Catalog
- Architecture introduction
- Installation creation and startup
- Profile directory introduction
- Crawling data and parsing
- Data persistence
- Action chain, verification code to control sliding
Architecture introduction
Scrapy is an open-source and collaborative framework, which was originally designed for page grabbing (more specifically, network grabbing). It can extract the required data from the website in a fast, simple and scalable way. However, at present, scrapy is widely used in data mining, monitoring, automated testing and other fields. It can also be used to obtain data returned by API s (such as Amazon Associates Web Services) or general web crawlers.

Scrapy is developed based on twisted framework, which is a popular event driven python Network Framework. So scrapy uses a non blocking (aka asynchronous) code for concurrency. The overall structure is roughly as follows
IO multiplexing
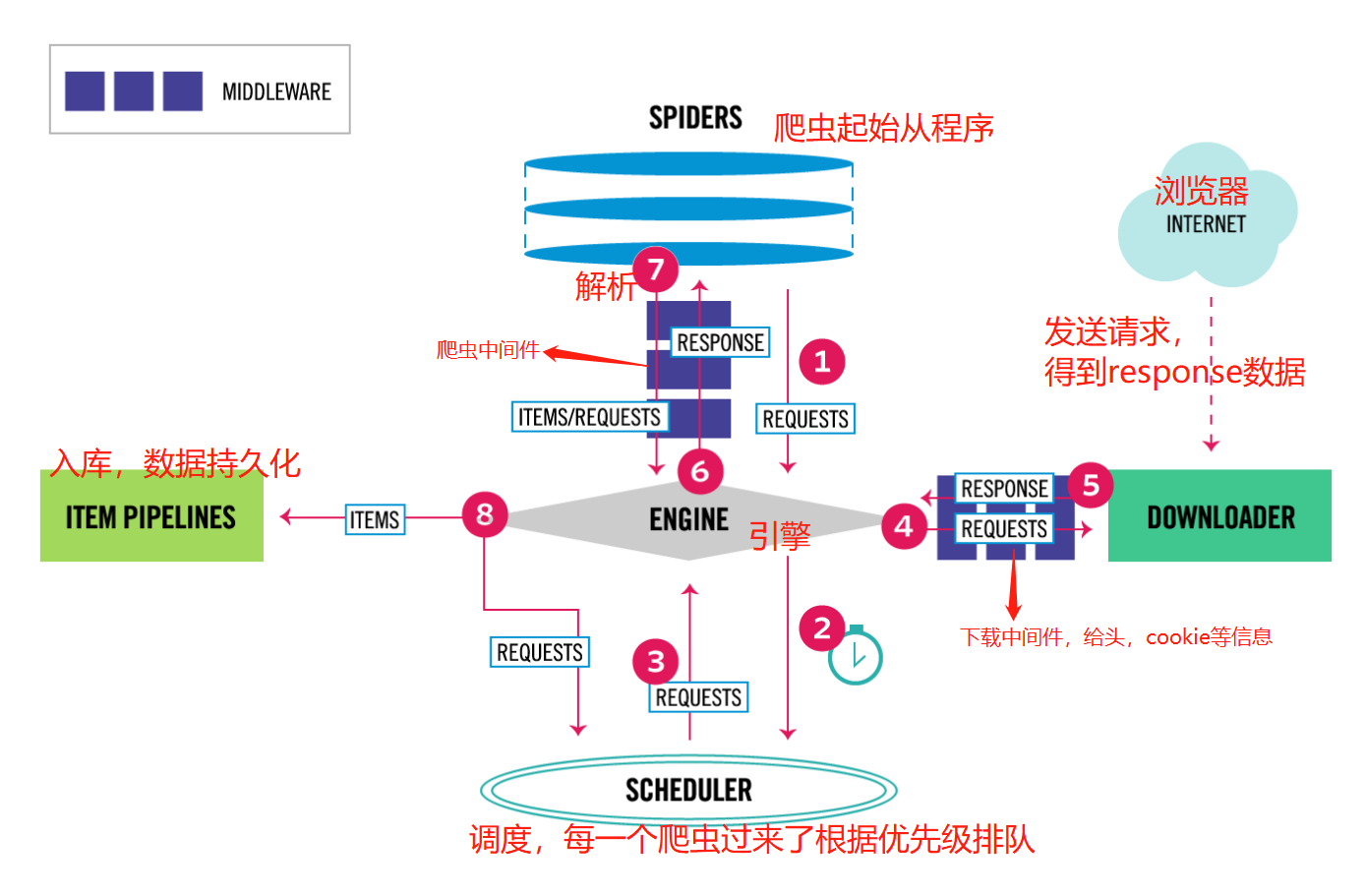
#Engine (main) The engine is responsible for controlling the flow of data between all components of the system and triggering events when certain actions occur. For more information, see the data flow section above. #Scheduler It is used to accept the request sent by the engine, press it into the queue, and return when the engine requests again. It can be imagined as a priority queue of a URL, which determines the next URL to be grabbed, and removes duplicate URLs at the same time #Downloader It is used to download web content and return it to EGINE. The Downloader is based on twisted, an efficient asynchronous model #Spiders SPIDERS is a developer-defined class used to parse responses, extract items, or send new requests #Project pipelines Be responsible for processing items after they are extracted, mainly including cleaning, validation, persistence (such as saving to database) and other operations #Two Middleware -Crawler Middleware -Download middleware (most used, add header, add proxy, add cookie, integrate selenium)
Installation creation and startup
# 1 frame is not a module
# 2. django (you will find that it is the same as django in many places)
# 3 installation
-mac,linux Platform: pip3 install scrapy
-windows Platform: pip3 install scrapy(Most people can)
- If it fails:
1,pip3 install wheel #After installation, the software can be installed through the wheel file. The official website of the wheel file is https://www.lfd.uci.edu/~gohlke/pythonlibs
3,pip3 install lxml
4,pip3 install pyopenssl
5,Download and install pywin32: https://sourceforge.net/projects/pywin32/files/pywin32/
6,download twisted Of wheel Document: http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
7,implement pip3 install Download directory\Twisted-17.9.0-cp36-cp36m-win_amd64.whl
8,pip3 install scrapy
# 4. In the script folder, there will be the executable file of the script.exe
-Establish scrapy Item: scrapy startproject Project name (django Create project)
-To create a reptile: scrapy genspider Crawler name website address to be crawled # Multiple crawlers can be created
# 5 command start crawler
-scrapy crawl Reptile name
-scrapy crawl Reptile name --nolog # No log output started
# 6 file execution crawler (recommended)
-Create a main.py,Right click to execute
from scrapy.cmdline import execute
# execute(['scrapy','crawl','chouti','--nolog']) # No log level set
execute(['scrapy','crawl','chouti']) # Log level set
Profile directory introduction
-crawl_chouti # Project name
-crawl_chouti # With project name, folder
-spiders # spiders: put the reptiles generated by the genspider, and put them all under here
-__init__.py
-chouti.py # Drawer crawler
-cnblogs.py # cnblogs crawler
-items.py # Compare the models.py file in django and write model classes one by one
-middlewares.py # Middleware (crawler middleware, Download Middleware), which is written here
-pipelines.py # Where to write persistence (persistence to file, mysql, redis, mongodb)
-settings.py # configuration file
-scrapy.cfg # Don't pay attention to it
# Configuration file settings.py
ROBOTSTXT_OBEY = False # Whether to follow the crawler protocol and run forcibly
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36' # Request the ua in the header, go to the browser to copy it, or use the ua pool to get it
LOG_LEVEL='ERROR' # In this way, the program error information will be printed,
#Start the crawler directly, and there is no log output for the crawler name
# scrapy crawl Reptile name --nolog # No need to start like this after configuration
# Crawler file
class ChoutiSpider(scrapy.Spider):
name = 'chouti' # Reptile name
allowed_domains = ['https://dig.chouti.com/'] # The domain that can be crawled. If you want to climb more, comment it out
start_urls = ['https://dig.chouti.com/'] # The starting position. Once the crawler starts, it will send a request to it first
def parse(self, response): # Parse, request back, execute the parser automatically, and parse in this method
print('---------------------------',response)
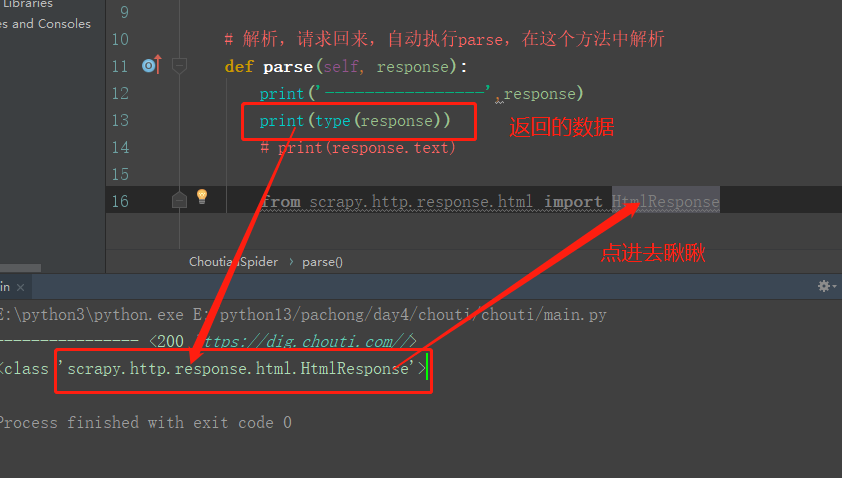
Crawling data and parsing
# 1 resolution, you can use bs4 resolution
from bs4 import BeautifulSoup
soup=BeautifulSoup(response.text,'lxml')
soup.find_all() # bs4 analysis
soup.select() # css analysis
# 2 built in parser
response.css
response.xpath
