Link to the general outline of this series of articles: surface flinger series of articles of Android GUI system
Summary & description of key points in this chapter:
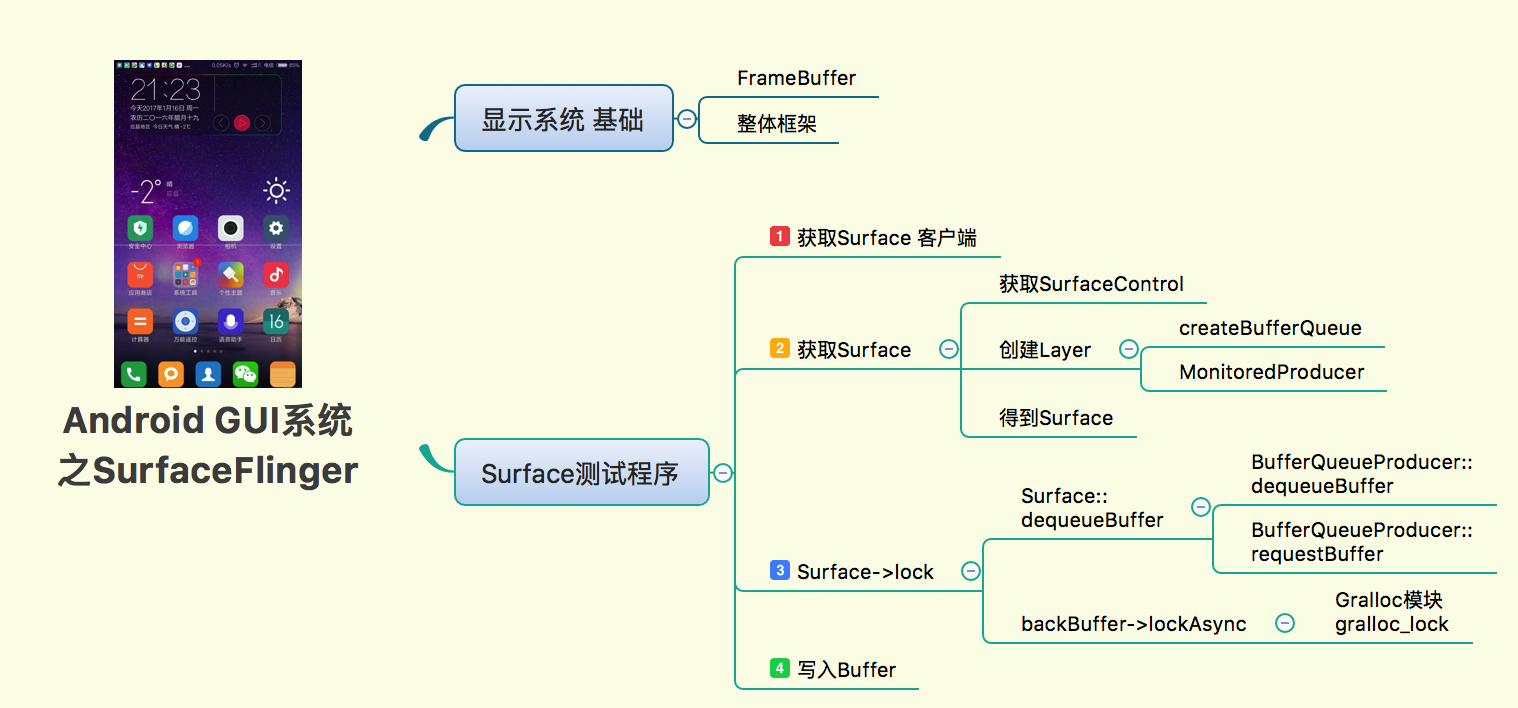
The mind map of this chapter is as above. It mainly describes the process of acquiring Buffer, locking (the most critical) and writing Buffer in the third step of the surf CE test program demo.
