preface
Most of the good videos are short videos! The same interface returns different videos to users
Today, I will take you down the video recommended by the system!
Knowledge points
1. Dynamic data capture demonstration
2. json data analysis method
3. Video data saving
Environment introduction
python 3.6
pycharm
requests
json
General thinking of reptiles
1. Analyze the target web page to determine the url path and headers parameters to be crawled
2. Send request -- requests simulate browser to send request and get response data
3. Parse data
4. Save data - save in destination folder
step
1. Import tool
import requests import time import pprint
2. Determine the url path to crawl, and the headers parameter
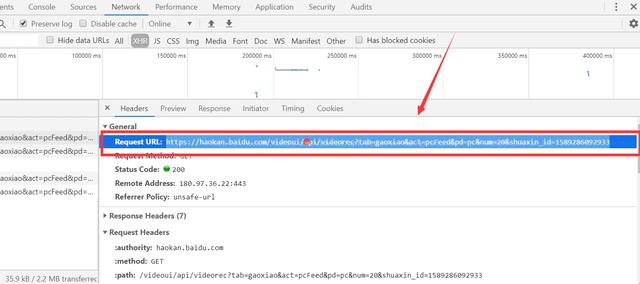
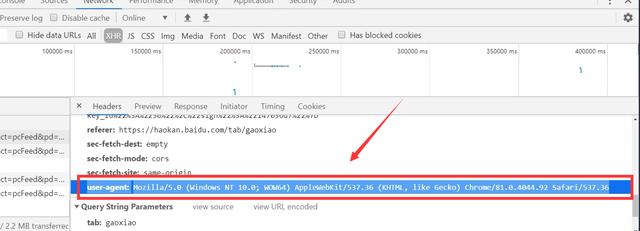
# Get timestamp """ //The time stamp refers to the total number of milliseconds from 00:00:00, January 1, 1970, GMT (08:00:00, January 1, 1970, Beijing time). //Second timestamps, 10 bits //Millisecond timestamps, 13 bits //Microsecond timestamps, 16 bit """ time_one = str(int(time.time() * 1000)) # print(time_one) base_url = 'https://haokan.baidu.com/videoui/api/videorec?tab=gaoxiao&act=pcFeed&pd=pc&num=20&shuaxin_id=' + time_one headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36', 'cookie': 'BIDUPSID=ABD6DB65092EB1ECFA3DB139E3DCDE8D; PSTM=1575868363; BAIDUID=ABD6DB65092EB1ECE63825000D8C97DB:FG=1; BDUSS=U1c0hpalFvb2ZLclIwY0tHSnA2T0ZLbjV3NDcyQmhkQ2FsV2VPbmptS1U1QzllRVFBQUFBJCQAAAAAAAAAAAEAAAD9hL2nuti-~M~oMzEzNjQxOQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAJRXCF6UVwheZn; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; PC_TAB_LOG=haokan_website_page; Hm_lvt_4aadd610dfd2f5972f1efee2653a2bc5=1578978739,1578979115; BAIDU_SSP_lcr=https://www.hao123.com/link/https/?key=http%3A%2F%2Fv.baidu.com%2F&&monkey=m-coolsites-row0&c=B22D86A598C084B684993C4C1472E65C; BDRCVFR[PaHiFN6tims]=9xWipS8B-FspA7EnHc1QhPEUf; delPer=0; PSINO=6; H_PS_PSSID=; Hm_lpvt_4aadd610dfd2f5972f1efee2653a2bc5=1578982791; reptileData=%7B%22data%22%3A%22ff38fdbd98456480e9c9c7834cbfeaa39236e14520ac985b719893846080819083f656303845fdcba03de7a67af409104bd1b7bccbc028b467f251922334608c1b34b919ef391c146a5ad41b8099df302ec0d32f3a55b4271300112ff8e8f12a1cde132ecaf78f8df8d9c97ddd9abefa4d7a4d8bdd641c156c016dba346150a8%22%2C%22key_id%22%3A%2230%22%2C%22sign%22%3A%226430f36d%22%7D' }
3. Send request -- requests simulate browser to send request and get response data
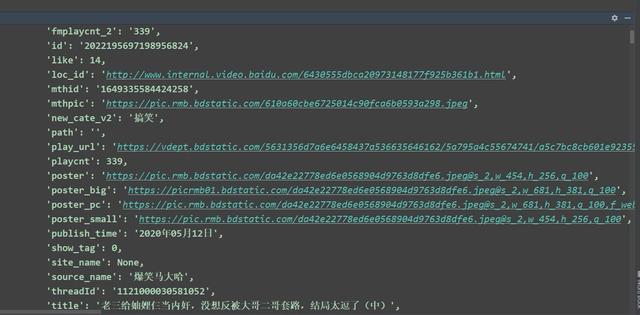
response = requests.get(base_url, headers=headers) data = response.json() # pprint.pprint(data)
4. Parse data

data_list = data['data']['response']['videos'] # --list # print(data_list) # Traversal list for data in data_list: video_name = data['title'] + '.rmvb' # Video file name video_url = data['play_url'] # Video url address # print(video_name, video_url) # print(type(video_name)) # Send request again print('Downloading:', video_name) video_data = requests.get(video_url, headers=headers).content
5. Save data - save in destination folder
with open('video\\' + video_name, 'wb') as f: f.write(video_data) print('Download complete...\n')
Run the code, the effect is as follows
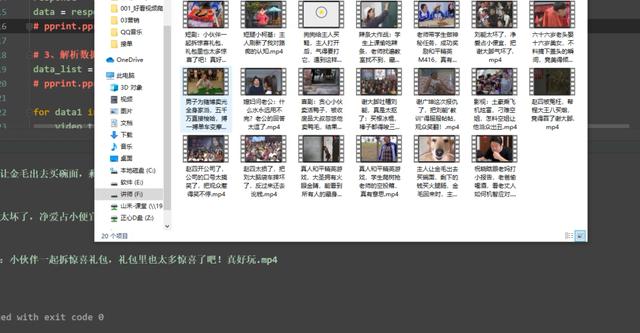
OK, so the video can be downloaded slowly
Welcome to the top right corner to pay attention to the editor. In addition to sharing technical articles, there are many benefits. Private learning materials can be obtained, including but not limited to Python practice, PDF electronic documents, interview brochures, learning materials, etc.
No matter you are zero foundation or have foundation, you can get the corresponding study gift pack! It includes Python software tools and the latest introduction to practice in 2020. Add 695185429 for free.