos.so")).getParent) DriverRegistry.register(driverClass) val driver: Driver = DriverManager.getDrivers.asScala.collectFirst { case d: DriverWrapper if d.wrapped.getClass.getCanonicalName == driverClass => d case d if d.getClass.getCanonicalName == driverClass => d }.getOrElse { throw new IllegalStateException( s"Did not find registered driver with class $driverClass") } driver.connect(options.url, options.asConnectionProperties) } }
(3) The loadlibrary method is as follows
def loadLibrary(libPath: String): Unit = { var lib = System.getProperty("java.library.path") val dirs = lib.split(":") if (!dirs.contains(libPath)) { lib = lib + s":${libPath}" System.setProperty("java.library.path", lib) val fieldSysPath = classOf[ClassLoader].getDeclaredField("sys_paths") fieldSysPath.setAccessible(true) fieldSysPath.set(null, null) } }
In yarn mode, you must set charset and locale for the url, such as
charset=UTF-8&locale=en_US.UTF-8
Otherwise, the container may exit abnormally.
Six libtaos.so Other loading methods
I also tried jna loading libtaos.so This method only needs to libtaos.so Put it into the project resources, the program will automatically search for the so file, so the code of c in tdengine will not be changed.
About the author: Dong Hongfei, big data development engineer, joined Shanghai ideal big data implementation department in 2015 and has worked so far. At present, he is mainly responsible for the design and development of the company's data bus products.
Company profile: China Telecom Shanghai ideal information industry (Group) Co., Ltd., founded in 1999 with a registered capital of 70 million yuan, is one of the information technology enterprises with large investment scale in Shanghai. Through the integration of the overall strength of the large-scale project implementation of each business unit in the company for many years, the company strives to forge the consulting planning and top-level design capacity of large-scale information projects, build "smart community", "smart Park" and "smart government", "smart medical", "smart Logistics" and other intelligent industry applications and other overall solutions, which can provide IT outsourcing services and network monitoring The one-stop safety solution for operation and maintenance management has gradually formed the product R & D accumulation and project delivery and platform operation experience in the "smart city" professional field, forging the comprehensive strength of the overall scientific research team and project implementation team.