There are many ways to connect hive and impala in python, including pyhive,impyla,pyspark,ibis, etc. in this article, we will introduce how to use these packages to connect hive or impala, and how to pass kerberos authentication.
Kerberos
If the cluster does not enable kerberos authentication, the code here is not needed, or the code here is not needed to pass the kinit command authentication in the system environment.
krbcontext.context_shell
# -*- coding: utf-8 -*-
__all__ = [ 'krbcontext', 'KRB5KinitError', ]
import os, sys
# import pwd
import subprocess
from contextlib import contextmanager
class KRB5KinitError(Exception):
pass
# def get_login():
# ''' Get current effective user name '''
#
# return pwd.getpwuid(os.getuid()).pw_name
def init_ccache_as_regular_user(principal=None, ccache_file=None):
'''Initialize credential cache as a regular user
Return the filename of newly initialized credential cache
'''
if not sys.stdin.isatty():
raise IOError('This is not running on console. So, you need to run kinit '
'with your principal manually before anything goes.')
cmd = 'kinit %(ccache_file)s %(principal)s'
args = {}
args['principal'] = principal
args['ccache_file'] = '-c %s' % ccache_file
kinit_proc = subprocess.Popen(
(cmd % args).split(),
stderr=subprocess.PIPE)
stdout_data, stderr_data = kinit_proc.communicate()
if kinit_proc.returncode > 0:
raise KRB5KinitError(stderr_data)
return ccache_file
def init_ccache_with_keytab(principal, keytab_file, ccache_file):
'''Initialize credential cache using keytab file
Return the filename of newly initialized credential cache
'''
cmd = 'kinit -kt %(keytab_file)s -c %(ccache_file)s %(principal)s'
args = {}
args['principal'] = principal
args['ccache_file'] = ccache_file
args['keytab_file'] = keytab_file
kinit_proc = subprocess.Popen(
(cmd % args).split(),
stderr=subprocess.PIPE)
stdout_data, stderr_data = kinit_proc.communicate()
if kinit_proc.returncode > 0:
raise KRB5KinitError(stderr_data)
return ccache_file
@contextmanager
def krbcontext(using_keytab=False, **kwargs):
'''A context manager for Kerberos-related actions
using_keytab: specify to use Keytab file in Kerberos context if True,
or be as a regular user.
kwargs: contains the necessary arguments used in kerberos context.
It can contain principal, keytab_file, ccache_file.
When you want to use Keytab file, keytab_file must be included.
'''
env_name = 'KRB5CCNAME'
old_ccache = os.getenv(env_name)
if using_keytab:
ccache_file = init_ccache_with_keytab(**kwargs)
else:
ccache_file = init_ccache_as_regular_user(kwargs.get("principal"), kwargs.get("ccache_file"))
os.environ[env_name] = ccache_file
yield
pyhive
Connect hive with pyhive
Environmental Science
""" decorator==4.4.2 future==0.18.2 gssapi==1.6.5 krbcontext==0.10 PyHive==0.5.0 impyla==0.14.1 sasl==0.2.1 six==1.11.0 thrift_sasl==0.3.0 # If using ibis or impyla requires thrift_sasl==0.2.1 thrift==0.13.0 thriftpy==0.3.5 """ from pyhive import sqlalchemy_hive,hive from krbcontext.context_shell import krbcontext
Kerberos authentication
There are two ways. One is to let the current user pass the kinit to maintain the kerberos authentication in the system environment. Then there is no need to write the kerberos authentication code in all the codes. Another way is to use the following code to enter the kerberos authentication session in the python script:
config = {
"kerberos_principal": "hive@CSDNTEST.COM.LOCAL",
"keytab_file": '/home/tools/wyk/keytab/hive.keytab',
"kerberos_ccache_file": '/home/tools/wyk/keytab/hive_ccache_uid',
"AUTH_MECHANISM": "GSSAPI"
}
with krbcontext(using_keytab=True,
principal=config['kerberos_principal'],
keytab_file=config['keytab_file'],
ccache_file=config['kerberos_ccache_file']):
#The scripts executed in this code block are all in kerberos authentication.