Key source code description
This part of the code is a simplified version of the source code of the Surface test program in the previous chapter, which saves the most critical processes as follows:
#include <cutils/memory.h>
#include <utils/Log.h>
#include <binder/IPCThreadState.h>
#include <binder/ProcessState.h>
#include <binder/IServiceManager.h>
#include <gui/Surface.h>
#include <gui/SurfaceComposerClient.h>
#include <android/native_window.h>
using namespace android;
int main(int argc, char** argv)
{
//...
//1 create the client of the surfacelinker
sp<SurfaceComposerClient> client = new SurfaceComposerClient();
//2 get surface
sp<SurfaceControl> surfaceControl = client->createSurface(String8("resize"),
160, 240, PIXEL_FORMAT_RGB_565, 0);
sp<Surface> surface = surfaceControl->getSurface();
//Set the layer. The higher the layer value is, the higher the display layer is
SurfaceComposerClient::openGlobalTransaction();
surfaceControl->setLayer(100000);
SurfaceComposerClient::closeGlobalTransaction();
//3 get buffer - > lock buffer - > write buffer - > unlock and submit buffer
//The main focus here: apply for Buff and submit Buff
ANativeWindow_Buffer outBuffer;
surface->lock(&outBuffer, NULL);
ssize_t bpr = outBuffer.stride * bytesPerPixel(outBuffer.format);
android_memset16((uint16_t*)outBuffer.bits, 0xF800, bpr*outBuffer.height);
surface->unlockAndPost();
//...
return 0;
}The main steps are:
- Obtain the client of the SurfaceFlinger (hereafter referred to as SF), obtain the SurfaceControl through the client of SF, and then obtain the Surface
- Set Layer value through SurfaceControl (ignored), obtain Buffer through Surface, lock Buffer and write Buffer
- Last commit Buffer
This chapter focuses on the process of acquiring Buffer, locking (the most critical) and writing Buffer in step 3. While getting Buffer is only to create an outBuffer through the antiativewindow ﹣ Buffer and pass it to the lock method of the Surface. Writing Buffer is only to write data to the Buffer through the final practical memset. Therefore, the most critical and tedious part is the Surface lock method, which mainly analyzes the whole method. The corresponding code is:
surface->lock(&outBuffer, NULL);
The lock method code of Surface is as follows:
status_t Surface::lock(ANativeWindow_Buffer* outBuffer, ARect* inOutDirtyBounds)
{
if (mLockedBuffer != 0) {
ALOGE("Surface::lock failed, already locked");
return INVALID_OPERATION;
}
//Get some information about the display
if (!mConnectedToCpu) {
int err = Surface::connect(NATIVE_WINDOW_API_CPU);
if (err) {
return err;
}
// we're intending to do software rendering from this point
setUsage(GRALLOC_USAGE_SW_READ_OFTEN | GRALLOC_USAGE_SW_WRITE_OFTEN);
}
ANativeWindowBuffer* out;
int fenceFd = -1;
//Key point 1
status_t err = dequeueBuffer(&out, &fenceFd);
ALOGE_IF(err, "dequeueBuffer failed (%s)", strerror(-err));
if (err == NO_ERROR) {
sp<GraphicBuffer> backBuffer(GraphicBuffer::getSelf(out));
const Rect bounds(backBuffer->width, backBuffer->height);
Region newDirtyRegion;
if (inOutDirtyBounds) {
newDirtyRegion.set(static_cast<Rect const&>(*inOutDirtyBounds));
newDirtyRegion.andSelf(bounds);
} else {
newDirtyRegion.set(bounds);
}
// figure out if we can copy the frontbuffer back
const sp<GraphicBuffer>& frontBuffer(mPostedBuffer);
const bool canCopyBack = (frontBuffer != 0 &&
backBuffer->width == frontBuffer->width &&
backBuffer->height == frontBuffer->height &&
backBuffer->format == frontBuffer->format);
if (canCopyBack) {
// copy the area that is invalid and not repainted this round
const Region copyback(mDirtyRegion.subtract(newDirtyRegion));
if (!copyback.isEmpty())
copyBlt(backBuffer, frontBuffer, copyback);
} else {
// if we can't copy-back anything, modify the user's dirty
// region to make sure they redraw the whole buffer
newDirtyRegion.set(bounds);
mDirtyRegion.clear();
Mutex::Autolock lock(mMutex);
for (size_t i=0 ; i<NUM_BUFFER_SLOTS ; i++) {
mSlots[i].dirtyRegion.clear();
}
}
{ // scope for the lock
Mutex::Autolock lock(mMutex);
int backBufferSlot(getSlotFromBufferLocked(backBuffer.get()));
if (backBufferSlot >= 0) {
Region& dirtyRegion(mSlots[backBufferSlot].dirtyRegion);
mDirtyRegion.subtract(dirtyRegion);
dirtyRegion = newDirtyRegion;
}
}
mDirtyRegion.orSelf(newDirtyRegion);
if (inOutDirtyBounds) {
*inOutDirtyBounds = newDirtyRegion.getBounds();
}
void* vaddr;
//Key point 2
status_t res = backBuffer->lockAsync(
GRALLOC_USAGE_SW_READ_OFTEN | GRALLOC_USAGE_SW_WRITE_OFTEN,
newDirtyRegion.bounds(), &vaddr, fenceFd);
if (res != 0) {
err = INVALID_OPERATION;
} else {
mLockedBuffer = backBuffer;
//Construct the outbuffer variable
outBuffer->width = backBuffer->width;
outBuffer->height = backBuffer->height;
outBuffer->stride = backBuffer->stride;
outBuffer->format = backBuffer->format;
outBuffer->bits = vaddr;//mmap map address
}
}
return err;
}At the same time, we will focus on the four key points identified in the code to start the analysis.
1 dequeueBuffer analysis
The dequeueBuffer method of Surface is implemented as follows:
int Surface::dequeueBuffer(android_native_buffer_t** buffer, int* fenceFd) {
//...
//Producer, issue Buffer request to SurfaceFlinger to get the Buffer, an element of mslots array
status_t result = mGraphicBufferProducer->dequeueBuffer(&buf, &fence, swapIntervalZero,
reqW, reqH, reqFormat, reqUsage);
//...
if ((result & IGraphicBufferProducer::BUFFER_NEEDS_REALLOCATION) || gbuf == 0) {
//Request and return fd to SF, then mmap on APP side
result = mGraphicBufferProducer->requestBuffer(buf, &gbuf);
if (result != NO_ERROR) {
mGraphicBufferProducer->cancelBuffer(buf, fence);
return result;
}
}
//...
*buffer = gbuf.get();
return OK;
}
Here we focus on two key methods: the dequeueBuffer method of mGraphicBufferProducer and the requestBuffer method of mGraphicBufferProducer. (the analysis of Binder communication part is ignored in this analysis process. For details of Binder communication part, please refer to the link of series of articles: The core mechanism of android system binder)
dequeueBuffer method of 1.1 mGraphicBufferProducer
The dequeueBuffer code of BufferQueueProducer is implemented as follows:
status_t BufferQueueProducer::dequeueBuffer(int *outSlot,
sp<android::Fence> *outFence, bool async,
uint32_t width, uint32_t height, uint32_t format, uint32_t usage) {
//...
{ // Autolock scope
//...
int found;
//Get the free slots element and lock it
status_t status = waitForFreeSlotThenRelock("dequeueBuffer", async,
&found, &returnFlags);
if (status != NO_ERROR) {
return status;
}
//...
} // Autolock scope
//Reassign if necessary
if (returnFlags & BUFFER_NEEDS_REALLOCATION) {
status_t error;
BQ_LOGV("dequeueBuffer: allocating a new buffer for slot %d", *outSlot);
sp<GraphicBuffer> graphicBuffer(mCore->mAllocator->createGraphicBuffer(
width, height, format, usage, &error));
if (graphicBuffer == NULL) {
BQ_LOGE("dequeueBuffer: createGraphicBuffer failed");
return error;
}
{ // Autolock scope
Mutex::Autolock lock(mCore->mMutex);
if (mCore->mIsAbandoned) {
BQ_LOGE("dequeueBuffer: BufferQueue has been abandoned");
return NO_INIT;
}
mSlots[*outSlot].mFrameNumber = UINT32_MAX;
mSlots[*outSlot].mGraphicBuffer = graphicBuffer;
} // Autolock scope
}
if (attachedByConsumer) {
returnFlags |= BUFFER_NEEDS_REALLOCATION;
}
//...
return returnFlags;
}Here we focus on two pieces of code: waitForFreeSlotThenRelock method and the creation of graphicBuffer.
1.1.1 waitForFreeSlotThenRelock analysis
The code implementation of waitForFreeSlotThenRelock is as follows:
status_t BufferQueueProducer::waitForFreeSlotThenRelock(const char* caller,
bool async, int* found, status_t* returnFlags) const {
bool tryAgain = true;
while (tryAgain) {
if (mCore->mIsAbandoned) {
BQ_LOGE("%s: BufferQueue has been abandoned", caller);
return NO_INIT;
}
//...
// Look for a free buffer to give to the client
*found = BufferQueueCore::INVALID_BUFFER_SLOT;
int dequeuedCount = 0;
int acquiredCount = 0;
for (int s = 0; s < maxBufferCount; ++s) {
switch (mSlots[s].mBufferState) {
case BufferSlot::DEQUEUED:
++dequeuedCount;
break;
case BufferSlot::ACQUIRED:
++acquiredCount;
break;
case BufferSlot::FREE:
// We return the oldest of the free buffers to avoid
// stalling the producer if possible, since the consumer
// may still have pending reads of in-flight buffers
if (*found == BufferQueueCore::INVALID_BUFFER_SLOT ||
mSlots[s].mFrameNumber < mSlots[*found].mFrameNumber) {
*found = s;
}
break;
default:
break;
}
}
//...
} // while (tryAgain)
return NO_ERROR;
}The most critical part is the above section. The main function is to find the FREE free Buffer in the mSlots array and return it by subscript (the subscript is found in the previous section of code)
1.1.2 creation of graphicBuffer
When creating a graphicBuffer, a parameter is passed here, which is as follows:
mCore->mAllocator->createGraphicBuffer(width, height, format, usage, &error)
Here is mainly to call the createGraphicBuffer method of the member variable mlocator (IGraphicBufferAlloc type) in the BufferQueueCore. This code is relatively simple, and finally returns a variable of GraphicBuffer type. The code is as follows:
sp<GraphicBuffer> GraphicBufferAlloc::createGraphicBuffer(uint32_t w, uint32_t h,
PixelFormat format, uint32_t usage, status_t* error) {
sp<GraphicBuffer> graphicBuffer(new GraphicBuffer(w, h, format, usage));
status_t err = graphicBuffer->initCheck();
*error = err;
if (err != 0 || graphicBuffer->handle == 0) {
if (err == NO_MEMORY) {
GraphicBuffer::dumpAllocationsToSystemLog();
}
ALOGE("GraphicBufferAlloc::createGraphicBuffer(w=%d, h=%d) "
"failed (%s), handle=%p",
w, h, strerror(-err), graphicBuffer->handle);
return 0;
}
return graphicBuffer;
}
After that, we will analyze the corresponding constructors of SP < graphicbuffer > graphicbuffer (...). The code is as follows:
GraphicBuffer::GraphicBuffer(uint32_t w, uint32_t h,
PixelFormat reqFormat, uint32_t reqUsage)
: BASE(), mOwner(ownData), mBufferMapper(GraphicBufferMapper::get()),
mInitCheck(NO_ERROR), mId(getUniqueId())
{
width = w;
height = h;
stride = inStride;
format = inFormat;
usage = 0;
handle = NULL;
mInitCheck = initSize(w, h, reqFormat, reqUsage);
}Continue to analyze initSize here, and the code is as follows:
status_t GraphicBuffer::initSize(uint32_t w, uint32_t h, PixelFormat format,
uint32_t reqUsage)
{
//Open the Gralloc module
GraphicBufferAllocator& allocator = GraphicBufferAllocator::get();
//Call the alloc function of HAL module
status_t err = allocator.alloc(w, h, format, reqUsage, &handle, &stride);
if (err == NO_ERROR) {
this->width = w;
this->height = h;
this->format = format;
this->usage = reqUsage;
}
return err;
}Here, we call the granlloc module and get the code of allocator as follows:
GraphicBufferAllocator::GraphicBufferAllocator()
: mAllocDev(0)
{
hw_module_t const* module;
int err = hw_get_module(GRALLOC_HARDWARE_MODULE_ID, &module);
ALOGE_IF(err, "FATAL: can't find the %s module", GRALLOC_HARDWARE_MODULE_ID);
if (err == 0) {
gralloc_open(module, &mAllocDev);
}
}Then use allocator.alloc to request memory. The code is as follows:
status_t GraphicBufferAllocator::alloc(uint32_t w, uint32_t h, PixelFormat format,
int usage, buffer_handle_t* handle, int32_t* stride)
{
if (!w || !h)
w = h = 1;
// we have a h/w allocator and h/w buffer is requested
status_t err;
err = mAllocDev->alloc(mAllocDev, w, h, format, usage, handle, stride);
if (err == NO_ERROR) {
Mutex::Autolock _l(sLock);
KeyedVector<buffer_handle_t, alloc_rec_t>& list(sAllocList);
int bpp = bytesPerPixel(format);
if (bpp < 0) {
// probably a HAL custom format. in any case, we don't know
// what its pixel size is.
bpp = 0;
}
alloc_rec_t rec;
rec.w = w;
rec.h = h;
rec.s = *stride;
rec.format = format;
rec.usage = usage;
rec.size = h * stride[0] * bpp;
list.add(*handle, rec);
}
return err;
}
Here, the mllocdev - > alloc method is called, and the next step is the call of the galloc module in HAL layer. When the galloc module is initialized, the code is as follows:
int gralloc_device_open(const hw_module_t* module, const char* name,
hw_device_t** device)
{
int status = -EINVAL;
if (!strcmp(name, GRALLOC_HARDWARE_GPU0)) {
gralloc_context_t *dev;
dev = (gralloc_context_t*)malloc(sizeof(*dev));
/* initialize our state here */
memset(dev, 0, sizeof(*dev));
/* initialize the procs */
dev->device.common.tag = HARDWARE_DEVICE_TAG;
dev->device.common.version = 0;
dev->device.common.module = const_cast<hw_module_t*>(module);
dev->device.common.close = gralloc_close;
dev->device.alloc = gralloc_alloc;
dev->device.free = gralloc_free;
*device = &dev->device.common;
status = 0;
} else {
status = fb_device_open(module, name, device);
}
return status;
}
Therefore, the mllocdev - > alloc method here is the corresponding Gralloc_allocmethod of the Gralloc module. The code is as follows:
static int gralloc_alloc(alloc_device_t* dev,
int w, int h, int format, int usage,
buffer_handle_t* pHandle, int* pStride)
{
//...
int err;
if (usage & GRALLOC_USAGE_HW_FB) {
err = gralloc_alloc_framebuffer(dev, size, usage, pHandle);
} else {
err = gralloc_alloc_buffer(dev, size, usage, pHandle);
}
//...
*pStride = stride;
return 0;
}
Because it is an application buffer, the selected buffer is a granlloc ﹐ alloc ﹐ buffer. Continue to analyze the code as follows:
static int gralloc_alloc_buffer(alloc_device_t* dev,
size_t size, int /*usage*/, buffer_handle_t* pHandle)
{
//...
fd = ashmem_create_region("gralloc-buffer", size);
//...
if (err == 0) {
private_handle_t* hnd = new private_handle_t(fd, size, 0);
gralloc_module_t* module = reinterpret_cast<gralloc_module_t*>(
dev->common.module);
err = mapBuffer(module, hnd);
if (err == 0) {
*pHandle = hnd;
}
}
return err;
}Here, we use the ashmem shared memory mechanism to allocate memory Buffer and get fd. At the same time, we use fd and Buffer generated by mmap to construct a handle. The address generated by mmap is directly used by SF.
