One: Background
1. Storytelling
Recently, looking at the major technical communities, whether they know, the Nuggets, the Blog Garden or csdn, we can hardly see any articles about sqlserver class shared by small partners. It looks like sqlserver has disappeared in recent years and no one has written it since. It is impossible to write sqlserver again. It will never be written in this life. We can only maintain our life by exporting mysql through technology.
2. Understanding the architecture diagram
The best thing about mysql is open source, millions of sources in your hand. What's wrong?This is much cooler than sqlserver, so you don't have to tamper with dbcc anymore.
1. Start with the architecture diagram
Everyone knows that a drawing is needed to make/decorate a house. In fact, the software is the same. As long as there is such a drawing, the big direction will be fixed. If you go deeper into the details, you will not lose your direction. Then you can see the architecture drawing I have drawn. Please tap the wrong one.
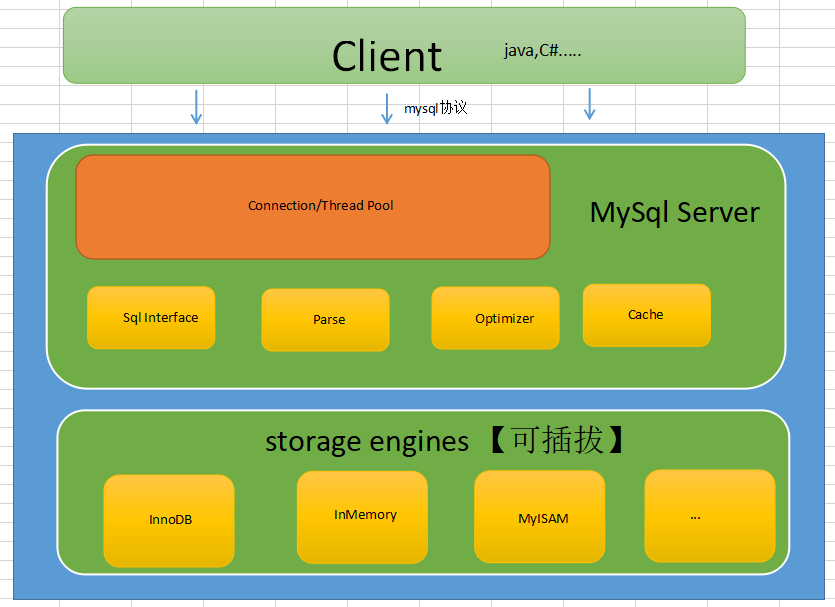
In fact, the SqlServer, Oracle, MySql architectures are very similar. The distinct feature of MySql is that the storage engine is made into plug-and-drop, which is amazing. Currently InnoDB is the most commonly used, which gives me the idea that a business is ready to run in InMemory mode, which is awesome ~~
2. Introduction of Functional Points
MySql is actually two big blocks, one is the MySql Server layer and the other is the Storage Engines layer.
<1> Client
SDKs in different languages can communicate with mysqld by following the mysql protocol.
<2> Connection/Thread Pool
MySql is written in C++, and Connection s are invaluable for maintaining a pool during initialization.
<3> SqlInterface,Parse,Optimizer,Cache
Understanding sql processing, parsing, optimization, caching and other processing and filtering modules is enough.
<4> Storage Engines
The modules responsible for storage, official, third-party, or even you can customize this data store, which makes the ecology work..
3: Source Code Analysis
As for how to download mysql source code, let's not mention it here. You go to the official website and make your own play. This series uses the classic version of mysql 5.7.14.
1. Learn how mysql starts listening
With millions of lines of source in your hand, how do you find the entry function???_In fact, it is very simple to generate a dump file on the mysqld process and look at its managed heap.

As you can see from the diagram, the entry function is mysqld! Mysqld_Mysqld_in main+0x227Main, you can then retrieve the full text from the source code.
<1> mysqld_Main entry function=> sql/Main.cc
extern int mysqld_main(int argc, char **argv); int main(int argc, char **argv) { return mysqld_main(argc, argv); }
Here you can open the C++ source code with visual studio, and use the view definition function, which is very useful.
<2>Create Listening
int mysqld_main(int argc, char **argv) { //Create a service listener thread handle_connections_sockets(); } void handle_connections_sockets() { //Listening Connections new_sock= mysql_socket_accept(key_socket_client_connection, sock, (struct sockaddr *)(&cAddr), &length); if (mysql_socket_getfd(sock) == mysql_socket_getfd(unix_sock)) thd->security_ctx->set_host((char*) my_localhost); //Create Connection create_new_thread(thd); } //Create a new thread to process user connections static void create_new_thread(THD *thd){ thd->thread_id= thd->variables.pseudo_thread_id= thread_id++; //Thread entered thread scheduler MYSQL_CALLBACK(thread_scheduler, add_connection, (thd)); }
mysql has now opened a thread to monitor port 3306, waiting for client requests to trigger add_connection callback.
