In the era of information explosion, how can you obtain effective information efficiently?
This small case also uses two key databases in python, requests and beautiful soup, to initiate requests and analyze web data. The little partners who are not familiar with the use of these two databases can check the data online and learn. I will not explain too much here, but mainly talk about how to use them
1. First, be sure to import two tool libraries at the beginning of the code file
import requests from bs4 import BeautifulSoup
2. After the two libraries are ready, you can encapsulate the function that initiates the request in the function body
# Get the page content under the current url and return the soup object def get_page(link_url): response = requests.get(link_url) soup = BeautifulSoup(response.text, 'lxml') return soup
3. After the request is initiated, analyze the web code, find the specific link we want, and store it in the list
# Get all listings links def get_links(url): soup = get_page(url) # find_all is to get all the information link_div = soup.find_all('div', class_='content__list--item') # Get the div containing the link links = [url+div.a.get('href') for div in link_div] # List derivation print all listings url return links
Using find_all function gets all contents in the soap object__ List – item, get the corresponding url and store it in the list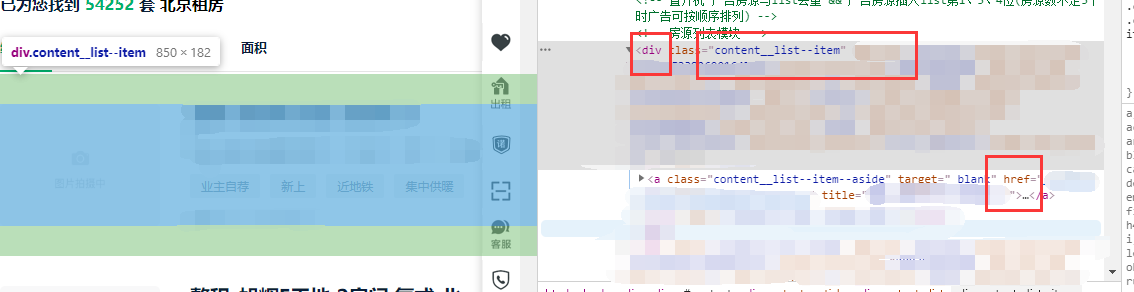
4. After obtaining our link information in batch, go deep into the interface corresponding to the link, analyze the web code, and package it into the function body
Like getting rent
! [insert picture description here]( https://img-blog.csdnimg.cn/20200613084317599.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1pfbG92ZV91,size_16,color_FFFFFF,t_70find function obtains a single piece of data, finds the value of corresponding div and corresponding class to lock
money = page_res.find('div', class_='content__aside--title') danwei = page_res.find('div', class_ = 'content__aside--title')
5. The same is true for other information. Use find in combination_ All and find methods get the corresponding information
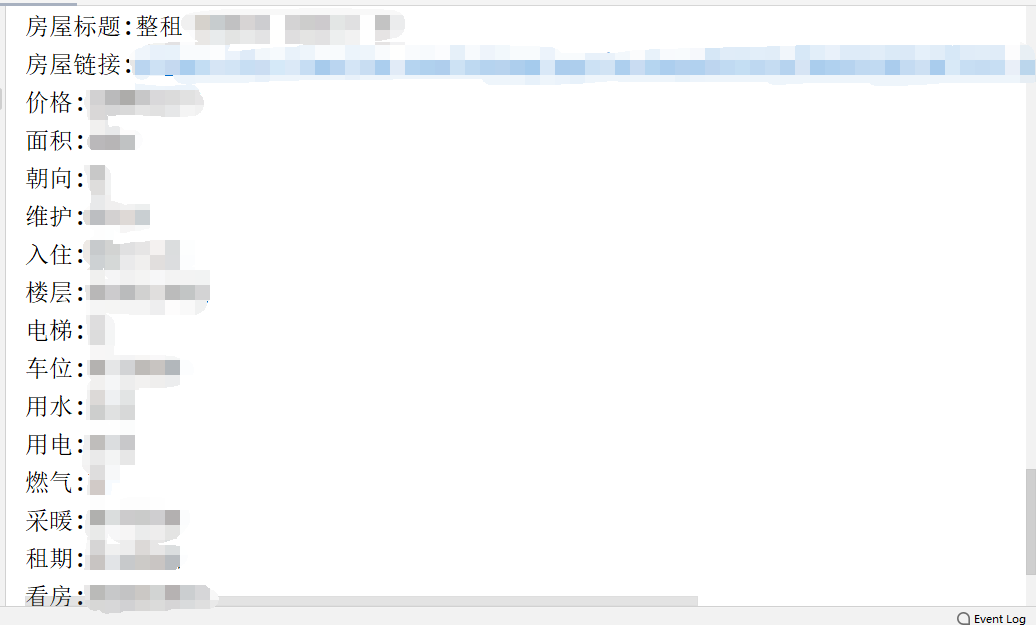
# Housing information house_info = page_res.find_all('div', class_ = 'content__article__info') house_title = page_res.find('p', class_ = 'content__title')# Listing title # essential information base_info = page_res.find_all('li', class_ = 'fl oneline') # Store as list area = base_info[1].text[3:] # the measure of area direction = base_info[2].text[3:] weihu = base_info[4].text[3:] ruzhu = base_info[5].text[3:] floor = base_info[7].text[3:] dianti = base_info[8].text[3:] chewei = base_info[10].text[3:] water = base_info[11].text[3:] # water elec = base_info[13].text[3:] # Electricity consumption ranqi = base_info[14].text[3:] # Gas cainuan = base_info[16].text[3:] # heating zuqi = base_info[18].text[3:] # lease term kanfang = base_info[21].text[3:] # House watching
6. Use dictionary for storage, convenient for management
global info info = { "House title":house_title.text, "House links":i, "Price":money.find('span').text+danwei.text[5:8], "the measure of area":area, "orientation":direction, "maintain":weihu, "Check in":ruzhu, "floor":floor, "Elevator.":dianti, "parking lot":chewei, "water":water, "Electricity consumption":elec, "Gas":ranqi, "heating":cainuan, "lease term":zuqi, "House watching":kanfang }
Finally, you can traverse as needed, and put some results as follows: