
Preface
Station B as a barrage video website, has the so-called barrage culture, so let's see next, what is the most barrage in a video?
Knowledge points:
1. Basic process of reptile
2. Regular
3. requests
4. jieba
5. csv
6. wordcloud
Development environment:
Python 3.6
Pycharm
Python section
Step:
import re
import requests
import csv
1. Determine the url path to crawl, and the headers parameter
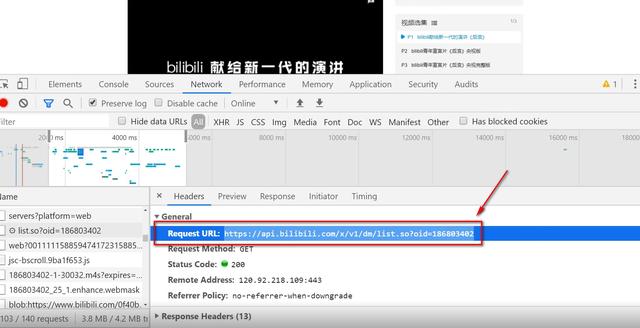

code:
url = 'https://api.bilibili.com/x/v1/dm/list.so?oid=186803402'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
2. Simulate browser to send request and get corresponding content
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
resp = requests.get(url)
#Random code
print(resp.content.decode('utf-8'))3. Analyze web page extract data
#Extract web page data as required
res = re.compile('<d.*?>(.*?)</d>')
danmu = re.findall(res,html_doc)
print(danmu)
4. Save data
for i in danmu:
with open('C:/Users/Administrator/Desktop/B Standing barrage.csv','a',newline='',encoding='utf-8-sig') as f:
writer = csv.writer(f)
danmu = []
danmu.append(i)
writer.writerow(danmu)

Display data
Import word cloud production library wordcloud and Chinese word segmentation library jieba
import jieba
import wordcloud
Import the imread function in the imageio library, and use this function to read the local image as the word cloud shape image
import imageio
mk = imageio.imread(r"fist.png")
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36",
}
response = requests.get("https://api.bilibili.com/x/v1/dm/list.so?oid=186803402", headers=headers)
# print(response.text)
html_doc = response.content.decode('utf-8')
# soup = BeautifulSoup(html_doc,'lxml')
format = re.compile("<d.*?>(.*?)</d>")
DanMu = format.findall(html_doc)
for i in DanMu:
with open('C:/Users/Mark/Desktop/b Standing barrage.csv', "a", newline='', encoding='utf-8-sig') as csvfile:
writer = csv.writer(csvfile)
danmu = []
danmu.append(i)
writer.writerow(danmu)
Construct and configure the word cloud object w, pay attention to adding the stopwords set parameter, put the words that do not want to be displayed in the word cloud in the stopwords set, and remove the words "Cao Cao" and "Kong Ming" here
w = wordcloud.WordCloud(width=1000,
height=700,
background_color='white',
font_path='msyh.ttc',
mask=mk,
scale=15,
stopwords={' '},
contour_width=5,
contour_color='red')
Chinese word segmentation is performed on the text from external files to get string
f = open('C:/Users/Mark/Desktop/b Standing barrage.csv', encoding='utf-8')
txt = f.read()
txtlist = jieba.lcut(txt)
string = " ".join(txtlist)Pass the string variable into the generate() method of w, and input text to the word cloud
w.generate(string)
Export word cloud pictures to the current folder
w.to_file('C:/Users/Mark/Desktop/output2-threekingdoms.png')The effect is as follows:

