Volkswagen Reviews Data Crawler Access Tutorial - [SVG Mapped Version]
Preface:
Popular Reviews is a popular third-party food-related review website.From the website, you can recommend preferential information for eating, drinking and playing, and provide a variety of life services such as food restaurants, Hotel travel, movie tickets, home decoration, beauty and hairdressing, sports and fitness. Through the aggregation of a large number of real consumption reviews, you can help everyone select businesses with satisfactory service.
Therefore, the site's data is also very valuable.Preferential offers, number of evaluations, positive reviews and other data are also very popular with data companies.
As mentioned above, this is a SVG mapping version
I hope it will be helpful to your friends who read this article.
- Environment and Toolkit:
- python 3.6
- Self-built IP pool (proxy) (using ipidea's domestic proxy)
- parsel (page parsing)
Let me see how to start exploring
This time we're going to " http://www.dianping.com/shop/16790071/review_all"as an example.
Now that the reader can see this, he must have known it.
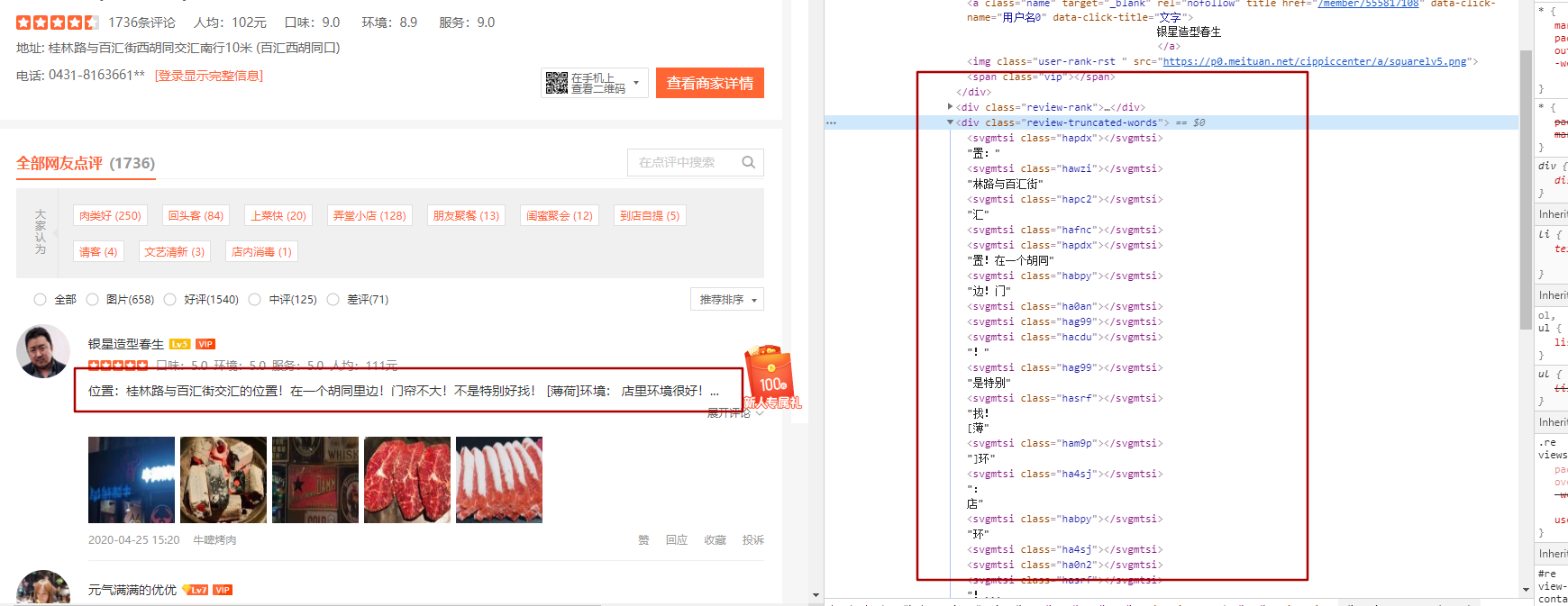
From the red box contrast in the picture, you can see the contrast between the left and right contents.Visible results are not what you see but what you return from the page.