#You can query hdfs hive hbase and so on in this code block as long as it is a component with permission of kerberos principaluse
The following code needs to be in the above kerberos code block to pass kerberos authentication. If the cluster has not started kerberos authentication or the current system has used kinit for authentication, the above code is not required:
con = hive.connect(host='uatnd02.csdntest.com.local',port=10000,auth='KERBEROS',kerberos_service_name="hive") #host is the node of hiveserver2, port is 10000 by default, and it is the port of hs2
cursor = con.cursor()
cursor.execute('select * from dl_nccp.account limit 5') #No semicolons!
# cursor.execute('desc dl_nccp.account') #No semicolons!
datas = cursor.fetchall()
print(datas)
cursor.close()
con.close()
impyla
Environmental Science
""" decorator==4.4.2 future==0.18.2 gssapi==1.6.5 krbcontext==0.10 PyHive==0.5.0 impyla==0.14.1 sasl==0.2.1 six==1.11.0 thrift_sasl==0.2.1 # Only this one is different from pyhive's thrift==0.13.0 thriftpy==0.3.5 """ from impala.dbapi import connect from krbcontext.context_shell import krbcontext
Kerberos authentication
Like pyhive above, slightly
use
#Impyla thrift = = 0.2.1 is the same as the dependent version of ibis, which can be used at the same time
conn = connect(host='uatnd02.csdntest.com.local', port=10000, auth_mechanism='GSSAPI',kerberos_service_name='hive')
cur = conn.cursor()
cur.execute('SHOW databases') #No semicolons
cur.table_exists(table_name='account',database_name='dl_nccp') #return True or False
cur.ping() #return True or False
cur.status() #return True or False
cur.get_table_schema(table_name='account',database_name='dl_nccp') #The return table structure is similar to desc
print(cur.fetchall())
cur.close()
conn.close()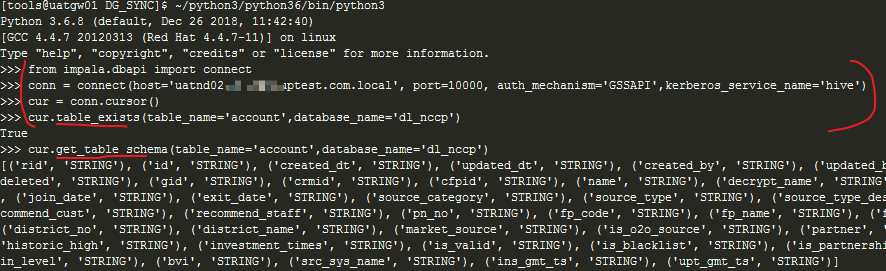
ibis
ibis is a very powerful third-party environment package, which supports access to all kinds of databases or file systems. It has powerful functions and returns to Panda data frame format, which is very friendly to data developers. I have used this package for more than two years, and it is highly recommended.
Official documents: https://docs.ibis-project.org/getting-started.html
Environmental Science
""" ibis-framework==0.14.0 #pip install ibis-framework[impala]==0.14.0 decorator==4.4.2 future==0.18.2 gssapi==1.6.5 krbcontext==0.10 PyHive==0.5.0 impyla==0.14.1 sasl==0.2.1 six==1.11.0 thrift_sasl==0.2.1 # Only this one is different from pyhive's thrift==0.13.0 thriftpy==0.3.5 """
Kerberos authentication
Like pyhive above, slightly
use
There are many functions available in the official documents and source code. Here are only some commonly used functions. It is recommended to see the source code or official documents for those who use the ibis package.