# Built in parsing
# All the items selected with css or xpath are placed in the list
# Take the first one: extract "first()
# Remove all extract()
# css selector takes text and properties:
# .link-title::text # Take the text, and the data is in the data
# .link-title::attr(href) # Take the attribute, and the data is in the data
# xpath selector takes text and properties
# .//a[contains(@class,"link-title")/text()]
#.//a[contains(@class,"link-title")/@href]
# Built in css selection period, take all
div_list = response.css('.link-con .link-item')
for div in div_list:
content = div.css('.link-title').extract()
print(content)
Data persistence
# Mode 1 (not recommended)
-1 parser Analytic functions,return List, list set dictionary
# Commands (support: ('json ',' jsonlines', 'JL', 'CSV', 'XML', 'marshal', 'pickle')
# Data to aa.json file
-2 scrapy crawl chouti -o aa.json
# Code:
lis = []
for div in div_list:
content = div.select('.link-title')[0].text
lis.append({'title':content})
return lis
# Mode 2 pipeline mode (pipeline)
-1 stay items.py Create model class in
-2 In reptiles chouti.py,Import, put the parsed data into item Object (to use brackets)
-3 yield item object
-4 Profile configuration pipeline
ITEM_PIPELINES = {
# Number indicates priority (the smaller the number, the higher the priority)
'crawl_chouti.pipelines.CrawlChoutiPipeline': 300,
'crawl_chouti.pipelines.CrawlChoutiRedisPipeline': 301,
}
-5 pipline.py Write persistent classes in
spider_open # Method, open the file at the beginning
process_item # Method, write to file
spider_close # Method, close file
Save to file
# choutiaa.py crawler file
import scrapy
from chouti.items import ChoutiItem # Import model class
class ChoutiaaSpider(scrapy.Spider):
name = 'choutiaa'
# allowed_domains = ['https://dig.chouti.com / '] (domain allowed to crawl)
start_urls = ['https://dig.chouti.com//'] # Starting position
# Parse, request back, execute parse automatically, parse in this method
def parse(self, response):
print('----------------',response)
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text,'lxml')
div_list = soup.select('.link-con .link-item')
for div in div_list:
content = div.select('.link-title')[0].text
href = div.select('.link-title')[0].attrs['href']
item = ChoutiItem() # Generate model objects
item['content'] = content # add value
item['href'] = href
yield item # Must use yield
# items.py model class file
import scrapy
class ChoutiItem(scrapy.Item):
content = scrapy.Field()
href = scrapy.Field()
# Pipeline.py data persistence file
class ChoutiPipeline(object):
def open_spider(self, spider):
# Open the file at the beginning
self.f = open('a.txt', 'w', encoding='utf-8')
def process_item(self, item, spider):
# print(item)
# Write to file