The class of the <svgmtsi>tag content is actually the setting in the corresponding class file. From the following figure, we can see that the corresponding css instances have a link, which is a link to the corresponding svg mapping
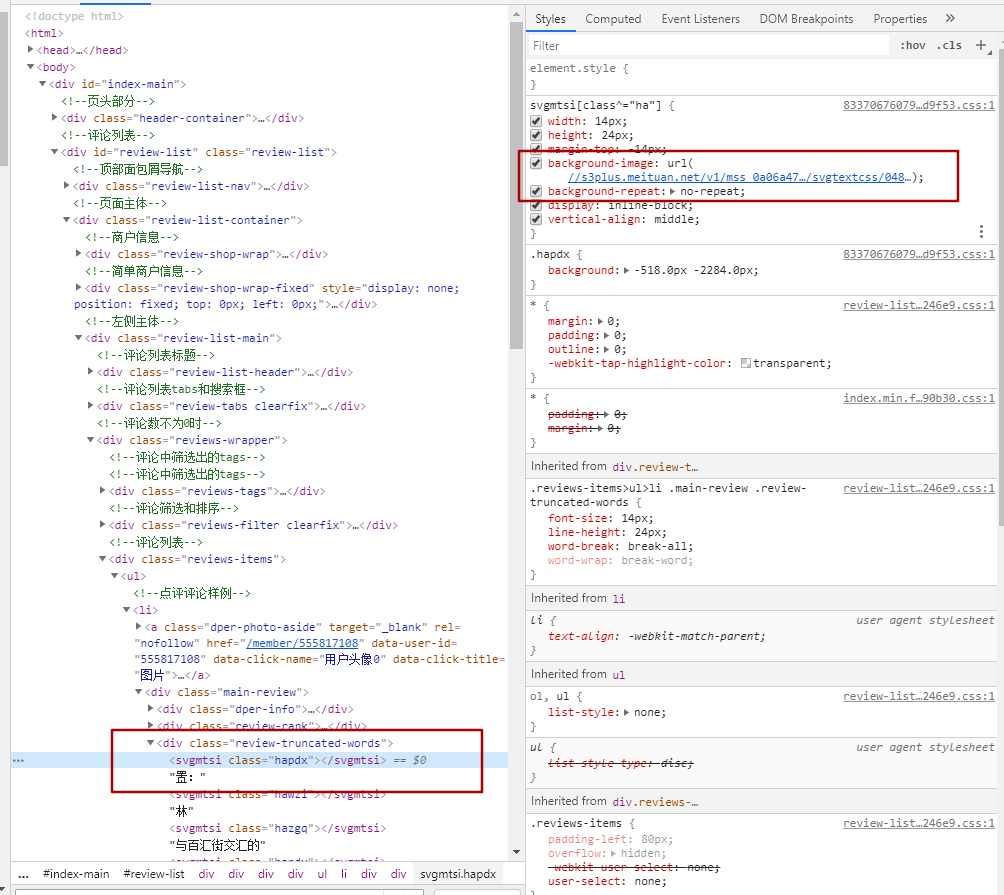

This is the link: https://s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/048cf3c5718ff9fca0a56e2d9cf019fe.svg"
Open this link to see the following:

Notice the contrast above, below the flood width on the right.hapdx property, which corresponds to a background image that knows the location of the svg text.You can modify the parameter values yourself, and the corresponding positions change.
So we just need to do three steps.
One.Find the css path of the corresponding page and load the parsed content.Handle.
Two.Replace the content of the page, and the text you need to replace is found in the css by attributes.
Three.Parse the page to get the value of the corresponding page.
