1. Operation process of spider

The main process is to set the callback function, obtain the return result, print directly or return method, how to save the return type, where to go, and how to open the pipeline,
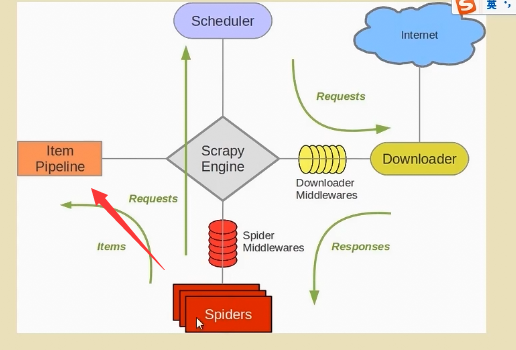 Send to the pipeline for cleaning and other data operations
Send to the pipeline for cleaning and other data operations
2.Spider class analysis

name can be seen in Class in the crawler file, and it can also be seen in the command line interface using the summary list command.
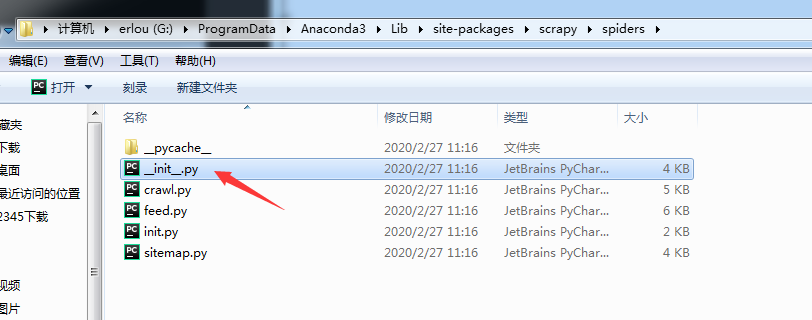
In the python environment where the scraper is installed, the package of the spider can be found in the directory of lib - > site packages - > scraper. Bloggers are here for reference only:
3.Spider's case practice
Need a layer of security verification
https://wenku.baidu.com/search?word=python&pn=20
# -*- coding: utf-8 -*-
import scrapy
class WenkuSpider(scrapy.Spider):
name = 'wenku'
allowed_domains = ['wenku.baidu.com']
start_urls = ['https://wenku.baidu.com/search?word=python&pn=0','https://wenku.baidu.com/search?word=python&pn=10','https://wenku.baidu.com/search?word=python&pn=20']
def parse(self, response):
# print("hello scrapy")
dllist = response.selector.xpath("//dl")
# This part is only for testing, because the dl tag can't be retrieved, see what the reason is, do you want to completely anti crawl or just set the header that can't be crawled
allist = response.selector.xpath("//a")
for a in allist:
print(a)
for dd in dllist:
print(dd)
print("123")
print(dd.css("p.fl a::attr('title')").extract_first())
print("-"*70)
# This part can't be collected. After careful inspection, it is fruitless. I found the same case on the Internet and decided to go back first
In the access test of chrome browser, a manual verification is completed, and then the test content and the target title content can be collected. Whether it's because of the role of the browser in the collection of scratch, or whether the baidu Library has filtered the verification of the verified IP address, here my web page is no longer needed to open, and if similar problems are encountered later, it can be reorganized for confirmation.
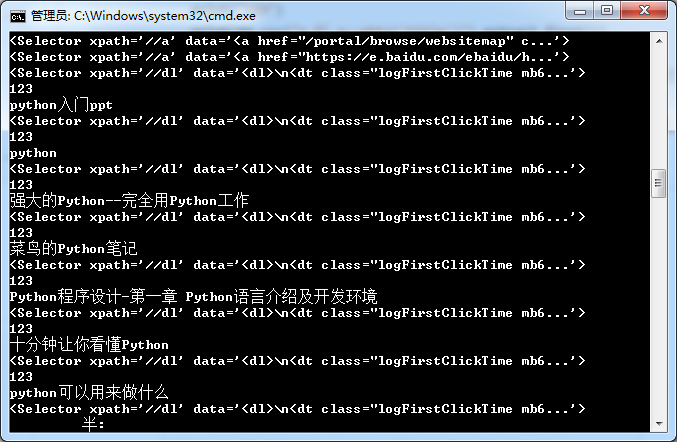
Then, we use the url reconstruction to complete the collection of multiple connections. During the operation, the first few CMDS are OK, but some of them can't be opened in the next few pages. So, modify the 10 page sample given by the teacher, change it to 5 pages, reopen the command-line interface for practice, and insert a small idea. The collection task completed by the handwritten python crawler used in the previous period is more troublesome, and the results obtained are relatively difficult It's also not structured enough. You can complete this part of the operation by using scrape collection. Localize first, and then consider using distributed or cloud,
 You can only reopen one operation interface that cannot be opened.
