Then climb the hook, and directly ignore the anti climbing! Selenium+Xpath+re visible and creepable
I wrote a blog before python successfully climbs the dragnet -- initial understanding of anti climbing (a small white real climbing path, the content is a little bit smaller) This is the first time for me to crawl a website with various anti climbing measures. Most of the previous crawls were simple static fixed-point web crawling (practicing the use of simple python web crawler Library), so I encountered a big wave of setbacks, and I just managed to solve it after reading a lot of big guys' blogs. Of course, now I have a good understanding of the way of data loading with hooks (Ajax dynamic loading Data) and anti climbing measures A kind of
Recently, I have learned Selenium automatic test library, and I want to try to use this method to crawl the hook again, to realize the difference. Of course, using this library is because it simulates browser browsing and human click input, does not need to analyze the response of web page requests, and does not need to construct header requests, so I want to try it. Because do not need too much analysis, so directly on the code!
Import the required Library:
from selenium import webdriver import time import lxml from lxml import etree import re
Browse and click the simulation browser in the main method. If you put it in a certain method, you may get the result that the simulation browser is successful, but you may get the result of exiting in seconds:
if __name__ == '__main__': url = 'https://www.lagou.com/' #login(url) #Initialize browser driver = webdriver.Chrome() #Jump to target page driver.get(url)
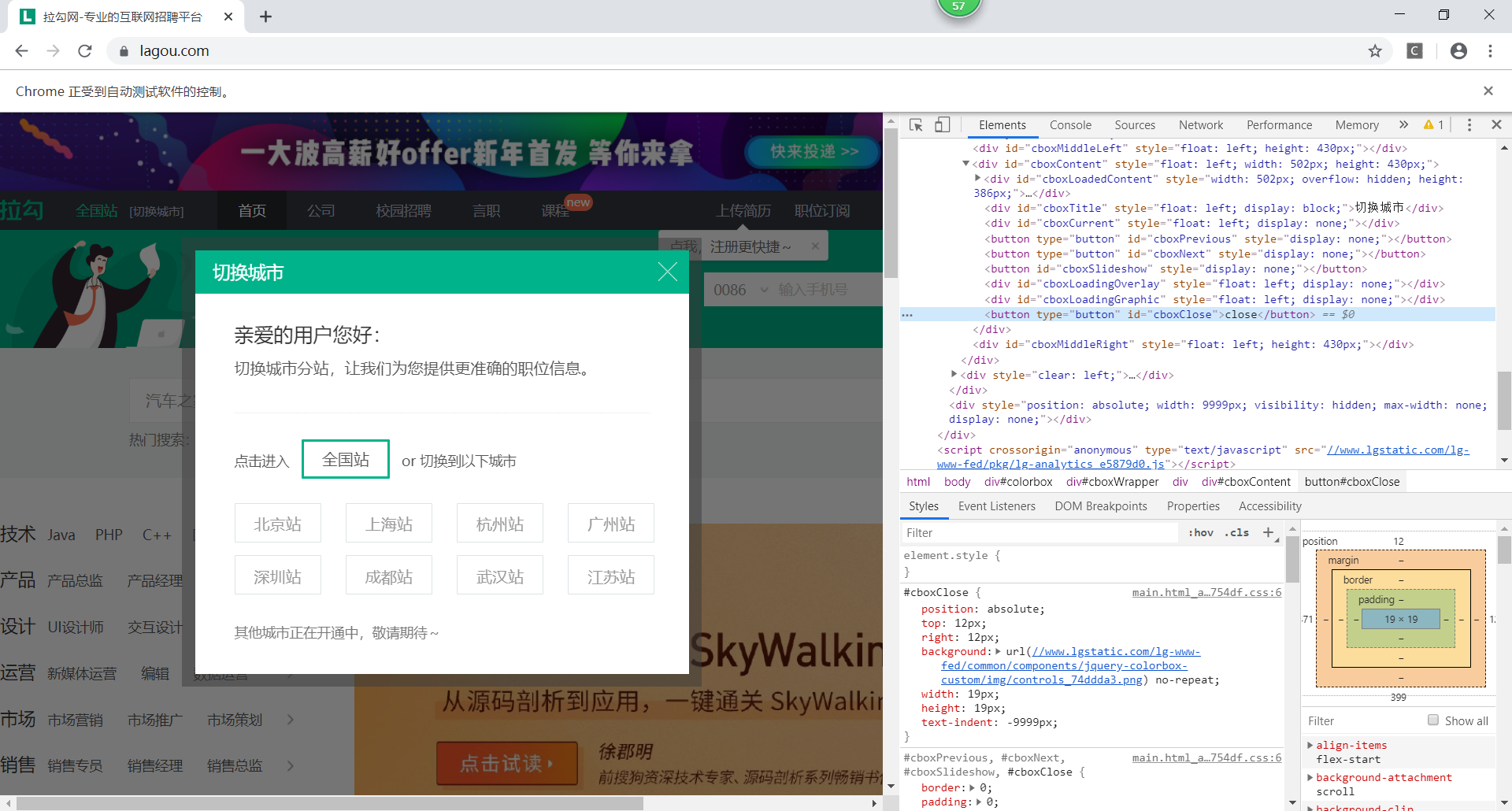 As can be seen from the figure, a city selection box pops up after the webpage jump, which affects our access to the source code of the webpage. So I first find the source code of the close button, find it and click it to close the pop-up window
As can be seen from the figure, a city selection box pops up after the webpage jump, which affects our access to the source code of the webpage. So I first find the source code of the close button, find it and click it to close the pop-up window
#Get button to close pop-up #<button type="button" id="cboxClose">close</button> button_close = driver.find_element_by_id('cboxClose') #Close pop up button_close.click()
In this way, the pop-up window can be closed. The next step is to get the input box, input the keyword you want to query into the input box, and click the search button:

Lock the button and input box according to the key attributes of Element element shown in the figure:
#Wait 1 second for the response from the source code of the web page time.sleep(1) #keywards = input('Please input the position information you want to find: ') input = driver.find_element_by_id('search_input') input.send_keys('python Internet worm') button_search = driver.find_element_by_id('search_button') button_search.click()
This completes the search of keywords. When the browser is opened automatically, there are irrelevant pop ups. It's better to analyze them and close the pop ups. Maybe everyone has different situations, and there may not be pop ups. So I will not put the screenshot here, and directly give the code for closing pop ups. Then I will get the current source code of the web page:
#< div class = "body BTN" > do not give < / div > button_btn = driver.find_element_by_class_name('body-btn') button_btn.click() time.sleep(1) page_source = driver.page_source
Finally, I can analyze the information you want. Here I use the methods of re and Xpath to strengthen the practice of both: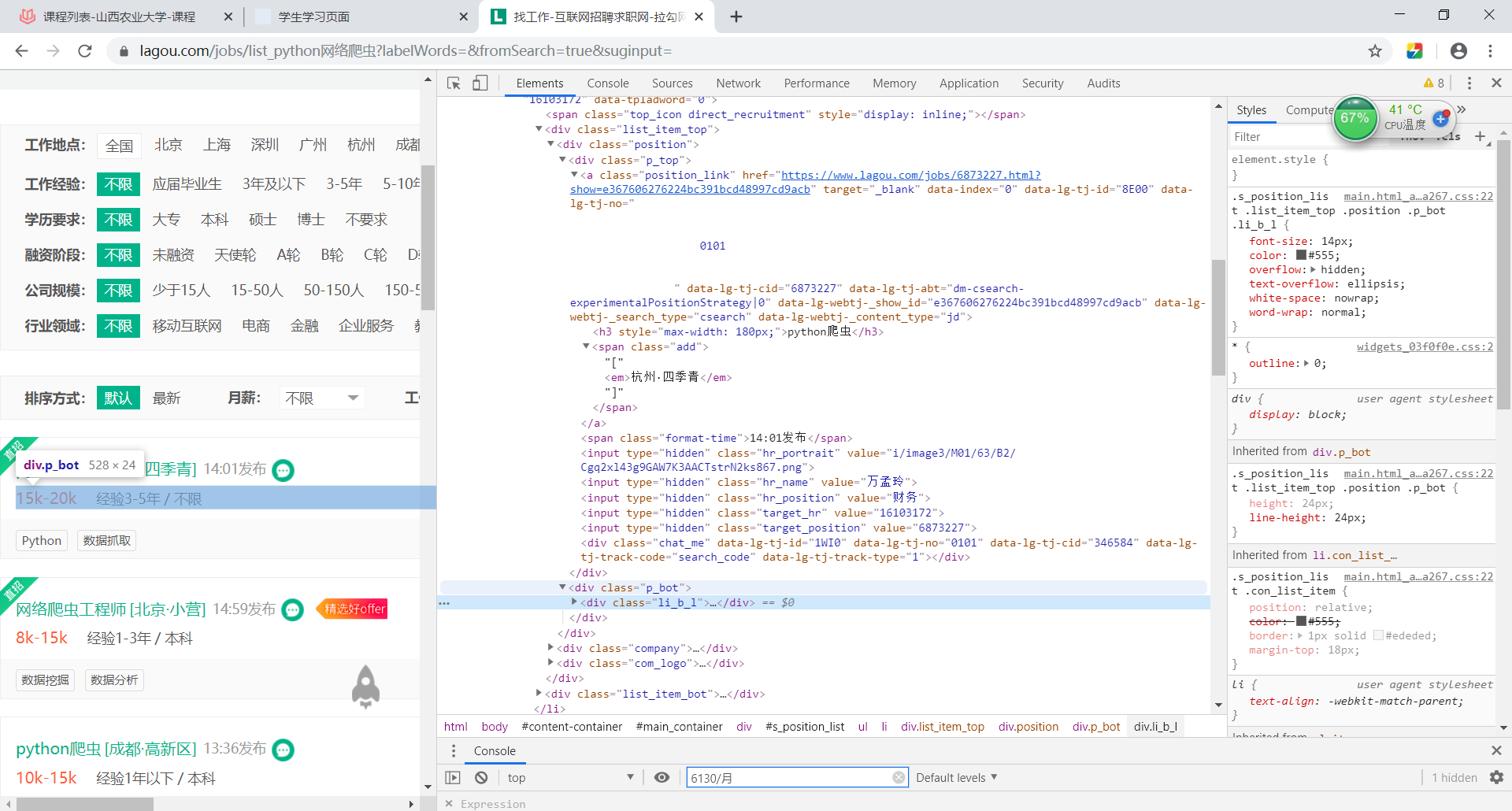
It can be seen that all information of each position is placed in the div tag:
def search_information(page_source): tree = etree.HTML(page_source) #< H3 style = "max width: 180px;" > Web crawler Engineer</h3> position_name = tree.xpath('//h3[@style="max-width: 180px;"]/text()') #< span class = "add" > [< EM > Beijing · Xiaoying < / EM >]</span> position_location = tree.xpath('//span[@class="add"]/em/text()') #< span class = "format time" > 17:15 release</span> position_report_time = tree.xpath('//span[@class="format-time"]/text()') #<span class="money">8k-15k</span> positon_salary = tree.xpath('//span[@class="money"]/text()') #position_edution = tree.xpath('//div[@class="li_b_l"]/text()') position_edution = re.findall('<div.*?class="li_b_l">(.*?)</div>',str(page_source),re.S) position_result_edution = sub_edution(position_edution) position_company_name = tree.xpath('//div[@class="company_name"]/a/text()') position_company_href = tree.xpath('//div[@class="company_name"]/a/@href') position_company_industry = tree.xpath('//div[@class="industry"]/text()') position_company_industry_result = sub_industry(position_company_industry) #< div class = "Li ﹐ B ﹐" > Free brunch + free bus + five insurances and two