preface:
In the holiday, often want to try their own cooking, kitchen this website is a good choice. Under the kitchen is one of the necessary sites, mainly provides a variety of food practices and cooking skills, including many kinds. Today, I will teach you to climb and take down the recipes in the kitchen and save them in the world file, so that you can make your own recipes in the future.
1, Project purpose
Obtain the recipe, and save the recipe name, raw materials, download links and downloads in the world document in batch.
2, Project preparation
Software: PyCharm
Required libraries: requests, lxml, fake_useragent,time
The website is as follows:
https://www.xiachufang.com/explore/?page={}When clicking the next page, each page added will be increased by 1, and {} will be used to replace the transformed variable, and then for loop will be used to traverse the URL to realize multiple URL requests.
3, Treatment of anti climbing measures
There are two main points to note:
1. Use the requests library directly. Without setting any header s, the website will not return data directly
2. The same ip is accessed several times in a row and directly blocked. At first, my ip was blocked in this way. In order to solve these two problems, after the final study, the following methods can be used effectively.
(1) Get the normal http request headers and set these regular http request headers when requests are requested.
(2) Using fake_ User agent, generate random user agent for access.
4, Project implementation
1. Define a class class to inherit object, define init method to inherit self, and main function to inherit self. Import the required library and URL, the code is as follows.
import requests
from lxml import etree
from fake_useragent import UserAgent
import time
class kitchen(object):
def __init__(self):
self.url = "https://www.xiachufang.com/explore/?page={}"
def main(self):
pass
if __name__ == '__main__':
imageSpider = kitchen()
imageSpider.main()2. Generate UserAgent randomly.
for i in range(1, 50):
self.headers = {
'User-Agent': ua.random,
}3. Send request to get response, page callback, convenient for next request.
def get_page(self, url):
res = requests.get(url=url, headers=self.headers)
html = res.content.decode("utf-8")
return html4. xpath parses the primary page data to obtain the secondary page URL.
def parse_page(self, html):
parse_html = etree.HTML(html)
image_src_list = parse_html.xpath('//li/div/a/@href')5. for traversal, defining a variable food_info to get the corresponding menu name, raw material and download link on the secondary page.
for i in image_src_list:
url = "https://www.xiachufang.com/" + i
# print(url)
html1 = self.get_page(url) # Second occurrence request
parse_html1 = etree.HTML(html1)
# print(parse_html1)
num = parse_html1.xpath('.//h2[@id="steps"]/text()')[0].strip()
name = parse_html1.xpath('.//li[@class="container"]/p/text()')
ingredients = parse_html1.xpath('.//td//a/text()')
food_info = '''
//Type% s
//Dish name:% s
//Raw material:% s
//Download link:% s,
=================================================================
''' % (str(self.u), num, ingredients, url)6. Save in a world document.
f = open('go to the kitchen/menu.doc', 'a', encoding='utf-8') # Open file as' w '
f.write(str(food_info))
f.close()7. Call the method to realize the function.
html = self.get_page(url) self.parse_page(html)
8. Project optimization
(1) Method 1: set the time delay.
time.sleep(1.4)
(2) Method 2: define a variable u,for traversal, indicating that the second kind of food is crawled. (clearer and more impressive).
u = 0 self.u += 1;
5, Effect display
1. Click the green triangle to run the input start page and the end page.
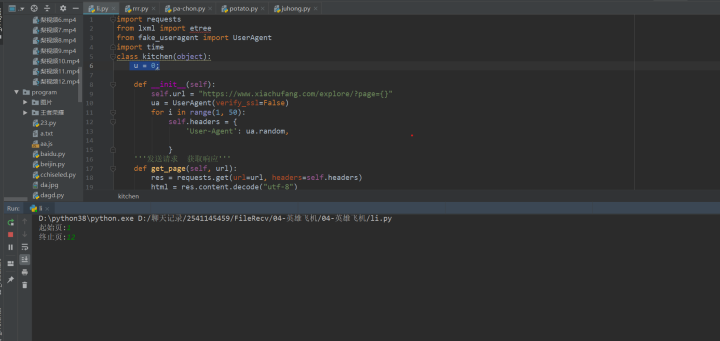
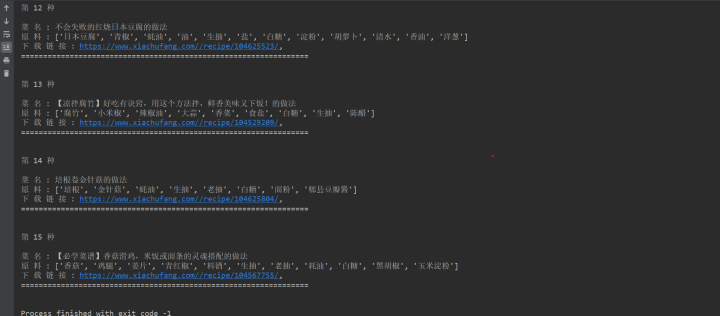
2. After running the program, the results are displayed in the console, as shown in the following figure.
3. Save the running results in the world document, as shown in the following figure.
4. Double click the file, and the content is as shown in the figure below.

Finally, the conclusion is as follows:
1. Based on Python web crawler, this paper obtains the recipe information of kitchen website, the difficulties and key points in the application, and how to prevent anti climbing, and makes a relative solution.
2. It introduces how to splice strings and how to convert lists into types.
3. The code is very simple. I hope it can help you.
4. You are welcome to actively try. Sometimes it's easy to see others realize it. But when you do it yourself, there will always be all kinds of problems. Don't look too high or too low. Only by doing it frequently can you understand it more deeply.
5. You can choose your favorite categories and get your favorite recipes. Everyone is a chef.
6, welcome to everyone, message, forwarding, thank you for your support and cooperation, need this source code can pay attention to the official account: "Python's advanced journey" surprise! I think it's good. Give it a Star~