You can only reopen one operation interface that cannot be opened.
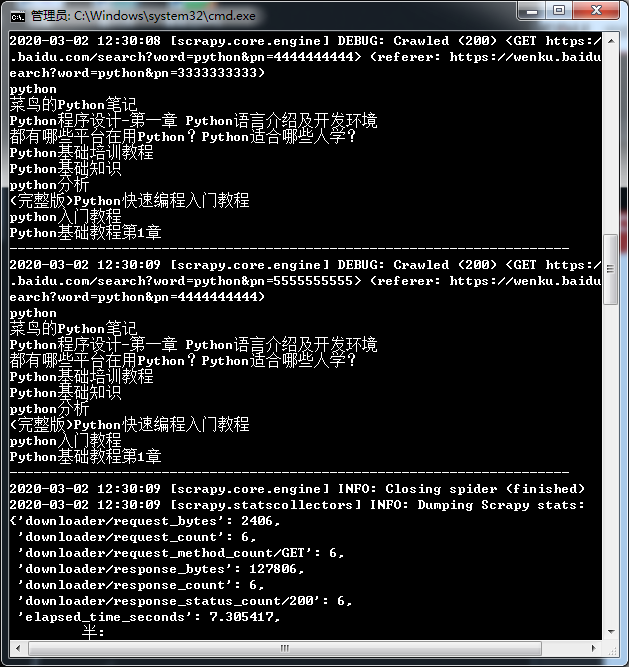
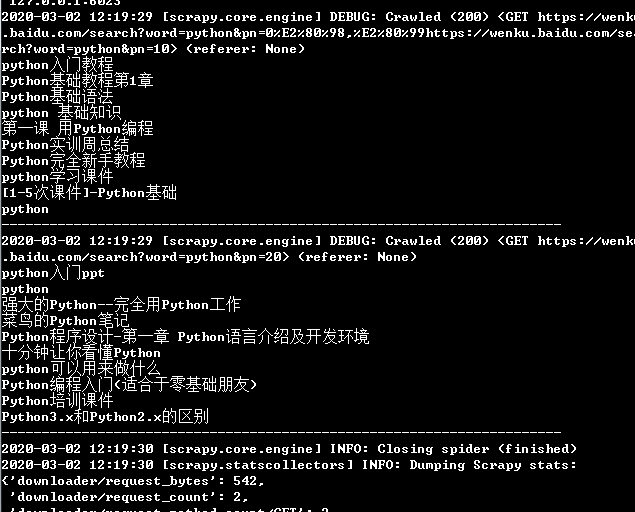
After changing the number of pages to 5, the collection was completed soon, but a problem was found. Each page of this part is the same, and the collection is the same page. Compared with the top part, when putting the url into the start uurl, the multi page content collected is different. After checking, it is found that when the page url is changed in the code, it should be the front part + str (number * 10). When I put * 10 into the function of converting to string, * 10 aims to display 10 items on each page. Here, the front number is higher each time, and the back Multiply it directly. After modifying the source code, the result is ok.
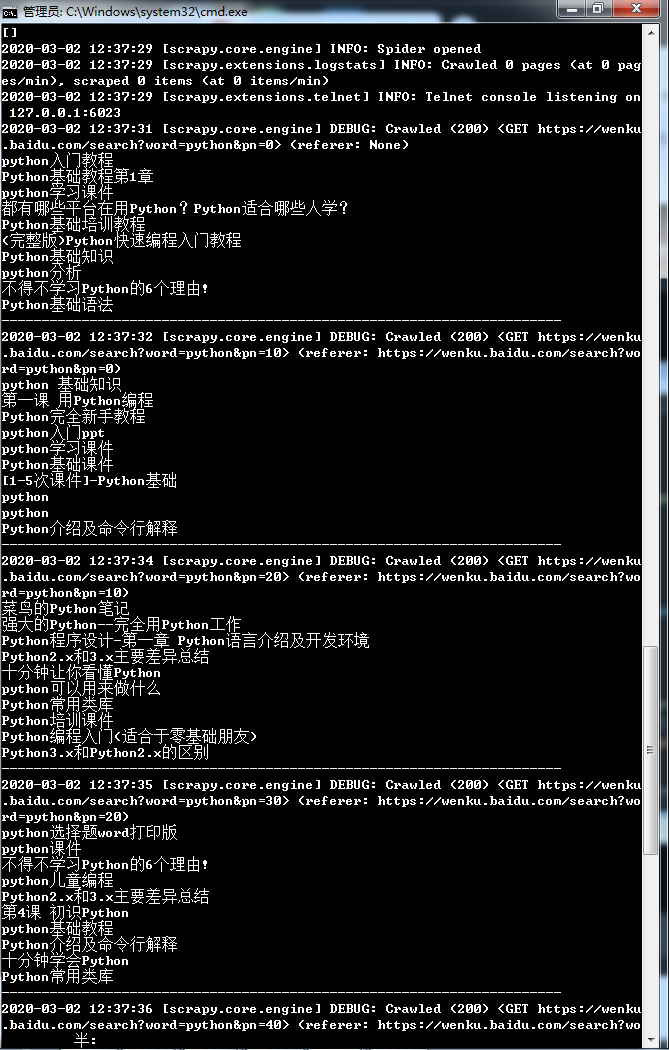
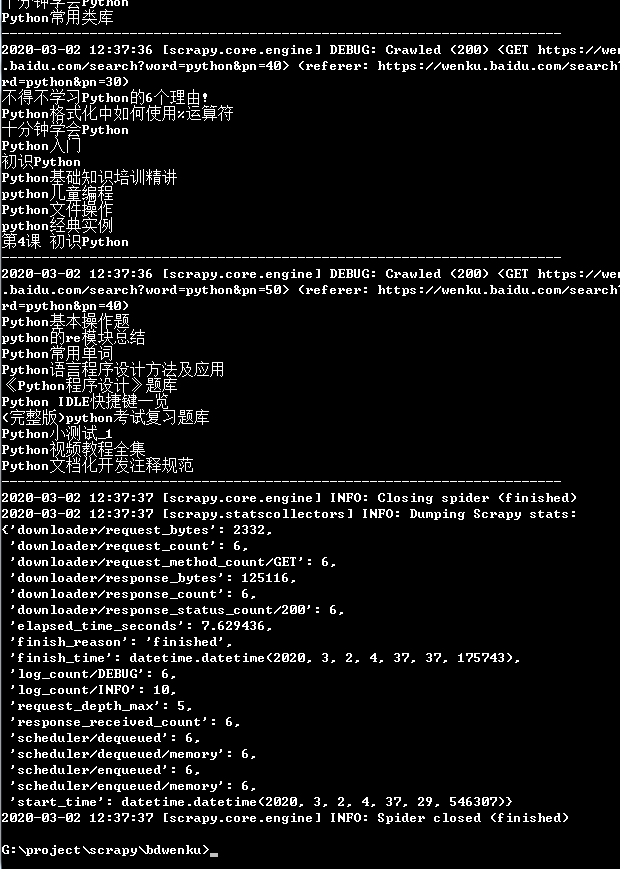
Search the title of the result from the python library on page 1-5. This part of the teacher explained here, first put the source code:
# -*- coding: utf-8 -*-
import scrapy
class WenkuSpider(scrapy.Spider):
name = 'wenku'
allowed_domains = ['wenku.baidu.com']