payments + year-end bonus "< / div > position_good = tree.xpath('//div[@class="li_b_r"]/text()') for i in range(len(position_company_name)): print("Title:{}".format(position_name[i])) print("Company location:{}".format(position_location [i])) print("Information release time:{}".format(position_report_time[i])) print("Position salary:{}".format(positon_salary[i])) print("Job requirements:{}".format(position_result_edution[i])) print("corporate name:{}".format(position_company_name[i])) print("Company size:{}".format(position_company_industry_result[i])) print("Corporate welfare:{}".format(position_good[i])) print("Company link:{}".format(position_company_href[i])) print('-----------------------------------------------------------------------')
The content returned by the regular expression contains a space character
def sub_edution(list): a =[] result = [] for i in list: one = re.sub('\n', '', i) two = re.sub(' <span.*?>.*?</span>', '', one) three = re.sub('<!--<i></i>-->', '', two) a.append(three) for i in a[::2]: result.append(i) return result def sub_industry(list): result = [] for i in list: a = re.sub('\n','',i) result.append(a) return result
Results of final spooling: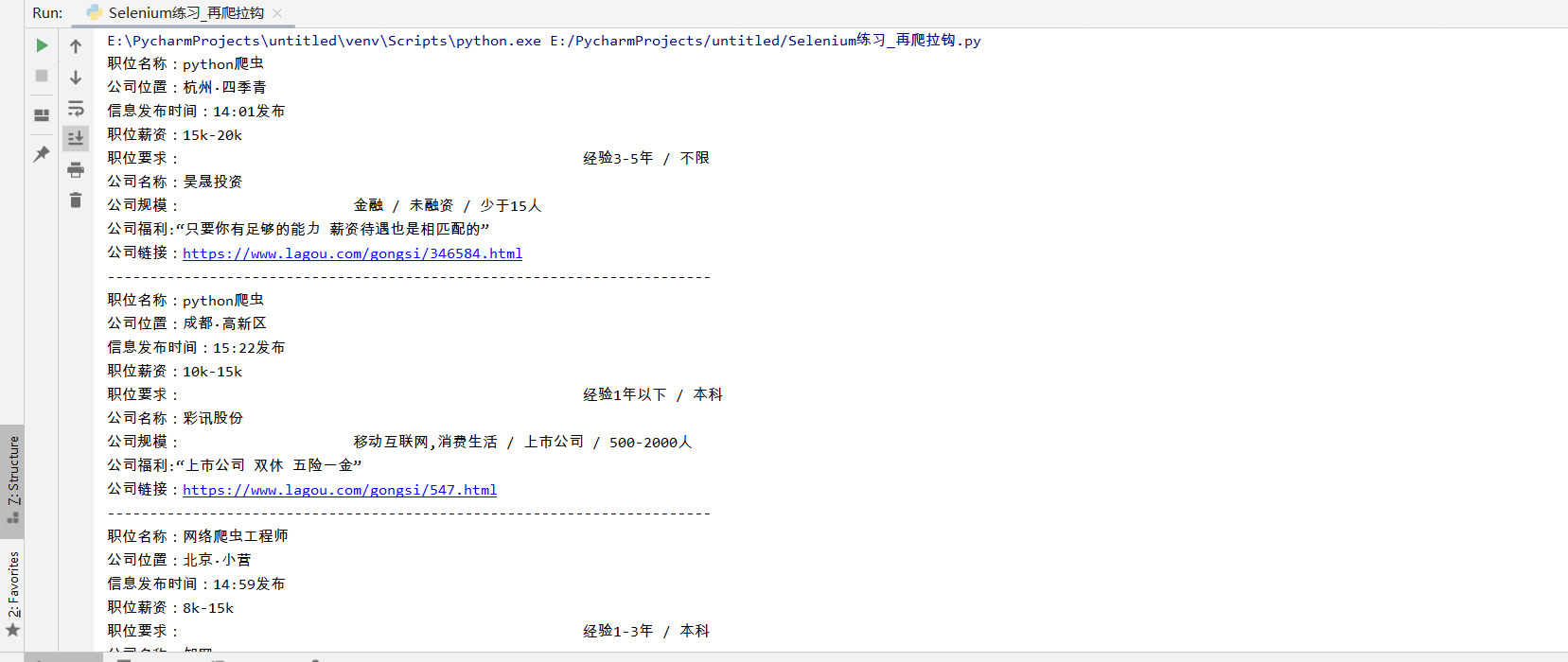 Here I only crawl one page, with 30 pages of information. Brothers can try to crawl multiple pages by themselves. It's very simple to observe the different URL links of different pages
Here I only crawl one page, with 30 pages of information. Brothers can try to crawl multiple pages by themselves. It's very simple to observe the different URL links of different pages
Thank you for reading A kind of