2. Understand how mysql handles sql requests
Here I take Insert operation as an example and dissect the process slightly:
Thread_triggers when the user requests sql to comeScheduler's callback function add_connection.
static scheduler_functions one_thread_per_connection_scheduler_functions= { 0, // max_threads NULL, // init init_new_connection_handler_thread, // init_new_connection_thread create_thread_to_handle_connection, // add_connection NULL, // thd_wait_begin NULL, // thd_wait_end NULL, // post_kill_notification one_thread_per_connection_end, // end_thread NULL, // end };
From scheduler_As you can see in functions, add_connection corresponds to create_thread_to_handle_connection, which triggers this function when a request comes in, uses a thread to process a user connection, as you can see from the name.
<1>Client request created_Thread_To_Handle_Connection take-over and call stack tracing
void create_thread_to_handle_connection(THD *thd) { if ((error= mysql_thread_create(key_thread_one_connection, &thd->real_id, &connection_attrib, handle_one_connection,(void*) thd))){} } //Trigger callback function handle_one_connection pthread_handler_t handle_one_connection(void *arg) { do_handle_one_connection(thd); } //Continue processing void do_handle_one_connection(THD *thd_arg){ while (thd_is_connection_alive(thd)) { mysql_audit_release(thd); if (do_command(thd)) break; //Do_hereCommand continues processing } } //Continue Distribution bool do_command(THD *thd) { return_value= dispatch_command(command, thd, packet+1, (uint) (packet_length-1)); } bool dispatch_command(enum enum_server_command command, THD *thd, char* packet, uint packet_length) { switch (command) { case COM_INIT_DB: .... break; ... case COM_QUERY: //Query statement: insert xxxx mysql_parse(thd, thd->query(), thd->query_length(), &parser_state); //sql parsing break; } } //sql parsing module void mysql_parse(THD *thd, char *rawbuf, uint length, Parser_state *parser_state) { error= mysql_execute_command(thd); }
<2>Here its Parse, Optimizer and Cache are all finished. Next, look at the CRID type of sql and continue the chase.
//Continue execution int mysql_execute_command(THD *thd) { switch (lex->sql_command) { case SQLCOM_SELECT: res= execute_sqlcom_select(thd, all_tables); break; //This insert is what I want to chase case SQLCOM_INSERT: res= mysql_insert(thd, all_tables, lex->field_list, lex->many_values, lex->update_list, lex->value_list, lex->duplicates, lex->ignore); } } //Insert insert operation processing bool mysql_insert(THD *thd,TABLE_LIST *table_list,List<Item> &fields, List<List_item> &values_list, List<Item> &update_fields, List<Item> &update_values, enum_duplicates duplic, bool ignore) { while ((values= its++)) { error= write_record(thd, table, &info, &update); } } //Write Record int write_record(THD *thd, TABLE *table, COPY_INFO *info, COPY_INFO *update) { if (duplicate_handling == DUP_REPLACE || duplicate_handling == DUP_UPDATE) { // ha_write_row focuses on this function while ((error=table->file->ha_write_row(table->record[0]))) { .... } } }
As you can see, the call chain is still deep, chasing ha_Write_The row method is basically a catch-up, and the next step is the implementation of the interface MySql Server provides to Storage Engine. If you don't believe it, keep looking.
<3>Continue digging ha_write_row
int handler::ha_write_row(uchar *buf) { MYSQL_TABLE_IO_WAIT(m_psi, PSI_TABLE_WRITE_ROW, MAX_KEY, 0,{ error= write_row(buf); }) } //This is a virtual method virtual int write_row(uchar *buf __attribute__((unused))) { return HA_ERR_WRONG_COMMAND; }
See no, write_row is a virtual method, i.e. implemented for the underlying method, which is here for the major Storage Engines._
3. Call Chain Diagram
So many methods, it seems a little confused, let me draw a picture to help you understand this call stack.
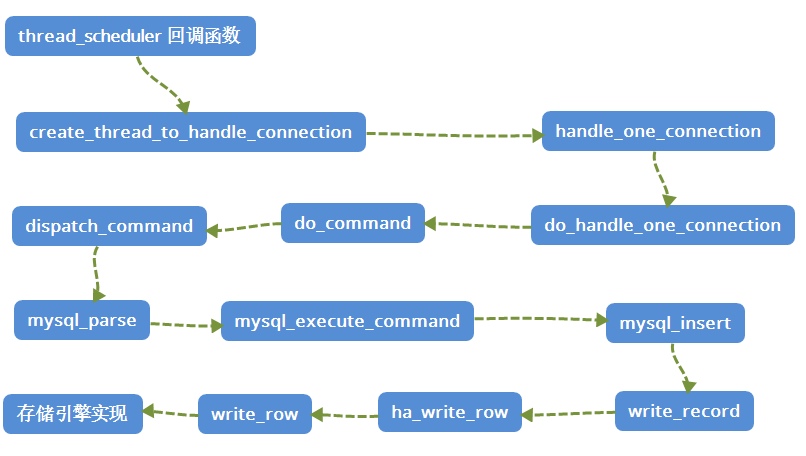
Three: Summary
You must be familiar with the schema diagram. It is much easier to find information from the source code with the schema diagram. In a word, learning mysql is full of accomplishment..