start_urls = ['https://wenku.baidu.com/search?word=python&pn=0']
p = 0
def parse(self, response):
# The output of extracting the title content of the first five pages of search results in baidu Library with python as the keyword
dllist = response.selector.xpath("//dl")
for dd in dllist:
print(dd.css("p.fl a::attr('title')").extract_first())
print("-"*70)
# Callback function, for url reconstruction
self.p += 1
if self.p < 6:
next_url = 'https://wenku.baidu.com/search?word=python&pn='+str(self.p*10)
url = response.urljoin(next_url)#Build absolute url address (can be omitted)
yield scrapy.Request(url=url,callback=self.parse)I will make a small extension of the title and url, and collect the "title + url" into the csv file. For the review of the previous blog post, the modification of the items file and the persistent storage of items to the file, first put the results, then put the source code:
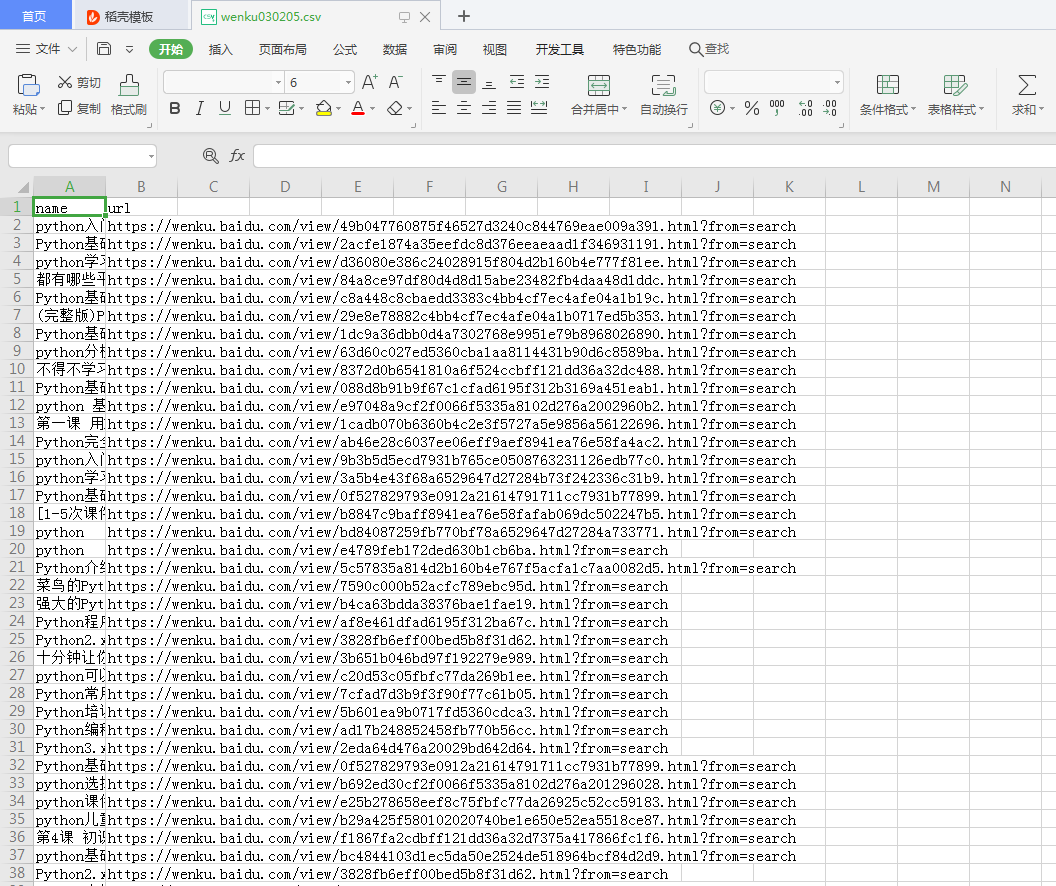
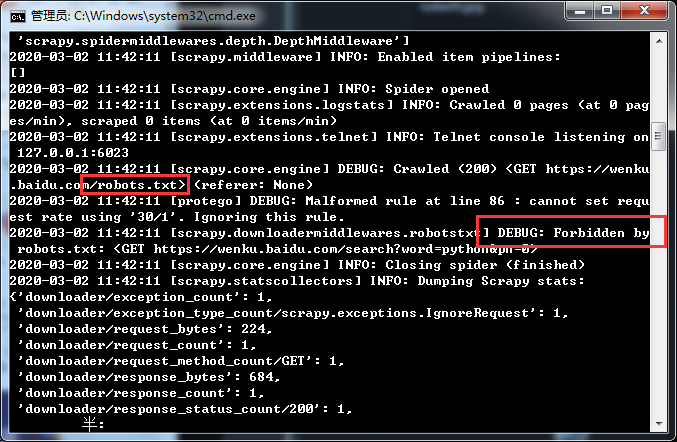
Under the source code, you need to take it by yourself and study reasonably. Do not use it commercially [as of 20200302 13:39, this code can achieve the target source code collection without complying with the robot protocol]:
# -*- coding: utf-8 -*-
import scrapy
import bdwenku
import bdwenku.items
from bdwenku.items import BdwenkuItem
class WenkuSpider(scrapy.Spider):
name = 'wenku'
allowed_domains = ['wenku.baidu.com']
start_urls = ['https://wenku.baidu.com/search?word=python&pn=0']
p = 0
def parse(self, response):
# print("hello scrapy")
dllist = response.selector.xpath("//dl")
for dd in dllist:
# Declare a new class object for storing data
item = bdwenku.items.BdwenkuItem()
item['name'] = dd.css("p.fl a::attr('title')").extract_first()
item['url'] = dd.css("p.fl a::attr('href')").extract_first()
yield item
self.p += 1
if self.p < 6:
next_url = 'https://wenku.baidu.com/search?word=python&pn='+str(self.p*10)
url = response.urljoin(next_url)#Build absolute url address (can be omitted)
yield scrapy.Request(url=url,callback=self.parse)
This is the end of this part of learning, including declaration of new classes, package operation, item passing, in which index part '' quotation mark is essential, pay attention to syntax issues.
One word of vitality! Practice deliberately, improve every day ~ come on~