import ibis
import pandas as pd
import ibis.expr.datatypes as dt
conf={
"impala_host":"uathd01.csdntest.com.local",
"impala_port":21050,
"kerberos_service_name":"impala",
"auth_mechanism":"GSSAPI",
"webhdfs_host1":"uatnd01.csdntest.com.local",
"webhdfs_host2":"uatnd02.csdntest.com.local",
"webhdfs_port":9870 #If it is the version before Hadoop 3, the parameter here is changed to 50070
}
#Get hdfs connection
try:
hdfs_client = ibis.hdfs_connect(host = conf["webhdfs_host2"], port = conf["webhdfs_port"], auth_mechanism = conf["auth_mechanism"], use_https = False, verify = False)
hdfs_client.ls('/')
except:
hdfs_client = ibis.hdfs_connect(host = conf["webhdfs_host1"], port = conf["webhdfs_port"], auth_mechanism = conf["auth_mechanism"], use_https = False, verify = False)
#Get impala connection
impala_client = ibis.impala.connect(host=conf["impala_host"], port=conf["impala_port"], hdfs_client = hdfs_client, auth_mechanism=conf["auth_mechanism"], timeout = 300)
# select * from dh_sales.r_order limit 10, return pandas dataframe
res = impala_client.table('r_order', database='dh_sales').execute(limit=10)
print(type(res))
print(res.dtypes)
print(res)
#Query impala with SQL
res = impala_client.sql("""select area,is_oversea,dw_ins_ts,sum(gid_cnt) from dh_t3_report_crm.r_duration_area_metr where is_oversea=0 group by 1,2,3 limit 5""")