1.2 mGraphicBufferProducer's requestBuffer method
At this time, SF has obtained the handle (the set of handle fd of Buffer to be applied and the first address of mmap). Next, call requestBuffer to use the Binder mechanism to pass the SF handle to the APP (the analysis of Binder communication part is ignored in this analysis process. For details of Binder communication part, please refer to the links in the series of articles: The core mechanism of android system binder ) The requestBuffer code of BufferQueueProducer is implemented as follows:
status_t BufferQueueProducer::requestBuffer(int slot, sp<GraphicBuffer>* buf) {
Mutex::Autolock lock(mCore->mMutex);
//...
mSlots[slot].mRequestBufferCalled = true;
*buf = mSlots[slot].mGraphicBuffer;
return NO_ERROR;
}1.3 summary
APP corresponds to a client, a SurfaceControl corresponds to a Layer, and each Surface corresponds to an mslots array (there are 64 elements in the mslots array, each element contains a GraphicBuffer and a handle, including the mapping address of fd and mmap). The process of obtaining Buffer from Surface is as follows:
- Execute dequeueBuffer first. If there is no Buffer on the Surface, apply to the producer producer (GraphicBufferProducer class object, and finally through SF operation) to check whether there is any remaining item in mslots. If there is a direct return, apply to the malloc Hal to get a handle (the set of handle fd of the Buffer to be applied and the first address of mmap)
- Secondly, execute the requestBuffer, and the APP (Client side) transfers the SF obtained handle to the Client side handle through this method
- APP gets fd, mmap gets the address (mmap is executed through the Gralloc HAL), and then writes to Buffer
2 backBuffer->lockAsync analysis
The backbuffer - > lockasync code is implemented as follows:
status_t GraphicBuffer::lockAsync(uint32_t usage, const Rect& rect, void** vaddr, int fenceFd)
{
//...
status_t res = getBufferMapper().lockAsync(handle, usage, rect, vaddr, fenceFd);
return res;
}
Continue to analyze the lockAsync method of GraphicBufferMapper. The code implementation is as follows:
status_t GraphicBufferMapper::lockAsync(buffer_handle_t handle,
int usage, const Rect& bounds, void** vaddr, int fenceFd)
{
status_t err;
if (mAllocMod->common.module_api_version >= GRALLOC_MODULE_API_VERSION_0_3) {
err = mAllocMod->lockAsync(mAllocMod, handle, usage,
bounds.left, bounds.top, bounds.width(), bounds.height(),
vaddr, fenceFd);
} else {
sync_wait(fenceFd, -1);
close(fenceFd);
err = mAllocMod->lock(mAllocMod, handle, usage,
bounds.left, bounds.top, bounds.width(), bounds.height(),
vaddr);
}
return err;
}Further analysis here will lead to HAL layer, which corresponds to the function of granloc ⒌ lock of granloc module. The code implementation is as follows:
int gralloc_lock(gralloc_module_t const* /*module*/,
buffer_handle_t handle, int /*usage*/,
int /*l*/, int /*t*/, int /*w*/, int /*h*/,
void** vaddr)
{
if (private_handle_t::validate(handle) < 0)
return -EINVAL;
private_handle_t* hnd = (private_handle_t*)handle;
*vaddr = (void*)hnd->base;
return 0;
}This is mainly to assign handle - > base to the parameter vaddr of backBuffer - > lockasync, which is also the address of mmap mapping in APP. Finally, the outBuffer will be initialized with the member variable of backBuffer through the assignment operation of outBuffer - > bits = vaddr.

