
Preface
The text and pictures in this article are from the Internet. They are for study and communication only. They do not have any commercial use. The copyright is owned by the original author. If you have any questions, please contact us in time for processing.

Now there are many kinds of courses in APP for all kinds of learning, and those who are dazzled do not know which one to learn, so this crawler was born.
This article mainly writes python crawlers, crawls which classes of courses are most popular in your interest, helps you solve selection difficulties, and improves yourself by typing a few more lines of code in practice.
Before the text begins, let's take a look at the final report:

The following is a detailed crawl process:
Step 1:
fiddler package, analysis of different classifications of id, get the human classification id=3613, historical classification id=531, education classification id=537, financial classification id=533, for later convenience, we will first store each classification in the list as a dictionary.
category_list = [{"id": 3613, "name": "humanity"}, {"id": 531, "name": "History"}, {"id": 537, "name": "education"}, {"id": 533, "name": "Finance"}]
Step 2:
Analyse the interface addresses of the rankings by fiddler package:
list_url = "https://c.qingting.fm/rankinglist/v1/items?type=hot&category=%s&range=total&page=%s"
The following is the data returned by the interface, which returns 30 pieces of data per page, totaling 100 pieces of data.
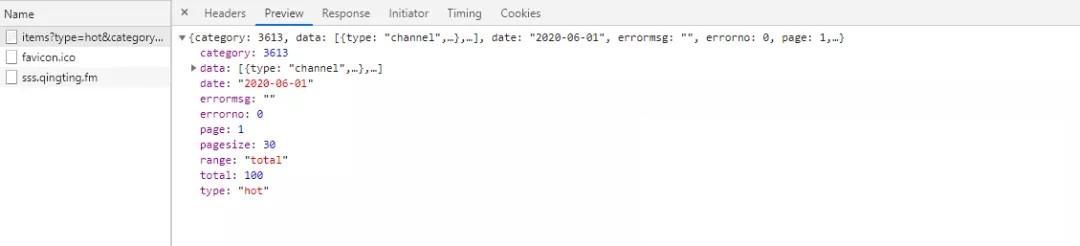
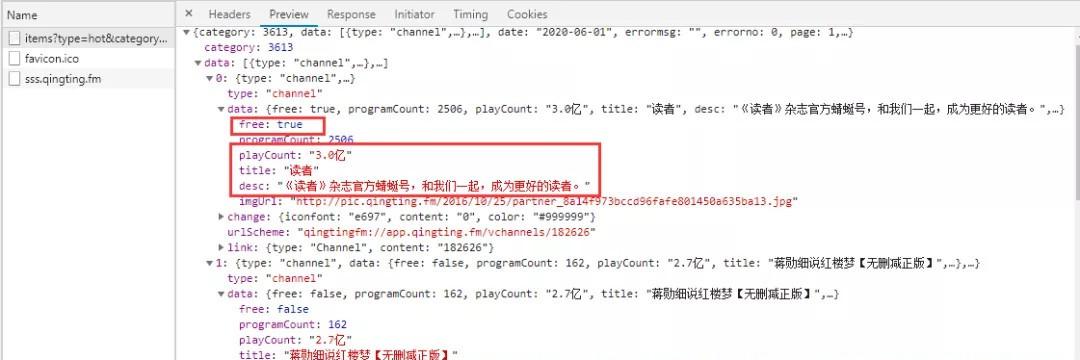
Step 3:
Write scripts (traverse different classifications, page request interface data, parse interface data, write to Excel documents)
def get_rank_list(list): list_url = "https://c.qingting.fm/rankinglist/v1/items?type=hot&category=%s&range=total&page=%s" result_list = [] for item in list: r_id = item['id'] category_name = item['name'] try: for p in range(1,4): list_res = urllib.request.urlopen(list_url%(r_id,p)).read().decode() list_res = json.loads(list_res) for dict in list_res['data']: # Because each page requests an interface once, we store each request's interface data in a dictionary in the list. result_dict = {} result_dict['Course Name'] = dict['data']['title'] result_dict['Course Description'] = dict['data']['desc'] result_dict['Play Count'] = dict['data']['playCount'] result_dict['Number of Chapters'] = dict['data']['programCount'] result_dict['Category name'] = category_name result_list.append(result_dict) except Exception as e: print(e) continue //Write functions to write Excel documents. (This uses the panda library, which is great for working with documents.) def write2csv(list): df = pd.DataFrame(list) df.index = np.arange(1, len(list)+1) df.to_csv("qingting.csv",mode='a',encoding="utf_8_sig")
Full code:
#!/bin/python # coding:utf-8 import time import urllib.request import json import pandas as pd import random import numpy as np category_list = [{"id": 3613, "name": "humanity"}, {"id": 531, "name": "History"}, {"id": 537, "name": "education"}, {"id": 533, "name": "Finance"}] def get_rank_list(list): list_url = "https://c.qingting.fm/rankinglist/v1/items?type=hot&category=%s&range=total&page=%s" result_list = [] for item in list: r_id = item['id'] category_name = item['name'] try: for p in range(1,4): list_res = urllib.request.urlopen(list_url%(r_id,p)).read().decode() list_res = json.loads(list_res) for dict in list_res['data']: # Because each page requests an interface once, we store each request's interface data in a dictionary in the list. result_dict = {} result_dict['Course Name'] = dict['data']['title'] result_dict['Course Description'] = dict['data']['desc'] result_dict['Play Count'] = dict['data']['playCount'] result_dict['Number of Chapters'] = dict['data']['programCount'] result_dict['Category name'] = category_name result_list.append(result_dict) except Exception as e: print(e) continue write2csv(result_list) def write2csv(list): df = pd.DataFrame(list) df.index = np.arange(1, len(list)+1) df.to_csv("qingting.csv",mode='a',encoding="utf_8_sig") get_rank_list(category_list)