df_res = res.execute()
print(df_res)
#All tables under the column Library
impala_client.list_tables(database='dl_common')
#Using pandas dataframe to create tables and automatically map types
impala_client.create_table(table_name='ibis_create0602',obj=sys_dict,database='default',force=True)
...
#pd_res_acc omitted
#pd_res_cre slightly
...
#Insert data using pandas datraframe
impala_client.insert(table_name='tmp_account',obj=pd_res_acc,database='default',overwrite=True)
impala_client.insert(table_name='ibis_create',obj=pd_res_cre,database='default',overwrite=True)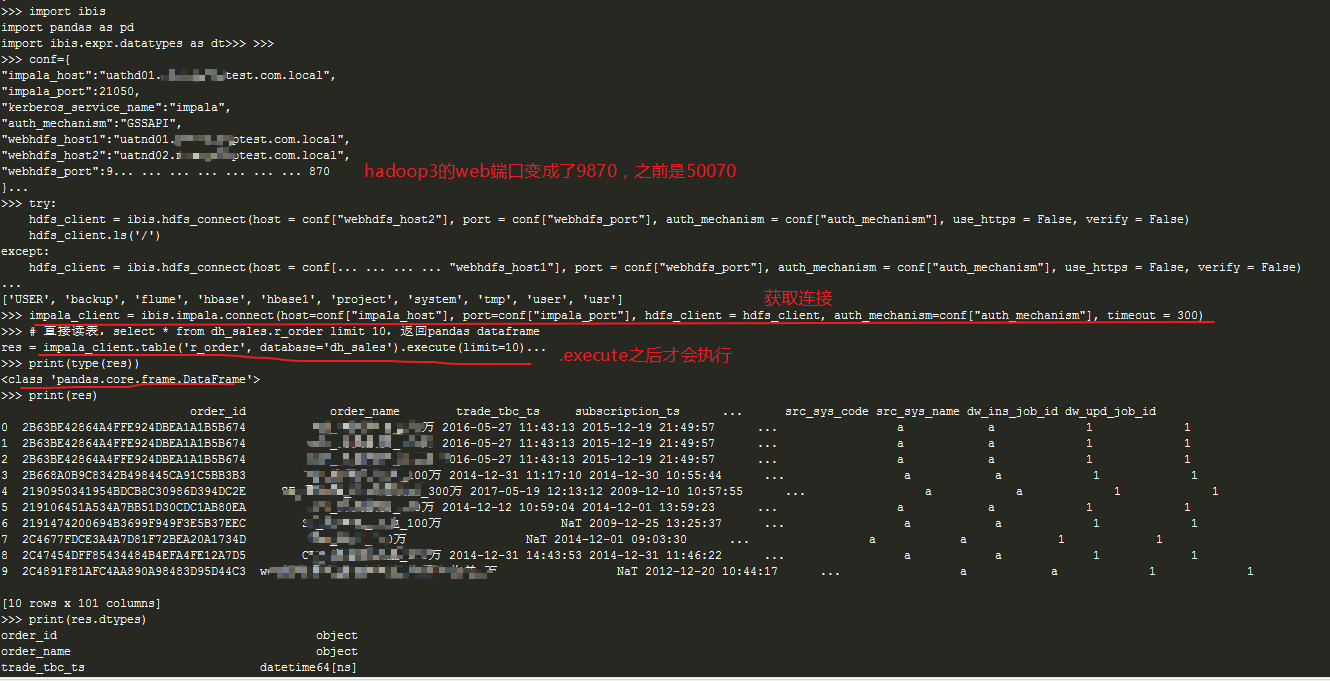


BUG resolution
The following error may be reported when executing the insert or create command. This is a source level BUG. Please refer to the following link to modify the source code to solve this problem:
UnicodeEncodeError: 'latin-1' codec can't encode characters in position 160-161: ordinal not in range(256)
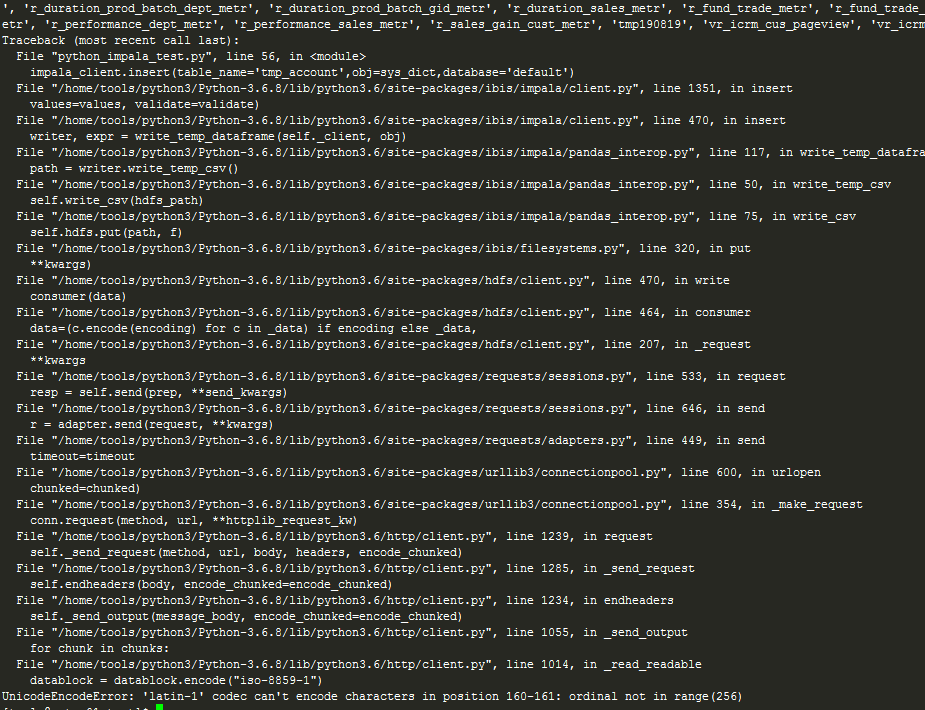
reference resources: https://github.com/ibis-project/ibis/issues/2120
vim /home/tools/python3/Python-3.6.8/lib/python3.6/site-packages/hdfs/client.py

pyspark
Environmental Science
vim /etc/profile
export SPARK_HOME=/opt/cloudera/parcels/CDH/lib/spark export SPARK_CONF_DIR=$SPARK_HOME/conf export PYTHONPATH=/home/tools/anaconda3/envs/csdn/bin export PYSPARK_PYTHON=/home/tools/anaconda3/envs/csdn/bin/python3.6