The code is as follows:
import re
import requests
def svg_parser(url):
r = requests.get(url, headers=headers)
font = re.findall('" y="(\d+)">(\w+)</text>', r.text, re.M)
if not font:
font = []
z = re.findall('" textLength.*?(\w+)</textPath>', r.text, re.M)
y = re.findall('id="\d+" d="\w+\s(\d+)\s\w+"', r.text, re.M)
for a, b in zip(y, z):
font.append((a, b))
width = re.findall("font-size:(\d+)px", r.text)[0]
new_font = []
for i in font:
new_font.append((int(i[0]), i[1]))
return new_font, int(width)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36",
"Cookie": "_lxsdk_cuid=171c55eb43ac8-07f006bde8dc41-5313f6f-1fa400-171c55eb43ac8; _lxsdk=171c55eb43ac8-07f006bde8dc41-5313f6f-1fa400-171c55eb43ac8; _hc.v=970ed851-cbab-8871-10cf-06251d4e64a0.1588154251; t_lxid=17186f9fa02c8-02b79fa94db2c8-5313f6f-1fa400-17186f9fa03c8-tid; _lxsdk_s=171c55ea204-971-8a9-eae%7C%7C368"}
r = requests.get("http://www.dianping.com/shop/73408241/review_all", headers=headers)
print(r.status_code)
# print(r.text)
css_url = "http:" + re.findall('href="(//s3plus.meituan.net.*?svgtextcss.*?.css)', r.text)[0]
print(css_url)
css_cont = requests.get(css_url, headers=headers)
print(css_cont.text)
svg_url = re.findall('class\^="(\w+)".*?(//s3plus.*?\.svg)', css_cont.text)
print(svg_url)
s_parser = []
for c, u in svg_url:
f, w = svg_parser("http:" + u)
s_parser.append({"code": c, "font": f, "fw": w})
print(s_parser)
css_list = re.findall('(\w+){background:.*?(\d+).*?px.*?(\d+).*?px;', '\n'.join(css_cont.text.split('}')))
css_list = [(i[0], int(i[1]), int(i[2])) for i in css_list]
def font_parser(ft):
for i in s_parser:
if i["code"] in ft[0]:
font = sorted(i["font"])
if ft[2] < int(font[0][0]):
x = int(ft[1] / i["fw"])
return font[0][1][x]
for j in range(len(font)):
if (j + 1) in range(len(font)):
if (ft[2] >= int(font[j][0]) and ft[2] < int(font[j + 1][0])):
x = int(ft[1] / i["fw"])
return font[j + 1][1][x]
replace_dic = []
for i in css_list:
replace_dic.append({"code": i[0], "word": font_parser(i)})
rep = r.text
# print(rep)
for i in range(len(replace_dic)):
# print(replace_dic[i]["code"])
try:
if replace_dic[i]["code"] in rep:
a = re.findall(f'<\w+\sclass="{replace_dic[i]["code"]}"><\/\w+>', rep)[0]
rep = rep.replace(a, replace_dic[i]["word"])
except Exception as e:
print(e)
# print(rep)
from parsel import Selector
response = Selector(text=rep)
li_list = response.xpath('//div[@class="reviews-items"]/ul/li')
for li in li_list:
infof = li.xpath('.//div[@class="review-truncated-words"]/text()').extract()
print(infof[0].strip().replace("\n",""))The results are compared as follows:
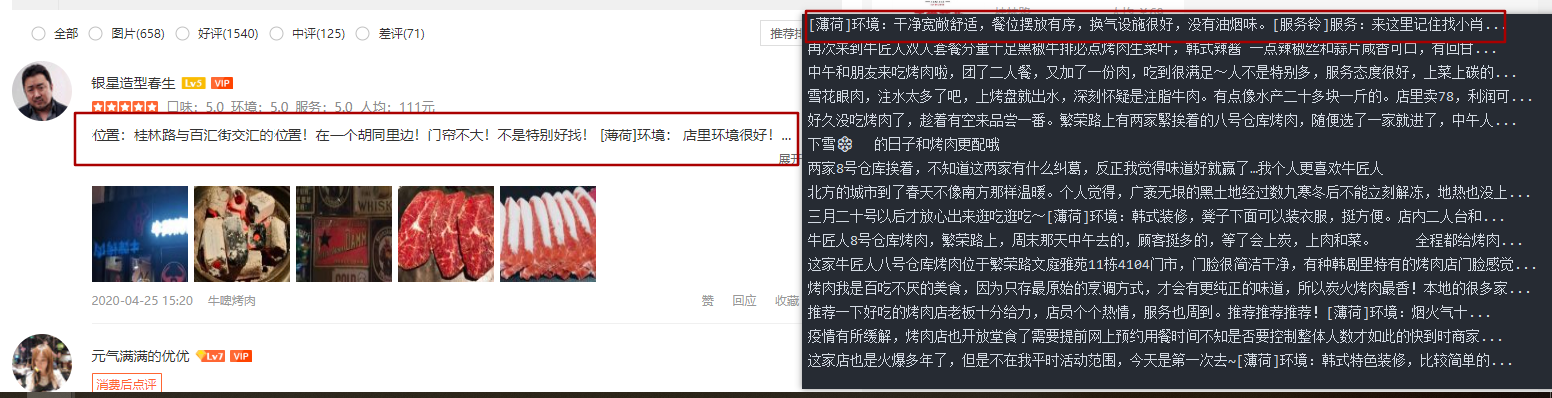
The specific process is shown in the code, and the details need to be improved, but the corresponding content can be displayed.
The two collecting tutorials of public commentary are over here. Welcome to contact me for detailed communication.
This article is intended for communication and sharing, [No reprinting without permission]