""" pyspark==2.4.5 """
kerberos authentication
Like pyhive above, slightly
use
Use pyspark to connect hive for query, and change spark dataframe to Panda dataframe:
from __future__ import division
#import findspark as fs
#fs.init()
import pandas as pd
from pyspark.sql import HiveContext,SparkSession,SQLContext
from pyspark import SparkContext, SparkConf
import pyspark.sql.functions as F
import datetime as dt
from datetime import datetime
import random
import numpy as np
from log3 import log_to_file, log
from pyspark.sql.types import *
conf = SparkConf().setMaster("yarn").setAppName("MF_return_calc")
sc = SparkContext(conf=conf)
sc.setLogLevel("WARN")
hiveCtx = HiveContext(sc)
spark = SparkSession.builder.master("yarn").appName("MF_return_calc").config("spark.debug.maxToStringFields", "100").getOrCreate()
#Execute SQL
test_sql = """select * from dl_nccp.account limit 5"""
res = hiveCtx.sql(test_sql)
type(res) #Return spark dataframe
res.head(3)
res_pd = res.toPandas() #Convert spark dataframe to Panda dataframe
res_pd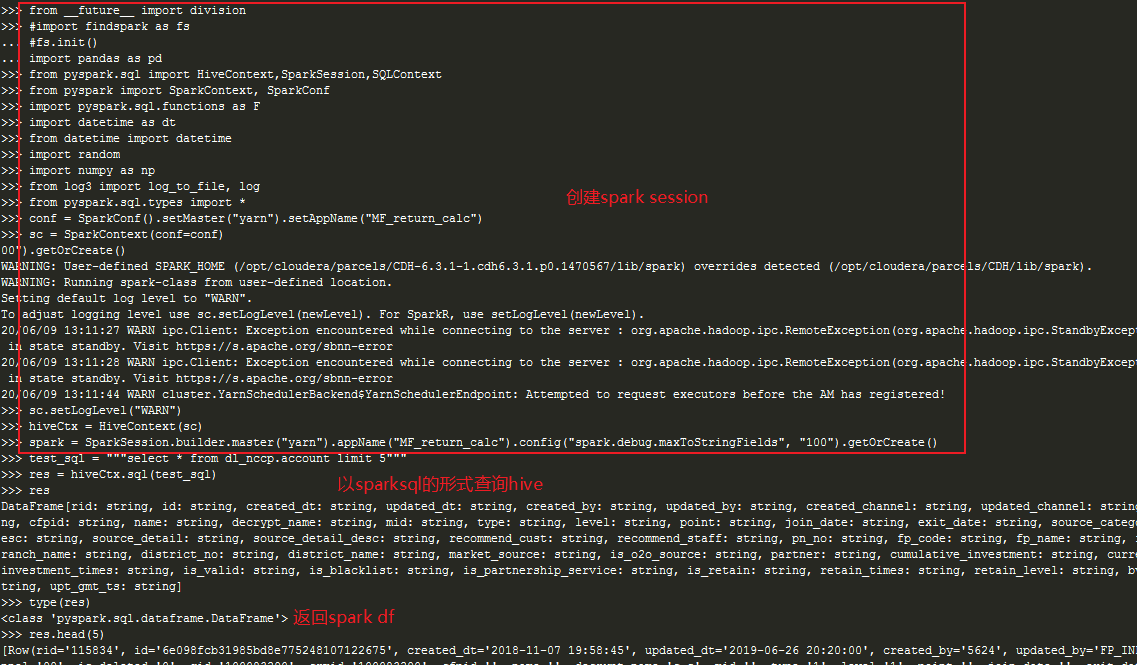
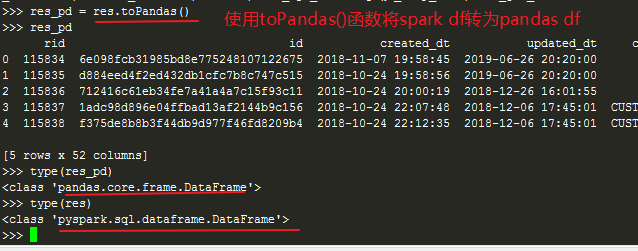
OK, the above four ways to visit hive and impala in python are introduced. I hope they can help you. Thank you!
I hope this article can help you, please give me a compliment and encourage the author ~ thank you!